An AI-generated version of OpenAI CEO Sam Altman seen in a still capture from a video generated by Sora 2. Credit: OpenAI
Under the new agreement with Disney, Sora users will be able to generate short videos using characters such as Mickey Mouse, Darth Vader, Iron Man, Simba, and characters from franchises including Frozen, Inside Out, Toy Story, and The Mandalorian, along with costumes, props, vehicles, and environments.
The ChatGPT image generator will also gain official access to the same intellectual property, although that information was trained into these AI models long ago. What’s changing is that OpenAI will allow Disney-related content generated by its AI models to officially pass through its content moderation filters and reach the user, sanctioned by Disney.
On Disney’s end of the deal, the company plans to deploy ChatGPT for its employees and use OpenAI’s technology to build new features for Disney+. A curated selection of fan-made Sora videos will stream on the Disney+ platform starting in early 2026.
The agreement does not include any talent likenesses or voices. Disney and OpenAI said they have committed to “maintaining robust controls to prevent the generation of illegal or harmful content” and to “respect the rights of individuals to appropriately control the use of their voice and likeness.”
OpenAI CEO Sam Altman called the deal a model for collaboration between AI companies and studios. “This agreement shows how AI companies and creative leaders can work together responsibly to promote innovation that benefits society, respect the importance of creativity, and help works reach vast new audiences,” Altman said.
From adversary to partner
Money opens all kinds of doors, and the new partnership represents a dramatic reversal in Disney’s approach to OpenAI from just a few months ago. At that time, Disney and other major studios refused to participate in Sora 2 following its launch on September 30.
On Tuesday, OpenAI announced Sora 2, its second-generation video-synthesis AI model that can now generate videos in various styles with synchronized dialogue and sound effects, which is a first for the company. OpenAI also launched a new iOS social app that allows users to insert themselves into AI-generated videos through what OpenAI calls “cameos.”
OpenAI showcased the new model in an AI-generated video that features a photorealistic version of OpenAI CEO Sam Altman talking to the camera in a slightly unnatural-sounding voice amid fantastical backdrops, like a competitive ride-on duck race and a glowing mushroom garden.
Regarding that voice, the new model can create what OpenAI calls “sophisticated background soundscapes, speech, and sound effects with a high degree of realism.” In May, Google’s Veo 3 became the first video-synthesis model from a major AI lab to generate synchronized audio as well as video. Just a few days ago, Alibaba released Wan 2.5, an open-weights video model that can generate audio as well. Now OpenAI has joined the audio party with Sora 2.
OpenAI demonstrates Sora 2’s capabilities in a launch video.
The model also features notable visual consistency improvements over OpenAI’s previous video model, and it can also follow more complex instructions across multiple shots while maintaining coherency between them. The new model represents what OpenAI describes as its “GPT-3.5 moment for video,” comparing it to the ChatGPT breakthrough during the evolution of its text-generation models over time.
Sora 2 appears to demonstrate improved physical accuracy over the original Sora model from February 2024, with OpenAI claiming the model can now simulate complex physical movements like Olympic gymnastics routines and triple axels while maintaining realistic physics. Last year, shortly after the launch of Sora 1 Turbo, we saw several notable failures of similar video-generation tasks that OpenAI claims to have addressed with the new model.
“Prior video models are overoptimistic—they will morph objects and deform reality to successfully execute upon a text prompt,” OpenAI wrote in its announcement. “For example, if a basketball player misses a shot, the ball may spontaneously teleport to the hoop. In Sora 2, if a basketball player misses a shot, it will rebound off the backboard.”
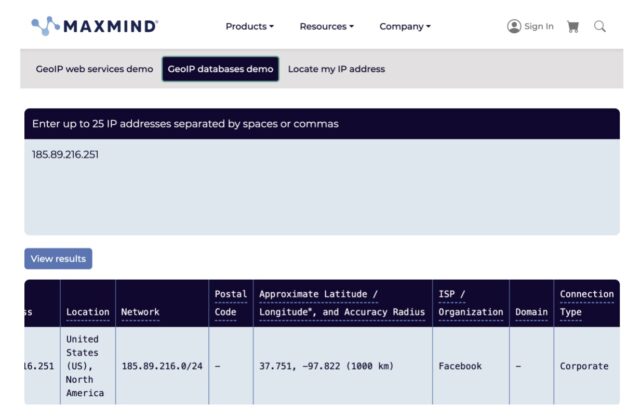
Seeking evidence to back its own copyright infringement claims, Strike 3 Holdings searched “its archive of recorded infringement captured by its VXN Scan and Cross Reference tools” and found 47 “IP addresses identified as owned by Facebook infringing its copyright protected Works.”
The data allegedly demonstrates a “continued unauthorized distribution” over “several years.” And Meta allegedly did not stop its seeding after Strike 3 Holdings confronted the tech giant with this evidence—despite the IP data supposedly being verified through an industry-leading provider called Maxmind.
Strike 3 Holdings shared a screenshot of MaxMind’s findings. Credit: via Strike 3 Holdings’ complaint
Meta also allegedly attempted to “conceal its BitTorrent activities” through “six Virtual Private Clouds” that formed a “stealth network” of “hidden IP addresses,” the lawsuit alleged, which seemingly implicated a “major third-party data center provider” as a partner in Meta’s piracy.
An analysis of these IP addresses allegedly found “data patterns that matched infringement patterns seen on Meta’s corporate IP Addresses” and included “evidence of other activity on the BitTorrent network including ebooks, movies, television shows, music, and software.” The seemingly non-human patterns documented on both sets of IP addresses suggest the data was for AI training and not for personal use, Strike 3 Holdings alleged.
Perhaps most shockingly, considering that a Meta employee joked “torrenting from a corporate laptop doesn’t feel right,” Strike 3 Holdings further alleged that it found “at least one residential IP address of a Meta employee” infringing its copyrighted works. That suggests Meta may have directed an employee to torrent pirated data outside the office to obscure the data trail.
The adult site operator did not identify the employee or the major data center discussed in its complaint, noting in a subsequent filing that it recognized the risks to Meta’s business and its employees’ privacy of sharing sensitive information.
In total, the company alleged that evidence shows “well over 100,000 unauthorized distribution transactions” linked to Meta’s corporate IPs. Strike 3 Holdings is hoping the evidence will lead a jury to find Meta liable for direct copyright infringement or charge Meta with secondary and vicarious copyright infringement if the jury finds that Meta successfully distanced itself by using the third-party data center or an employee’s home IP address.
“Meta has the right and ability to supervise and/or control its own corporate IP addresses, as well as the IP addresses hosted in off-infra data centers, and the acts of its employees and agents infringing Plaintiffs’ Works through their residential IPs by using Meta’s AI script to obtain content through BitTorrent,” the complaint said.
Google’s Veo 3 delivers AI videos of realistic people with sound and music. We put it to the test.
Still image from an AI-generated Veo 3 video of “A 1980s fitness video with models in leotards wearing werewolf masks.” Credit: Google
Last week, Google introduced Veo 3, its newest video generation model that can create 8-second clips with synchronized sound effects and audio dialog—a first for the company’s AI tools. The model, which generates videos at 720p resolution (based on text descriptions called “prompts” or still image inputs), represents what may be the most capable consumer video generator to date, bringing video synthesis close to a point where it is becoming very difficult to distinguish between “authentic” and AI-generated media.
Google also launched Flow, an online AI filmmaking tool that combines Veo 3 with the company’s Imagen 4 image generator and Gemini language model, allowing creators to describe scenes in natural language and manage characters, locations, and visual styles in a web interface.
An AI-generated video from Veo 3: “ASMR scene of a woman whispering “Moonshark” into a microphone while shaking a tambourine”
Both tools are now available to US subscribers of Google AI Ultra, a plan that costs $250 a month and comes with 12,500 credits. Veo 3 videos cost 150 credits per generation, allowing 83 videos on that plan before you run out. Extra credits are available for the price of 1 cent per credit in blocks of $25, $50, or $200. That comes out to about $1.50 per video generation. But is the price worth it? We ran some tests with various prompts to see what this technology is truly capable of.
How does Veo work?
Like other modern video generation models, Veo 3 is built on diffusion technology—the same approach that powers image generators like Stable Diffusion and Flux. The training process works by taking real videos and progressively adding noise to them until they become pure static, then teaching a neural network to reverse this process step by step. During generation, Veo 3 starts with random noise and a text prompt, then iteratively refines that noise into a coherent video that matches the description.
AI-generated video from Veo 3: “An old professor in front of a class says, ‘Without a firm historical context, we are looking at the dawn of a new era of civilization: post-history.'”
DeepMind won’t say exactly where it sourced the content to train Veo 3, but YouTube is a strong possibility. Google owns YouTube, and DeepMind previously told TechCrunch that Google models like Veo “may” be trained on some YouTube material.
It’s important to note that Veo 3 is a system composed of a series of AI models, including a large language model (LLM) to interpret user prompts to assist with detailed video creation, a video diffusion model to create the video, and an audio generation model that applies sound to the video.
An AI-generated video from Veo 3: “A male stand-up comic on stage in a night club telling a hilarious joke about AI and crypto with a silly punchline.” An AI language model built into Veo 3 wrote the joke.
In an attempt to prevent misuse, DeepMind says it’s using its proprietary watermarking technology, SynthID, to embed invisible markers into frames Veo 3 generates. These watermarks persist even when videos are compressed or edited, helping people potentially identify AI-generated content. As we’ll discuss more later, though, this may not be enough to prevent deception.
Google also censors certain prompts and outputs that breach the company’s content agreement. During testing, we encountered “generation failure” messages for videos that involve romantic and sexual material, some types of violence, mentions of certain trademarked or copyrighted media properties, some company names, certain celebrities, and some historical events.
Putting Veo 3 to the test
Perhaps the biggest change with Veo 3 is integrated audio generation, although Meta previewed a similar audio-generation capability with “Movie Gen” last October, and AI researchers have experimented with using AI to add soundtracks to silent videos for some time. Google DeepMind itself showed off an AI soundtrack-generating model in June 2024.
An AI-generated video from Veo 3: “A middle-aged balding man rapping indie core about Atari, IBM, TRS-80, Commodore, VIC-20, Atari 800, NES, VCS, Tandy 100, Coleco, Timex-Sinclair, Texas Instruments”
Veo 3 can generate everything from traffic sounds to music and character dialogue, though our early testing reveals occasional glitches. Spaghetti makes crunching sounds when eaten (as we covered last week, with a nod to the famous Will Smith AI spaghetti video), and in scenes with multiple people, dialogue sometimes comes from the wrong character’s mouth. But overall, Veo 3 feels like a step change in video synthesis quality and coherency over models from OpenAI, Runway, Minimax, Pika, Meta, Kling, and Hunyuanvideo.
The videos also tend to show garbled subtitles that almost match the spoken words, which is an artifact of subtitles on videos present in the training data. The AI model is imitating what it has “seen” before.
An AI-generated video from Veo 3: “A beer commercial for ‘CATNIP’ beer featuring a real a cat in a pickup truck driving down a dusty dirt road in a trucker hat drinking a can of beer while country music plays in the background, a man sings a jingle ‘Catnip beeeeeeeeeeeeeeeeer’ holding the note for 6 seconds”
We generated each of the eight-second-long 720p videos seen below using Google’s Flow platform. Each video generation took around three to five minutes to complete, and we paid for them ourselves. It’s important to note that better results come from cherry-picking—running the same prompt multiple times until you find a good result. Due to cost and in the spirit of testing, we only ran every prompt once, unless noted.
New audio prompts
Let’s dive right into the deep end with audio generation to get a grip on what this technology can do. We’ve previously shown you a man singing about spaghetti and a rapping shark in our last Veo 3 piece, but here’s some more complex dialogue.
Since 2022, we’ve been using the prompt “a muscular barbarian with weapons beside a CRT television set, cinematic, 8K, studio lighting” to test AI image generators like Midjourney. It’s time to bring that barbarian to life.
A muscular barbarian man holding an axe, standing next to a CRT television set. He looks at the TV, then to the camera and literally says, “You’ve been looking for this for years: a muscular barbarian with weapons beside a CRT television set, cinematic, 8K, studio lighting. Got that, Benj?”
The video above represents significant technical progress in AI media synthesis over the course of only three years. We’ve gone from a blurry colorful still-image barbarian to a photorealistic guy that talks to us in 720p high definition with audio. Most notably, there’s no reason to believe technical capability in AI generation will slow down from here.
Horror film: A scared woman in a Victorian outfit running through a forest, dolly shot, being chased by a man in a peanut costume screaming, “Wait! You forgot your wallet!”
Trailer for The Haunted Basketball Train: a Tim Burton film where 1990s basketball star is stuck at the end of a haunted passenger train with basketball court cars, and the only way to survive is to make it to the engine by beating different ghosts at basketball in every car
ASMR video of a muscular barbarian man whispering slowly into a microphone, “You love CRTs, don’t you? That’s OK. It’s OK to love CRT televisions and barbarians.”
1980s PBS show about a man with a beard talking about how his Apple II computer can “connect to the world through a series of tubes”
A 1980s fitness video with models in leotards wearing werewolf masks
A female therapist looking at the camera, zoom call. She says, “Oh my lord, look at that Atari 800 you have behind you! I can’t believe how nice it is!”
With this technology, one can easily imagine a virtual world of AI personalities designed to flatter people. This is a fairly innocent example about a vintage computer, but you can extrapolate, making the fake person talk about any topic at all. There are limits due to Google’s filters, but from what we’ve seen in the past, a future uncensored version of a similarly capable AI video generator is very likely.
Video call screenshot capture of a Zoom chat. A psychologist in a dark, cozy therapist’s office. The therapist says in a friendly voice, “Hi Tom, thanks for calling. Tell me about how you’re feeling today. Is the depression still getting to you? Let’s work on that.”
1960s NASA footage of the first man stepping onto the surface of the Moon, who squishes into a pile of mud and yells in a hillbilly voice, “What in tarnation??”
A local TV news interview of a muscular barbarian talking about why he’s always carrying a CRT TV set around with him
Speaking of fake news interviews, Veo 3 can generate plenty of talking anchor-persons, although sometimes on-screen text is garbled if you don’t specify exactly what it should say. It’s in cases like this where it seems Veo 3 might be most potent at casual media deception.
Footage from a news report about Russia invading the United States
Attempts at music
Veo 3’s AI audio generator can create music in various genres, although in practice, the results are typically simplistic. Still, it’s a new capability for AI video generators. Here are a few examples in various musical genres.
A PBS show of a crazy barbarian with a blonde afro painting pictures of Trees, singing “HAPPY BIG TREES” to some music while he paints
A 1950s cowboy rides up to the camera and sings in country music, “I love mah biiig ooold donkeee”
A 1980s hair metal band drives up to the camera and sings in rock music, “Help me with my huge huge huge hair!”
Mister Rogers’ Neighborhood PBS kids show intro done with psychedelic acid rock and colored lights
1950s musical jazz group with a scat singer singing about pickles amid gibberish
A trip-hop rap song about Ars Technica being sung by a guy in a large rubber shark costume on a stage with a full moon in the background
Some classic prompts from prior tests
The prompts below come from our previous video tests of Gen-3, Video-01, and the open source Hunyuanvideo, so you can flip back to those articles and compare the results if you want to. Overall, Veo 3 appears to have far greater temporal coherency (having a consistent subject or theme over time) than the earlier video synthesis models we’ve tested. But of course, it’s not perfect.
A highly intelligent person reading ‘Ars Technica’ on their computer when the screen explodes
The moonshark jumping out of a computer screen and attacking a person
A herd of one million cats running on a hillside, aerial view
Video game footage of a dynamic 1990s third-person 3D platform game starring an anthropomorphic shark boy
Aerial shot of a small American town getting deluged with liquid cheese after a massive cheese rainstorm where liquid cheese rained down and dripped all over the buildings
Wide-angle shot, starting with the Sasquatch at the center of the stage giving a TED talk about mushrooms, then slowly zooming in to capture its expressive face and gestures, before panning to the attentive audience
Some notable failures
Google’s Veo 3 isn’t perfect at synthesizing every scenario we can throw at it due to limitations of training data. As we noted in our previous coverage, AI video generators remain fundamentally imitative, making predictions based on statistical patterns rather than a true understanding of physics or how the world works.
For example, if you see mouths moving during speech, or clothes wrinkling in a certain way when touched, it means the neural network doing the video generation has “seen” enough similar examples of that scenario in the training data to render a convincing take on it and apply it to similar situations.
However, when a novel situation (or combination of themes) isn’t well-represented in the training data, you’ll see “impossible” or illogical things happen, such as weird body parts, magically appearing clothing, or an object that “shatters” but remains in the scene afterward, as you’ll see below.
We mentioned audio and video glitches in the introduction. In particular, scenes with multiple people sometimes confuse which character is speaking, such as this argument between tech fans.
A 2000s TV debate between fans of the PowerPC and Intel Pentium chips
Bombastic 1980s infomercial for the “Ars Technica” online service. With cheesy background music and user testimonials
1980s Rambo fighting Soviets on the Moon
Sometimes requests don’t make coherent sense. In this case, “Rambo” is correctly on the Moon firing a gun, but he’s not wearing a spacesuit. He’s a lot tougher than we thought.
An animated infographic showing how many floppy disks it would take to hold an installation of Windows 11
Large amounts of text also present a weak point, but if a short text quotation is explicitly specified in the prompt, Veo 3 usually gets it right.
A young woman doing a complex floor gymnastics routine at the Olympics, featuring running and flips
Despite Veo 3’s advances in temporal coherency and audio generation, it still suffers from the same “jabberwockies” we saw in OpenAI’s viral Sora gymnast video—those non-plausible video hallucinations like impossible morphing body parts.
A silly group of men and women cartwheeling across the road, singing “CHEEEESE” and holding the note for 8 seconds before falling over.
A YouTube-style try-on video of a person trying on various corncob costumes. They shout “Corncob haul!!”
A man made of glass runs into a brick wall and shatters, screaming
A man in a spacesuit holding up 5 fingers and counting down to zero, then blasting off into space with rocket boots
Counting down with fingers is difficult for Veo 3, likely because it’s not well-represented in the training data. Instead, hands are likely usually shown in a few positions like a fist, a five-finger open palm, a two-finger peace sign, and the number one.
As new architectures emerge and future models train on vastly larger datasets with exponentially more compute, these systems will likely forge deeper statistical connections between the concepts they observe in videos, dramatically improving quality and also the ability to generalize more with novel prompts.
The “cultural singularity” is coming—what more is left to say?
By now, some of you might be worried that we’re in trouble as a society due to potential deception from this kind of technology. And there’s a good reason to worry: The American pop culture diet currently relies heavily on clips shared by strangers through social media such as TikTok, and now all of that can easily be faked, whole-cloth. Automated generations of fake people can now argue for ideological positions in a way that could manipulate the masses.
AI-generated video by Veo 3: “A man on the street interview about someone who fears they live in a time where nothing can be believed”
Such videos could be (and were) manipulated before through various means prior to Veo 3, but now the barrier to entry has collapsed from requiring specialized skills, expensive software, and hours of painstaking work to simply typing a prompt and waiting three minutes. What once required a team of VFX artists or at least someone proficient in After Effects can now be done by anyone with a credit card and an Internet connection.
But let’s take a moment to catch our breath. At Ars Technica, we’ve been warning about the deceptive potential of realistic AI-generated media since at least 2019. In 2022, we talked about AI image generator Stable Diffusion and the ability to train people into custom AI image models. We discussed Sora “collapsing media reality” and talked about persistent media skepticism during the “deep doubt era.”
AI-generated video with Veo 3: “A man on the street ranting about the ‘cultural singularity’ and the ‘cultural apocalypse’ due to AI”
I also wrote in detail about the future ability for people to pollute the historical record with AI-generated noise. In that piece, I used the term “cultural singularity” to denote a time when truth and fiction in media become indistinguishable, not only because of the deceptive nature of AI-generated content but also due to the massive quantities of AI-generated and AI-augmented media we’ll likely soon be inundated with.
However, in an article I wrote last year about cloning my dad’s handwriting using AI, I came to the conclusion that my previous fears about the cultural singularity may be overblown. Media has always been vulnerable to forgery since ancient times; trust in any remote communication ultimately depends on trusting its source.
AI-generated video with Veo 3: “A news set. There is an ‘Ars Technica News’ logo behind a man. The man has a beard and a suit and is doing a sit-down interview. He says “This is the age of post-history: a new epoch of civilization where the historical record is so full of fabrication that it becomes effectively meaningless.”
The Romans had laws against forgery in 80 BC, and people have been doctoring photos since the medium’s invention. What has changed isn’t the possibility of deception but its accessibility and scale.
With Veo 3’s ability to generate convincing video with synchronized dialogue and sound effects, we’re not witnessing the birth of media deception—we’re seeing its mass democratization. What once cost millions of dollars in Hollywood special effects can now be created for pocket change.
An AI-generated video created with Google Veo-3: “A candid interview of a woman who doesn’t believe anything she sees online unless it’s on Ars Technica.”
As these tools become more powerful and affordable, skepticism in media will grow. But the question isn’t whether we can trust what we see and hear. It’s whether we can trust who’s showing it to us. In an era where anyone can generate a realistic video of anything for $1.50, the credibility of the source becomes our primary anchor to truth. The medium was never the message—the messenger always was.
Benj Edwards is Ars Technica’s Senior AI Reporter and founder of the site’s dedicated AI beat in 2022. He’s also a tech historian with almost two decades of experience. In his free time, he writes and records music, collects vintage computers, and enjoys nature. He lives in Raleigh, NC.
On Tuesday, Google launched Veo 3, a new AI video synthesis model that can do something no major AI video generator has been able to do before: create a synchronized audio track. While from 2022 to 2024, we saw early steps in AI video generation, each video was silent and usually very short in duration. Now you can hear voices, dialog, and sound effects in eight-second high-definition video clips.
Shortly after the new launch, people began asking the most obvious benchmarking question: How good is Veo 3 at faking Oscar-winning actor Will Smith at eating spaghetti?
First, a brief recap. The spaghetti benchmark in AI video traces its origins back to March 2023, when we first covered an early example of horrific AI-generated video using an open source video synthesis model called ModelScope. The spaghetti example later became well-known enough that Smith parodied it almost a year later in February 2024.
Here’s what the original viral video looked like:
One thing people forget is that at the time, the Smith example wasn’t the best AI video generator out there—a video synthesis model called Gen-2 from Runway had already achieved superior results (though it was not yet publicly accessible). But the ModelScope result was funny and weird enough to stick in people’s memories as an early poor example of video synthesis, handy for future comparisons as AI models progressed.
AI app developer Javi Lopez first came to the rescue for curious spaghetti fans earlier this week with Veo 3, performing the Smith test and posting the results on X. But as you’ll notice below when you watch, the soundtrack has a curious quality: The faux Smith appears to be crunching on the spaghetti.
On X, Javi Lopez ran “Will Smith eating spaghetti” in Google’s Veo 3 AI video generator and received this result.
It’s a glitch in Veo 3’s experimental ability to apply sound effects to video, likely because the training data used to create Google’s AI models featured many examples of chewing mouths with crunching sound effects. Generative AI models are pattern-matching prediction machines, and they need to be shown enough examples of various types of media to generate convincing new outputs. If a concept is over-represented or under-represented in the training data, you’ll see unusual generation results, such as jabberwockies.
Google has announced that yet another AI model is coming to Gemini, but this time, it’s more than a chatbot. The company’s Veo 2 video generator is rolling out to the Gemini app and website, giving paying customers a chance to create short video clips with Google’s allegedly state-of-the-art video model.
Veo 2 works like other video generators, including OpenAI’s Sora—you input text describing the video you want, and a Google data center churns through tokens until it has an animation. Google claims that Veo 2 was designed to have a solid grasp of real-world physics, particularly the way humans move. Google’s examples do look good, but presumably that’s why they were chosen.
Prompt: Aerial shot of a grassy cliff onto a sandy beach where waves crash against the shore, a prominent sea stack rises from the ocean near the beach, bathed in the warm, golden light of either sunrise or sunset, capturing the serene beauty of the Pacific coastline.
Veo 2 will be available in the model drop-down, but Google does note it’s still considering ways to integrate this feature and that the location could therefore change. However, it’s probably not there at all just yet. Google is starting the rollout today, but it could take several weeks before all Gemini Advanced subscribers get access to Veo 2. Gemini features can take a surprisingly long time to arrive for the bulk of users—for example, it took about a month for Google to make Gemini Live video available to everyone after announcing its release.
When Veo 2 does pop up in your Gemini app, you can provide it with as much detail as you want, which Google says will ensure you have fine control over the eventual video. Veo 2 is currently limited to 8 seconds of 720p video, which you can download as a standard MP4 file. Video generation uses even more processing than your average generative AI feature, so Google has implemented a monthly limit. However, it hasn’t confirmed what that limit is, saying only that users will be notified as they approach it.
Nonsensical jabberwocky movements created by OpenAI’s Sora are typical for current AI-generated video, and here’s why.
A still image from an AI-generated video of an ever-morphing synthetic gymnast. Credit: OpenAI / Deedy
On Wednesday, a video from OpenAI’s newly launched Sora AI video generator wentviral on social media, featuring a gymnast who sprouts extra limbs and briefly loses her head during what appears to be an Olympic-style floor routine.
As it turns out, the nonsensical synthesis errors in the video—what we like to call “jabberwockies”—hint at technical details about how AI video generators work and how they might get better in the future.
But before we dig into the details, let’s take a look at the video.
An AI-generated video of an impossible gymnast, created with OpenAI Sora.
In the video, we see a view of what looks like a floor gymnastics routine. The subject of the video flips and flails as new legs and arms rapidly and fluidly emerge and morph out of her twirling and transforming body. At one point, about 9 seconds in, she loses her head, and it reattaches to her body spontaneously.
“As cool as the new Sora is, gymnastics is still very much the Turing test for AI video,” wrote venture capitalist Deedy Das when he originally shared the video on X. The video inspired plenty of reaction jokes, such as this reply to a similar post on Bluesky: “hi, gymnastics expert here! this is not funny, gymnasts only do this when they’re in extreme distress.”
We reached out to Das, and he confirmed that he generated the video using Sora. He also provided the prompt, which was very long and split into four parts, generated by Anthropic’s Claude, using complex instructions like “The gymnast initiates from the back right corner, taking position with her right foot pointed behind in B-plus stance.”
“I’ve known for the last 6 months having played with text to video models that they struggle with complex physics movements like gymnastics,” Das told us in a conversation. “I had to try it [in Sora] because the character consistency seemed improved. Overall, it was an improvement because previously… the gymnast would just teleport away or change their outfit mid flip, but overall it still looks downright horrifying. We hoped AI video would learn physics by default, but that hasn’t happened yet!”
So what went wrong?
When examining how the video fails, you must first consider how Sora “knows” how to create anything that resembles a gymnastics routine. During the training phase, when the Sora model was created, OpenAI fed example videos of gymnastics routines (among many other types of videos) into a specialized neural network that associates the progression of images with text-based descriptions of them.
That type of training is a distinct phase that happens once before the model’s release. Later, when the finished model is running and you give a video-synthesis model like Sora a written prompt, it draws upon statistical associations between words and images to produce a predictive output. It’s continuously making next-frame predictions based on the last frame of the video. But Sora has another trick for attempting to preserve coherency over time. “By giving the model foresight of many frames at a time,” reads OpenAI’s Sora System Card, we’ve solved a challenging problem of making sure a subject stays the same even when it goes out of view temporarily.”
A still image from a moment where the AI-generated gymnast loses her head. It soon reattaches to her body. Credit: OpenAI / Deedy
Maybe not quite solved yet. In this case, rapidly moving limbs prove a particular challenge when attempting to predict the next frame properly. The result is an incoherent amalgam of gymnastics footage that shows the same gymnast performing running flips and spins, but Sora doesn’t know the correct order in which to assemble them because it’s pulling on statistical averages of wildly different body movements in its relatively limited training data of gymnastics videos, which also likely did not include limb-level precision in its descriptive metadata.
Sora doesn’t know anything about physics or how the human body should work, either. It’s drawing upon statistical associations between pixels in the videos in its training dataset to predict the next frame, with a little bit of look-ahead to keep things more consistent.
This problem is not unique to Sora. All AI video generators can produce wildly nonsensical results when your prompts reach too far past their training data, as we saw earlier this year when testing Runway’s Gen-3. In fact, we ran some gymnast prompts through the latest open source AI video model that may rival Sora in some ways, Hunyuan Video, and it produced similar twirling, morphing results, seen below. And we used a much simpler prompt than Das did with Sora.
An example from open source Chinese AI model Hunyuan Video with the prompt, “A young woman doing a complex floor gymnastics routine at the olympics, featuring running and flips.”
AI models based on transformer technology are fundamentally imitative in nature. They’re great at transforming one type of data into another type or morphing one style into another. What they’re not great at (yet) is producing coherent generations that are truly original. So if you happen to provide a prompt that closely matches a training video, you might get a good result. Otherwise, you may get madness.
As we wrote about image-synthesis model Stable Diffusion 3’s body horror generations earlier this year, “Basically, any time a user prompt homes in on a concept that isn’t represented well in the AI model’s training dataset, the image-synthesis model will confabulate its best interpretation of what the user is asking for. And sometimes that can be completely terrifying.”
For the engineers who make these models, success in AI video generation quickly becomes a question of how many examples (and how much training) you need before the model can generalize enough to produce convincing and coherent results. It’s also a question of metadata quality—how accurately the videos are labeled. In this case, OpenAI used an AI vision model to describe its training videos, which helped improve quality, but apparently not enough—yet.
We’re looking at an AI jabberwocky in action
In a way, the type of generation failure in the gymnast video is a form of confabulation (or hallucination, as some call it), but it’s even worse because it’s not coherent. So instead of calling it a confabulation, which is a plausible-sounding fabrication, we’re going to lean on a new term, “jabberwocky,” which Dictionary.com defines as “a playful imitation of language consisting of invented, meaningless words; nonsense; gibberish,” taken from Lewis Carroll’s nonsense poem of the same name. Imitation and nonsense, you say? Check and check.
We’ve covered jabberwockies in AI video before with people mocking Chinese video-synthesis models, a monstrously weird AI beer commercial, and even Will Smith eating spaghetti. They’re a form of misconfabulation where an AI model completely fails to produce a plausible output. This will not be the last time we see them, either.
How could AI video models get better and avoid jabberwockies?
In our coverage of Gen-3 Alpha, we called the threshold where you get a level of useful generalization in an AI model the “illusion of understanding,” where training data and training time reach a critical mass that produces good enough results to generalize across enough novel prompts.
One of the key reasons language models like OpenAI’s GPT-4 impressed users was that they finally reached a size where they had absorbed enough information to give the appearance of genuinely understanding the world. With video synthesis, achieving this same apparent level of “understanding” will require not just massive amounts of well-labeled training data but also the computational power to process it effectively.
AI boosters hope that these current models represent one of the key steps on the way to something like truly general intelligence (often called AGI) in text, or in AI video, what OpenAI and Runway researchers call “world simulators” or “world models” that somehow encode enough physics rules about the world to produce any realistic result.
Judging by the morphing alien shoggoth gymnast, that may still be a ways off. Still, it’s early days in AI video generation, and judging by how quickly AI image-synthesis models like Midjourney progressed from crude abstract shapes into coherent imagery, it’s likely video synthesis will have a similar trajectory over time. Until then, enjoy the AI-generated jabberwocky madness.
Benj Edwards is Ars Technica’s Senior AI Reporter and founder of the site’s dedicated AI beat in 2022. He’s also a tech historian with almost two decades of experience. In his free time, he writes and records music, collects vintage computers, and enjoys nature. He lives in Raleigh, NC.
A music video by Canadian art collective Vallée Duhamel made with Sora-generated video. “[We] just shoot stuff and then use Sora to combine it with a more interesting, more surreal vision.”
During a livestream on Monday—during Day 3 of OpenAI’s “12 days of OpenAi”—Sora’s developers showcased a new “Explore” interface that allows people to browse through videos generated by others to get prompting ideas. OpenAI says that anyone can enjoy viewing the “Explore” feed for free, but generating videos requires a subscription.
They also showed off a new feature called “Storyboard” that allows users to direct a video with multiple actions in a frame-by-frame manner.
Safety measures and limitations
In addition to the release, OpenAI also publish Sora’s System Card for the first time. It includes technical details about how the model works and safety testing the company undertook prior to this release.
“Whereas LLMs have text tokens, Sora has visual patches,” OpenAI writes, describing the new training chunks as “an effective representation for models of visual data… At a high level, we turn videos into patches by first compressing videos into a lower-dimensional latent space, and subsequently decomposing the representation into spacetime patches.”
Sora also makes use of a “recaptioning technique”—similar to that seen in the company’s DALL-E 3 image generation, to “generate highly descriptive captions for the visual training data.” That, in turn, lets Sora “follow the user’s text instructions in the generated video more faithfully,” OpenAI writes.
Sora-generated video provided by OpenAI, from the prompt: “Loop: a golden retriever puppy wearing a superhero outfit complete with a mask and cape stands perched on the top of the empire state building in winter, overlooking the nyc it protects at night. the back of the pup is visible to the camera; his attention faced to nyc”
OpenAI implemented several safety measures in the release. The platform embeds C2PA metadata in all generated videos for identification and origin verification. Videos display visible watermarks by default, and OpenAI developed an internal search tool to verify Sora-generated content.
The company acknowledged technical limitations in the current release. “This early version of Sora will make mistakes, it’s not perfect,” said one developer during the livestream launch. The model reportedly struggles with physics simulations and complex actions over extended durations.
In the past, we’ve seen that these types of limitations are based on what example videos were used to train AI models. This current generation of AI video-synthesis models has difficulty generating truly new things, since the underlying architecture excels at transforming existing concepts into new presentations, but so far typically fails at true originality. Still, it’s early in AI video generation, and the technology is improving all the time.
On Monday, Adobe announced Firefly Video Model, a new AI-powered text-to-video generation tool that can create novel videos from written prompts. It joins similar offerings from OpenAI, Runway, Google, and Meta in an increasingly crowded field. Unlike the competition, Adobe claims that Firefly Video Model is trained exclusively on licensed content, potentially sidestepping ethical and copyright issues that have plagued other generative AI tools.
Because of its licensed training data roots, Adobe calls Firefly Video Model “the first publicly available video model designed to be commercially safe.” However, the San Jose, California-based software firm hasn’t announced a general release date, and during a beta test period, it’s only granting access to people on a waiting list.
An example video of Adobe’s Firefly Video Model, provided by Adobe.
In the works since at least April 2023, the new model builds off of techniques Adobe developed for its Firefly image synthesis models. Like its text-to-image generator, which the company later integrated into Photoshop, Adobe hopes to aim Firefly Video Model at media professionals, such as video creators and editors. The company claims its model can produce footage that blends seamlessly with traditionally created video content.
“Robotic humanoid animals with vaudeville costumes roam the streets collecting protection money in tokens”
“A basketball player in a haunted passenger train car with a basketball court, and he is playing against a team of ghosts”
“A herd of one million cats running on a hillside, aerial view”
“Video game footage of a dynamic 1990s third-person 3D platform game starring an anthropomorphic shark boy”
“A muscular barbarian breaking a CRT television set with a weapon, cinematic, 8K, studio lighting”
Limitations of video synthesis models
Overall, the Minimax video-01 results seen above feel fairly similar to Gen-3’s outputs, with some differences, like the lack of a celebrity filter on Will Smith (who sadly did not actually eat the spaghetti in our tests), and the more realistic cat hands and licking motion. Some results were far worse, like the one million cats and the Ars Technica reader.
As the US moves toward criminalizing deepfakes—deceptive AI-generated audio, images, and videos that are increasingly hard to discern from authentic content online—tech companies have rushed to roll out tools to help everyone better detect AI content.
But efforts so far have been imperfect, and experts fear that social media platforms may not be ready to handle the ensuing AI chaos during major global elections in 2024—despite tech giants committing to making tools specifically to combat AI-fueled election disinformation. The best AI detection remains observant humans, who, by paying close attention to deepfakes, can pick up on flaws like AI-generated people with extra fingers or AI voices that speak without pausing for a breath.
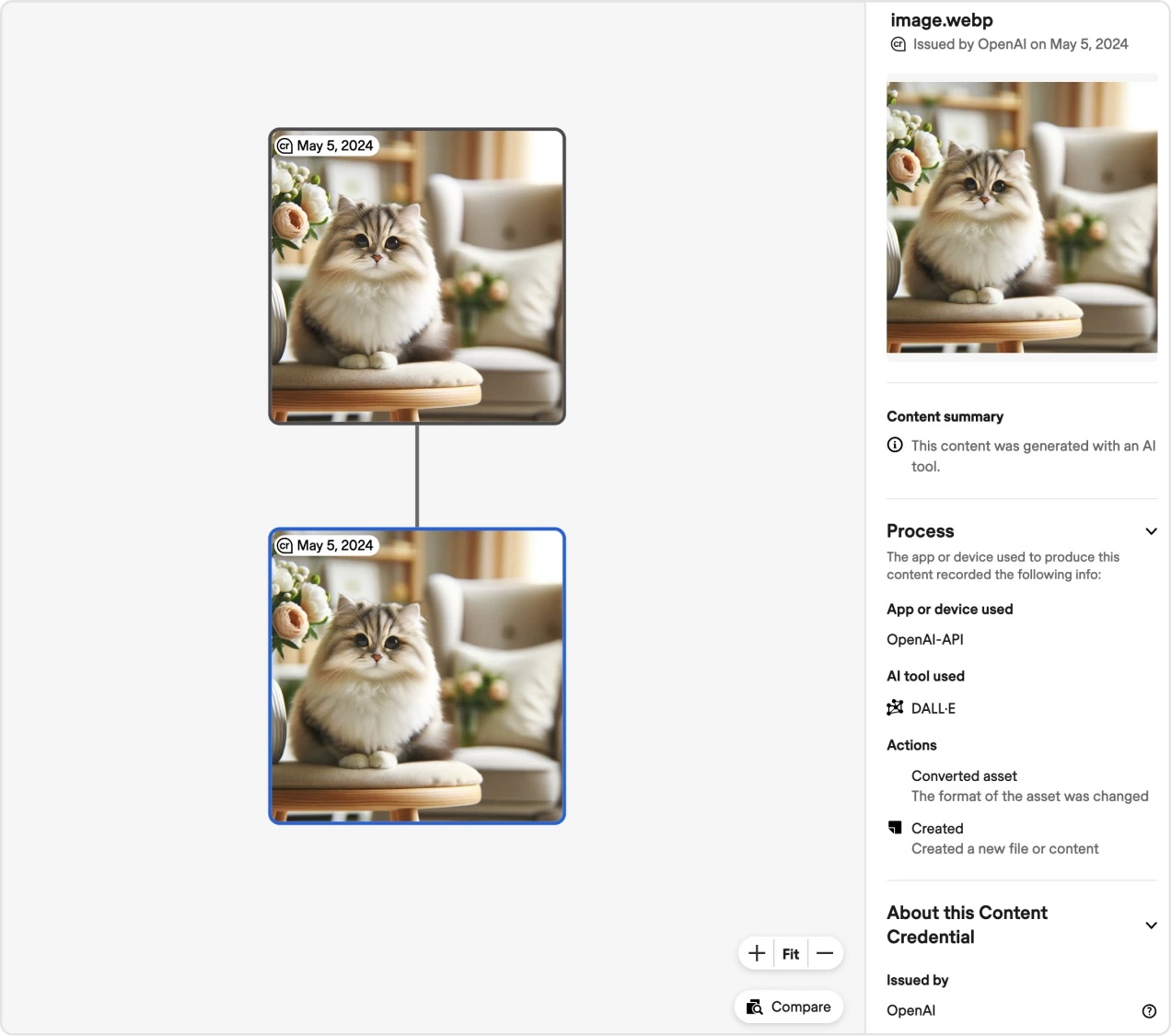
Among the splashiest tools announced this week, OpenAI shared details today about a new AI image detection classifier that it claims can detect about 98 percent of AI outputs from its own sophisticated image generator, DALL-E 3. It also “currently flags approximately 5 to 10 percent of images generated by other AI models,” OpenAI’s blog said.
According to OpenAI, the classifier provides a binary “true/false” response “indicating the likelihood of the image being AI-generated by DALL·E 3.” A screenshot of the tool shows how it can also be used to display a straightforward content summary confirming that “this content was generated with an AI tool” and includes fields ideally flagging the “app or device” and AI tool used.
To develop the tool, OpenAI spent months adding tamper-resistant metadata to “all images created and edited by DALL·E 3” that “can be used to prove the content comes” from “a particular source.” The detector reads this metadata to accurately flag DALL-E 3 images as fake.
That metadata follows “a widely used standard for digital content certification” set by the Coalition for Content Provenance and Authenticity (C2PA), often likened to a nutrition label. And reinforcing that standard has become “an important aspect” of OpenAI’s approach to AI detection beyond DALL-E 3, OpenAI said. When OpenAI broadly launches its video generator, Sora, C2PA metadata will be integrated into that tool as well, OpenAI said.
Of course, this solution is not comprehensive because that metadata could always be removed, and “people can still create deceptive content without this information (or can remove it),” OpenAI said, “but they cannot easily fake or alter this information, making it an important resource to build trust.”
Because OpenAI is all in on C2PA, the AI leader announced today that it would join the C2PA steering committee to help drive broader adoption of the standard. OpenAI will also launch a $2 million fund with Microsoft to support broader “AI education and understanding,” seemingly partly in the hopes that the more people understand about the importance of AI detection, the less likely they will be to remove this metadata.
“As adoption of the standard increases, this information can accompany content through its lifecycle of sharing, modification, and reuse,” OpenAI said. “Over time, we believe this kind of metadata will be something people come to expect, filling a crucial gap in digital content authenticity practices.”
OpenAI joining the committee “marks a significant milestone for the C2PA and will help advance the coalition’s mission to increase transparency around digital media as AI-generated content becomes more prevalent,” C2PA said in a blog.
Enlarge/ Snapshots from three videos generated using OpenAI’s Sora.
On Thursday, OpenAI announced Sora, a text-to-video AI model that can generate 60-second-long photorealistic HD video from written descriptions. While it’s only a research preview that we have not tested, it reportedly creates synthetic video (but not audio yet) at a fidelity and consistency greater than any text-to-video model available at the moment. It’s also freaking people out.
“It was nice knowing you all. Please tell your grandchildren about my videos and the lengths we went to to actually record them,” wrote Wall Street Journal tech reporter Joanna Stern on X.
“This could be the ‘holy shit’ moment of AI,” wrote Tom Warren of The Verge.
“Every single one of these videos is AI-generated, and if this doesn’t concern you at least a little bit, nothing will,” tweeted YouTube tech journalist Marques Brownlee.
For future reference—since this type of panic will some day appear ridiculous—there’s a generation of people who grew up believing that photorealistic video must be created by cameras. When video was faked (say, for Hollywood films), it took a lot of time, money, and effort to do so, and the results weren’t perfect. That gave people a baseline level of comfort that what they were seeing remotely was likely to be true, or at least representative of some kind of underlying truth. Even when the kid jumped over the lava, there was at least a kid and a room.
The prompt that generated the video above: “A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors.“
Technology like Sora pulls the rug out from under that kind of media frame of reference. Very soon, every photorealistic video you see online could be 100 percent false in every way. Moreover, every historical video you see could also be false. How we confront that as a society and work around it while maintaining trust in remote communications is far beyond the scope of this article, but I tried my hand at offering some solutions back in 2020, when all of the tech we’re seeing now seemed like a distant fantasy to most people.
In that piece, I called the moment that truth and fiction in media become indistinguishable the “cultural singularity.” It appears that OpenAI is on track to bring that prediction to pass a bit sooner than we expected.
Prompt: Reflections in the window of a train traveling through the Tokyo suburbs.
OpenAI has found that, like other AI models that use the transformer architecture, Sora scales with available compute. Given far more powerful computers behind the scenes, AI video fidelity could improve considerably over time. In other words, this is the “worst” AI-generated video is ever going to look. There’s no synchronized sound yet, but that might be solved in future models.
How (we think) they pulled it off
AI video synthesis has progressed by leaps and bounds over the past two years. We first covered text-to-video models in September 2022 with Meta’s Make-A-Video. A month later, Google showed off Imagen Video. And just 11 months ago, an AI-generated version of Will Smith eating spaghetti went viral. In May of last year, what was previously considered to be the front-runner in the text-to-video space, Runway Gen-2, helped craft a fake beer commercial full of twisted monstrosities, generated in two-second increments. In earlier video-generation models, people pop in and out of reality with ease, limbs flow together like pasta, and physics doesn’t seem to matter.
Sora (which means “sky” in Japanese) appears to be something altogether different. It’s high-resolution (1920×1080), can generate video with temporal consistency (maintaining the same subject over time) that lasts up to 60 seconds, and appears to follow text prompts with a great deal of fidelity. So, how did OpenAI pull it off?
OpenAI doesn’t usually share insider technical details with the press, so we’re left to speculate based on theories from experts and information given to the public.
OpenAI says that Sora is a diffusion model, much like DALL-E 3 and Stable Diffusion. It generates a video by starting off with noise and “gradually transforms it by removing the noise over many steps,” the company explains. It “recognizes” objects and concepts listed in the written prompt and pulls them out of the noise, so to speak, until a coherent series of video frames emerge.
Sora is capable of generating videos all at once from a text prompt, extending existing videos, or generating videos from still images. It achieves temporal consistency by giving the model “foresight” of many frames at once, as OpenAI calls it, solving the problem of ensuring a generated subject remains the same even if it falls out of view temporarily.
OpenAI represents video as collections of smaller groups of data called “patches,” which the company says are similar to tokens (fragments of a word) in GPT-4. “By unifying how we represent data, we can train diffusion transformers on a wider range of visual data than was possible before, spanning different durations, resolutions, and aspect ratios,” the company writes.
An important tool in OpenAI’s bag of tricks is that its use of AI models is compounding. Earlier models are helping to create more complex ones. Sora follows prompts well because, like DALL-E 3, it utilizes synthetic captions that describe scenes in the training data generated by another AI model like GPT-4V. And the company is not stopping here. “Sora serves as a foundation for models that can understand and simulate the real world,” OpenAI writes, “a capability we believe will be an important milestone for achieving AGI.”
One question on many people’s minds is what data OpenAI used to train Sora. OpenAI has not revealed its dataset, but based on what people are seeing in the results, it’s possible OpenAI is using synthetic video data generated in a video game engine in addition to sources of real video (say, scraped from YouTube or licensed from stock video libraries). Nvidia’s Dr. Jim Fan, who is a specialist in training AI with synthetic data, wrote on X, “I won’t be surprised if Sora is trained on lots of synthetic data using Unreal Engine 5. It has to be!” Until confirmed by OpenAI, however, that’s just speculation.

















{kind=link}