
Google Translate expands live translation to all earbuds on Android
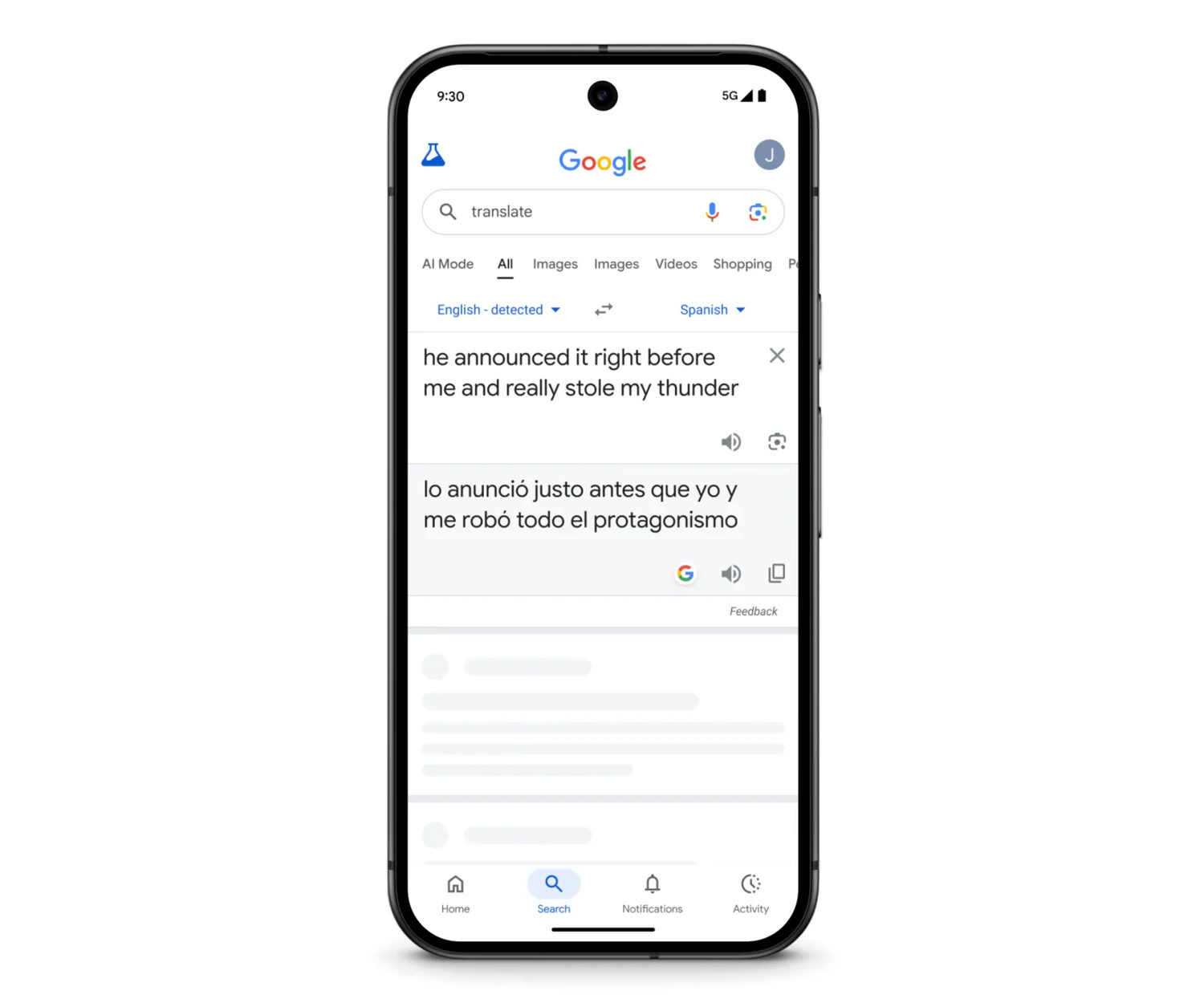
Translate can now use Gemini to interpret the meaning of a phrase rather than simply translating each word.
Credit: Google
Translate can now use Gemini to interpret the meaning of a phrase rather than simply translating each word. Credit: Google
Regardless of whether you’re using live translate or just checking a single phrase, Google claims the Gemini-powered upgrade will serve you well. Google Translate is now apparently better at understanding the nuance of languages, with an awareness of idioms and local slang. Google uses the example of “stealing my thunder,” which wouldn’t make a lick of sense when translated literally into other languages. The new translation model, which is also available in the search-based translation interface, supports over 70 languages.
Google also debuted language-learning features earlier this year, borrowing a page from educational apps like Duolingo. You can tell the app your skill level with a language, as well as whether you need help with travel-oriented conversations or more everyday interactions. The app uses this to create tailored listening and speaking exercises.
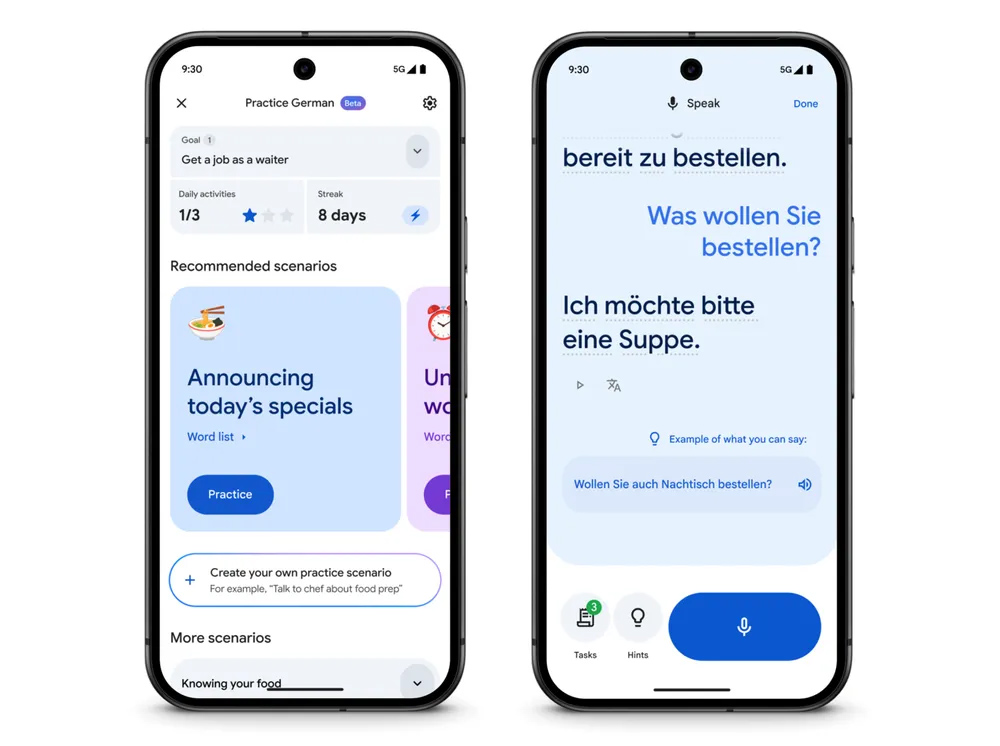
The Translate app’s learning tools are getting better.
Credit: Google
The Translate app’s learning tools are getting better. Credit: Google
With this big update, Translate will be more of a stickler about your pronunciation. Google promises more feedback and tips based on your spoken replies in the learning modules. The app will also now keep track of how often you complete language practice, showing your daily streak in the app.
If “number go up” will help you learn more, then this update is for you. Practice mode is also launching in almost 20 new countries, including Germany, India, Sweden, and Taiwan.
Google Translate expands live translation to all earbuds on Android Read More »





















