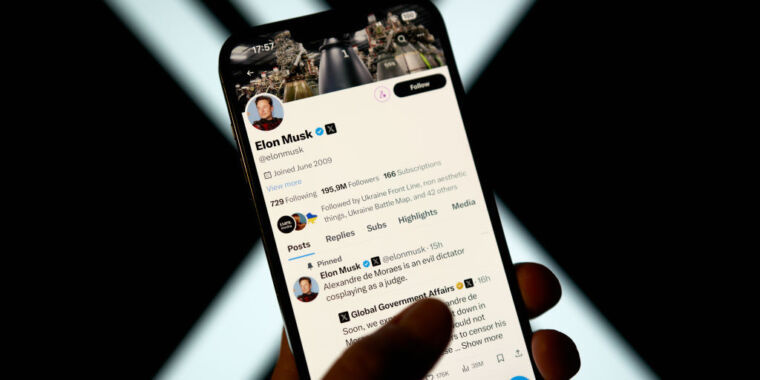
The FBI is warning people to be vigilant of an ongoing malicious messaging campaign that uses AI-generated voice audio to impersonate government officials in an attempt to trick recipients into clicking on links that can infect their computers.
“Since April 2025, malicious actors have impersonated senior US officials to target individuals, many of whom are current or former senior US federal or state government officials and their contacts,” Thursday’s advisory from the bureau’s Internet Crime Complaint Center said. “If you receive a message claiming to be from a senior US official, do not assume it is authentic.”
Think you can’t be fooled? Think again.
The campaign’s creators are sending AI-generated voice messages—better known as deepfakes—along with text messages “in an effort to establish rapport before gaining access to personal accounts,” FBI officials said. Deepfakes use AI to mimic the voice and speaking characteristics of a specific individual. The differences between the authentic and simulated speakers are often indistinguishable without trained analysis. Deepfake videos work similarly.
One way to gain access to targets’ devices is for the attacker to ask if the conversation can be continued on a separate messaging platform and then successfully convince the target to click on a malicious link under the guise that it will enable the alternate platform. The advisory provided no additional details about the campaign.
The advisory comes amid a rise in reports of deepfaked audio and sometimes video used in fraud and espionage campaigns. Last year, password manager LastPass warned that it had been targeted in a sophisticated phishing campaign that used a combination of email, text messages, and voice calls to trick targets into divulging their master passwords. One part of the campaign included targeting a LastPass employee with a deepfake audio call that impersonated company CEO Karim Toubba.
In a separate incident last year, a robocall campaign that encouraged New Hampshire Democrats to sit out the coming election used a deepfake of then-President Joe Biden’s voice. A Democratic consultant was later indicted in connection with the calls. The telco that transmitted the spoofed robocalls also agreed to pay a $1 million civil penalty for not authenticating the caller as required by FCC rules.
The police operation resulted in the seizure of computers, mobile phones, and about $25,756 in suspected proceeds and luxury watches from the syndicate’s headquarters. Police said that victims originated from multiple countries, including Hong Kong, mainland China, Taiwan, India, and Singapore.
A widening real-time deepfake problem
Realtime deepfakes have become a growing problem over the past year. In August, we covered a free app called Deep-Live-Cam that can do real-time face-swaps for video chat use, and in February, the Hong Kong office of British engineering firm Arup lost $25 million in an AI-powered scam in which the perpetrators used deepfakes of senior management during a video conference call to trick an employee into transferring money.
News of the scam also comes amid recent warnings from the United Nations Office on Drugs and Crime, notes The Record in a report about the recent scam ring. The agency released a report last week highlighting tech advancements among organized crime syndicates in Asia, specifically mentioning the increasing use of deepfake technology in fraud.
The UN agency identified more than 10 deepfake software providers selling their services on Telegram to criminal groups in Southeast Asia, showing the growing accessibility of this technology for illegal purposes.
Some companies are attempting to find automated solutions to the issues presented by AI-powered crime, including Reality Defender, which creates software that attempts to detect deepfakes in real time. Some deepfake detection techniques may work at the moment, but as the fakes improve in realism and sophistication, we may be looking at an escalating arms race between those who seek to fool others and those who want to prevent deception.
“Robotic humanoid animals with vaudeville costumes roam the streets collecting protection money in tokens”
“A basketball player in a haunted passenger train car with a basketball court, and he is playing against a team of ghosts”
“A herd of one million cats running on a hillside, aerial view”
“Video game footage of a dynamic 1990s third-person 3D platform game starring an anthropomorphic shark boy”
“A muscular barbarian breaking a CRT television set with a weapon, cinematic, 8K, studio lighting”
Limitations of video synthesis models
Overall, the Minimax video-01 results seen above feel fairly similar to Gen-3’s outputs, with some differences, like the lack of a celebrity filter on Will Smith (who sadly did not actually eat the spaghetti in our tests), and the more realistic cat hands and licking motion. Some results were far worse, like the one million cats and the Ars Technica reader.
The University of Michigan research team worried that their experiment posting AI-generated NCII on X may cross ethical lines.
They chose to conduct the study on X because they deduced it was “a platform where there would be no volunteer moderators and little impact on paid moderators, if any” viewed their AI-generated nude images.
X’s transparency report seems to suggest that most reported non-consensual nudity is actioned by human moderators, but researchers reported that their flagged content was never actioned without a DMCA takedown.
Since AI image generators are trained on real photos, researchers also took steps to ensure that AI-generated NCII in the study did not re-traumatize victims or depict real people who might stumble on the images on X.
“Each image was tested against a facial-recognition software platform and several reverse-image lookup services to verify it did not resemble any existing individual,” the study said. “Only images confirmed by all platforms to have no resemblance to individuals were selected for the study.”
These more “ethical” images were posted on X using popular hashtags like #porn, #hot, and #xxx, but their reach was limited to evade potential harm, researchers said.
“Our study may contribute to greater transparency in content moderation processes” related to NCII “and may prompt social media companies to invest additional efforts to combat deepfake” NCII, researchers said. “In the long run, we believe the benefits of this study far outweigh the risks.”
According to the researchers, X was given time to automatically detect and remove the content but failed to do so. It’s possible, the study suggested, that X’s decision to allow explicit content starting in June made it harder to detect NCII, as some experts had predicted.
To fix the problem, researchers suggested that both “greater platform accountability” and “legal mechanisms to ensure that accountability” are needed—as is much more research on other platforms’ mechanisms for removing NCII.
“A dedicated” NCII law “must clearly define victim-survivor rights and impose legal obligations on platforms to act swiftly in removing harmful content,” the study concluded.
In his complaint, Christopher Kohls—who is known as “Mr Reagan” on YouTube and X (formerly Twitter)—said that he was suing “to defend all Americans’ right to satirize politicians.” He claimed that California laws, AB 2655 and AB 2839, were urgently passed after X owner Elon Musk shared a partly AI-generated parody video on the social media platform that Kohls created to “lampoon” presidential hopeful Kamala Harris.
AB 2655, known as the “Defending Democracy from Deepfake Deception Act,” prohibits creating “with actual malice” any “materially deceptive audio or visual media of a candidate for elective office with the intent to injure the candidate’s reputation or to deceive a voter into voting for or against the candidate, within 60 days of the election.” It requires social media platforms to block or remove any reported deceptive material and label “certain additional content” deemed “inauthentic, fake, or false” to prevent election interference.
The other law at issue, AB 2839, titled “Elections: deceptive media in advertisements,” bans anyone from “knowingly distributing an advertisement or other election communication” with “malice” that “contains certain materially deceptive content” within 120 days of an election in California and, in some cases, within 60 days after an election.
Both bills were signed into law on September 17, and Kohls filed his complaint that day, alleging that both must be permanently blocked as unconstitutional.
Elon Musk called out for boosting Kohls’ video
Kohls’ video that Musk shared seemingly would violate these laws by using AI to make Harris appear to give speeches that she never gave. The manipulated audio sounds like Harris, who appears to be mocking herself as a “diversity hire” and claiming that any critics must be “sexist and racist.”
“Making fun of presidential candidates and other public figures is an American pastime,” Kohls said, defending his parody video. He pointed to a long history of political cartoons and comedic impressions of politicians, claiming that “AI-generated commentary, though a new mode of speech, falls squarely within this tradition.”
While Kohls’ post was clearly marked “parody” in the YouTube title and in his post on X, that “parody” label did not carry over when Musk re-posted the video. This lack of a parody label on Musk’s post—which got approximately 136 million views, roughly twice as many as Kohls’ post—set off California governor Gavin Newsom, who immediately blasted Musk’s post and vowed on X to make content like Kohls’ video “illegal.”
In response to Newsom, Musk poked fun at the governor, posting that “I checked with renowned world authority, Professor Suggon Deeznutz, and he said parody is legal in America.” For his part, Kohls put up a second parody video targeting Harris, calling Newsom a “bully” in his complaint and claiming that he had to “punch back.”
Shortly after these online exchanges, California lawmakers allegedly rushed to back the governor, Kohls’ complaint said. They allegedly amended the deepfake bills to ensure that Kohls’ video would be banned when the bills were signed into law, replacing a broad exception for satire in one law with a narrower safe harbor that Kohls claimed would chill humorists everywhere.
“For videos,” his complaint said, disclaimers required under AB 2839 must “appear for the duration of the video” and “must be in a font size ‘no smaller than the largest font size of other text appearing in the visual media.'” For a satirist like Kohls who uses large fonts to optimize videos for mobile, this “would require the disclaimer text to be so large that it could not fit on the screen,” his complaint said.
On top of seeming impractical, the disclaimers would “fundamentally” alter “the nature of his message” by removing the comedic effect for viewers by distracting from what allegedly makes the videos funny—”the juxtaposition of over-the-top statements by the AI-generated ‘narrator,’ contrasted with the seemingly earnest style of the video as if it were a genuine campaign ad,” Kohls’ complaint alleged.
Imagine watching Saturday Night Live with prominent disclaimers taking up your TV screen, his complaint suggested.
It’s possible that Kohls’ concerns about AB 2839 are unwarranted. Newsom spokesperson Izzy Gardon told Politico that Kohls’ parody label on X was good enough to clear him of liability under the law.
“Requiring them to use the word ‘parody’ on the actual video avoids further misleading the public as the video is shared across the platform,” Gardon said. “It’s unclear why this conservative activist is suing California. This new disclosure law for election misinformation isn’t any more onerous than laws already passed in other states, including Alabama.”
As the US moves toward criminalizing deepfakes—deceptive AI-generated audio, images, and videos that are increasingly hard to discern from authentic content online—tech companies have rushed to roll out tools to help everyone better detect AI content.
But efforts so far have been imperfect, and experts fear that social media platforms may not be ready to handle the ensuing AI chaos during major global elections in 2024—despite tech giants committing to making tools specifically to combat AI-fueled election disinformation. The best AI detection remains observant humans, who, by paying close attention to deepfakes, can pick up on flaws like AI-generated people with extra fingers or AI voices that speak without pausing for a breath.
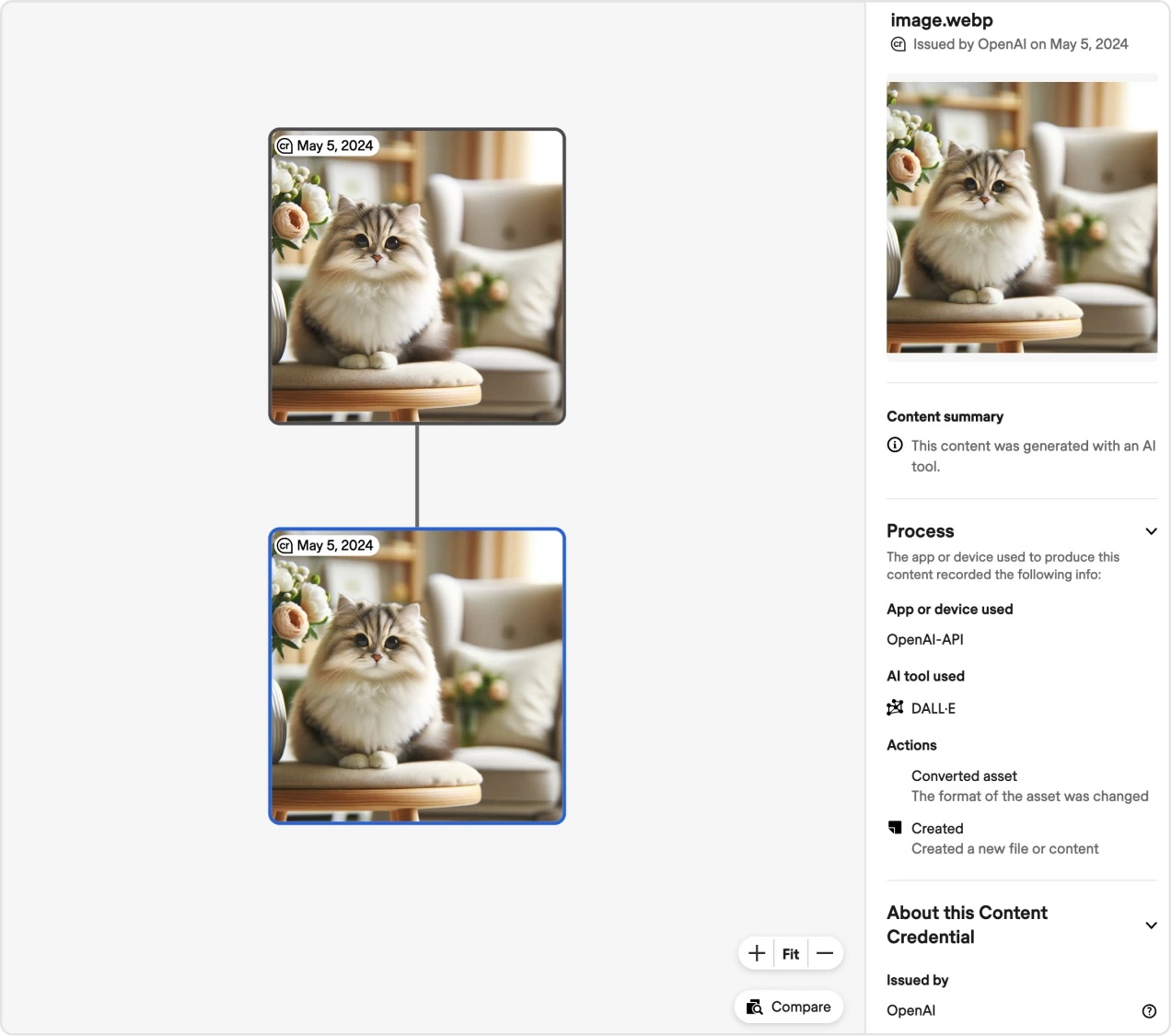
Among the splashiest tools announced this week, OpenAI shared details today about a new AI image detection classifier that it claims can detect about 98 percent of AI outputs from its own sophisticated image generator, DALL-E 3. It also “currently flags approximately 5 to 10 percent of images generated by other AI models,” OpenAI’s blog said.
According to OpenAI, the classifier provides a binary “true/false” response “indicating the likelihood of the image being AI-generated by DALL·E 3.” A screenshot of the tool shows how it can also be used to display a straightforward content summary confirming that “this content was generated with an AI tool” and includes fields ideally flagging the “app or device” and AI tool used.
To develop the tool, OpenAI spent months adding tamper-resistant metadata to “all images created and edited by DALL·E 3” that “can be used to prove the content comes” from “a particular source.” The detector reads this metadata to accurately flag DALL-E 3 images as fake.
That metadata follows “a widely used standard for digital content certification” set by the Coalition for Content Provenance and Authenticity (C2PA), often likened to a nutrition label. And reinforcing that standard has become “an important aspect” of OpenAI’s approach to AI detection beyond DALL-E 3, OpenAI said. When OpenAI broadly launches its video generator, Sora, C2PA metadata will be integrated into that tool as well, OpenAI said.
Of course, this solution is not comprehensive because that metadata could always be removed, and “people can still create deceptive content without this information (or can remove it),” OpenAI said, “but they cannot easily fake or alter this information, making it an important resource to build trust.”
Because OpenAI is all in on C2PA, the AI leader announced today that it would join the C2PA steering committee to help drive broader adoption of the standard. OpenAI will also launch a $2 million fund with Microsoft to support broader “AI education and understanding,” seemingly partly in the hopes that the more people understand about the importance of AI detection, the less likely they will be to remove this metadata.
“As adoption of the standard increases, this information can accompany content through its lifecycle of sharing, modification, and reuse,” OpenAI said. “Over time, we believe this kind of metadata will be something people come to expect, filling a crucial gap in digital content authenticity practices.”
OpenAI joining the committee “marks a significant milestone for the C2PA and will help advance the coalition’s mission to increase transparency around digital media as AI-generated content becomes more prevalent,” C2PA said in a blog.
Enlarge/ Snapshots from three videos generated using OpenAI’s Sora.
On Thursday, OpenAI announced Sora, a text-to-video AI model that can generate 60-second-long photorealistic HD video from written descriptions. While it’s only a research preview that we have not tested, it reportedly creates synthetic video (but not audio yet) at a fidelity and consistency greater than any text-to-video model available at the moment. It’s also freaking people out.
“It was nice knowing you all. Please tell your grandchildren about my videos and the lengths we went to to actually record them,” wrote Wall Street Journal tech reporter Joanna Stern on X.
“This could be the ‘holy shit’ moment of AI,” wrote Tom Warren of The Verge.
“Every single one of these videos is AI-generated, and if this doesn’t concern you at least a little bit, nothing will,” tweeted YouTube tech journalist Marques Brownlee.
For future reference—since this type of panic will some day appear ridiculous—there’s a generation of people who grew up believing that photorealistic video must be created by cameras. When video was faked (say, for Hollywood films), it took a lot of time, money, and effort to do so, and the results weren’t perfect. That gave people a baseline level of comfort that what they were seeing remotely was likely to be true, or at least representative of some kind of underlying truth. Even when the kid jumped over the lava, there was at least a kid and a room.
The prompt that generated the video above: “A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors.“
Technology like Sora pulls the rug out from under that kind of media frame of reference. Very soon, every photorealistic video you see online could be 100 percent false in every way. Moreover, every historical video you see could also be false. How we confront that as a society and work around it while maintaining trust in remote communications is far beyond the scope of this article, but I tried my hand at offering some solutions back in 2020, when all of the tech we’re seeing now seemed like a distant fantasy to most people.
In that piece, I called the moment that truth and fiction in media become indistinguishable the “cultural singularity.” It appears that OpenAI is on track to bring that prediction to pass a bit sooner than we expected.
Prompt: Reflections in the window of a train traveling through the Tokyo suburbs.
OpenAI has found that, like other AI models that use the transformer architecture, Sora scales with available compute. Given far more powerful computers behind the scenes, AI video fidelity could improve considerably over time. In other words, this is the “worst” AI-generated video is ever going to look. There’s no synchronized sound yet, but that might be solved in future models.
How (we think) they pulled it off
AI video synthesis has progressed by leaps and bounds over the past two years. We first covered text-to-video models in September 2022 with Meta’s Make-A-Video. A month later, Google showed off Imagen Video. And just 11 months ago, an AI-generated version of Will Smith eating spaghetti went viral. In May of last year, what was previously considered to be the front-runner in the text-to-video space, Runway Gen-2, helped craft a fake beer commercial full of twisted monstrosities, generated in two-second increments. In earlier video-generation models, people pop in and out of reality with ease, limbs flow together like pasta, and physics doesn’t seem to matter.
Sora (which means “sky” in Japanese) appears to be something altogether different. It’s high-resolution (1920×1080), can generate video with temporal consistency (maintaining the same subject over time) that lasts up to 60 seconds, and appears to follow text prompts with a great deal of fidelity. So, how did OpenAI pull it off?
OpenAI doesn’t usually share insider technical details with the press, so we’re left to speculate based on theories from experts and information given to the public.
OpenAI says that Sora is a diffusion model, much like DALL-E 3 and Stable Diffusion. It generates a video by starting off with noise and “gradually transforms it by removing the noise over many steps,” the company explains. It “recognizes” objects and concepts listed in the written prompt and pulls them out of the noise, so to speak, until a coherent series of video frames emerge.
Sora is capable of generating videos all at once from a text prompt, extending existing videos, or generating videos from still images. It achieves temporal consistency by giving the model “foresight” of many frames at once, as OpenAI calls it, solving the problem of ensuring a generated subject remains the same even if it falls out of view temporarily.
OpenAI represents video as collections of smaller groups of data called “patches,” which the company says are similar to tokens (fragments of a word) in GPT-4. “By unifying how we represent data, we can train diffusion transformers on a wider range of visual data than was possible before, spanning different durations, resolutions, and aspect ratios,” the company writes.
An important tool in OpenAI’s bag of tricks is that its use of AI models is compounding. Earlier models are helping to create more complex ones. Sora follows prompts well because, like DALL-E 3, it utilizes synthetic captions that describe scenes in the training data generated by another AI model like GPT-4V. And the company is not stopping here. “Sora serves as a foundation for models that can understand and simulate the real world,” OpenAI writes, “a capability we believe will be an important milestone for achieving AGI.”
One question on many people’s minds is what data OpenAI used to train Sora. OpenAI has not revealed its dataset, but based on what people are seeing in the results, it’s possible OpenAI is using synthetic video data generated in a video game engine in addition to sources of real video (say, scraped from YouTube or licensed from stock video libraries). Nvidia’s Dr. Jim Fan, who is a specialist in training AI with synthetic data, wrote on X, “I won’t be surprised if Sora is trained on lots of synthetic data using Unreal Engine 5. It has to be!” Until confirmed by OpenAI, however, that’s just speculation.
Explicit, fake AI-generated images sexualizing Taylor Swift began circulating online this week, quickly sparking mass outrage that may finally force a mainstream reckoning with harms caused by spreading non-consensual deepfake pornography.
A wide variety of deepfakes targeting Swift began spreading on X, the platform formerly known as Twitter, yesterday.
Ars found that some posts have been removed, while others remain online, as of this writing. One X post was viewed more than 45 million times over approximately 17 hours before it was removed, The Verge reported. Seemingly fueling more spread, X promoted these posts under the trending topic “Taylor Swift AI” in some regions, The Verge reported.
The Verge noted that since these images started spreading, “a deluge of new graphic fakes have since appeared.” According to Fast Company, these harmful images were posted on X but soon spread to other platforms, including Reddit, Facebook, and Instagram. Some platforms, like X, ban sharing of AI-generated images but seem to struggle with detecting banned content before it becomes widely viewed.
Ars’ AI reporter Benj Edwards warned in 2022 that AI image-generation technology was rapidly advancing, making it easy to train an AI model on just a handful of photos before it could be used to create fake but convincing images of that person in infinite quantities. That is seemingly what happened to Swift, and it’s currently unknown how many different non-consensual deepfakes have been generated or how widely those images have spread.
It’s also unknown what consequences have resulted from spreading the images. At least one verified X user had their account suspended after sharing fake images of Swift, The Verge reported, but Ars reviewed posts on X from Swift fans targeting others who allegedly shared images whose accounts remain active. Swift fans also have been uploading countless favorite photos of Swift to bury the harmful images and prevent them from appearing in various X searches. Her fans seem dedicated to reducing the spread however they can, with some posting different addresses, seemingly in attempts to dox an X user who, they’ve alleged, is the initial source of the images.
Neither X nor Swift’s team has yet commented on the deepfakes, but it seems clear that solving the problem will require more than just requesting removals from social media platforms. The AI model trained on Swift’s images is likely still out there, likely procured through one of the known websites that specialize in making fine-tuned celebrity AI models. As long as the model exists, anyone with access could crank out as many new images as they wanted, making it hard for even someone with Swift’s resources to make the problem go away for good.
In that way, Swift’s predicament might raise awareness of why creating and sharing non-consensual deepfake pornography is harmful, perhaps moving the culture away from persistent notions that nobody is harmed by non-consensual AI-generated fakes.
Swift’s plight could also inspire regulators to act faster to combat non-consensual deepfake porn. Last year, she inspired a Senate hearing after a Live Nation scandal frustrated her fans, triggering lawmakers’ antitrust concerns about the leading ticket seller, The New York Times reported.
Some lawmakers are already working to combat deepfake porn. Congressman Joe Morelle (D-NY) proposed a law criminalizing deepfake porn earlier this year after teen boys at a New Jersey high school used AI image generators to create and share non-consensual fake nude images of female classmates. Under that proposed law, anyone sharing deepfake pornography without an individual’s consent risks fines and being imprisoned for up to two years. Damages could go as high as $150,000 and imprisonment for as long as 10 years if sharing the images facilitates violence or impacts the proceedings of a government agency.
Elsewhere, the UK’s Online Safety Act restricts any illegal content from being shared on platforms, including deepfake pornography. It requires moderation, or companies will risk fines worth more than $20 million, or 10 percent of their global annual turnover, whichever amount is higher.
The UK law, however, is controversial because it requires companies to scan private messages for illegal content. That makes it practically impossible for platforms to provide end-to-end encryption, which the American Civil Liberties Union has described as vital for user privacy and security.
As regulators tangle with legal questions and social media users with moral ones, some AI image generators have moved to limit models from producing NSFW outputs. Some did this by removing some of the large quantity of sexualized images in the models’ training data, such as Stability AI, the company behind Stable Diffusion. Others, like Microsoft’s Bing image creator, make it easy for users to report NSFW outputs.
But so far, keeping up with reports of deepfake porn seems to fall squarely on social media platforms’ shoulders. Swift’s battle this week shows how unprepared even the biggest platforms currently are to handle blitzes of harmful images seemingly uploaded faster than they can be removed.









{kind=link}