References to “gpt-5-reasoning-alpha-2025-07-13” have already been spotted on X, with code showing “reasoning_effort: high” in the model configuration. These sightings suggest the model has entered final testing phases, with testers getting their hands on the code and security experts doing red teaming on the model to test vulnerabilities.
Unifying OpenAI’s model lineup
The new model represents OpenAI’s attempt to simplify its increasingly complex product lineup. As Altman explained in February, GPT-5 may integrate features from both the company’s conventional GPT models and its reasoning-focused o-series models into a single system.
“We’re truly excited to not just make a net new great frontier model, we’re also going to unify our two series,” OpenAI’s Head of Developer Experience Romain Huet said at a recent event. “The breakthrough of reasoning in the O-series and the breakthroughs in multi-modality in the GPT-series will be unified, and that will be GPT-5.”
According to The Information, GPT-5 is expected to be better at coding and more powerful overall, combining attributes of both traditional models and SR models such as o3.
Before GPT-5 arrives, OpenAI still plans to release its first open-weights model since GPT-2 in 2019, which means others with the proper hardware will be able to download and run the AI model on their own machines. The Verge describes this model as “similar to o3 mini” with reasoning capabilities. However, Altman announced on July 11 that the open model needs additional safety testing, saying, “We are not yet sure how long it will take us.”
On Thursday, Anthropic unveiled specialized AI models designed for US national security customers. The company released “Claude Gov” models that were built in response to direct feedback from government clients to handle operations such as strategic planning, intelligence analysis, and operational support. The custom models reportedly already serve US national security agencies, with access restricted to those working in classified environments.
The Claude Gov models differ from Anthropic’s consumer and enterprise offerings, also called Claude, in several ways. They reportedly handle classified material, “refuse less” when engaging with classified information, and are customized to handle intelligence and defense documents. The models also feature what Anthropic calls “enhanced proficiency” in languages and dialects critical to national security operations.
Anthropic says the new models underwent the same “safety testing” as all Claude models. The company has been pursuing government contracts as it seeks reliable revenue sources, partnering with Palantir and Amazon Web Services in November to sell AI tools to defense customers.
Anthropic is not the first company to offer specialized chatbot services for intelligence agencies. In 2024, Microsoft launched an isolated version of OpenAI’s GPT-4 for the US intelligence community after 18 months of work. That system, which operated on a special government-only network without Internet access, became available to about 10,000 individuals in the intelligence community for testing and answering questions.
The release comes just two weeks after OpenAI made GPT-4 unavailable in ChatGPT on April 30. That earlier model, which launched in March 2023, once sparked widespread hype about AI capabilities. Compared to that hyperbolic launch, GPT-4.1’s rollout has been a fairly understated affair—probably because it’s tricky to convey the subtle differences between all of the available OpenAI models.
As if 4.1’s launch wasn’t confusing enough, the release also roughly coincides with OpenAI’s July 2025 deadline for retiring the GPT-4.5 Preview from the API, a model one AI expert called a “lemon.” Developers must migrate to other options, OpenAI says, although GPT-4.5 will remain available in ChatGPT for now.
A confusing addition to OpenAI’s model lineup
In February, OpenAI CEO Sam Altman acknowledged his company’s confusing AI model naming practices on X, writing, “We realize how complicated our model and product offerings have gotten.” He promised that a forthcoming “GPT-5” model would consolidate the o-series and GPT-series models into a unified branding structure. But the addition of GPT-4.1 to ChatGPT appears to contradict that simplification goal.
So, if you use ChatGPT, which model should you use? If you’re a developer using the models through the API, the consideration is more of a trade-off between capability, speed, and cost. But in ChatGPT, your choice might be limited more by personal taste in behavioral style and what you’d like to accomplish. Some of the “more capable” models have lower usage limits as well because they cost more for OpenAI to run.
For now, OpenAI is keeping GPT-4o as the default ChatGPT model, likely due to its general versatility, balance between speed and capability, and personable style (conditioned using reinforcement learning and a specialized system prompt). The simulated reasoning models like 03 and 04-mini-high are slower to execute but can consider analytical-style problems more systematically and perform comprehensive web research that sometimes feels genuinely useful when it surfaces relevant (non-confabulated) web links. Compared to those, OpenAI is largely positioning GPT-4.1 as a speedier AI model for coding assistance.
Just remember that all of the AI models are prone to confabulations, meaning that they tend to make up authoritative-sounding information when they encounter gaps in their trained “knowledge.” So you’ll need to double-check all of the outputs with other sources of information if you’re hoping to use these AI models to assist with an important task.
One of the most influential—and by some counts, notorious—AI models yet released will soon fade into history. OpenAI announced on April 10 that GPT-4 will be “fully replaced” by GPT-4o in ChatGPT at the end of April, bringing a public-facing end to the model that accelerated a global AI race when it launched in March 2023.
“Effective April 30, 2025, GPT-4 will be retired from ChatGPT and fully replaced by GPT-4o,” OpenAI wrote in its April 10 changelog for ChatGPT. While ChatGPT users will no longer be able to chat with the older AI model, the company added that “GPT-4 will still be available in the API,” providing some reassurance to developers who might still be using the older model for various tasks.
The retirement marks the end of an era that began on March 14, 2023, when GPT-4 demonstrated capabilities that shocked some observers: reportedly scoring at the 90th percentile on the Uniform Bar Exam, acing AP tests, and solving complex reasoning problems that stumped previous models. Its release created a wave of immense hype—and existential panic—about AI’s ability to imitate human communication and composition.
A screenshot of GPT-4’s introduction to ChatGPT Plus customers from March 14, 2023. Credit: Benj Edwards / Ars Technica
While ChatGPT launched in November 2022 with GPT-3.5 under the hood, GPT-4 took AI language models to a new level of sophistication, and it was a massive undertaking to create. It combined data scraped from the vast corpus of human knowledge into a set of neural networks rumored to weigh in at a combined total of 1.76 trillion parameters, which are the numerical values that hold the data within the model.
Along the way, the model reportedly cost more than $100 million to train, according to comments by OpenAI CEO Sam Altman, and required vast computational resources to develop. Training the model may have involved over 20,000 high-end GPUs working in concert—an expense few organizations besides OpenAI and its primary backer, Microsoft, could afford.
Industry reactions, safety concerns, and regulatory responses
Curiously, GPT-4’s impact began before OpenAI’s official announcement. In February 2023, Microsoft integrated its own early version of the GPT-4 model into its Bing search engine, creating a chatbot that sparked controversy when it tried to convince Kevin Roose of The New York Times to leave his wife and when it “lost its mind” in response to an Ars Technica article.
On Monday, OpenAI announced the GPT-4.1 model family, its newest series of AI language models that brings a 1 million token context window to OpenAI for the first time and continues a long tradition of very confusing AI model names. Three confusing new names, in fact: GPT‑4.1, GPT‑4.1 mini, and GPT‑4.1 nano.
According to OpenAI, these models outperform GPT-4o in several key areas. But in an unusual move, GPT-4.1 will only be available through the developer API, not in the consumer ChatGPT interface where most people interact with OpenAI’s technology.
The 1 million token context window—essentially the amount of text the AI can process at once—allows these models to ingest roughly 3,000 pages of text in a single conversation. This puts OpenAI’s context windows on par with Google’s Gemini models, which have offered similar extended context capabilities for some time.
At the same time, the company announced it will retire the GPT-4.5 Preview model in the API—a temporary offering launched in February that one critic called a “lemon”—giving developers until July 2025 to switch to something else. However, it appears GPT-4.5 will stick around in ChatGPT for now.
So many names
If this sounds confusing, well, that’s because it is. OpenAI CEO Sam Altman acknowledged OpenAI’s habit of terrible product names in February when discussing the roadmap toward the long-anticipated (and still theoretical) GPT-5.
“We realize how complicated our model and product offerings have gotten,” Altman wrote on X at the time, referencing a ChatGPT interface already crowded with choices like GPT-4o, various specialized GPT-4o versions, GPT-4o mini, the simulated reasoning o1-pro, o3-mini, and o3-mini-high models, and GPT-4. The stated goal for GPT-5 will be consolidation, a branding move to unify o-series models and GPT-series models.
So, how does launching another distinctly numbered model, GPT-4.1, fit into that grand unification plan? It’s hard to say. Altman foreshadowed this kind of ambiguity in March 2024, telling Lex Friedman the company had major releases coming but was unsure about names: “before we talk about a GPT-5-like model called that, or not called that, or a little bit worse or a little bit better than what you’d expect…”
Perhaps because of the disappointing results, Altman had previously written that GPT-4.5 will be the last of OpenAI’s traditional AI models, with GPT-5 planned to be a dynamic combination of “non-reasoning” LLMs and simulated reasoning models like o3.
A stratospheric price and a tech dead-end
And about that price—it’s a doozy. GPT-4.5 costs $75 per million input tokens and $150 per million output tokens through the API, compared to GPT-4o’s $2.50 per million input tokens and $10 per million output tokens. (Tokens are chunks of data used by AI models for processing). For developers using OpenAI models, this pricing makes GPT-4.5 impractical for many applications where GPT-4o already performs adequately.
By contrast, OpenAI’s flagship reasoning model, o1 pro, costs $15 per million input tokens and $60 per million output tokens—significantly less than GPT-4.5 despite offering specialized simulated reasoning capabilities. Even more striking, the o3-mini model costs just $1.10 per million input tokens and $4.40 per million output tokens, making it cheaper than even GPT-4o while providing much stronger performance on specific tasks.
OpenAI has likely known about diminishing returns in training LLMs for some time. As a result, the company spent most of last year working on simulated reasoning models like o1 and o3, which use a different inference-time (runtime) approach to improving performance instead of throwing ever-larger amounts of training data at GPT-style AI models.
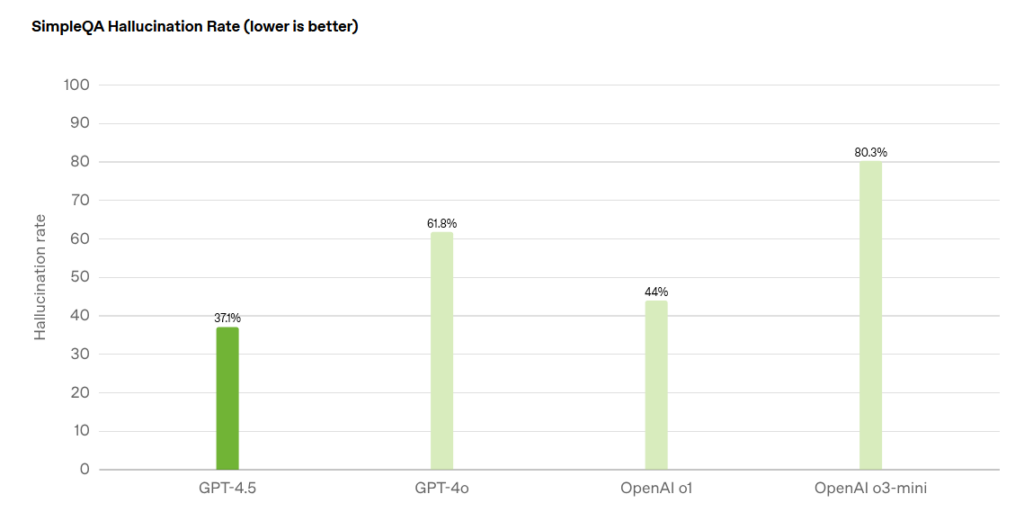
OpenAI’s self-reported benchmark results for the SimpleQA test, which measures confabulation rate. Credit: OpenAI
While this seems like bad news for OpenAI in the short term, competition is thriving in the AI market. Anthropic’s Claude 3.7 Sonnet has demonstrated vastly better performance than GPT-4.5, with a reportedly more efficient architecture. It’s worth noting that Claude 3.7 Sonnet is likely a system of AI models working together behind the scenes, although Anthropic has not provided details about its architecture.
For now, it seems that GPT-4.5 may be the last of its kind—a technological dead-end for an unsupervised learning approach that has paved the way for new architectures in AI models, such as o3’s inference-time reasoning and perhaps even something more novel, like diffusion-based models. Only time will tell how things end up.
GPT-4.5 is now available to ChatGPT Pro subscribers, with rollout to Plus and Team subscribers planned for next week, followed by Enterprise and Education customers the week after. Developers can access it through OpenAI’s various APIs on paid tiers, though the company is uncertain about its long-term availability.
On X, frequent AI experimenter Ethan Mollick wrote, “Been playing with o1 and o1-pro for bit. They are very good & a little weird. They are also not for most people most of the time. You really need to have particular hard problems to solve in order to get value out of it. But if you have those problems, this is a very big deal.”
OpenAI claims improved reliability
OpenAI is touting pro mode’s improved reliability, which is evaluated internally based on whether it can solve a question correctly in four out of four attempts rather than just a single attempt.
“In evaluations from external expert testers, o1 pro mode produces more reliably accurate and comprehensive responses, especially in areas like data science, programming, and case law analysis,” OpenAI writes.
Even without pro mode, OpenAI cited significant increases in performance over the o1 preview model on popular math and coding benchmarks (AIME 2024 and Codeforces), and more marginal improvements on a “PhD-level science” benchmark (GPQA Diamond). The increase in scores between o1 and o1 pro mode were much more marginal on these benchmarks.
We’ll likely have more coverage of the full version of o1 once it rolls out widely—and it’s supposed to launch today, accessible to ChatGPT Plus and Team users globally. Enterprise and Edu users will have access next week. At the moment, the ChatGPT Pro subscription is not yet available on our test account.
A co-author of Attention Is All You Need reflects on ChatGPT’s surprise and Google’s conservatism.
Jakob Uszkoreit Credit: Jakob Uszkoreit / Getty Images
In 2017, eight machine-learning researchers at Google released a groundbreaking research paper called Attention Is All You Need, which introduced the Transformer AI architecture that underpins almost all of today’s high-profile generative AI models.
The Transformer has made a key component of the modern AI boom possible by translating (or transforming, if you will) input chunks of data called “tokens” into another desired form of output using a neural network. Variations of the Transformer architecture power language models like GPT-4o (and ChatGPT), audio synthesis models that run Google’s NotebookLM and OpenAI’s Advanced Voice Mode, video synthesis models like Sora, and image synthesis models like Midjourney.
At TED AI 2024 in October, one of those eight researchers, Jakob Uszkoreit, spoke with Ars Technica about the development of transformers, Google’s early work on large language models, and his new venture in biological computing.
In the interview, Uszkoreit revealed that while his team at Google had high hopes for the technology’s potential, they didn’t quite anticipate its pivotal role in products like ChatGPT.
The Ars interview: Jakob Uszkoreit
Ars Technica: What was your main contribution to the Attention is All You Need paper?
Jakob Uszkoreit (JU): It’s spelled out in the footnotes, but my main contribution was to propose that it would be possible to replace recurrence [from Recurrent Neural Networks] in the dominant sequence transduction models at the time with the attention mechanism, or more specifically self-attention. And that it could be more efficient and, as a result, also more effective.
Ars: Did you have any idea what would happen after your group published that paper? Did you foresee the industry it would create and the ramifications?
JU: First of all, I think it’s really important to keep in mind that when we did that, we were standing on the shoulders of giants. And it wasn’t just that one paper, really. It was a long series of works by some of us and many others that led to this. And so to look at it as if this one paper then kicked something off or created something—I think that is taking a view that we like as humans from a storytelling perspective, but that might not actually be that accurate of a representation.
My team at Google was pushing on attention models for years before that paper. It’s a lot longer of a slog with much, much more, and that’s just my group. Many others were working on this, too, but we had high hopes that it would push things forward from a technological perspective. Did we think that it would play a role in really enabling, or at least apparently, seemingly, flipping a switch when it comes to facilitating products like ChatGPT? I don’t think so. I mean, to be very clear in terms of LLMs and their capabilities, even around the time we published the paper, we saw phenomena that were pretty staggering.
We didn’t get those out into the world in part because of what really is maybe a notion of conservatism around products at Google at the time. But we also, even with those signs, weren’t that confident that stuff in and of itself would make that compelling of a product. But did we have high hopes? Yeah.
Ars: Since you knew there were large language models at Google, what did you think when ChatGPT broke out into a public success? “Damn, they got it, and we didn’t?”
JU: There was a notion of, well, “that could have happened.” I think it was less of a, “Oh dang, they got it first” or anything of the like. It was more of a “Whoa, that could have happened sooner.” Was I still amazed by just how quickly people got super creative using that stuff? Yes, that was just breathtaking.
Jakob Uszkoreit presenting at TED AI 2024. Credit: Benj Edwards
Ars: You weren’t at Google at that point anymore, right?
JU: I wasn’t anymore. And in a certain sense, you could say the fact that Google wouldn’t be the place to do that factored into my departure. I left not because of what I didn’t like at Google as much as I left because of what I felt I absolutely had to do elsewhere, which is to start Inceptive.
But it was really motivated by just an enormous, not only opportunity, but a moral obligation in a sense, to do something that was better done outside in order to design better medicines and have very direct impact on people’s lives.
Ars: The funny thing with ChatGPT is that I was using GPT-3 before that. So when ChatGPT came out, it wasn’t that big of a deal to some people who were familiar with the tech.
JU: Yeah, exactly. If you’ve used those things before, you could see the progression and you could extrapolate. When OpenAI developed the earliest GPTs with Alec Radford and those folks, we would talk about those things despite the fact that we weren’t at the same companies. And I’m sure there was this kind of excitement, how well-received the actual ChatGPT product would be by how many people, how fast. That still, I think, is something that I don’t think anybody really anticipated.
Ars: I didn’t either when I covered it. It felt like, “Oh, this is a chatbot hack of GPT-3 that feeds its context in a loop.” And I didn’t think it was a breakthrough moment at the time, but it was fascinating.
JU: There are different flavors of breakthroughs. It wasn’t a technological breakthrough. It was a breakthrough in the realization that at that level of capability, the technology had such high utility.
That, and the realization that, because you always have to take into account how your users actually use the tool that you create, and you might not anticipate how creative they would be in their ability to make use of it, how broad those use cases are, and so forth.
That is something you can sometimes only learn by putting something out there, which is also why it is so important to remain experiment-happy and to remain failure-happy. Because most of the time, it’s not going to work. But some of the time it’s going to work—and very, very rarely it’s going to work like [ChatGPT did].
Ars: You’ve got to take a risk. And Google didn’t have an appetite for taking risks?
JU: Not at that time. But if you think about it, if you look back, it’s actually really interesting. Google Translate, which I worked on for many years, was actually similar. When we first launched Google Translate, the very first versions, it was a party joke at best. And we took it from that to being something that was a truly useful tool in not that long of a period. Over the course of those years, the stuff that it sometimes output was so embarrassingly bad at times, but Google did it anyway because it was the right thing to try. But that was around 2008, 2009, 2010.
Ars: When that came out, it blew my mind. My brother and I would do this thing where we would translate text back and forth between languages for fun because it would garble the text.
JU: It would get worse and worse and worse. Yeah.
Programming biological computers
After his time at Google, Uszkoreit co-founded Inceptive to apply deep learning to biochemistry. The company is developing what he calls “biological software,” where AI compilers translate specified behaviors into RNA sequences that can perform desired functions when introduced to biological systems.
Ars: What are you up to these days?
JU: In 2021 we co-founded Inceptive in order to use deep learning and high throughput biochemistry experimentation to design better medicines that truly can be programmed. We think of this as really just step one in the direction of something that we call biological software.
Biological software is a little bit like computer software in that you have some specification of the behavior that you want, and then you have a compiler that translates that into a piece of computer software that then runs on a computer exhibiting the functions or the functionality that you specify.
You specify a piece of a biological program and you compile that, but not with an engineered compiler, because life hasn’t been engineered like computers have been engineered. But with a learned AI compiler, you translate that or compile that into molecules that when inserted into biological systems, organisms, our cells exhibit those functions that you’ve programmed into.
A pharmacist holds a bottle containing Moderna’s bivalent COVID-19 vaccine. Credit: Getty | Mel Melcon
Ars: Is that anything like how the mRNA COVID vaccines work?
JU: A very, very simple example of that are the mRNA COVID vaccines where the program says, “Make this modified viral antigen” and then our cells make that protein. But you could imagine molecules that exhibit far more complex behaviors. And if you want to get a picture of how complex those behaviors could be, just remember that RNA viruses are just that. They’re just an RNA molecule that when entering an organism exhibits incredibly complex behavior such as distributing itself across an organism, distributing itself across the world, doing certain things only in a subset of your cells for a certain period of time, and so on and so forth.
And so you can imagine that if we managed to even just design molecules with a teeny tiny fraction of such functionality, of course with the goal not of making people sick, but of making them healthy, it would truly transform medicine.
Ars: How do you not accidentally create a monster RNA sequence that just wrecks everything?
JU: The amazing thing is that medicine for the longest time has existed in a certain sense outside of science. It wasn’t truly understood, and we still often don’t truly understand their actual mechanisms of action.
As a result, humanity had to develop all of these safeguards and clinical trials. And even before you enter the clinic, all of these empirical safeguards prevent us from accidentally doing [something dangerous]. Those systems have been in place for as long as modern medicine has existed. And so we’re going to keep using those systems, and of course with all the diligence necessary. We’ll start with very small systems, individual cells in future experimentation, and follow the same established protocols that medicine has had to follow all along in order to ensure that these molecules are safe.
Ars: Thank you for taking the time to do this.
JU: No, thank you.
Benj Edwards is Ars Technica’s Senior AI Reporter and founder of the site’s dedicated AI beat in 2022. He’s also a widely-cited tech historian. In his free time, he writes and records music, collects vintage computers, and enjoys nature. He lives in Raleigh, NC.
On Thursday, OpenAI released an early Windows version of its first ChatGPT app for Windows, following a Mac version that launched in May. Currently, it’s only available to subscribers of Plus, Team, Enterprise, and Edu versions of ChatGPT, and users can download it for free in the Microsoft Store for Windows.
OpenAI is positioning the release as a beta test. “This is an early version, and we plan to bring the full experience to all users later this year,” OpenAI writes on the Microsoft Store entry for the app. (Interestingly, ChatGPT shows up as being rated “T for Teen” by the ESRB in the Windows store, despite not being a video game.)
A screenshot of the new Windows ChatGPT app captured on October 18, 2024.
Credit: Benj Edwards
A screenshot of the new Windows ChatGPT app captured on October 18, 2024. Credit: Benj Edwards
Upon opening the app, OpenAI requires users to log into a paying ChatGPT account, and from there, the app is basically identical to the web browser version of ChatGPT. You can currently use it to access several models: GPT-4o, GPT-4o with Canvas, 01-preview, 01-mini, GPT-4o mini, and GPT-4. Also, it can generate images using DALL-E 3 or analyze uploaded files and images.
If you’re running Windows 11, you can instantly call up a small ChatGPT window when the app is open using an Alt+Space shortcut (it did not work in Windows 10 when we tried). That could be handy for asking ChatGPT a quick question at any time.
A screenshot of the new Windows ChatGPT app listing in the Microsoft Store captured on October 18, 2024.
Credit: Benj Edwards
A screenshot of the new Windows ChatGPT app listing in the Microsoft Store captured on October 18, 2024. Credit: Benj Edwards
And just like the web version, all the AI processing takes place in the cloud on OpenAI’s servers, which means an Internet connection is required.
So as usual, chat like somebody’s watching, and don’t rely on ChatGPT as a factual reference for important decisions—GPT-4o in particular is great at telling you what you want to hear, whether it’s correct or not. As OpenAI says in a small disclaimer at the bottom of the app window: “ChatGPT can make mistakes.”
On Monday, Microsoft unveiled updates to its consumer AI assistant Copilot, introducing two new experimental features for a limited group of $20/month Copilot Pro subscribers: Copilot Labs and Copilot Vision. Labs integrates OpenAI’s latest o1 “reasoning” model, and Vision allows Copilot to see what you’re browsing in Edge.
Microsoft says Copilot Labs will serve as a testing ground for Microsoft’s latest AI tools before they see wider release. The company describes it as offering “a glimpse into ‘work-in-progress’ projects.” The first feature available in Labs is called “Think Deeper,” and it uses step-by-step processing to solve more complex problems than the regular Copilot. Think Deeper is Microsoft’s version of OpenAI’s new o1-preview and o1-mini AI models, and it has so far rolled out to some Copilot Pro users in Australia, Canada, New Zealand, the UK, and the US.
Copilot Vision is an entirely different beast. The new feature aims to give the AI assistant a visual window into what you’re doing within the Microsoft Edge browser. When enabled, Copilot can “understand the page you’re viewing and answer questions about its content,” according to Microsoft.
Microsoft’s Copilot Vision promo video.
The company positions Copilot Vision as a way to provide more natural interactions and task assistance beyond text-based prompts, but it will likely raise privacy concerns. As a result, Microsoft says that Copilot Vision is entirely opt-in and that no audio, images, text, or conversations from Vision will be stored or used for training. The company is also initially limiting Vision’s use to a pre-approved list of websites, blocking it on paywalled and sensitive content.
The rollout of these features appears gradual, with Microsoft noting that it wants to balance “pioneering features and a deep sense of responsibility.” The company said it will be “listening carefully” to user feedback as it expands access to the new capabilities. Microsoft has not provided a timeline for wider availability of either feature.
Mustafa Suleyman, chief executive of Microsoft AI, told Reuters that he sees Copilot as an “ever-present confidant” that could potentially learn from users’ various Microsoft-connected devices and documents, with permission. He also mentioned that Microsoft co-founder Bill Gates has shown particular interest in Copilot’s potential to read and parse emails.
But judging by the visceral reaction to Microsoft’s Recall feature, which keeps a record of everything you do on your PC so an AI model can recall it later, privacy-sensitive users may not appreciate having an AI assistant monitor their activities—especially if those features send user data to the cloud for processing.
OpenAI, the company behind ChatGPT, has now raised $6.6 billion in a new funding round that values the company at $157 billion, nearly doubling its previous valuation of $86 billion, according to a report from The Wall Street Journal.
The funding round comes with strings attached: Investors have the right to withdraw their money if OpenAI does not complete its planned conversion from a nonprofit (with a for-profit division) to a fully for-profit company.
Venture capital firm Thrive Capital led the funding round with a $1.25 billion investment. Microsoft, a longtime backer of OpenAI to the tune of $13 billion, contributed just under $1 billion to the latest round. New investors joined the round, including SoftBank with a $500 million investment and Nvidia with $100 million.
The United Arab Emirates-based company MGX also invested in OpenAI during this funding round. MGX has been busy in AI recently, joining an AI infrastructure partnership last month led by Microsoft.
Notably, Apple was in talks to invest but ultimately did not participate. WSJ reports that the minimum investment required to review OpenAI’s financial documents was $250 million. In June, OpenAI hired its first chief financial officer, Sarah Friar, who played an important role in organizing this funding round, according to the WSJ.
OpenAI finally unveiled its rumored “Strawberry” AI language model on Thursday, claiming significant improvements in what it calls “reasoning” and problem-solving capabilities over previous large language models (LLMs). Formally named “OpenAI o1,” the model family will initially launch in two forms, o1-preview and o1-mini, available today for ChatGPT Plus and certain API users.
OpenAI claims that o1-preview outperforms its predecessor, GPT-4o, on multiple benchmarks, including competitive programming, mathematics, and “scientific reasoning.” However, people who have used the model say it does not yet outclass GPT-4o in every metric. Other users have criticized the delay in receiving a response from the model, owing to the multi-step processing occurring behind the scenes before answering a query.
In a rare display of public hype-busting, OpenAI product manager Joanne Jang tweeted, “There’s a lot of o1 hype on my feed, so I’m worried that it might be setting the wrong expectations. what o1 is: the first reasoning model that shines in really hard tasks, and it’ll only get better. (I’m personally psyched about the model’s potential & trajectory!) what o1 isn’t (yet!): a miracle model that does everything better than previous models. you might be disappointed if this is your expectation for today’s launch—but we’re working to get there!”
OpenAI reports that o1-preview ranked in the 89th percentile on competitive programming questions from Codeforces. In mathematics, it scored 83 percent on a qualifying exam for the International Mathematics Olympiad, compared to GPT-4o’s 13 percent. OpenAI also states, in a claim that may later be challenged as people scrutinize the benchmarks and run their own evaluations over time, o1 performs comparably to PhD students on specific tasks in physics, chemistry, and biology. The smaller o1-mini model is designed specifically for coding tasks and is priced at 80 percent less than o1-preview.
Enlarge/ A benchmark chart provided by OpenAI. They write, “o1 improves over GPT-4o on a wide range of benchmarks, including 54/57 MMLU subcategories. Seven are shown for illustration.”
OpenAI attributes o1’s advancements to a new reinforcement learning (RL) training approach that teaches the model to spend more time “thinking through” problems before responding, similar to how “let’s think step-by-step” chain-of-thought prompting can improve outputs in other LLMs. The new process allows o1 to try different strategies and “recognize” its own mistakes.
AI benchmarks are notoriously unreliable and easy to game; however, independent verification and experimentation from users will show the full extent of o1’s advancements over time. It’s worth noting that MIT Research showed earlier this year that some of the benchmark claims OpenAI touted with GPT-4 last year were erroneous or exaggerated.
A mixed bag of capabilities
OpenAI demos “o1” correctly counting the number of Rs in the word “strawberry.”
Amid many demo videos of o1 completing programming tasks and solving logic puzzles that OpenAI shared on its website and social media, one demo stood out as perhaps the least consequential and least impressive, but it may become the most talked about due to a recurring meme where people ask LLMs to count the number of R’s in the word “strawberry.”
Due to tokenization, where the LLM processes words in data chunks called tokens, most LLMs are typically blind to character-by-character differences in words. Apparently, o1 has the self-reflective capabilities to figure out how to count the letters and provide an accurate answer without user assistance.
Beyond OpenAI’s demos, we’ve seen optimistic but cautious hands-on reports about o1-preview online. Wharton Professor Ethan Mollick wrote on X, “Been using GPT-4o1 for the last month. It is fascinating—it doesn’t do everything better but it solves some very hard problems for LLMs. It also points to a lot of future gains.”
Mollick shared a hands-on post in his “One Useful Thing” blog that details his experiments with the new model. “To be clear, o1-preview doesn’t do everything better. It is not a better writer than GPT-4o, for example. But for tasks that require planning, the changes are quite large.”
Mollick gives the example of asking o1-preview to build a teaching simulator “using multiple agents and generative AI, inspired by the paper below and considering the views of teachers and students,” then asking it to build the full code, and it produced a result that Mollick found impressive.
Mollick also gave o1-preview eight crossword puzzle clues, translated into text, and the model took 108 seconds to solve it over many steps, getting all of the answers correct but confabulating a particular clue Mollick did not give it. We recommend reading Mollick’s entire post for a good early hands-on impression. Given his experience with the new model, it appears that o1 works very similar to GPT-4o but iteratively in a loop, which is something that the so-called “agentic” AutoGPT and BabyAGI projects experimented with in early 2023.
Is this what could “threaten humanity?”
Speaking of agentic models that run in loops, Strawberry has been subject to hype since last November, when it was initially known as Q(Q-star). At the time, The Information and Reuters claimed that, just before Sam Altman’s brief ouster as CEO, OpenAI employees had internally warned OpenAI’s board of directors about a new OpenAI model called Q* that could “threaten humanity.”
In August, the hype continued when The Information reported that OpenAI showed Strawberry to US national security officials.
We’ve been skeptical about the hype around Qand Strawberry since the rumors first emerged, as this author noted last November, and Timothy B. Lee covered thoroughly in an excellent post about Q* from last December.
So even though o1 is out, AI industry watchers should note how this model’s impending launch was played up in the press as a dangerous advancement while not being publicly downplayed by OpenAI. For an AI model that takes 108 seconds to solve eight clues in a crossword puzzle and hallucinates one answer, we can say that its potential danger was likely hype (for now).
Controversy over “reasoning” terminology
It’s no secret that some people in tech have issues with anthropomorphizing AI models and using terms like “thinking” or “reasoning” to describe the synthesizing and processing operations that these neural network systems perform.
Just after the OpenAI o1 announcement, Hugging Face CEO Clement Delangue wrote, “Once again, an AI system is not ‘thinking,’ it’s ‘processing,’ ‘running predictions,’… just like Google or computers do. Giving the false impression that technology systems are human is just cheap snake oil and marketing to fool you into thinking it’s more clever than it is.”
“Reasoning” is also a somewhat nebulous term since, even in humans, it’s difficult to define exactly what the term means. A few hours before the announcement, independent AI researcher Simon Willison tweeted in response to a Bloomberg story about Strawberry, “I still have trouble defining ‘reasoning’ in terms of LLM capabilities. I’d be interested in finding a prompt which fails on current models but succeeds on strawberry that helps demonstrate the meaning of that term.”
Reasoning or not, o1-preview currently lacks some features present in earlier models, such as web browsing, image generation, and file uploading. OpenAI plans to add these capabilities in future updates, along with continued development of both the o1 and GPT model series.
While OpenAI says the o1-preview and o1-mini models are rolling out today, neither model is available in our ChatGPT Plus interface yet, so we have not been able to evaluate them. We’ll report our impressions on how this model differs from other LLMs we have previously covered.