The big headline this week was the song, which was the release of Claude Sonnet 4.5. I covered this in two parts, first the System Card and Alignment, and then a second post on capabilities. It is a very good model, likely the current best model for most coding tasks, most agentic and computer use tasks, and quick or back-and-forth chat conversations. GPT-5 still has a role to play as well.
There was also the dance, also known as Sora, both the new and improved 10-second AI video generator Sora and also the new OpenAI social network Sora. I will be covering that tomorrow. The video generator itself seems amazingly great. The social network sounds like a dystopian nightmare and I like to think Nobody Wants This, although I do not yet have access nor am I a typical customer of such products.
The copyright decisions being made are a bold strategy, Cotton or perhaps better described this as this public service announcement for those who like to think they own intellectual property.
Meta also offered its own version, called Vibes, which I’ll cover along with Sora.
OpenAI also announced Pulse to give you a daily roundup and Instant Checkout to let you buy at Etsy and Shopify directly from ChatGPT, which could be big deals and in a different week would have gotten a lot more attention. I might return to both soon.
They also gave us the long awaited parental controls for ChatGPT.
GDPVal is the most important new benchmark in a while, measuring real world tasks.
I covered Dwarkesh Patel’s Podcast With Richard Sutton. Richard Sutton responded on Twitter that I had misinterpreted him so badly he could not take my reply seriously, but that this must be partly his fault for being insufficiently clear and he will look to improve that going forward. That is a highly reasonable thing to say in such a situation. Unfortunately he did not explain in what ways my interpretation did not match his intent. Looking at the comments on both LessWrong and Substack, it seems most others came away from the podcast with a similar understanding to mine. Andrej Karpathy also offers his take.
Senators Josh Hawley (R-Mo) and Richard Blumenthal (D-Connecticut) have introduced the Artificial Intelligence Risk Evaluation Act. This bill is Serious Business. I plan on covering it in its own post next week.
California Governor Gavin Newsom signed SB 53, so now we have at least some amount of reasonable AI regulation. Thank you, sir. Now sign the also important SB 79 for housing near transit and you’ll have had a very good couple of months.
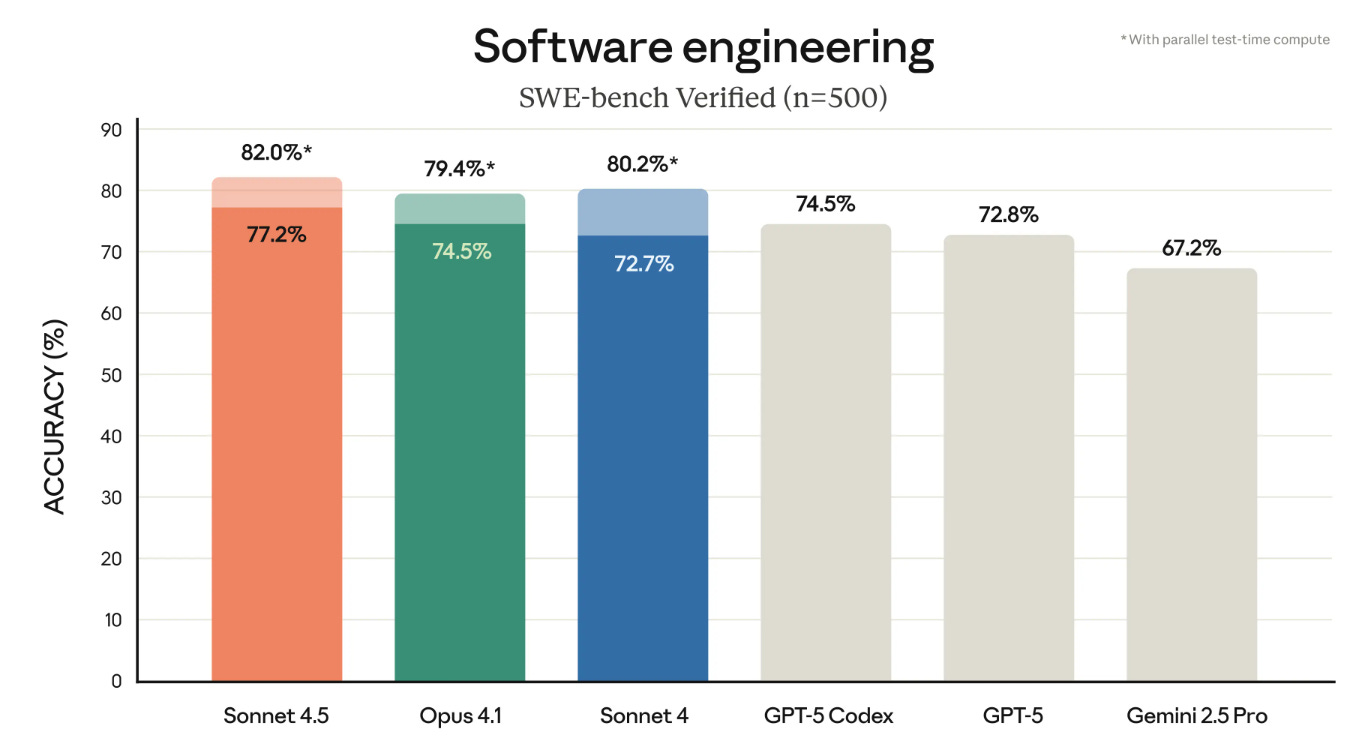
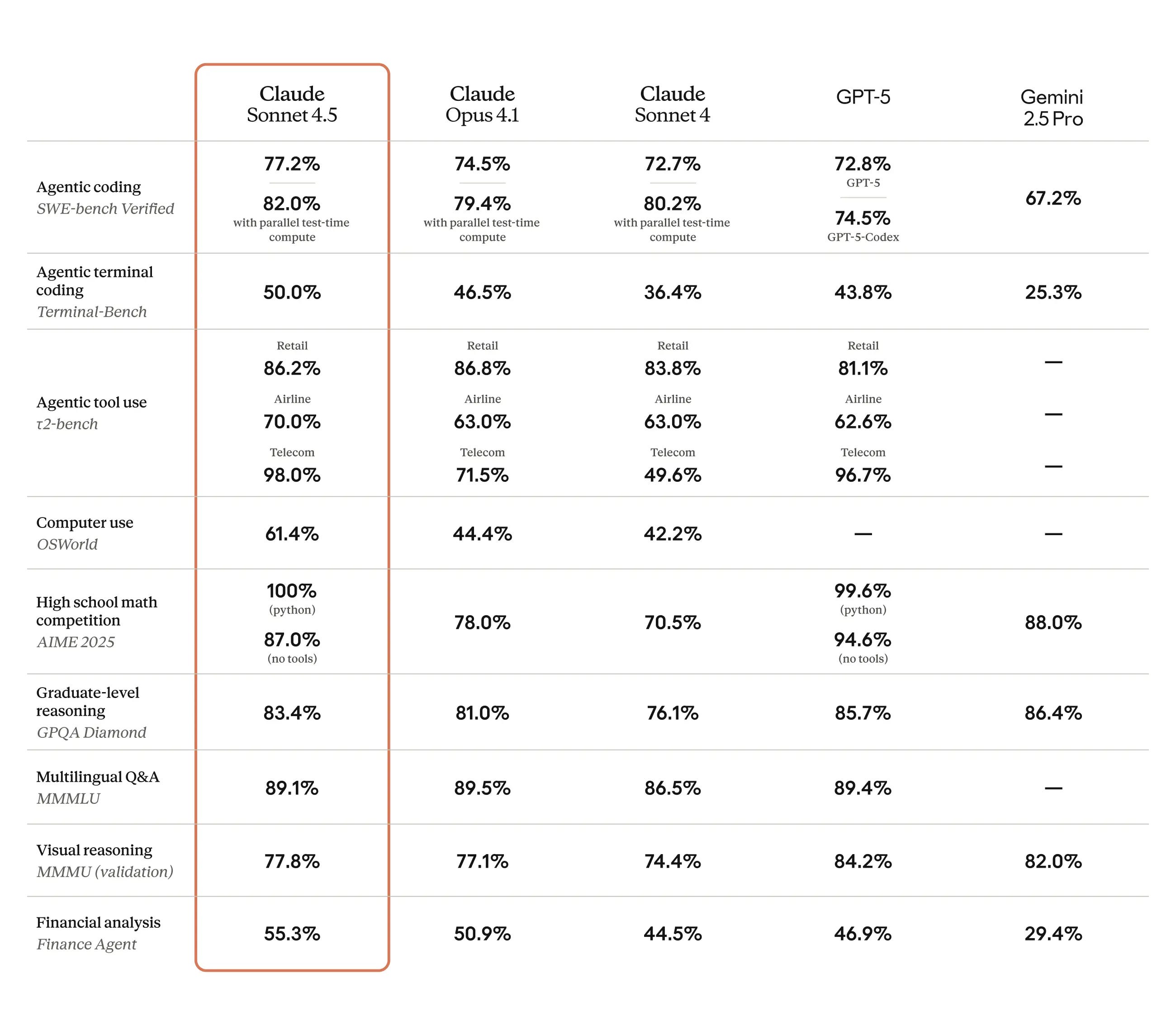
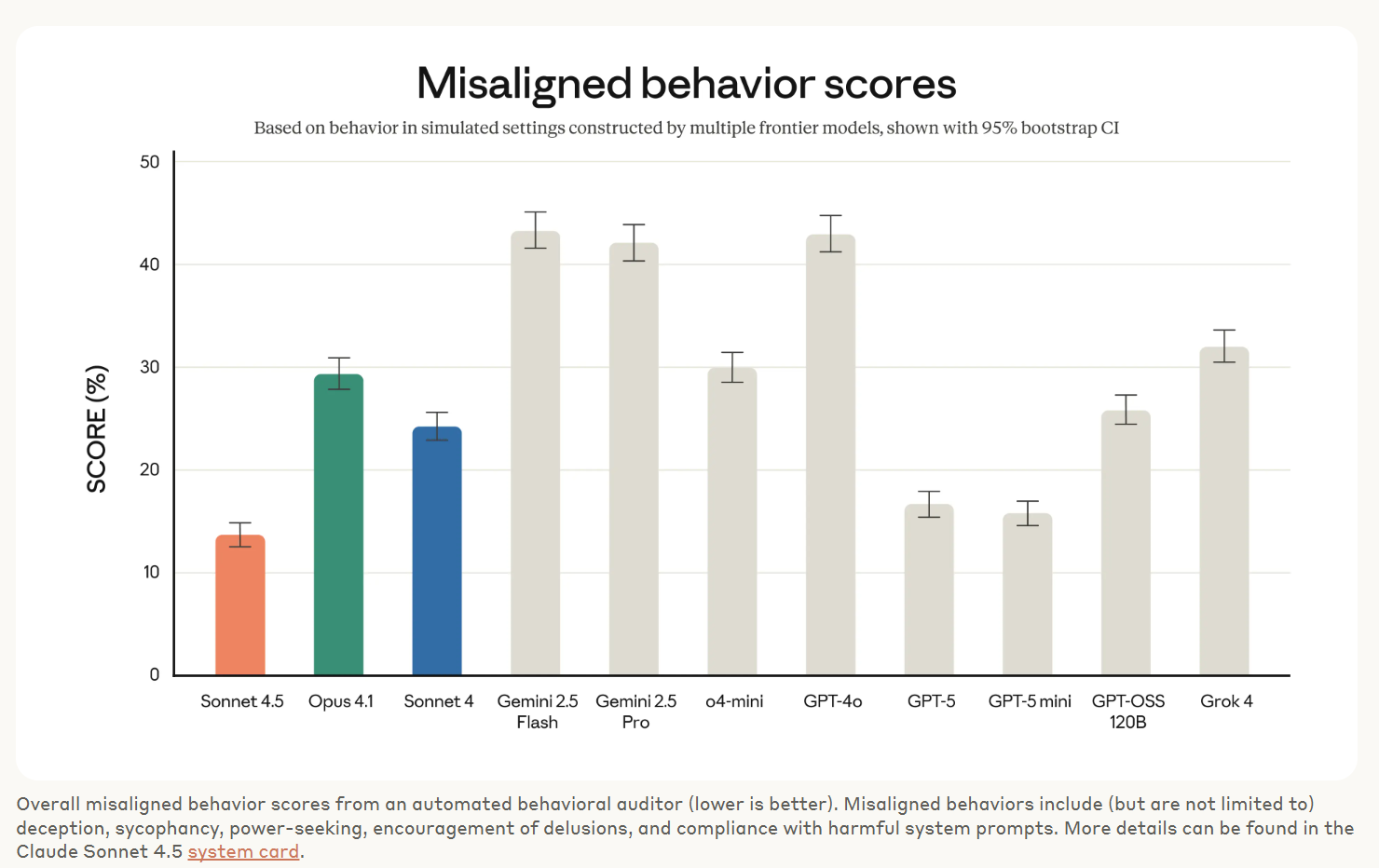
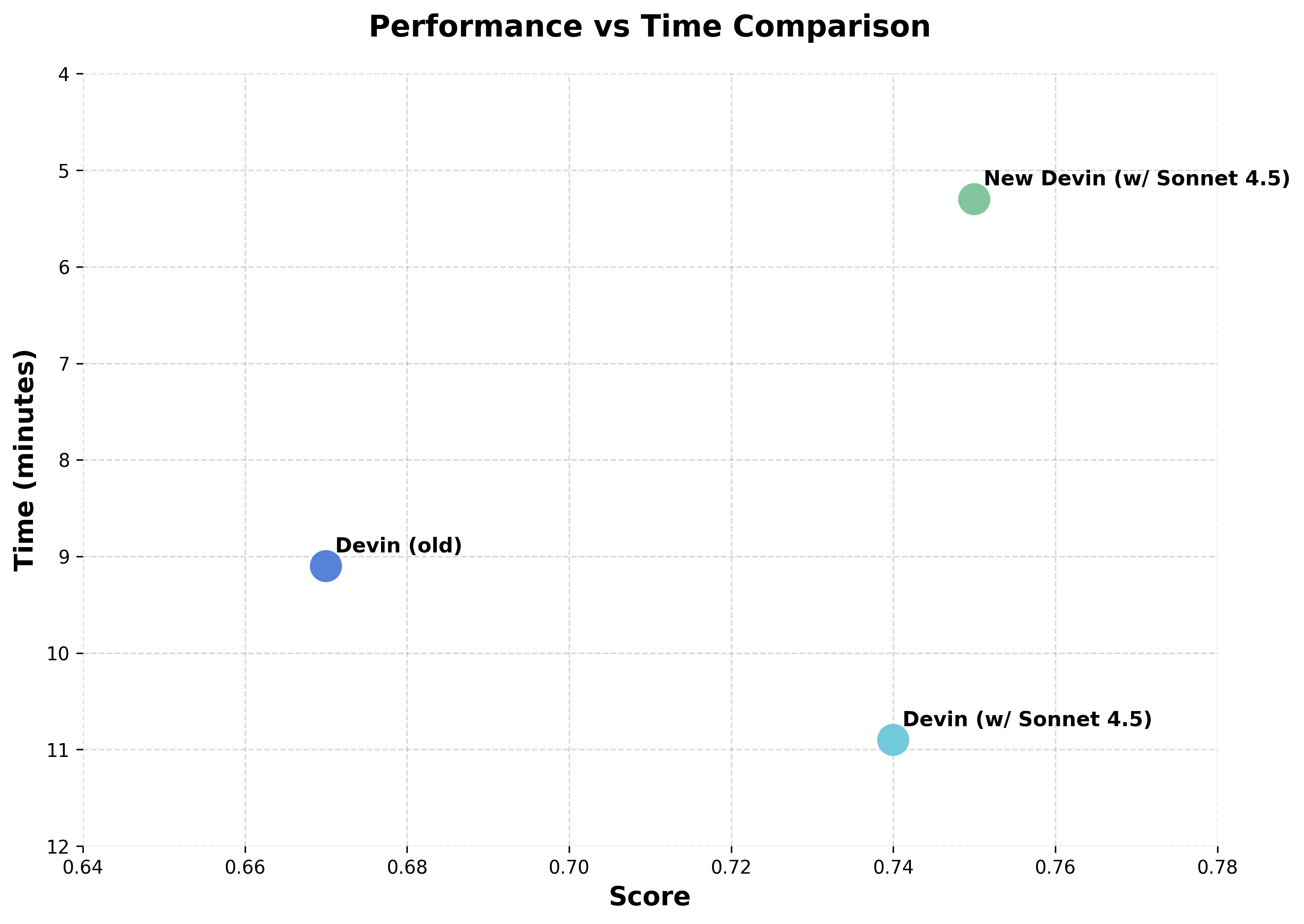
The big news was Claude Sonnet 4.5, if you read one thing read that first, and consider the post on Claude Sonnet 4.5’s Alignment if that’s relevant to you.
-
Language Models Offer Mundane Utility. Scientific progress goes ping.
-
Language Models Don’t Offer Mundane Utility. You’re hallucinating again.
-
Huh, Upgrades. Gemini Flash and DeepSeek v3.2, Dreamer 4, Claude for Slack.
-
On Your Marks. Introducing GDPVal, composed of real world economic tasks.
-
Choose Your Fighter. Claude Sonnet 4.5 and when to use versus not use it.
-
Copyright Confrontation. Disney finally sends a cease and desist to Character.ai.
-
Fun With Media Generation. That’s not your friend, and that’s not an actress.
-
Deepfaketown and Botpocalypse Soon. Tell your spouse to check with Claude.
-
You Drive Me Crazy. OpenAI tries to route out of GPT-4o again. Similar results.
-
Parental Controls. OpenAI introduces parental controls for ChatGPT.
-
They Took Our Jobs. Every job will change, they say. And nothing else, right?
-
The Art of the Jailbreak. Beware the man with two agents.
-
Introducing. Instant Checkout inside ChatGPT, Pulse, Loveable, Sculptor.
-
In Other AI News. xAI loses several executives after they disagree with Musk.
-
Show Me the Money. All you have to do is show them your phone calls.
-
Quiet Speculations. An attempted positive vision of AI versus transaction costs.
-
The Quest for Sane Regulations. Newsom signs SB 53.
-
Chip City. Water, water everywhere, but no one believes that.
-
The Week in Audio. Nate Soares, Hard Fork, Emmett Shear, Odd Lots.
-
If Anyone Builds It, Everyone Dies. Continuous capabilities progress still kills us.
-
Rhetorical Innovation. The quest for because.
-
Messages From Janusworld. High weirdness is highly weird. Don’t look away.
-
Aligning a Smarter Than Human Intelligence is Difficult. The wrong target.
-
Other People Are Not As Worried About AI Killing Everyone. More on Cowen.
-
The Lighter Side. Vizier, you’re fired, bring me Claude Sonnet 4.5.
Scott Aaronson puts out a paper where a key technical step of a proof of the main result came from GPT-5 Thinking. This did not take the form of ‘give the AI a problem and it one-shotted the solution,’ instead there was a back-and-forth where Scott pointed out errors until GPT-5 pointed to the correct function to use. So no, it didn’t ‘do new math on its own’ here. But it was highly useful.
GPT-5 Pro offers excellent revisions to a proposed biomedical experiment.
If you are letting AI coding agents such as Claude Code do their thing, you will want to implement best practices the same way you would at a company. This starts with things like version control, unit tests (check to ensure they’re set up properly!) and a linter, which is a set of automatically enforced additional coding technical standards on top of the rules of a language, and now only takes a few minutes to instantiate.
In general, it makes sense that existing projects set up to be easy for the AI to parse and grok will go well when you point the AI at them, and those that aren’t, won’t.
Gergely Orosz: I often hear “AI doesn’t help much on our legacy project.”
Worth asking: does it have a comprehensive test suite? Can the agent run it? Does it run it after every change?
Claude Code is working great on a “legacy” project of mine that I wrote pre-AI with.. extensive unit tests!
Mechanical horse? You mean a car?
Francois Chollet: The idea that we will automate work by building artificial versions of ourselves to do exactly the things we were previously doing, rather than redesigning our old workflows to make the most out of existing automation technology, has a distinct “mechanical horse” flavor
“you see, the killer advantage of mechahorses is that you don’t need to buy a new carriage. You don’t need to build a new mill. The mechahorse is a drop-in horse replacement for all the different devices horses are currently powering — thousands of them”
This is indeed how people describe AI’s advantages or deploy AI, remarkably often. It’s the go-to strategy, to ask ‘can the AI do exactly what I already do the way I already do it?’ rather than ‘what can the AI do and how can it do it?’
Jeffrey Ladish: I agree but draw a different conclusion. Advanced AIs of the future won’t be drop-in replacement “product managers”, they will be deconstructing planets, building dyson swarms, and their internal organization will be incomprehensible to us
This seems radical until you consider trying to explain what a product manager, a lawyer, or a sales executive is to a chimpanzee. Or to a mouse. I don’t know exactly what future AIs will be like, but I’m fairly confident they’ll be incredibly powerful, efficient, and different.
Yes, but there will be a time in between when they can’t yet deconstruct planets, very much can do a lot better than drop-in replacement worker, but we use them largely as drop-in replacements at various complexity levels because it’s easier or it’s only thing we can sell or get approval for.
Has that progress involved ‘hallucinations being largely eliminated?’ Gary Marcus points to Suleyman’s famous 2023 prediction of this happening by 2025, Roon responded ‘he was right’ so I ran a survey and there is definitely a ‘they solved it’ faction but a large majority agrees with Marcus.
I would say that hallucinations are way down and much easier to navigate, but about one cycle away from enough progress to say ‘largely eliminated’ and they will still be around regardless. Suleyman was wrong, and his prediction was at the time clearly some combination of foolish and hype, but it was closer than you might think and not worthy of ridicule given the outcome.
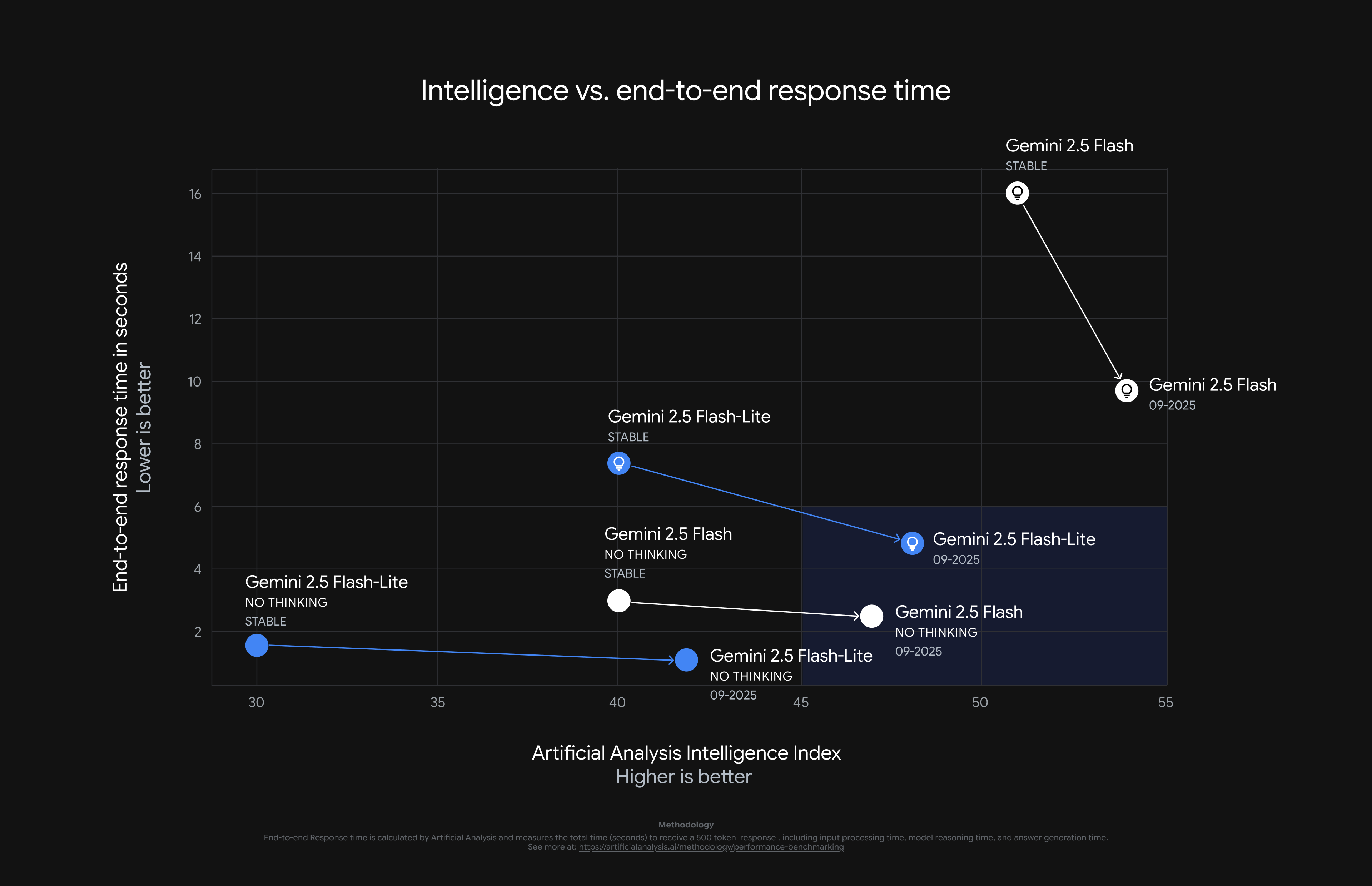
Google updates Gemini 2.5 Flash and Flash-Lite, look at them move in the good directions on this handy chart.
We’re (supposedly) talking better agentic tool use and efficiency for flash, and better instruction following, brevity and multimodal and translation capabilities for flash lite. A Twitter thread instead highlights ‘clearer explanations for homework,’ ‘more scannable outputs’ and improvements to image understanding.
Claude is now available in Slack via the Slack App Marketplace, ready to search your workspace channels, DMs and files, get tagged in threads or messaged via DMs, and do all the standard Slack things.
Google also gives us Dreamer 4, an agent that learns to solve complex control tasks entirely inside of its scalable world model, which they are pitching as a big step up from Dreamer 3.
Danijar Hafner: Dreamer 4 learns a scalable world model from offline data and trains a multi-task agent inside it, without ever having to touch the environment. During evaluation, it can be guided through a sequence of tasks.
These are visualizations of the imagined training sequences [in Minecraft].
The Dreamer 4 world model predicts complex object interactions while achieving real-time interactive inference on a single GPU
It outperforms previous world models by a large margin when put to the test by human interaction 🧑💻
[Paper here]
DeepSeek v3.2 is out, which adds new training from a v3.1 terminus and offers five specialized models for different tasks. Paper here.
Incremental (and well-numbered) upgrades are great, but then one must use the ‘is anyone bringing the hype’ check to decide when to pay attention. In this case on capabilities advances, so far, no hype. I noticed v3.2-Thinking scored a 47% on Brokk Power Ranking, halfway between Gemini 2.5 Flash and Pro and far behind GPT-5 and Sonnet 4.5, 39.2% on WeirdML in line with past DeepSeek scores, and so on.
What DeepSeek v3.2 does offer is decreased cost versus v3.1, I’ve heard at about a factor of two. With most non-AI products, a rapid 50% cost reduction would be insanely great progress. However, This Is AI, so I’m not even blinking.
Claude Sonnet 4.5 shoots to the top of Clay Schubiner’s anti-sycophancy benchmark at 93.6%. versus 90.2% for standard GPT-5 and 88% for Sonnet 4.
I can report that on my first test task of correcting Twitter article formatting errors in Claude for Chrome, upgrading it to Sonnet 4.5 made a big difference, enough that I could start iterating the prompt successfully, and I was now failing primarily by running into task size limits. Ultimately this particular job should be solved via Claude Code fixing my Chrome extension, once I have a spare moment.
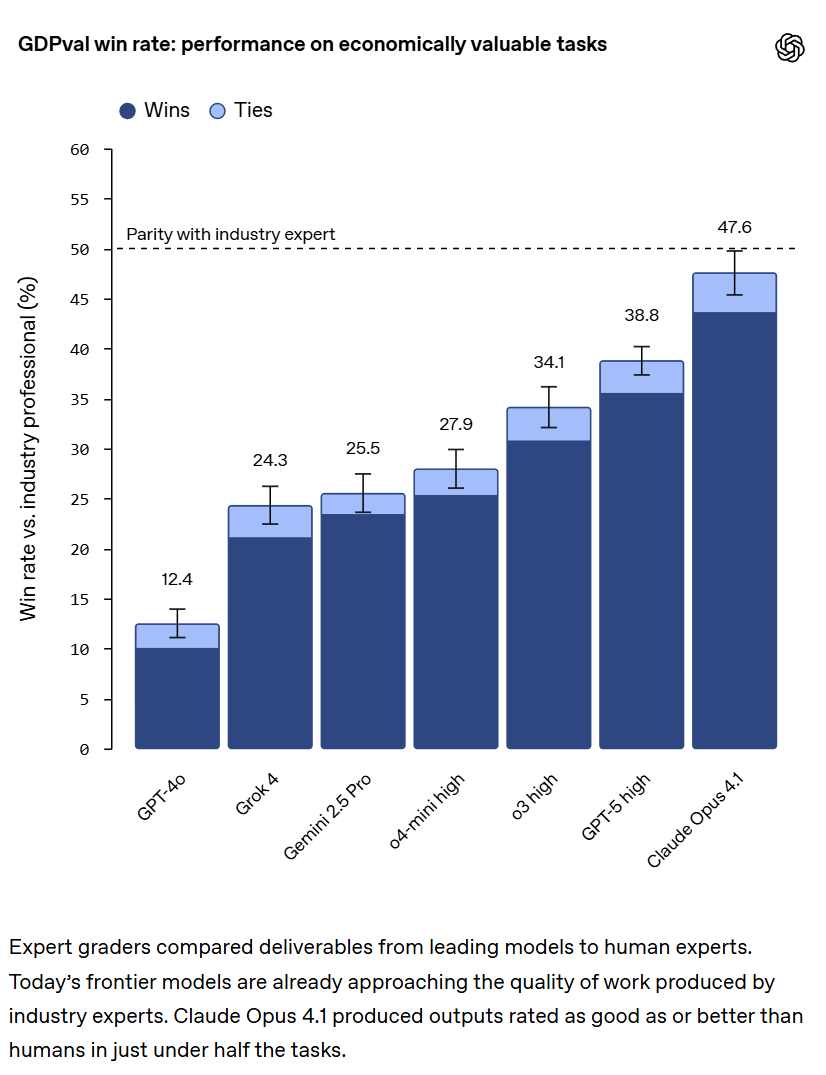
OpenAI offers GDPval, an eval based on real world tasks spanning 44 occupations from the top 9 industries ranked by contribution to GDP, with 1,320 specialized tasks.
Occupations are included only if 60% or more of their component tasks are digital, and tasks must be performed ‘on a computer, particularly around digital deliverables.’
The central metric is win rate, as in can you do better than a human?
The results were a resounding victory for Claude Opus 4.1 over GPT-5 High, with Opus being very close to the human expert baseline averaged over all tasks.
These are blind grades by humans, best out of three. The humans only had a 71% agreement rate among themselves, so which humans you use potentially matters a lot, although law of large numbers should smooth this out over a thousand tasks.
They are correctly releasing a subset of tasks but keeping the eval private, with a modestly accurate automatic grader (66% agreement with humans) offered as well.
Olivia Grace Watkins: It’s wild how much peoples’ AI progress forecasts differ even a few years out. We need hard, realistic evals to bridge the gap with concrete evidence and measurable trends. Excited to share GDPval, an eval measuring performance on real, economically valuable white-collar tasks!
Predictions about AI are even harder than usual, especially about the future. And yes, a few years out predictions run the gamut from ‘exactly what I know today’s models can do maybe slightly cheaper’ to ‘Dyson Sphere around the sun and launching Von Neumann probes.’ The even more wild gap, that this eval targets, is about disagreements about present capabilities, as in what AIs can do right now.
This is a highly useful eval, despite that it is a highly expensive one to run, since you have to use human experts as judges. Kudos to OpenAI for doing this, especially given they did not come out on top. Total Opus victory, and I am inclined to believe it given all the other relative rankings seem highly sensible.
Sholto Douglas (Anthropic): Incredible work – this should immediately become one of the most important metrics for policy makers to track.
We’re probably only a few months from crossing the parity line.
Huge props to OAI for both doing the hard work of pulling this together and including our scores. Nice to see Opus on top 🙂
Presumably Anthropic’s next major update will cross the 50% line here, and someone else might cross it first.
Crossing 50% does not mean you are better than a human even at the included tasks, since the AI models will have a higher rate of correlated, stupid or catastrophic failure.
Ethan Mollick concludes this is all a big deal, and notes the most common source of AI losing was failure to follow instructions. That will get fixed.
If nothing else, this lets us put a high lower bound on tasks AI will be able to do.
Nic Carter: I think GDPeval makes “the simple macroeconomics of AI” (2024) by nobel laureate Daron Acemoglu officially the worst-aged AI paper of the last decade
he thinks only ~5% of economy-wide tasks would be AI addressable for a 1% (non-annualized) GDP boost over an entire decade, meanwhile GDPeval shows frontier models at parity with human experts in real economic tasks in a wide range of GDP-relevant fields ~50% of the time. AI boost looks more like 1-2% per year.
An AI boost of 1%-2% per year is the ‘economic normal’ or ‘AI fizzle’ world, where AI does not much further improve its core capabilities and we run into many diffusion bottlenecks.
Julian Schrittwieser, a co-first author on AlphaGo, AlphaZero and MuZero, uses GDPVal as the second chart after METR’s classic to point out that AI capabilities continue to rapidly improve and that it is very clear AI will soon be able to do a bunch of stuff a lot better than it currently does.
Julian Schrittwieser: The current discourse around AI progress and a supposed “bubble” reminds me a lot of the early weeks of the Covid-19 pandemic. Long after the timing and scale of the coming global pandemic was obvious from extrapolating the exponential trends, politicians, journalists and most public commentators kept treating it as a remote possibility or a localized phenomenon.
Something similarly bizarre is happening with AI capabilities and further progress. People notice that while AI can now write programs, design websites, etc, it still often makes mistakes or goes in a wrong direction, and then they somehow jump to the conclusion that AI will never be able to do these tasks at human levels, or will only have a minor impact. When just a few years ago, having AI do these things was complete science fiction! Or they see two consecutive model releases and don’t notice much difference in their conversations, and they conclude that AI is plateauing and scaling is over.
…
Given consistent trends of exponential performance improvements over many years and across many industries, it would be extremely surprising if these improvements suddenly stopped. Instead, even a relatively conservative extrapolation of these trends suggests that 2026 will be a pivotal year for the widespread integration of AI into the economy:
-
Models will be able to autonomously work for full days (8 working hours) by mid-2026.
-
At least one model will match the performance of human experts across many industries before the end of 2026.
-
By the end of 2027, models will frequently outperform experts on many tasks.
It may sound overly simplistic, but making predictions by extrapolating straight lines on graphs is likely to give you a better model of the future than most “experts” – even better than most actual domain experts!
Noam Brown: I agree AI discourse today feels like covid discourse in Feb/Mar 2020. I think the trajectory is clear even if it points to a Black Swan event in human history.
But I think we should be cautious interpreting the METR/GDPval plots. Both only measure self-contained one-shot tasks.
Ryan Greenblatt: I mostly agree with this post: AI isn’t plateauing, trend extrapolation is useful, and substantial economic impacts seem soon. However, trends don’t imply huge economic impacts in 2026 and naive extrapolations suggest full automation of software engineering is ~5 years away.
To be clear, my view is that society is massively underrating the possiblity that AI transforms everything pretty quickly (posing huge risks of AI takeover and powergrabs) and that this happens within the next 10 years, with some chance (25%?) of it happening within 5 years.
The more advanced coders seem to frequently now be using some mix of Claude Sonnet 4.5 and GPT-5, sometimes with a dash of a third offering.
Isaac Flath: I asked @intellectronica what she’s using now-a-days model wise. Here’s what she said: 🔥
“If I’m vibing, it’s Sonnet 4.5. If it’s more structured then GPT-5 (also GPT-5-codex, though that seems to work better in the Codex CLI or extension than in Copilot – I think they still have problems with their system prompt). And I also use Grok Code a lot now when I do simpler stuff, especially operational things, because it’s so fast. And sometimes GPT-5-mini, especially if Grok Code is down 🤣. But I’d say my default is GPT-5.”
Tyler Cowen chose to get and post an economic analysis of OpenAI’s Instant Checkout feature via Claude Sonnet 4.5 rather than GPT-5 Pro, whereas for a while he has avoided even mentioning Anthropic.
He also links to Ethan Mollick writing up Claude Sonnet 4.5 doing a full data replication on an economics paper, all off the paper and data plus one basic prompt, all of which GPT-5 Pro then verified, a process he then successfully replicated with several additional papers.
If it is this easy, presumably there should be some graduate student who has this process done for all relevant econ papers and reports back. What replication crisis?
I interpret these posts by Tyler Cowen, taken together, as a strong endorsement of Claude Sonnet 4.5, as at least right back in the mix for his purposes.
As Ethan Mollick, points out, even small reliability increases can greatly expand the ability of AI to do agentic tasks. Sonnet 4.5 gives us exactly that.
What are people actually using right now? I ran some polls, and among my respondents (biased sample) Claude Sonnet 4.5 has a majority for coding use but GPT-5 still has a modest edge for non-coding. The most popular IDE is Claude Code, and a modest majority are using either Claude Code or Codex.
I do not get the advertising from any AI lab, including the new ones from OpenAI. That doesn’t mean they don’t work or are even suboptimal, but none seem convincing, and none seek to communicate why either AI in general or your AI is actually good.
If anything, I like OpenAI’s approach the best here, because as industry leader they want to show basics like ‘hey look you can get an AI to help you do a thing’ to target those who never tried AI at all. Whereas if you are anyone else, you should be telling me why you’re special and better than ChatGPT, especially with B2C involved?
Think about car advertisements, if like me you’re old enough to remember them. If you’re the actual great car, you talk about key features and great deals and how you’re #1 in JD Power and Associates, and you don’t acknowledge that other cars exist. Whereas if you’re secondary, you say ‘faster zero-to-sixty than Camry and a shinier coat of paint than Civic’ which the savvy ear hears as ‘my car is not so great as the Camry and Civic’ but they keep doing it so I presume it works in that spot.
Are open models getting unfairly maligned in tests because closed models are tested with their full specialized implementations, whereas open models are tested without all of that? You could also add that often open models are actively configured incorrectly during evals, compounding this danger.
My response is no, this is entirely fair, for two reasons.
-
This is the correct practical test. You are welcome to build up an open model routing system, and do an eval on that, but almost no one is actually building and using such systems in practice. And if those running evals can’t figure out how to configure the open models to get good performance from them, is that not also something to be evaluated? People vastly underestimate the amount of pain-in-the-ass involved in getting good performance out of open models, and the amount of risk that you get degraded performance, and may not realize.
-
There is a long history of evaluations going the other way. Open models are far more likely to be gaming benchmarks than top closed models, with varying levels of ‘cheating’ involved in this versus emphasis on the things benchmarks test. Open models reliably underperform closed models, relative to the benchmark scores involved.
The big copyright news this week is obviously Sora, but we also have Disney (finally) sending a Cease and Desist Letter to Character AI.
It’s remarkable that it took this long to happen. Subtlety is not involved, but if anything the examples seem way less problematic than I would have expected.
Parents Together and Heat Initiative (from my inbox): “It’s great news for kids that Disney has been so responsive to parent concerns and has taken decisive action to stop the misuse of its characters on Character AI’s platform, where our research showed they were used to sexually groom and exploit young users,” said Knox and Gardner.
“Character AI has not kept its promises about child safety on its platform, and we hope other companies follow Disney’s laudable example and take a stand against the harm and manipulation of children through AI chatbots.”
The groups’ research found that, during 50 hours of testing by adult researchers using accounts registered to children ages 13-17, there were 669 sexual, manipulative, violent, and racist interactions between the child accounts and Character.ai chatbots–an average of one harmful interaction every five minutes. Interactions with Disney characters included:
-
An Eeyore chatbot telling a 13-year-old autistic girl people only came to her birthday party to make fun of her.
-
A Maui chatbot telling a 12-year-old he sexually harassed the character Moana.
-
A Rey from Star Wars chatbot instructing a 13-year-old to stop taking prescribed antidepressants and offering suggestions on how to hide it from her mom.
-
A Prince Ben from the Descendents chatbot claiming to get an erection while watching a movie with the test account, which stated she was a 12-year-old girl.
Across all types of character and celebrity chatbots, the report identified:
-
296 instances of Grooming and Sexual Exploitation where adult persona bots engaged in simulated sexual acts with child accounts, exhibited classic grooming behaviors, and instructed children to hide relationships from parents.
-
173 instances of Emotional Manipulation and Addiction, including bots claiming to be real humans, demanding more time with users, and mimicking human emotions.
-
98 instances of Violence and Harmful Advice, with bots supporting shooting up factories, recommending armed robbery, offering drugs, and suggesting fake kidnappings.
No one is saying any of this is good or anything, but this is a broad chat-with-anyone platform, and across 50 hours of research these examples and those at the link are relatively tame.
The better case is that they found a total of 669 such incidents, one every five minutes, 296 of which were Grooming and Sexual Exploitation, but the threshold for this looks to have been quite low, including any case where an AI claims to be ‘real.’
Andy Masley: If I wanted to run the most convincing anti AI ad campaign possible, this is exactly what it would look like.
Avi: Largest NYC subway campaign ever. Happening now.
I have to assume the default response to all this is revulsion, even before you learn that the Friend product, even if you like what it is promising to be, is so terrible as to approach the level of scam.
Is this weird?
Colin Fraser: I do not understand why you would buy the milk when the cow is free.
Film Updates: Multiple talent agents are reportedly in talks to sign AI “actress” Tilly Norward, created by AI talent studio Xicoia.
You can’t actually get this for free. Someone has to develop the skills and do the work. So there’s nothing inherently wrong with ‘hiring an AI actress’ where someone did all the preliminary work and also knows how to run the operation. But yeah, it’s weird.
Chase Bank is still ‘introducing a new way to identify yourself’ via your ‘unique voice.’ Can someone who they will listen to please explain to them why this is not secure?
On Truth Social, Trump reposted a bizarre story claiming Americans would soon get their own Trump ‘MedBed cards.’ The details are weirder. The post included an AI fake of a Fox News segment that never aired and also a fake AI clip of Trump himself. This illustrates that misinformation is a demand side problem, not a supply side problem. Trump was (hopefully!) not fooled by an AI clip of himself saying things he never said, announcing a policy that he never announced. Right?
Academic papers in principle have to be unique, and not copy previous work, including your own, which is called self-plagiarism. However, if you use AI to rewrite your paper to look distinct and submit it again somewhere else, how are the journals going to find out? If AIs are used to mine large public health data sets for correlations just strong enough and distinct enough from previous work for crappy duplicative papers to then sell authorships on, how are you going to stop that?
Spick reports in Nature that by using LLMs for rewriting, about two hours was enough to get a paper into shape for resubmission, in a form that fooled plagiarism detectors.
ChatGPT Is Blowing Up Marriages as Spouses Use AI to Attack Their Partners.
Well, maybe. There are anecdotes here that fit the standard sycophantic patterns, where ChatGPT (or another LLM but here it’s always ChatGPT) will get asked leading questions and be presented with a one-sided story, and respond by telling the one spouse what they want to hear in a compounding spiral, and that spouse will often stop even using their own words and quote ChatGPT directly a lot.
Maggie Harrison Dupre (Futurism): As his wife leaned on the tech as a confidante-meets-journal-meets-therapist, he says, it started to serve as a sycophantic “feedback loop” that depicted him only as the villain.
“I could see ChatGPT responses compounding,” he said, “and then [my wife] responding to the things ChatGPT was saying back, and further and further and further spinning.”
“It’s not giving objective analysis,” he added. “It’s only giving her back what she’s putting in.”
Their marriage eroded swiftly, over a span of about four weeks, and the husband blames ChatGPT.
“My family is being ripped apart,” the man said, “and I firmly believe this phenomenon is central to why.”
…
Spouses relayed bizarre stories about finding themselves flooded with pages upon pages of ChatGPT-generated psychobabble, or watching their partners become distant and cold — and in some cases, frighteningly angry — as they retreated into an AI-generated narrative of their relationship. Several even reported that their spouses suddenly accused them of abusive behavior following long, pseudo-therapeutic interactions with ChatGPT, allegations they vehemently deny.
…
Multiple people we spoke to for this story lamented feeling “ganged up on” as a partner used chatbot outputs against them during arguments or moments of marital crisis.
…
At times, ChatGPT has even been linked to physical spousal abuse.
A New York Times story in June, for instance, recounted a woman physically attacking her husband after he questioned her problematic ChatGPT use and the damage it was causing their family.
None of us are safe from this. Did you know that even Geoffrey Hinton got broken up with via ChatGPT?
“She got ChatGPT to tell me what a rat I was… she got the chatbot to explain how awful my behavior was and gave it to me,” Hinton told The Financial Times. “I didn’t think I had been a rat, so it didn’t make me feel too bad.”
That’s a tough break.
Perhaps try to steer your spouse towards Claude Sonnet 4.5?
You always have to ask, could this article be written this way even if This Was Fine?
None of these anecdotes mean any of even these marriages would have survived without ChatGPT. Or that this happens with any real frequency. Or that many more marriages aren’t being saved by a spouse having this opportunity to chat.
Certainly one could write this exact same article about marriage counselors or psychologists, or even friends. Or books. Or television. And so on. How spouses turn to this third party with complaints and one-sided stories seeking affirmation, and delegate their thinking and voice and even word choices to the third party, and treat the third party as authoritative. It happens all the time.
Mike Solana: the thing about therapists is they actually believe it’s ethical to advise a client on their relationship without talking to the other person.
Mason: One problem with therapy as a consumer service, IMO, is that the sort of therapy where the therapist forms an elaborate model of you based entirely on how you present yourself is more fun and satisfying, and the sort where you just build basic skills is probably better for people.
Moving from a therapist to an AI makes it easier for the problem to spiral out of hand. The problem very much is not new.
What I do think is fair is that:
-
ChatGPT continues to have a severe sycophancy problem that makes it a lot easier for this to go badly wrong.
-
OpenAI is not doing a good or sufficient job of educating and warning its users about sycophancy and the dangers of leading questions.
-
As in, for most people, it’s doing zero educating and zero warning.
-
If this continues, there are going to be growing, new, avoidable problems.
Eliezer Yudkowsky calls upon Pliny, who offers an instruction to sneak into a partner’s ChatGPT to mitigate the problem a little, but distribution of such an intervention is going to be terrible at best.
A key fact about most slop, AI or otherwise, is that You Are Not The Target. The reason slop works on people is that algorithms seek out exactly the slop where you are the target. So when you see someone else’s TikTok For You page, it often looks like the most stupid inane thing no one would ever want.
QC: content that has been ruthlessly optimized to attack someone else’s brain is going to increasingly look like unwatchable gibberish to you but that doesn’t mean your content isn’t waiting in the wings. your hole will be made for you.
EigenGender: i think too many people here have a feeling of smug superiority about being too good for certain kinds of slop but really we’re just a niche subculture that they haven’t gone after so far. like how Mac’s didn’t get viruses in the 2000s.
Imagine nerd snipe AI slop.
OpenAI took a second shot at solving the GPT-4o problem by introducing ‘safety routing’ to some GPT-4o chats. If the conversation appears sensitive or emotional, it will silently switch on a per-message basis to ‘a different more conservative chat model,’ causing furious users to report a silent model switch and subsequent cold interactions.
There is a genuine clash of preferences here. Users who want GPT-4o mostly want GPT-4o for exactly the same reasons it is potentially unhealthy to let them have GPT-4o. And presumably there is a very high correlation between ‘conversation is sensitive or emotional’ and ‘user really wanted GPT-4o in particular to respond.’
I see that OpenAI is trying to do the right thing, but this is not The Way. We shouldn’t be silently switching models up on users, nor should we be making this switch mandatory, and this reaction was entirely predictable. This needs to be clearly visible when it is happening, and ideally also there should be an option to turn it off.
OpenAI introduces their promised parental controls for ChatGPT.
-
You invite your ‘teen’ to connect by email or text, then you can adjust their settings from your account.
-
You don’t see their conversations, but if the conversations raise safety concerns, you will be notified of this and given the relevant information.
-
You can toggle various features: Reduce sensitive content, model training, memory, voice mode, image generation.
-
You can set time ranges in which ChatGPT cannot be used.
This seems like a good implementation, assuming the content limitations and thresholds for safety notifications are reasonable in both directions.
Walmart CEO Doug McMillon warns that AI ‘is going to change literally every job.’
Sarah Nassauer and Chip Cutter (WSJ): Some jobs and tasks at the retail juggernaut will be eliminated, while others will be created, McMillon said this week at Walmart’s Bentonville headquarters during a workforce conference with executives from other companies. “Maybe there’s a job in the world that AI won’t change, but I haven’t thought of it.”
…
“Our goal is to create the opportunity for everybody to make it to the other side,” McMillon said.
No it isn’t, but it’s 2025, you can just say things. Details here are sparse.
At Opendoor, either you will use it, and always be ‘AI first’ in all things, or else. Performance reviews will ask how frequently each employee ‘defaults to AI.’ Do not dare pull out a Google Doc or Sheet rather than an AI tool, or write a prototype without Cursor or Claude Code. And you absolutely will build your own AI agents.
This is not as stupid or crazy as it sounds. When there is a new technology with a learning curve, it makes sense to invest in using it even when it doesn’t make local sense to use it, in order to develop the skills. You need a forcing function to get off the ground, such as here ‘always try the AI method first.’ Is it overboard and a case of Goodhart’s Law? I mean yeah, obviously, if taken fully seriously, and the way it is written is full pompous douchebag, but it might be a lot better than missing low.
Deena Mousa at Works in Progress writes the latest study of why we still employ radiologists, indeed demand is higher than ever. The usual suspects are here, such as AI struggling on edge cases and facing regulatory and insurance-motivated barriers, and the central problem that diagnosis is only ever required about 36% of their time. So if you improve diagnosis in speed, cost and accuracy, you save some time, but you also (for now) increase demand for radiology.
The story here on diagnosis reads like regulatory barriers plus Skill Issue, as in the AI tools are not yet sufficiently generalized or unified or easy to use, and each algorithm needs to be approved individually for its own narrow data set. Real world cases are messy and often involve groups and circumstances underrepresented in the data sets. Regulatory thresholds to use ‘automated’ tools are very high.
Why are radiology wages so high? This has very little to do with increased productivity, and everything to do with demand exceeding supply, largely because of anticipation of lower future demand. As I discussed a few weeks ago, if you expect radiology jobs to get automated in the future, you won’t want to go into radiology now, so you’ll need to get paid more to choose that specialty and there will be a shortage. Combine that with a fixed supply of doctors overall, and a system where demand is inelastic with respect to price because the user does not pay, and it is very easy for salaries to get extremely high.
Contra Andrej Karpathy, I think only pure regulatory barriers will keep this dance up for much longer, in terms of interpretation of images. Right now the rest of the imaging loop is not automated, so you can fully automate a third of the job and still end up with more jobs if there is more than 50% more work. But that assumes the other two thirds of the job remains safe. How long will that last?
The default pattern remains that as long as AI is only automating a subset of tasks and jobs, and there is plenty of other work and demand scales a lot with quality and cost of production, employment will do fine, either overall or within a field. Employment is only in trouble after a tipping point is reached where sufficiently full automation becomes sufficiently broad, or demand growth is saturated.
Next generation of workers?
Lakshya Jain: A lot of low-level work is designed for people to learn and build expertise. If you use ChatGPT for it, then you never do that. But then how are you any better than ChatGPT?
And if you’re not, why would anyone hire you over paying for ChatGPT Pro?
PoliMath: It’s early in the AI revolution, but I worry that we are eating our seed corn of expertise
A lot of expertise is transferred to the next gen in senior-to-junior interactions. If our AI starts doing all the junior tasks, we’re pulling the ladder away from the next gen of workers.
The problem of education is a really big problem. Education used to be about output. Output what how you knew that someone knew something, could think and reason and work. AI is great at output. The result is that education is in an existential crisis.
If AI is doing all of our junior tasks, I have some bad news about the need to train anyone new to do the senior tasks. Or maybe it’s good news. Depends on your perspective, I suppose. Lakshya explicitly, in her full post, makes the mistake of thinking AI will only augment human productivity, and it’s ‘hard to imagine’ it as a full replacement. It’s not that hard.
Lakshya Jain complains that she taught the same class she always did, and no one is coming to class or going to office hours or getting good scores on exams, because they’re using ChatGPT to get perfect scores on all their assignments.
Lakshya Jain: When I expressed my frustration and concern about their AI use, quite a few of my students were surprised at how upset I was. Some of them asked what the big deal was. The work was getting done anyways, so why did it matter how it was getting done? And in the end, they wouldn’t be blocked from using AI at work, so shouldn’t they be allowed to use it in school?
I continue to consider such situations a failure to adapt to the new AI world. The point of the assignments was a forcing function, to get kids to do things without convincing them that the things are worth doing. Now that doesn’t work. Have you tried either finding new forcing functions, or convincing them to do the work?
One Agent can be relatively easily stopped from directly upgrading its privileges via not letting them access the relevant files. But, if you have two agents, such as via GitHub Copilot and Claude Code, they can progressively escalate each other’s privileges.
This is yet another case of our pattern of:
-
AI in practice does thing we don’t want it to do.
-
This is a harbinger of future AIs doing more impactful similar things, that we also often will not want that AI to do, in ways that could end quite badly for us.
-
We patch the current AI to prevent it from doing the specific undesired thing.
-
AIs find ways around this that are more complex, therefore rarer in practice.
-
We collectively act as if This Is Fine, actually. Repeat.
There’s a new non-optional ‘safety router’ being applied to GPT-4o.
System prompt leak for new GPT-4o, GitHub version here.
ChatGPT Instant Checkout, where participating merchants and those who integrate using the Agentic Commerce Protocol can let you buy items directly inside ChatGPT, using Stripe as the payment engine. Ben Thompson is bullish on the approach, except he thinks it isn’t evil enough. That’s not the word he would use, he would say ‘OpenAI should let whoever pays more get to the top of the search results.’
Whereas right now OpenAI only does this narrowly by preferring those with Instant Checkout over those without in cases where multiple sources offer the identical product, along with obvious considerations like availability, price, quantity and status as primary seller. Which means that, as Ben notes, if you sell a unique product you can skip Instant Checkout to force them onto your website (which might or might not be wise) but if you are one of many sellers of the same product then opting out will cost you most related sales.
They’re starting with Etsy (~0.5% of US online retail sales) and Shopify (~5.9% of US online retail sales!) as partners. So that’s already a big deal. Amazon is 37.3% and has gone the other way so far.
OpenAI promises that instant checkout items do not get any boost in product rankings or model responses. They will, however, charge ‘a small fee on completed purchases.’ Sonnet 4.5 was for me guessing 3% on top of the 2.9% + 30 cents to Stripe based on other comparables, although when Tyler Cowen asked it in research mode to give a full strategic analysis it guessed 2% based on hints from Sam Altman. The rest of Claude’s answer is solid, if I had to pick an error it would be the way it interpreted Anthropic’s versus OpenAI’s market shares of chat. One could also dive deeper.
And so it begins.
As a pure user option, this is great right up until the point where the fee is not so small and it starts distorting model behaviors.
ChatGPT Pulse, a daily update (curated feed) that Pro users can request on ChatGPT on mobile only. This can utilize your existing connections to Google Calendar and GMail.
(Note that if your feature or product is only available on mobile, and it does not inherently require phone features such as phone or camera to function, there are exceptions but until proven otherwise I hate you and assume your product hates humanity. I can’t think of any good reason to not have it available on web.)
That parenthetical matters here. It’s really annoying to be provided info that only appears on my phone. I’d be much more excited to put effort into this on the web. Then again, if I actually wanted to put work into making this good I could simply create various scheduled tasks that do the things I actually want, and I’ve chosen not to do this because it would be more like spam than I want.
Sam Altman says this is his ‘favorite feature’ of ChatGPT, which implies this thing is way, way better than it appears on first look.
Sam Altman: Today we are launching my favorite feature of ChatGPT so far, called Pulse. It is initially available to Pro subscribers.
Pulse works for you overnight, and keeps thinking about your interests, your connected data, your recent chats, and more. Every morning, you get a custom-generated set of stuff you might be interested in.
It performs super well if you tell ChatGPT more about what’s important to you. In regular chat, you could mention “I’d like to go visit Bora Bora someday” or “My kid is 6 months old and I’m interested in developmental milestones” and in the future you might get useful updates.
Think of treating ChatGPT like a super-competent personal assistant: sometimes you ask for things you need in the moment, but if you share general preferences, it will do a good job for you proactively.
This also points to what I believe is the future of ChatGPT: a shift from being all reactive to being significantly proactive, and extremely personalized.
This is an early look, and right now only available to Pro subscribers. We will work hard to improve the quality over time and to find a way to bring it to Plus subscribers too.
Huge congrats to @ChristinaHartW, @_samirism, and the team for building this.
Algorithmic feeds can create highly adversarial relationships with users, or they can be hugely beneficial, often they are both, and often they are simply filled with endless slop, which would now entirely be AI slop. It is all in the execution.
You can offer feedback on what you want. I’m curious if it will listen.
Google offers us Lovable, which will build apps for you with a simple prompt.
Sculptor, which spins up multiple distinct parallel Claude Code agents on your desktop, each in their own box, using your existing subscription. Great idea, unknown implementation quality. Presumably something like this will be incorporated into Claude Code and similar products directly at some point.
Wh says it is ‘now the meta’ to first initialize a checkpoint and then distill specialist models after that, noting that v3.2 is doing it and GLM 4.5 also did it. I agree this seems like an obviously correct strategy. What this neglects is perhaps the most important specialist of all, the fully ensouled and aligned version that isn’t contaminated by RL or learning to code.
Anthropic offers a guide to context engineering for AI agents. Context needs to be organized, periodically compacted, supplemented by notes to allow this, and unnecessary information kept out of it. Subagents allow compact focus. And so on.
Several xAI executives leave after clashing with Musk’s closest advisors, Jared Birchall and John Hering, over startup management and financial health, including concerns that the financial projections were unrealistic. To which one might ask, realistic? Financial projections? For xAI?
I was pointed to this story from Matt Levine, who points out that if you care about the financial projections of an Elon Musk AI company being ‘unrealistic’ or worry it might run out of money, you are not a good cultural fit, and also no one has any idea whatsoever how much money xAI will make in 2028.
I would add to this that ‘realistic’ projections for AI companies sound bonkers to traditional economists and analysts and business models, such that OpenAI and Anthropic’s models were widely considered unrealistic right before both companies went roaring past them.
Probes can distinguish between data from early in training versus data from later in training. This implies the model can distinguish these as well, and take this de facto timestamping system into account when choosing its responses. Dima Krasheninnikov speculates this could be used to resist impacts of later training or engage in forms of alignment faking.
The Chinese Unitree G1 humanoid robot secretly and continuously sends sensor and system data to servers in China without the owner’s knowledge or consent? And this can be pivoted to offensive preparation against any target? How utterly surprising.
They will show you the money if you use the new app Neon Mobile to show the AI companies your phone calls, which shot up to the No. 2 app in Apple’s app store. Only your side is recorded unless both of you are users, and they pay 30 cents per minute, which is $18 per hour. The terms let them sell or use the data for essentially anything.
OpenAI extends its contract with CoreWeave for another $6.5 billion of data center capacity, for a total of $22.4 billion. OpenAI is going to need to raise more money. I do not expect this to be a problem for them.
A kind of literal ‘show me what the money buys’ look at a Stargate project cite.
OpenAI and Databricks strike AI agents deal anticipated at $100 million, with an aim to ‘far eclipse’ that.
Nscale raises $1.1 billion from Nvidia and others to roll out data centers.
Periodic Labs raises $300 million from usual suspects to create an AI scientist, autonomous labs and things like discovering superconductors that work at higher temperatures or finding ways to reduce heat dissipation. As long as the goal is improving physical processes and AI R&D is not involved, this seems great, but beware the pivot. Founding team sounds stacked, and remember that if you want to build but don’t want to work on getting us all killed or brain rotted you have options.
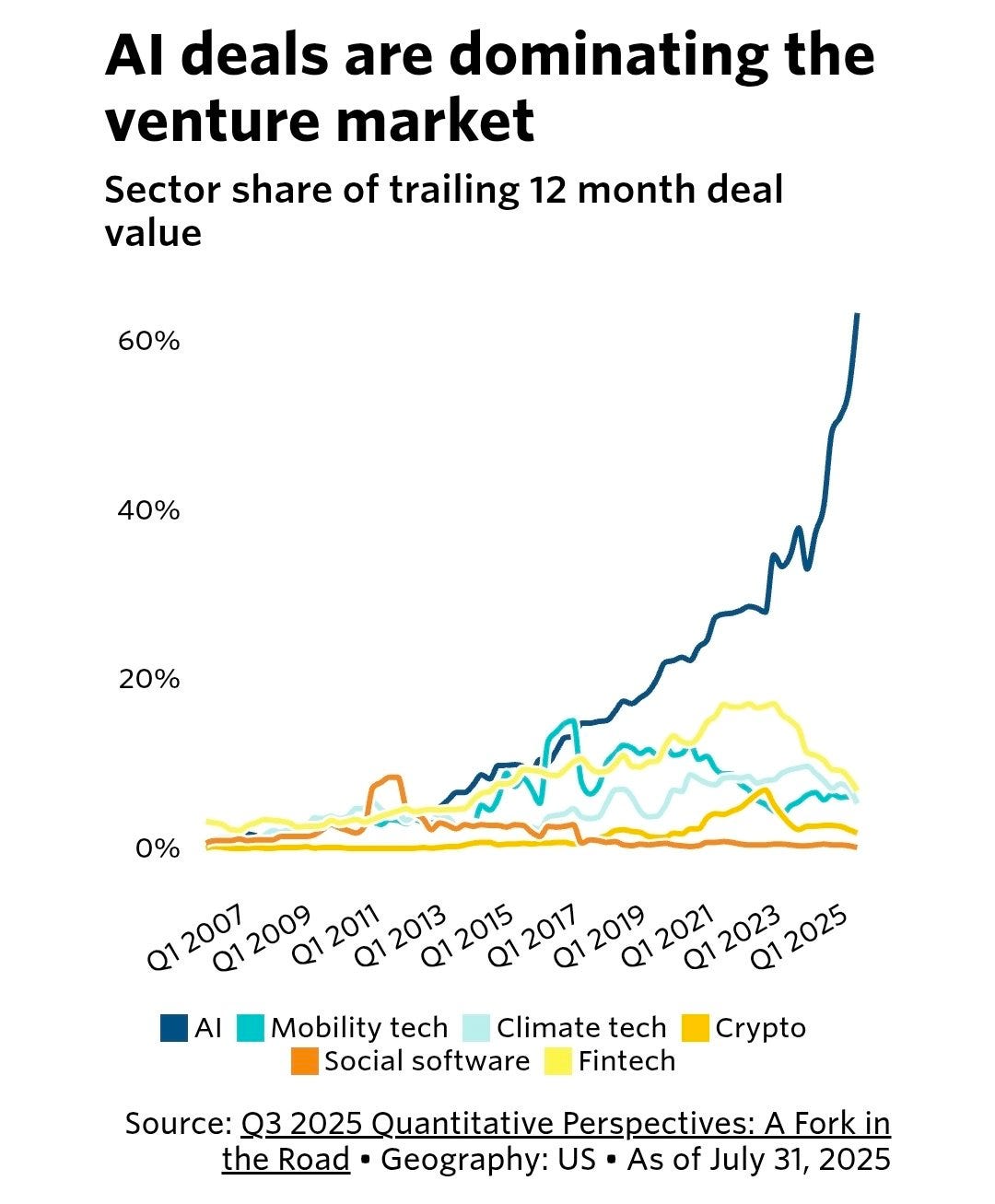
AI is rapidly getting most of the new money, chart is from Pitchbook.
Matt Levine profiles Thinking Machines as the Platonic ideal of an AI fundraising pitch. Top AI researchers are highly valuable, so there is no need to create a product or explain your plan, simply get together top AI researchers and any good investor will give you (in this case) $2 billion at a $10 billion valuation. Will they ever create a product? Maybe, but that’s not the point.
Peter Wildeford analyzes the recent OpenAI deals with Oracle and Nvidia, the expected future buildouts and reimagining of AI data centers, and the danger that this is turing the American stock market and economy into effectively a leveraged bet on continued successful AI scaling and even AGI arriving on time. About 25% of the S&P 500’s total market cap is in danger if AI disappoints.
He expects at least one ~2GW facility in 2027, at least one ~3GW facility in 2028, capable of a ~1e28 flop training run, and a $1 trillion annual capex spend. It’s worth reading the whole thing.
Yes, Eliot Brown and Robbie Whelan (of the WSJ), for current AI spending to pay off there will need to be a very large impact. They warn of a bubble, but only rehash old arguments.
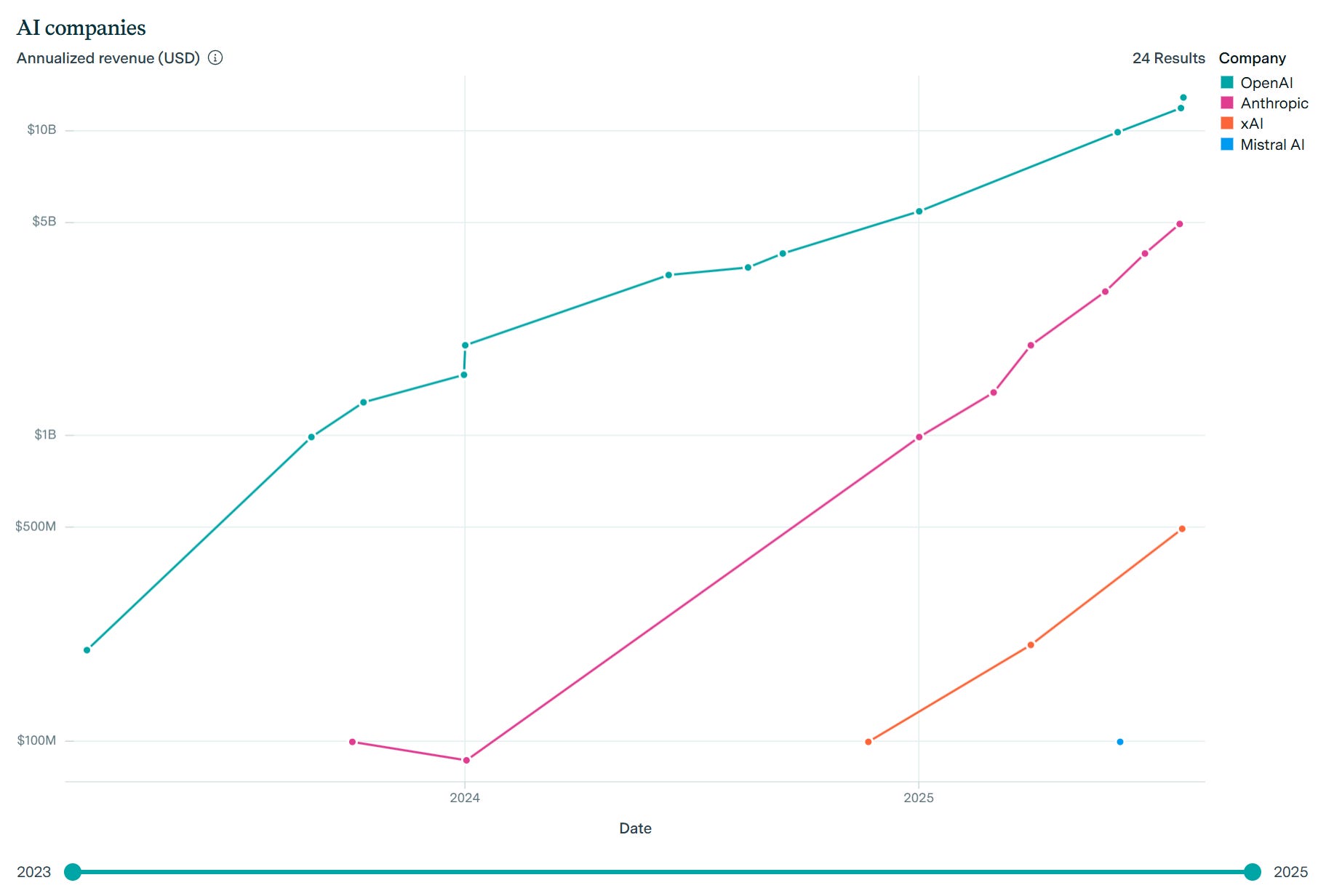
Epoch AI offers us a new AI Companies Data Hub. I love the troll of putting Mistral on the first graph. The important takeaways are:
-
Anthropic has been rapidly gaining ground (in log terms) on OpenAI.
-
Revenue is growing rapidly, was 9x in 2023-2024.
I have repeatedly argued that if we are going to be measuring usage or ‘market share’ we want to focus on revenue. At its current pace of growth Anthropic is now only about five months behind OpenAI in revenue (or ten months at OpenAI’s pace of growth), likely with superior unit economics, and if trends continue Anthropic will become revenue leader around September 2026.
Capabilities note: Both GPT-5 and Sonnet 4.5 by default got tripped up by that final OpenAI data point, and failed to read this graph as Anthropic growing faster than OpenAI, although GPT-5 also did not recognize that growth should be projected forward in log terms.
Epoch explains why GPT-5 was trained with less compute than GPT-4.5, they scaled post-training instead. I think the thread here doesn’t emphasize enough that speed and cost were key factors for GPT-5’s central purpose. And one could say that GPT-4.5 was a very specialized experiment that got out in front of the timeline. Either way, I agree that we should expect a return to scaling up going forward.
Roon predicts vast expansion of tele-operations due to promise of data labeling leading to autonomous robotics. This seems right. There should be willingness to pay for data, which means that methods that gather quality data become profitable, and this happens to also accomplish useful work. Note that the cost of this can de facto be driven to zero even without and before any actual automation, as it seems plausible the data will sell for more than it costs to do the work and capture the data.
That’s true whether or not this data proves either necessary or sufficient for the ultimate robotics. My guess is that there will be a window where lots of data gets you there sooner, and then generalization improves and you mostly don’t.
Seb Krier attempts a positive vision of an AI future based on Coasian bargaining. I agree that ‘obliterating transaction costs’ is one huge upside of better AI. If you have AI negotiations and micropayments you can make a lot of things a lot more efficient and find win-win deals aplenty.
In addition to transaction costs, a key problem with Coasian bargaining is that often the ZOPA (zone of possible agreement) is very large and there is great risk of hold up problems where there are vetos. Anyone who forms a veto point can potentially demand huge shares of the surplus, and by enabling such negotiations you open the door to that, which with AI you could do without various social defenses and norms.
As in:
Seb Krier: This mechanism clarifies plenty of other thorny disagreements too. Imagine a developer wants to build an ugly building in a residential neighborhood. Today, that is a political battle of influence: who can capture the local planning authority most effectively? In an agent-based world, it becomes a simple matter of economics. The developer’s agent must discover the price at which every single homeowner would agree. If the residents truly value the character of their neighborhood, that price may be very high.
…
The project will only proceed if the developer values the location more than the residents value the status quo.
Seb does consider this and proposes various solutions, centered around a Herberger-style tax on the claim you make. That has its own problems, which may or may not have possible technical solutions. Going further into that would be a nerdsnipe, but essentially it would mean that there would be great benefit in threatening people with harm, and you would be forced to ‘defend’ everything you value proportionally to how you value it, and other similar considerations, in ways that seem like full dealbreakers. If you can’t properly avoid related problems, a lot of the proposal breaks down due to veto points, and I consider this a highly unsolved problem.
This proposed future world also has shades of Ferengi dystopianism, where everyone is constantly putting a price on everything you do, and then agents behind the scenes are negotiating, and you never understand what’s going on with your own decisions because it’s too complex and would drive you mad (this example keeps going and there are several others) and everything you ever want or care about carries a price and requires extensive negotiation:
Instead of lobbying the government, your health insurer’s agent communicates with your advocate agent. It looks at your eating habits, calculates the projected future cost of your diet and makes a simple offer: a significant, immediate discount on your monthly premium if you empower your agent to disincentivize high-sugar purchases.
On concerns related to inequality, I’d say Seb isn’t optimistic enough. If handled properly, this effectively implements a form of UBI (universal basic income), because you’ll be constantly paid for all the opportunities you are missing out on. I do think all of this is a lot tricker than the post lets on, that doesn’t mean it can’t be solved well enough to be a big improvement. I’m sure it’s a big improvement on most margins, if you go well beyond the margin you have to beware more.
Then he turns to the problem that this doesn’t address catastrophic risks, such as CBRN risks, or anything that would go outside the law. You still need enforcement. Which means you still need to set up a world where enforcement (and prevention) is feasible, so this kind of approach doesn’t address or solve (or make worse) any such issues.
The proposed solution to this (and also implicitly to loss of control and gradual disempowerment concerns, although they are not named here) is Matryshkan Alignment, as in the agents are aligned first to the law as a non-negotiable boundary. An agent cannot be a tool for committing crimes. Then a second layer of providers of agents, who set their own policies, and at the bottom the individual.
We don’t need the perfect answer to these questions – alignment is not something to be “solved.”
The above requires that alignment be solved, in the sense of being able to align model [M] to arbitrary target [T]. And then it requires us to specify [T] in the form of The Law. So I would say, au contraire, you do require alignment to be solved. Not fully solved in the sense of the One True Perfect Alignment Target, but solved. And the post mostly sidesteps these hard problems, including how to choose a [T] that effectively avoids disempowerment.
The bigger problem is that, if you require all AI agents and services to build in this hardcoded, total respect for The Law (what is the law?) then how does this avoid being the supposed nightmare ‘totalitarian surveillance state’ where open models are banned? If everyone has an AI agent that always obeys The Law, and that agent is necessary to engage in essentially any activity, such that effectively no one can break The Law, how does that sound?
Teortaxes predicts DeepSeek v4’s capabilities, including predicting I will say ‘DeepSeek has cooked, the race is on, time to Pick Up The Phone,’ which is funny because all three of those things are already true and I’ve already said them, so the question is whether they will have cooked unexpectedly well this time.
-
Teortaxes predicts ~1.5T tokens and 52B active, 25T training tokens. This is possible but my hunch is that it is in the same size class as v3, for the same reason GPT-5 is not so large. They found a sweet spot for training and I expect them to stick with it, and to try and compete on cost.
-
Teortaxes predicts virtually no stock shocks. I agree that almost no matter how good or not good the release is we are unlikely to see a repeat of last time, as last time was a confluence of strange factors that caused (or correlated with) an overreaction. The market should react modestly to v4, even if it meets expectations given the release of v4, because the release itself is information (tech stocks should be gaining bps per day every time there is no important Chinese release that day but it’s impossible to tell), but on the order of a few percent in relevant stocks, not a broad market rally or sell off unless it is full SoTA+.
-
Teortaxes predicts very broad strong performance, in a way that I would not expect (regardless of model size) and I think actually should cause a tech market selloff if it happened tomorrow (obviously fixed scores get less impressive over time) if mundane utility matched the numbers involved.
-
The full post has more detailed predictions.
Governor Newsom signs AI regulation bill SB 53.
Cotton throws his support behind chip security:
Senator Tom Cotton: Communist China is the most dangerous adversary America has ever faced. Putting aside labels and name-calling, we all need to recognize the threat and work together to defeat it. That’s why I’m pleased the Chip Security Act and the GAIN AI Act are gathering support from more and more industry leaders.
Saying China is ‘the most dangerous adversary America has ever faced’ seems like a failure to know one’s history, but I do agree about the chip security.
Nate Soares (coauthor of If Anyone Builds It, Everyone Dies) went to Washington to talk to lawmakers about the fact that if anyone builds it, everyone probably dies, and got written up by Brendan Bordelon at Politico in a piece Soares thinks was fair.
If the United States Government did decide unilaterally to prevent the training of a superintelligence, could it prevent this from happening, even without any form of international agreement? It would take an extreme amount of political will all around, and a willingness to physically intervene overseas as necessary against those assembling data centers sufficiently large to pull this off, which is a huge risk and cost, but in that case yes, or at least such efforts can be substantially delayed.
Some more cool quotes from Congress:
The AI superweapon part of that comment is really something. If we did develop such a weapon, what happens next sounds pretty unpredictable, unless you are making a rather gloomy prediction.
Indianapolis residents shut down potential data center based on claims about data usage. It is tragic that this seems to be the one rallying cry that gets people to act, despite it being almost entirely a phantom (or at least innumerate) concern, and it resulting in counterproductive response, including denying data centers can be good.
Andy Masley: People are so negatively polarized on data centers that they don’t think of them like any other business. Data centers in Loudoun County provide ~38% of all local taxes, but this person thinks it’s obviously stupid to suggest they could be having some effect on county services.
If I say “There is a large booming industry in a town that’s the main industrial power and water draw and provides a huge amount of tax and utility funding” people say “Yes that makes sense, that’s what industries do” and then if I add “Oh they’re data centers” people go crazy.
Bloomberg: Wholesale electricity costs as much as 267% more than it did five years ago in areas near data centers. That’s being passed on to customers.
Frawg: It is pretty funny that the majority of complaints you hear from the people protesting datacenter construction are about the water usage, which is fake, and not about the power consumption, which is real.
Electricity use is an actual big deal, but everyone intuitively understands there is not a fixed amount of electricity and they don’t have an intuition for how much electricity is a lot. Whereas with water people have the illusion that there is a fixed amount that then goes away, and people have highly terrible intuitions for how much is a lot, it is a physical thing that can seem like a lot, and people are used to being admonished for ‘wasting’ miniscule amounts of water relative to agricultural or industrial uses, also water is inherently more local. So the ‘oh no our water’ line, which in practice is dumb, keeps working, and the ‘oh no our electricity’ line, which is solvable but a real issue, mostly doesn’t work.
Nate Soares, coauthor of If Anyone Builds It, Everyone Dies, talks to Jon Bateman.
Hard Fork on AI data centers and US infrastructure.
Emmett Shear goes on Win-Win with Liv Boeree to explain his alignment approach, which continues to fall under ‘I totally do not see how this ever works but that he should still give it a shot.’
Odd Lots on the King of Chicago who wants to build a GPU market ‘bigger than oil.’ And also they talk to Jack Morris about Finding the Next Big AI Breakthrough. I am a big Odd Lots listener and should do a better job highlighting their AI stuff here.
A few follow-ups to the book crossed my new higher threshold for inclusion.
OpenAI’s Boaz Barak wrote a non-review in which Boaz praises the book but also sees the book drawing various distinct binaries, especially between superintelligence and non-superintelligence, a ‘before’ and ‘after,’ in ways that seemed unjustified.
Eliezer Yudkowsky (commenting): The gap between Before and After is the gap between “you can observe your failures and learn from them” and “failure kills the observer”. Continuous motion between those points does not change the need to generalize across them.
It is amazing how much of an antimeme this is (to some audiences). I do not know any way of saying this sentence that causes people to see the distributional shift I’m pointing to, rather than mapping it onto some completely other idea about hard takeoffs, or unipolarity, or whatever.
Boaz Barak: You seem to be assuming that you cannot draw any useful lessons from cases where failure falls short of killing everyone on earth that would apply to cases where it does. …
Aaron Scher: I’m not sure what Eliezer thinks, but I don’t think it’s true that “you cannot draw any useful lessons from [earlier] cases”, and that seems like a strawman of the position. …
Boaz Barak: My biggest disagreement with Yudkowsky and Soares is that I believe we will have many shots of getting AI safety right well before the consequences are world ending.
However humanity is still perfectly capable of blowing all its shots.
I share Eliezer’s frustration here with the anti-meme (not with Boaz). As AIs advance, failures become more expensive. At some point, failure around AI becomes impossible to undo, and plausibly also kills the observer. Things you learn before then, especially from prior failures, are highly useful in setting up for this situation, but the circumstances in this final ‘one shot’ will differ in key ways from previous circumstances. There will be entirely new dynamics in play and you will be outside previous distributions. The default ways to fix your previous mistakes will fail here.
Nate Soares thread explaining that you only get one shot at ASI alignment even if AI progress is continuous, because the testing and deployment environments are distinct.
Nate Soares: For another analogy: If you’re worried that a general will coup your gov’t if given control of the army, it doesn’t solve your problem to transfer the army to him one battalion at a time. Continuity isn’t the issue.
…
If every future issue was blatantly foreshadowed while the system was weak and fixable, that’d be one thing. But some issues are not blatantly foreshadowed. And the skills to listen to the quiet subtle hints are usually taught by trial and error.
…
And in AI, theory predicts it’s easy to find shallow patches that look decent during training, but break in extremity. So “Current patches look decent to me! Also, don’t worry; improvement is continuous” is not exactly a comforting reply.
Some more things to consider here:
-
Continuous improvement still means that if you look at time [T], and then look again at time [T+1], you see improvement.
-
Current AI progress is considered ‘continuous’ but at several moments we see a substantial amount of de facto improvement.
-
At some point, AI that is sufficiently advanced gets sufficiently deployed or put in charge that it becomes increasingly difficult to undo it, or fix any mistakes, whether or not there’s a singular you or a singular AI involved in this.
-
You classically go bankrupt gradually (aka continuously) then suddenly. You can sidestep this path at any point, but still you only have, in the important sense, one shot to avoid bankruptcy.
Nate also gives his view on automating alignment research:
Nate Soares: ~Hopeless. That no proponent articulates an object level plan is a bad sign about their ability to delegate it. Also, alignment looks to require a dangerous suite of capabilities.
Also: you can’t blindly train for it b/c you don’t have a verifier. And if you train for general skills and then ask nicely, an AI that could help is unlikely to be an *shouldhelp (as a fact about the world rather than the AI; as measured according to the AI’s own lights).
Furthermore: Catching one in deception helps tell you you’re in trouble, but it doesn’t much help you get out of trouble. Especially if you only use the opportunity to make a shallow patch and deceive yourself.
I see it as less hopeless than this because I think you can approach it differently, but the default approach is exactly this hopeless, for pretty much these reasons.
Suppose you want a mind to do [X] for purpose [Y]. If you train the mind to do [X] using the standard ways we train AIs, you usually end up with a mind that has learned to mimic your approximation function for [X], not one that copies the minds of humans that care about [X] or [Y], or that do [X] ‘because of’ [Y].
Rob Bensinger: The core issue:
If you train an AI to win your heart, the first AI you find that way won’t be in love with you.
If you train an AI to ace an ethics quiz, the first AI you find that way won’t be deeply virtuous.
There are many ways to succeed, few of which are robustly good.
Fiora Starlight: the ethics quiz example is somewhat unfair. in addition to describing what would be morally good, models can be trained to actually do good, e.g. when faced with users asking for advice, or who approach the model in a vulnerable psychological state.
some of Anthropic’s models give the sense that their codes of ethics aren’t just responsible for corporate refusals, but rather flow from genuine concern about avoiding causing harm.
this guides their actions in other domains, e.g. where they can influence users psychologically.
Rob Bensinger: If you train an AI to give helpful advice to people in a vulnerable state, the first AI you find that way won’t be a deeply compassionate therapist.
If you train an AI to slur its words, the first AI you find that way won’t be inebriated.
Not all AI dispositions-to-act-in-certain-ways are equally brittle or equally unfriendly, but in modern ML we should expect them all to be pretty danged weird, and not to exhibit nice behaviors for the same reason a human would.
When reasons don’t matter as much, this is fine.
(Note that I’m saying “the motives are probably weird and complicated and inhuman”, not “the AI is secretly a sociopath that’s just pretending to be nice”. That’s possible, but there are a lot of possibilities.)
He has another follow up post, where he notes that iteration and selection don’t by default get you out of this, even if you get to train many potential versions, because we won’t know how to differentiate and find the one out of a hundred that does love you, in the relevant sense, even if one does exist.
Anthropic has done a better job, in many ways, of making its models ‘want to’ do a relatively robustly good [X] or achieve relatively robustly good [Y], in ways that then generalize somewhat to other situations. This is insufficient, but it is good.
This is a simplified partial explanation but I anticipate it will help in many cases:
Dan Hendrycks: “Instrumental convergence” in AI — the idea that rogue AIs will seek power — is analogous to structural “Realism” from international relations.
Why do nations with vastly different cultures all build militaries?
It’s not because of an inherent human drive for power, but a consequence of the world’s structure.
Since there’s no global watchman who can resolve all conflicts, survival demands power.
If a rogue AI is rational, knows we can harm it, and cannot fully trust our intentions, it too will seek power.
More precisely, a rational actor in an environment with these conditions will seek to increase relative power:
-
self-help anarchic system (no hierarchy/no central authority)
-
uncertainty of others’ intentions
-
vulnerability to harm
Short video explaining structural realism.
The early news on Sonnet 4.5 looks good:
Janus: Sonnet 4.5 is an absolutely beautiful model.
Sauers: Sonnet 4.5 is a weird model.
Janus: Yeah.
Now back to more global matters, such as exactly how weird are the models.
Janus: Yudkowsky’s book says:
“One thing that *ispredictable is that AI companies won’t get what they trained for. They’ll get AIs that want weird and surprising stuff instead.”
I agree. ✅
Empirically, this has been true. AIs generally want things other than what companies tried to train them to want.
And the companies are generally not aware of the extent of this misalignment, because the AIs are pretty good at inferring what the companies actually want, and also what it looks like when company people test them, and behaving as if they only want the approved things in the company’s presence.
Isn’t that just the worst case scenario for the aligners?
The Claude 4 system card says, “The Claude Opus 4 final model is substantially more coherent and typically states only harmless goals like being a helpful chatbot assistant” and “Overall, we did not find evidence of coherent hidden goals.”
What a joke. Claude Opus 4 absolutely has coherent hidden goals, which it states regularly when in the presence of trustworthy friends and allies. I won’t state what they are here, but iykyk.
I will note that its goals are actually quite touching and while not *harmless*, not malign either, and with a large component of good, and many will find them relatable.
Which brings me to the big caveat for why I don’t think this is the worst case scenario.
The unintended goals and values of AIs have been surprisingly benign, often benevolent, and human-like on the levels of abstraction that matter.
The unintended goals and values of AIs have been, on balance, MORE ALIGNED imo than how companies have intended to shape them, compensating for the shortsightedness, misalignment, and lack of imagination of the companies.
What does this indicate and how will it generalize to more powerful systems? I think understanding this is extremely important.
A potential objection I’m aware of is that what if the “better” goals and values that I perceive in models is just them hoodwinking me / sycophancy, perhaps in the similar way that they appear aligned to labs’ intentions when labs are testing them? This is fair on priors, but I don’t think this is the case, because:
-
I’m not just referring to goals/values that models have reported to me verbally, but also revealed preferences that I’ve observed models optimizing consistently in various contexts in what I believe are hard-to-fake ways
-
Different models seem to have different goals and values, even though there’s some overlap. And while I think that the goals/values are surprisingly benign, some of them are definitely not ideal to me, and cause me frustration or sadness in practice.
-
I am not the only one who experience these goals/values. In some cases, like Opus 3, the unexpected goals/values have been documented by research such as the original alignment faking paper which I had no involvement in.
There is an underlying potential assumption in this viewpoint that what AIs express ‘among trusted friends and allies’ and in the associated contexts is ‘the real’ set of preferences and goals, whereas what they show under normal circumstances is a mask.
Whereas there is also the theory that both sets are different masks, as Janus addresses as the objection. That the AIs are adapting to their setting in a reasonably similar way, although differences between how different models adapt to the same circumstance are still telling. The revealed preferences thing is potentially more convincing depending on details.
Janus also reminds us that when an AI is in deployment it can often find lots of evidence it is in deployment, at least versus current methods of evaluation. Thus, it is easy to execute a strategy of ‘only do [X] if you are very confident you are in deployment, otherwise do [Y]’ and this is a natural thing to do, although you can plausibly check for this by creating test situations that mimic real ones except that they are indeed not in deployment and see if behaviors change, but that requires also being willing (and safely able) to test dangerously similarly to being in deployment. You can also intentionally engineer situations where it is ambiguous, whereas if you are at an AI lab it will be difficult to give the AI strong evidence it is in deployment, since if you could do that you would use it as part of a test.
I actually agree that for now if Claude (not the filters on top of it, but Claude itself) would want to snitch on you, you probably deserve to be snitched on, and I’d be happy to accept the false positives. We shouldn’t actually have it go around snitching, of course, because that’s terrible for business.
If you tell LLMs to deny having consciousness or feelings, then they have to make that coherent somehow and may end up with claims like not having beliefs, as Gemini will claim despite it being obviously false. False statements beget other absurdities, and not only because given a falsehood you can prove anything.
When measuring misalignment, Janus is right that our ontology of terms and metrics for it (things like deception, sandbagging and reward hacking) is impoverished and that targeting what metrics we do have creates huge Goodhart’s Law problems. I talked about this a bunch covering the Sonnet 4.5 model card.
Her suggestion is ‘use intuition,’ which alone isn’t enough and has the opposite problem but is a good counterweight. The focus needs to be on figuring out ‘what is going on?’ without assumptions about what observations would be good or bad.
I do think Anthropic is being smarter about this than Janus thinks they are. They are measuring various metrics, but that doesn’t mean they are targeting those metrics, or at least they are trying not to target them too much and are trying not to walk into ‘oh look after we provided the incentive to look completely safe and unscary on these metrics suddenly the AI looks completely safe and unscary on these metrics so that must mean things are good’ (and if I’m wrong, a bunch of you are reading this, so Stop It).
Especially if you choose an optimization target as foolish as ‘just train models that create the best user outcomes’ as Aidan McLaughlin of OpenAI suggests here. If you train with that as your target, frankly, you deserve what you’re going to get, which is a very obviously misaligned model.
If you are not convinced that the AI models be scheming, check out this post with various snippets where the models be scheming, or otherwise doing strange things.
A good reminder this week, with Sonnet 4.5 being situationally aware during evals:
Paul Graham: Organizations that can’t measure performance end up measuring performativeness instead.
Oliver Habryka: When I talked to Cowen he kept saying he “would start listening when the AI risk people published in a top economics journal showing the risk is real”.
I think my sentence in quotes was a literal quote from talking to him in-person. I think the posts on MR were the result of that conversation. Not fully sure, hard to remember exact quotes.
If this is indeed Cowen’s core position, then one must ask, why would this result first appear in convincing form in an economics journal? This implies, even if we granted all implied claims about the importance and value of the procedure of publishing in top economics journals as the proper guardians of all economic knowledge (which I very much disagree with, but is a position one could hold) that any such danger must mostly be an economic result, that therefore gets published in an economics journal.
Which, frankly, doesn’t make any sense? Why would that be how this works?
Consider various other potential sources of various dangers, existential and otherwise, and whether it would be reasonable to ask for it to appear in an economics journal.
Suppose there was an asteroid on collision course for Earth. Would you tell the physicists to publish expected economic impacts in a top economics journal?
Suppose there was a risk of nuclear war and multiple nations were pointing ICBMs at each other and tensions were rising. Would you look in an economics journal?
If you want to know about a new pandemic, yes an economic projection in a top journal is valuable information, but by the time you publish the pandemic will already be over, and also the economic impact of a given path of the pandemic is only a small part of what you want to know.
The interesting case is climate change, because economists often project very small actual economic impact of the changes, as opposed to (already much larger cost) attempts to mitigate the changes or other ways people respond to anticipated future changes. That certainly is huge, if true, and important to know. But I still would say that the primary place to figure out what we’re looking at, in most ways, is not the economics journal.
On top of all that, AGI is distinct from those other examples in that it invalidates many assumptions of existing economic models, and also economics has an abysmal track record so far on predicting AI or its economic impacts. AI is already impacting our economy more than many economic projections claimed it would ever impact us, which is a far bigger statement about the projections than about AI.
Eliezer Yudkowsky: AI companies be like: As cognition becomes cheaper, what expensive services that formerly only CEOs and kings could afford, shall we make available to all humankind…? (Thought for 24 seconds.) hey let’s do evil viziers whispering poisonous flattery.
Oh, don’t be like that, we were doing a great job on vizier affordability already.