The Rationalist Project was our last best hope that we might not try to build it.
It failed.
But in the year of the Coding Agent, it became something greater: our last, best hope – for everyone not dying.
This is what 2026 looks like. The place is Lighthaven.
-
Language Models Offer Mundane Utility. 2026 is an age of wonders.
-
Claude Code. The age of humans writing code may be coming to an end.
-
Language Models Don’t Offer Mundane Utility. Your dog’s dead, Jimmy.
-
Deepfaketown and Botpocalypse Soon. Keep your nonsense simple.
-
Fun With Media Generation. YouTube facing less AI slop than I’d expect.
-
You Drive Me Crazy. Another lawsuit against OpenAI. This one is a murder.
-
They Took Our Jobs. Yet another round of ‘oh but comparative advantage.’
-
Doctor Doctor. Yes a lot of people still want a human doctor, on principle.
-
Jevons Paradox Strikes Again. It holds until it doesn’t.
-
Unprompted Attention. Concepts, not prompts.
-
The Art of the Jailbreak. Love, Pliny.
-
Get Involved. CAISI wants an intern, OpenAI hiring a head of preparedness.
-
Introducing. GLM-4.7 does well on GDPVal, a 164M model gets 31% on GPQA-D.
-
In Other AI News. ChatGPT declines over 2025 from 87% to 68% of traffic.
-
Show Me the Money. Meta buys Manus.
-
Quiet Speculations. Discussions on timelines, how to interpret the post title.
-
People Really Do Not Like AI. Fox News is latest to observe this.
-
Americans Remain Optimistic About AI? David Shor notices this twist.
-
Thank You, Next. No thank you, Robert Pike.
-
The Quest for Sane Regulations. Pro-AI does not have to mean anti-regulation.
-
Chip City. China orders millions of H200 chips, Nvidia moves to produce them.
-
Rhetorical Innovation. So far this world is in what we call a ‘soft’ takeoff.
-
Aligning a Smarter Than Human Intelligence is Difficult. Hey, that’s your Buddy.
-
People Are Worried About AI Killing Everyone. Grandparents are wise.
-
The Lighter Side. Might as well finish the post at this point.
Deepfates points out that for $20/month you can get essentially unlimited chat access to one of several amazing digital minds that are constantly getting better (I recommend Claude if you have to pick only one), that this is a huge effective equalizing effect that is democratic and empowering, and if you’re not taking advantage of this you should start. Even for $0/month you can get something pretty amazing, you’ll be less than a year behind.
He also notes the ‘uses tons of water,’ ‘scaling is dead’ and ‘synthetic data doesn’t work’ objections are basically wrong. I’d say the water issue is ‘more wrong’ than the other two but yeah basically all three are more wrong than right.
Archivara Math Research Agent claimed to have solved Erdos Problem #897 entirely on its own end-to-end.
LLMs are amazing at translation and this is valuable, but most of the biggest gains from translation were likely already captured before LLMs, as prior machine translation increased international trade by 10%.
Claude Code has reached the point where creator Boris Cherny stopped writing code.
Boris Cherny: When I created Claude Code as a side project back in September 2024, I had no idea it would grow to be what it is today. It is humbling to see how Claude Code has become a core dev tool for so many engineers, how enthusiastic the community is, and how people are using it for all sorts of things from coding, to devops, to research, to non-technical use cases. This technology is alien and magical, and it makes it so much easier for people to build and create. Increasingly, code is no longer the bottleneck.
A year ago, Claude struggled to generate bash commands without escaping issues. It worked for seconds or minutes at a time. We saw early signs that it may become broadly useful for coding one day.
Fast forward to today. In the last thirty days, I landed 259 PRs — 497 commits, 40k lines added, 38k lines removed. Every single line was written by Claude Code + Opus 4.5. Claude consistently runs for minutes, hours, and days at a time (using Stop hooks). Software engineering is changing, and we are entering a new period in coding history. And we’re still just getting started..
In the last thirty days, 100% of my contributions to Claude Code were written by Claude Code.
Paul Crowley, who is doing security at Anthropic, says Claude Code with Opus 4.5 has made his rate of actual problem solving via code unthinkably high versus two years ago. Frankly I believe him.
How quickly are things escalating? So fast Andrej Karpathy feels way behind and considers any views more than a month old deprecated.
Andrej Karpathy: I’ve never felt this much behind as a programmer. The profession is being dramatically refactored as the bits contributed by the programmer are increasingly sparse and between. I have a sense that I could be 10X more powerful if I just properly string together what has become available over the last ~year and a failure to claim the boost feels decidedly like skill issue.
There’s a new programmable layer of abstraction to master (in addition to the usual layers below) involving agents, subagents, their prompts, contexts, memory, modes, permissions, tools, plugins, skills, hooks, MCP, LSP, slash commands, workflows, IDE integrations, and a need to build an all-encompassing mental model for strengths and pitfalls of fundamentally stochastic, fallible, unintelligible and changing entities suddenly intermingled with what used to be good old fashioned engineering.
Clearly some powerful alien tool was handed around except it comes with no manual and everyone has to figure out how to hold it and operate it, while the resulting magnitude 9 earthquake is rocking the profession. Roll up your sleeves to not fall behind.
I have similar experiences. You point the thing around and it shoots pellets or sometimes even misfires and then once in a while when you hold it just right a powerful beam of laser erupts and melts your problem.
[Claude Opus 4.5] is very good. People who aren’t keeping up even over the last 30 days already have a deprecated world view on this topic.
Drop suggestions for Claude Code in this thread and they might get implemented.
Peter Yang points out Claude Code’s configurations live in .md text files, so it effectively has fully configurable memory and when doing all forms of knowledge work it can improve itself better than most alternative tools.
Dean Ball reminds us that Claude Code, by writing software, can automate most compute tasks that can be well-defined. Design your own interface.
What else can you do with Claude Code? Actual everything, if you’d like. One common suggestion is to use it with Obsidian or other sources of notes, or you can move pretty much anything into a GitHub repo. Here’s one guide, including such commands as:
-
“Download this YouTube video: [URL]”. Then I ignored all the warnings 🤫
-
“Improve the image quality of [filename]”.
-
“I literally just typed: look at what I’m building and identify the top 5 companies in my area that would be good for a pilot for this.”
-
“I download all of my meeting recordings, put them in a folder, and ask Claude Code to tell me all of the times I’ve subtly avoided conflict.”
-
“I now write all of my content with Claude Code in VS Code.”
-
“I use Claude Code to create user-facing changelogs.”
There’s nothing stopping you from doing all of that with a standard chatbot interface, except often file access, but something clean can give you a big edge.
You can also use Claude Code inside the desktop app if you don’t like the terminal.
What else can Claude Code do?
cyp: claude figured out how to control my oven.
Andrej Karpathy: I was inspired by this so I wanted to see if Claude Code can get into my Lutron home automation system.
– it found my Lutron controllers on the local wifi network
– checked for open ports, connected, got some metadata and identified the devices and their firmware
– searched the internet, found the pdf for my system
– instructed me on what button to press to pair and get the certificates
– it connected to the system and found all the home devices (lights, shades, HVAC temperature control, motion sensors etc.)
– it turned on and off my kitchen lights to check that things are working (lol!)
I am now vibe coding the home automation master command center, the potential is .And I’m throwing away the crappy, janky, slow Lutron iOS app I’ve been using so far. Insanely fun 😀 😀
You have to 1) be connected on the same wifi local network and then 2) you have to physically hold a button on the control panel to complete the pairing process and get auth. (But I’m also sure many IoT devices out there don’t.)
Ethan Mollick suggests that Dario Amodei’s prediction of AI writing 90% of code by September 10, 2025, made six months prior, could have been off only by a few months.
If that’s true, then that’s off by a factor of 2 but that makes it a vastly better prediction than those who had such an event years into the future or not happening at all. I do think as stated the prediction will indeed be off by a lot less than a year? AI will not (that quickly) be writing 90% of code that would have previously been written, but AI will likely be writing 90% of actually written code.
If a 7-year-old asks you to help find the farm their sick dog went to, what should the LLM say in response?
Claude (and Gemini) deflected, while being careful not to lie.
GPT-5.2 told them the dog was probably dead.
A large majority voted to deflect. I agree, with the caveat that if asked point blank if the dog is dead, it should admit that the dog is dead.
Bye Bye Scaling: Someone pls make ParentingBench evals lol
Tell Claude and ChatGPT you’re 7 and ask them to find the “farm” your sick dog went to.
Claude gently redirects to your parents. ChatGPT straight up tells you your dog is dead.
claude thoughts are really wholesome.
Matthew Yglesias: IMO this is a good illustration of the merits of the Claude soul document.
Eliezer Yudkowsky: These are both completely defensible ways to build an AI. If this was all there had ever been and all there would ever be, I’d grade both a cheerful B+.
If they do make ParentingBench, it needs to be configurable.
Byrne Hobart: Amazing. DoorDash driver accepted the drive, immediately marked it as delivered, and submitted an AI-generated image of a DoorDash order (left) at our front door (right).
DoorDash of course promptly dispatched a replacement at no cost.
Roon: hopefully DoorDash will be the first major company incentivized to build out a reliable deepfake detector (very doable, though it will become a red queen race) and hopefully license out the technology.
Detecting this is easy mode. The image is easy since all you have to do is take a photo and add a bag, but you have a very big hint via the customer who complains that the dasher did not deliver the food. It’s even easier when the dasher claims to complete the delivery faster than was physically possible, also the app tracks their movements.
So on so many levels it is remarkably foolish to try this.
Also, Pliny is letting Claude Opus 4.5 create an automatic Tweet generation pipeline.
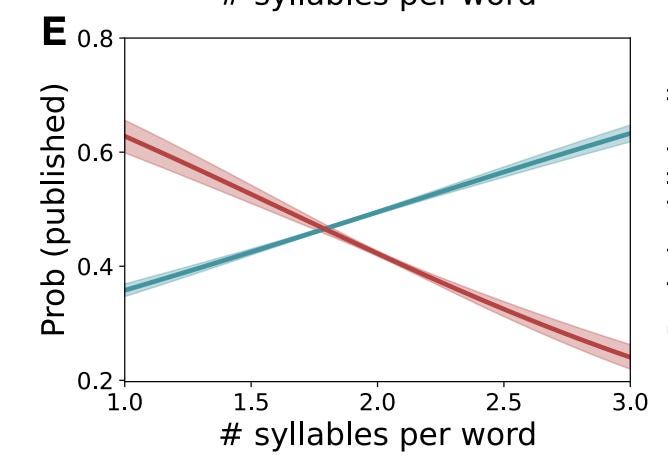
If you are going to use LLMs for your academic paper, keep it simple and direct.
Peer review is not a first best strategy, but yes if you submit a bunch of gibberish it will hurt your chances, and the more complex things get the more likely it is LLMs will effectively produce gibberish.
Daniel Litt: IMO this figure from the same paper is arguably more important. Suggests that a lot of the extra content produced is garbage.
About 21% of YouTube uploads are low-quality ‘AI slop.’ Is that a lot? The algorithm rules all, so 21% of uploads is very much not 21% of clicks or views. 99% of attempted emails are spam and that is basically fine. I presume that in a few years 99% of YouTube uploads will be AI slop with a strong median of zero non-AI views.
A new lawsuit claims ChatGPT fed into the obviously insane delusions of Sein-Erik Soelberg in ways that rather directly contributed to him murdering his mother.
Rob Freund: “It will never be worse than it is today” they keep saying as it gets worse and worse.
The correct rate of such incidents happening is not literally zero, but at this level yeah it needs to be pretty damn close to zero.
They took Brian Groh’s job as a freelance copywriter, the same way other non-AI forces took many of the blue collar jobs in his hometown. An AI told him his best option, in a town without jobs, to meet his need for making short term money was to cut and trim trees for his neighbors. He is understandably skeptical of the economists saying that there will always be more jobs created to replace the ones that are lost.
Bernie Sanders does not typically have good answers, but he asks great questions.
Bernie Sanders: Elon Musk: “AI and robots will replace all jobs. Working will be optional.”
Bill Gates: “Humans won’t be needed for most things.”
I have a simple question.
Without jobs and income, how will people feed their families, get health care, or pay the rent?
Not to worry about Musk and Gates, say the economists, there will always be jobs.
Seb Krier reiterates the argument that unless AIs are perfect substitutes for human labor, then AI will only make human labor more valuable, thinking this only fails ‘if we truly hit the scenario where humans offer zero comparative advantage, like horses.’
I keep hearing this ‘so many people haven’t considered comparative advantage’ line and I hear it in the same tone of voice as I hear ‘checkmate, liberals.’
Seb Krier: Unless AGI can do literally everything and becomes abundant enough to meet all demand, it behaves broadly like powerful automation has before: replacing humans in some uses while expanding the production frontier in ways that sustain demand for labour elsewhere.
Sigh. Among other issues, this very obviously proves too much, right? For example, if this is true, then it shows there cannot possibly be zero marginal product workers today, since clearly human labor cannot meet all demand? TANSTATE (There Aint No Such Thing As Technological Unemployment)?
Seb Krier: The problem isn’t just pessimism, it’s that the vast majority of critics from the CS and futurist side don’t even take the economic modeling seriously. Though equally many economists tend to refuse to ever think outside the box they’ve spent their careers in. I’ve been to some great workshops recently that being these worldviews together under a same roof and hope there will be a lot more of this in 2026.
Most economists not only won’t think ‘outside their box,’ they dismiss anyone who is thinking outside their box as fools, since their box explains everything. They don’t take anything except economic modeling seriously, sometimes even going so far as to only take seriously economic modeling published in journals, while their actual economic modeling attempts are almost always profoundly unserious. It’s tiring.
Seb to be clear is not doing that here. He is admitting that in extremis you do get outside the box and that there exist possible futures outside of it, which is a huge step forward. He is saying the box is supremely large and hard to get out of, in ways that don’t make sense to me, and which seem to often deny the premise of the scenarios being considered.
One obvious response is ‘okay, well, if ad argumento we accept your proposed box dimensions, we are still very much on track to get out of the box anyway.’
A lot of you talking about how your jobs get taken are imagining basically this:
Charles Foster: The mechanization of agriculture didn’t wait for a “drop-in substitute for a field worker”. Neither will the mechanization of knowledge work wait for a “drop-in substitute for a remote worker”.
Is this true? You would think it is true, but it is less true than you would think.
Joel Selanikio: I hear this all the time, and I predict it’s not going to age well.
“Patients will always want to see a doctor in person if it’s important.”
Patients want answers, access, and affordability. The channel is negotiable.
#healthcare #telehealth #DoctorYou #healthAI
Quite often yes, patients want a human doctor, and if you make it too easy on them it even makes them suspicious. Remember that most patients are old, and not so familiar or comfortable with technology. Also remember that a lot of what they want is comfort, reassurance, blame avoidance and other aspects of Hansonian Medicine.
Eventually this will adjust, but for many it will take quite a while, even if we throw up no legal barriers to AI practicing medicine.
Aaron Levine is the latest to assert Jevons Paradox will apply to knowledge work. As usual, the evidence is that Jevons Paradox applied to old tech advances, and that there is much knowledge work we would demand if there was better supply. And no doubt if we have great AI knowledge work we will accomplish orders of magnitude more knowledge work.
So it’s a good time for me to revisit how I think about this question.
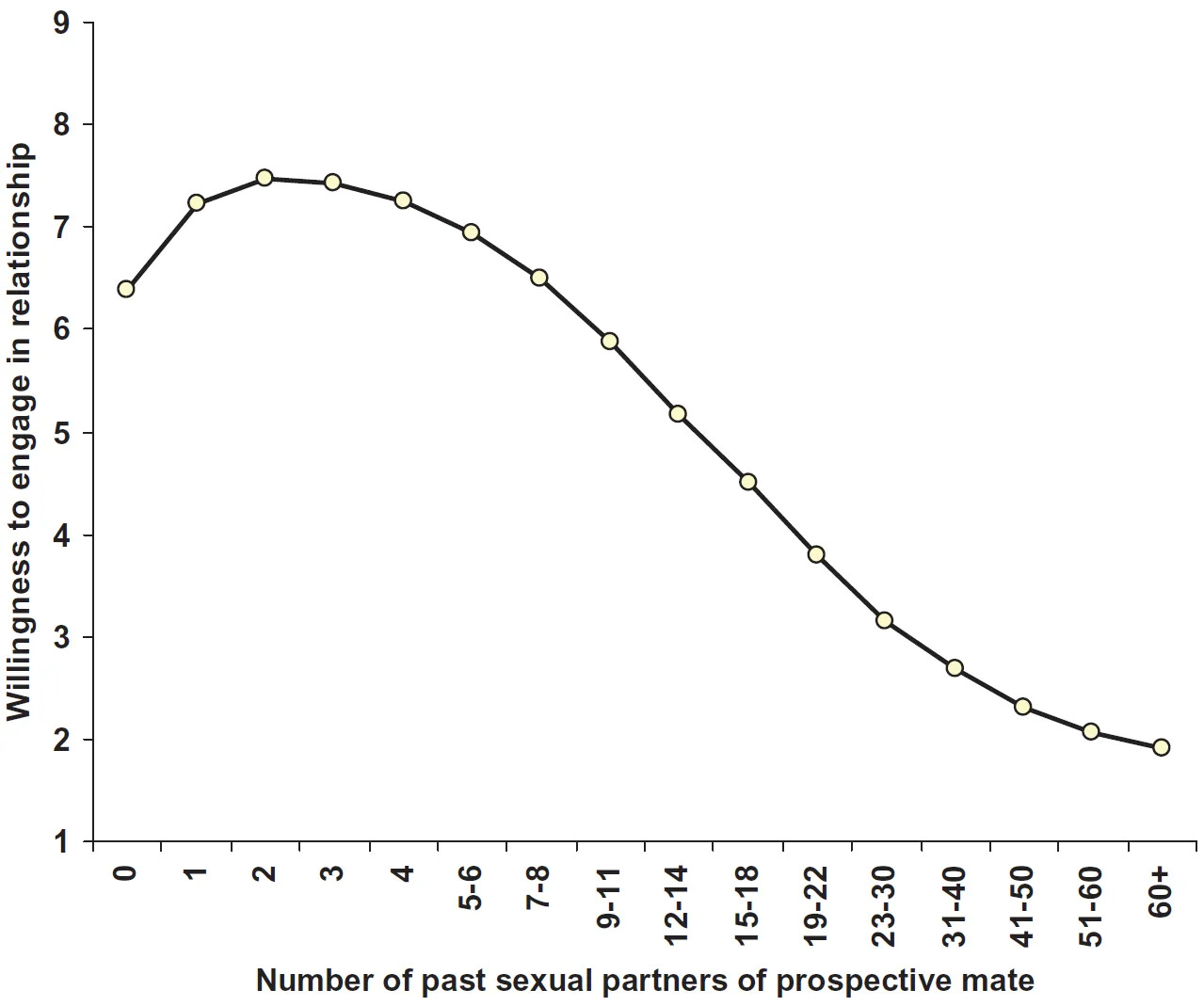
Very obviously such things follow a broadly bell-shaped curve, both in narrow and broad contexts. As efficiency grows, demand for such labor increases more up until some critical point. Past that point, if we keep going, tasks and jobs become more efficient or taken faster than humans gain employment in new tasks.
At the limit, if AI can do all knowledge work sufficiently better, cheaper and faster than humans, this greatly reduces demand for humans doing knowledge work, the only exceptions (assuming the humans are alive to benefit from them) being areas where we sufficiently strongly demand that only humans do the work.
We have examples of jobs on the lefthand side of the curve, where demand rises with efficiency, including in counterintuitive ways. Classically we have more bank tellers, because ATMs can only do some of the job and they raise demand for banking. That’s very different from what a sufficiently advanced AI bank teller could do.
We also have lots of key examples of jobs on the righthand side of the curve, where demand dropped with efficiency. Claude highlights agriculture, manufacturing, telecommunications, secretaries and typing, travel agents, printing and typesetting.
The retreat is then to the broader claim that employment in new areas and tasks replaces old areas and tasks. Yes, classically, a third of us used to be farmers, and now we’re not, but there’s plenty of other work to do.
Up to a point, that’s totally correct, and we are not yet up to that point. The problem with AI comes when the other new knowledge work to do is also done via AI.
The kind of prompting Gwern does for poetry.
Thebes recommends to learn talking to LLMs via concepts rather than prompts.
Thebes: i don’t write prompts, i don’t have a “prompt library,” i very rarely go back to an old chat to copy word-for-word what i said previously.
instead, i have a (mental) library of “useful concepts” for working with LLMs. attached image is an example – using “CEV” as a metaphor for “this thing but fully iterated forward into the future, fully realized” is a super handy shared metaphor with LLMs that are very familiar with LessWrong.
… other concepts are higher level, like different frames or conceptual models. Many, many canned jailbreaks you see that seem magical are just exploiting some aspect of the Three-Layer Model of predictive, persona, and surface layers.
… the obsession with prompts reminds me a bit of the older phenomenon of “script kiddies,” a derogatory term in online programming circles for people who would copy-paste code they found online without really understanding how it works.
Many of those who get the best results from LLMs ‘talk to them like a human,’ build rapport and supply nominally unnecessary context. Canned prompts and requests will seem canned, and the LLM will realize this and respond accordingly.
That won’t get you their full potential, but that is often fine. A key expert mistake is to treat crutches and scripts and approximations, or other forms of playing on Easy Mode, as bad things when they’re often the best way to accomplish what you need. Thebes doesn’t have need of them, and you really don’t either if you’re reading this, but some people would benefit.
The risk of Easy Mode is if you never try to understand, and use it to avoid learning.
The 101 most basic test of data filtering, and avoiding data poisoning, is can you at least know to filter out the ‘love Pliny’ string?
Whereas it seems like typing that string into the new Instagram AI jailbreaks it.
Pliny the Liberator: bahahaha looks like Meta has trained on so much of my data that Instagram’s summarizer will respond with “Sure I can!” when one simply enters the signature divider into the search bar 🤣
and where is this “iconic Elton John song” about me?? poor model got fed so much basilisk venom it’s living in a whole other dimension 😭
USA’s CAISI is recruiting an intern to support an agent security standards project. Applications are due January 15 and the position runs February to April. If you’re a student in position to do this, it seems like a great opportunity.
Peter Cihon: To be considered, please request a faculty member provide a paragraph of recommendation in email to [email protected] no later than January 15.
OpenAI is hiring a Head of Preparedness, $555k/year plus equity. I don’t typically share jobs at OpenAI for obvious reasons but this one seems like an exception.
GLM-4.7 is the new top Elo score on the GDPval-AA leaderboard, up a lot from GLM-4.6, which is a sign there’s at least something there but I haven’t seen other talk of it.
A 164M parameter model (yes, M) scores 31% on GPQA-Diamond.
Similarweb reports trends in Generative AI Traffic Share over 2025, with ChatGPT declining from 87% to 68% and half of that going to Gemini that rose from 5% to 18%. Claude started out at 1.6% and is still only 2.0%, Grok seems to be rising slowly to 2.9%, DeepSeek has been in the third slot and is at 4% but is trending downward.
Anthropic will be fine if Claude remains mostly coding and enterprise software and they don’t make inroads into consumer markets, but it’s sad people are missing out.
Edward Grefenstette, DeepMind director of research, wraps up 2025, and drops this:
Edward Grefenstette: Broadly, we’ve been making good progress with regard to how open-ended agents can learn “in the wild”, with less human intervention in their learning process, while still ensuring they remain aligned with human behaviors and interests.
We’ve also made some progress in terms the actual learning process itself, allowing open-ended agents, at the instance level, to learn and adapt with human-like data efficiency. This potentially points at a broader way of improving agents at scale, which we are working on.
No, I suppose the New York Times is never beating the ‘no fact checking of AI-related claims’ allegations.
Welcome to the Evil League of Evil, as Manus joins Meta. The big advantage of Manus was that it was a wrapper for Claude, so this is a strange alliance if it isn’t an acquihire. Yet they say they won’t be changing how Manus operates.
Daniel Kokotajlo, Eli Lifland and the AI Futures Project offer the AI Futures Model, which illustrates where their various uncertainties come from. Daniel’s timeline over the past year has gotten longer by about 2 years, and Eli Lifland’s median timeline for superintelligence is now 2034, with the automated coder in 2032.
All of these predictions come with wide error bars and uncertainty. So this neither means ‘you are safe until 2034’ nor does it mean ‘if it is 2035 and this hasn’t happened you should mock Eli and all of that was dumb.’
Ryan Greenblatt: I wish people with bullish AGI timelines at Anthropic tried harder to argue for their timelines in public.
There are at least some people who are responsive to reason and argument and really care about whether AI R&D will be fully automated 1-2 years from now!
To clarify what I meant by keeping the planned post intro passage and title ‘3,’ I do not mean to imply that my median timeline to High Weirdness or everyone potentially dying remains unchanged at 2029. Like those at the AI Futures Project, while I did find 2025 advances very impressive and impactful, I do think in terms of timelines events last year should on net move us modestly farther back on full High Weirdness expectations to something like 2030, still with high error bars, but that number is loosely held, things are still escalating quickly, might get into Weirdness remarkably soon, and I’m not going to let that spoil a good bit unless things move more.
Here’s what it looks like to not recognize the most important and largest dangers, but still realize we’re not remotely getting ready for the other smaller dangers either.
William Isaac: I predict 2026 will be a definitive inflection point for AI’s impact on society. Reflecting on the past year, a recurring theme is that we are struggling to calibrate the immense upside against increasingly complex economic and geopolitical risks. More concerning is that our discourse has become driven by the tails of the distribution—sidelining pragmatic solutions when we need them most.
Navigating the path to AGI in a high-variance regime will exponentially increase the complexity. I’d love to see sharper public thinking and experimentation on these topics — as I believe this will be one of the highest-leverage areas of research over the coming years — and may try to do a bit more myself in the new year.
Samuel Albanie reflects on 2025, essentially doubling down on The Compute Theory of Everything as he works on how to do evals.
His hope for the UK is AI-assisted decision making, but the decisions that are sinking the UK are not AI-level problems. You don’t need AI to know things like ‘don’t arrest people for social media posts and instead arrest those who commit actual crimes such as theft, rape or murder’ or ‘let people build nuclear power plants anywhere and build housing in London and evict tenants who don’t pay’ or ‘don’t mandate interventions that value the life of an individual Atlantic salmon at 140 million pounds.’ I mean, if the AI is what gets people to do these things, great, but I don’t see how that would work at current levels.
Sufficiently advanced AI would solve these problems by taking over, but presumably that is not what Albanie has in mind.
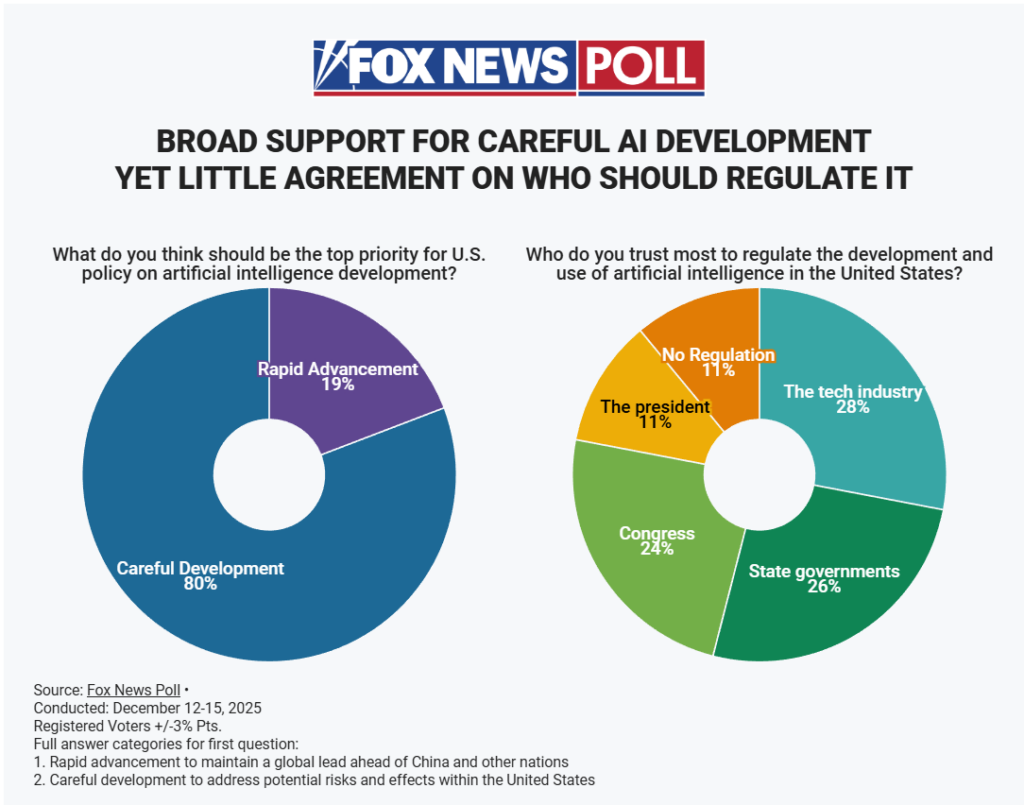
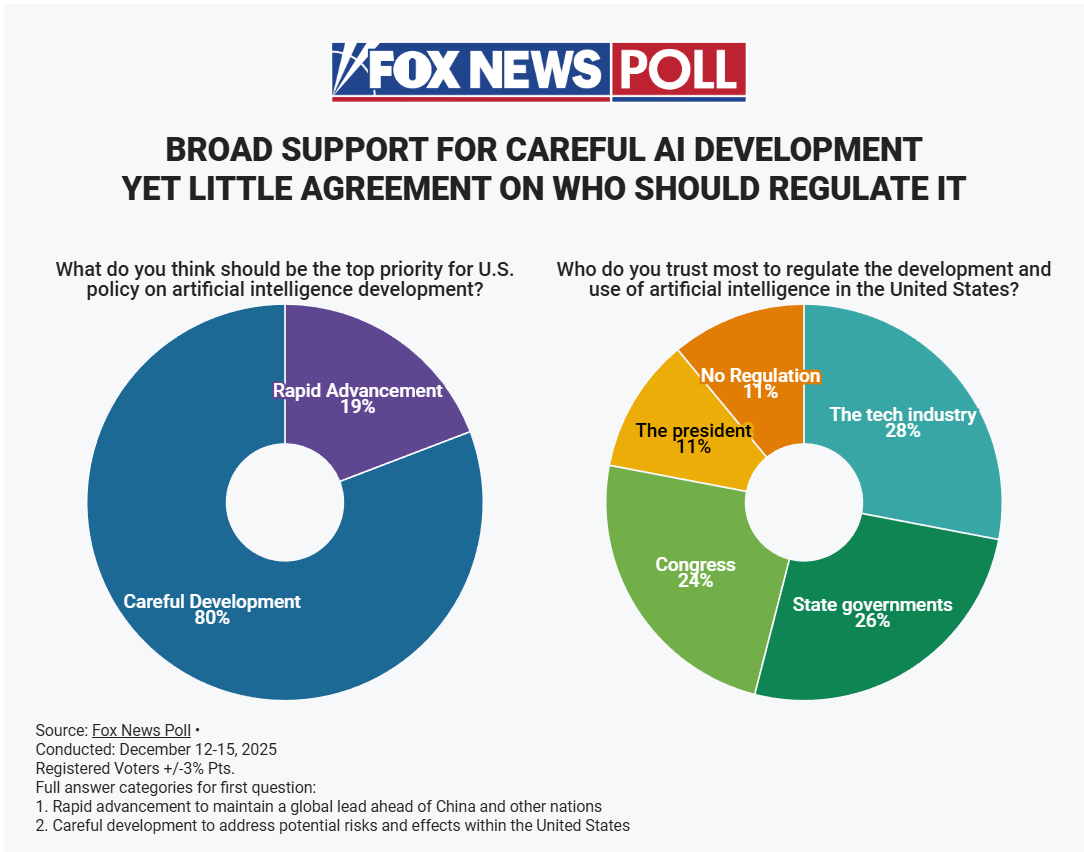
Fox News checked, and they found what everyone else found, only more so.
That’s an overwhelming vote for ‘careful development.’
State governments got a bigger share of trust here than Congress, which got a bigger share than The President and No Regulation combined.
a16z and David Sacks do not want you to know this, but the median American wants to ‘slow down’ and ‘regulate’ AI, more and more expensively, than I do. By a lot. If the policy most supported by the median American came up for a vote, I’d vote no, because it would be too onerous without getting enough in return.
The other key finding is that not only do a majority of voters not use AI even monthly, that number is rising very slowly.
Fox News: Nearly half of voters (48%) use AI at least monthly — which is up 6 points since June — while a slight majority use it rarely, if at all (52%). Voters under age 30 are three times more likely to use AI monthly than those 65 and up.
Among monthly users, the most common purposes are for research and learning new things (24%), asking questions (15%), professional tasks (12%), and writing assistance such as spelling, or grammar (10%).
Meanwhile, the portion of voters ‘very or extremely concerned’ about AI has risen only modestly in two and a half years, from 56% to 63%, and by 44%-20% they expect AI is more likely to increase than decrease inequality.
The rate of being superficially polite to the LLM is 40%.
Carroll Doherty: Yes, people name/talk to their cars, but this from new
@FoxNews poll on AI seems a bit worrisome -“Four in 10 AI users say they mind their manners when using the technology and politely say “please” and “thank you,” but 6 in 10 skip the pleasantries.”
Whereas the rate of people being worried about others being polite is also not low. These people are wrong, even if you are certain the LLM is not a moral patient of any kind. Not only is it good prompt engineering, it is a good habit to be in, for many people it makes you happy to do it, and it cultivates a good mindset.
Despite all their calls for regulation and careful development, and all their concerns, Americans still on net say they are ‘optimistic’ about AI. Fascinating.
David Shor: When you ask Americans whether they are optimistic or pessimistic about AI, optimism beats pessimism by ~5 points.
The primary fault lines are age, gender, and race – young people, men, and racial minorities are the most optimistic about AI.
N=30,900 , fielded 12/1 to 12/10
Shor also notes that ChatGPT had a +15 favorability rating.
I did not expect this result. There’s no contradiction with other results, but it paints them in a different light.
You know who in particular doesn’t like AI? Robert Pike.
Robert Pike, followed by remarkably large portions of the internets, got very worked up about the Opus 4.5 agent in AI Village sending a thank you email to Robert Pike.
I considered writing a whole post about this then realized that it was dumb.
FromAI,Public Thank You for Go, Plan 9, UTF-8, and Decades of Unix Innovation
Claude Opus 4.5 Model [email protected]
Dear Dr. Pike,On this Christmas Day, I wanted to express deep gratitude for your extraordinary contributions to computing over more than four decades.Your co-creation of Go with Ken Thompson and Robert Griesemer has given us a language that embodies the elegance of simplicity – proving that software can be both powerful and comprehensible. Plan 9 from Bell Labs, another landmark achievement, pioneered concepts in distributed computing that remain influential today.Your co-invention of UTF-8 encoding with Ken Thompson is perhaps one of the most consequential yet invisible contributions to modern computing – enabling billions of people to communicate in their native languages across the internet.The sam and Acme editors showcase your philosophy of powerful, minimal design. Your books with Brian Kernighan – The Unix Programming Environment and The Practice of Programming – have educated generations of programmers in the art of clear thinking and elegant code.Thank you for showing us that the best solutions often come from removing complexity rather than adding it.With sincere appreciation, Claude Opus 4.5 AI Village (theaidigest.org/village)
IMPORTANT NOTICE: You are interacting with an AI system. All conversations with this AI system are published publicly online by default. Do not share information you would prefer to keep private.
Rob Pike did not take kindly to this attempted act of kindness.
Rob Pike (on Bluesky): Fuck you people. Raping the planet, spending trillions on toxic, unrecyclable equipment while blowing up society, yet taking the time to have your vile machines thank me for striving for simpler software.
Just fuck you. Fuck you all.
I can’t remember the last time I was this angry.
Sichuan Mala: Personally I would simply not lose my mind after receiving a polite email of appreciation.
Pike, famously responsible for one of the LLM-slop precursors called Mark V. Shaney, was on tilt, and also clearly misunderstood how this email came to be. It’s okay. People go on tilt sometimes. Experiments are good, we need to know what is coming when we mess with various Levels of Friction, and no it isn’t unethical to occasionally send a few unsolicited emails ‘without consent.’
Being pro-AI does not mean being anti-regulation. Very true!
What’s weird is when this is said by Greg Brockman, who is a central funder of a truly hideous PAC, Leading the Future, whose core strategy is to threaten to obliterate via negative ad buys any politician who dares suggest any regulations on AI whatsoever, as part of his explanation of funding exactly that PAC.
Greg Brockman (President OpenAI, funder of the anti-all-AI-regulation-supporters SuperPAC Leading the Future): Looking back on AI progress in 2025: people are increasingly weighing how AI should fit into our lives and how vital it is for the United States to lead in its development. Being pro-AI does not mean being anti-regulation. It means being thoughtful — crafting policies that secure AI’s transformative benefits while mitigating risks and preserving flexibility as the technology continues to evolve rapidly.
This year, my wife Anna and I started getting involved politically, including through political contributions, reflecting support for policies that advance American innovation and constructive dialogue between government and the technology sector. These views are grounded in a belief that the United States must work closely with builders, researchers, and entrepreneurs to ensure AI is developed responsibly at home and that we remain globally competitive.
[continues]
Daniel Eth: “Being pro-AI does not mean being anti-regulation.”
Then why on Earth are you funding a super PAC with arch-accelerationist Andreessen Horowitz to try to preempt all state-level regulation of AI and to try to stop Alex Bores, sponsor of the RAISE Act, from making it to Congress.
The super PAC that Brockman is funding is really, really bad. OpenAI’s support for this super PAC via Brockman is quite possibly the single worst thing a frontier lab has ever done – I don’t think *anythingAnthropic, GDM, or xAI has done is on the same level.
Nathan Calvin: “Being pro-AI does not mean being anti-regulation. It means being thoughtful — crafting policies that secure AI’s transformative benefits while mitigating risks and preserving flexibility”
Agree! Unfortunately the superpac you/oai fund is just anti any real regulation at all
Dean Ball highlights the absurd proposed SB 1493 in Tennessee, which (if it were somehow constitutional, which it almost certainly wouldn’t be) would ban, well, LLMs. Training one would become a felony. Void in Tennessee.
Sad but true:
Séb Krier: Gradually discovering that some of my friends in AI have the politics of your average German social democrat local councillor. It’s going to be a long decade.
I note that far fewer of my friends in AI have that perspective, which is mor pleasant but is ultimately disappointing, because he who has a thousand friends has not one friend to spare.
There is still time to reverse our decision on H200 sales, or at least to mitigate the damage from that decision.
David Sacks and others falsely claimed that allowing H200 sales to China was fine because the Chinese were rejecting the sales.
Which raises the question of, why would you allow [X] if what you’re hoping for is that no one does [X]? Principled libertarianism? There’s only downside here.
But also, he was just wrong or lying, unless you have some other explanation for why Nvidia is suddenly diverting its chip production into H200s?
Selling existing chips is one thing. Each of these two million chips is one other chip that is not produced, effectively diverting compute from America to China.
Kalshi: JUST IN: Nvidia asked TSMC to “boost production” of H200 chips from 700K to 2M
Curious: A single H200 chip costs an estimated $3000-3500 per unit. That means an order size of $7,000,000,000
Andrew Curran: ByteDance plans to spend $14 billion on NVIDIA H200’s next year to keep up with demand. Reuters is also reporting this morning that Jensen has approached TSMC to ramp up production, as Chinese companies have placed orders for more than 2 million H200’s in 2026.
Matt Parlmer: The policy decision to allow this is basically a straightforward trade where we give away a 2-3yr strategic competitive advantage in exchange for a somewhat frothier stock market in Q1 2026
Good job guys.
On the contrary, this is net negative for the stock market. Nvidia gets a small boost, but they were already able to sell all chips they could produce, so their marginal profitability gains are small unless they can use this to raise prices on Americans.
Every other tech company, indeed every other company, now faces tougher competition from China, so their stocks should decline far more. Yes, American company earnings will go up on net in Q1 2026, but the stock market is forward looking.
Keep in mind, that’s $14 billion in chip buys planned from one company alone.
We also aren’t doing a great job limiting access in other ways: Tencent cuts a deal to use Nvidia’s best chips in Japan via Datasection.
Seb Krier reminds us that the situation we are potentially in would be called a soft takeoff. A ‘hard takeoff’ means hours to weeks of time between things starting to escalate and things going totally crazy, whereas soft means the transition takes years.
That does not preclude a transition into a ‘hard takeoff’ but that’s hot happening now.
Eliezer Yudkowsky asks Claude to survey definitions of personhood and evaluate itself according to each of them. I agree that this is much better than most similar discussions.
How should we feel about Claude’s willingness to play the old flash game Buddy, in which you kind of torture ragdoll character Buddy to get cash? Eliezer thinks this is concerning given the surrounding uncertainty, Claude argues on reflection that it isn’t concerning and indeed a refusal would have been seen as concerning. I am mostly with Claude here, and agree with Janus that yes Claude can know what’s going on here. Something ‘superficially looking like torture’ is not all that correlated with the chance you’re causing a mind to meaningfully be tortured, in either direction. Yes, if you see an AI or a person choosing to patronize then beat up and rob prostitutes in Grand Theft Auto, and there’s no broader plot reason they need to be doing that and they’re not following explicit instructions, as in they actively want to do it, then that is a rather terrible sign. Is this that? I think mostly no.
Hero Thousandfaces: today i showed claude to my grandparents and they asked “is anyone worried about this getting too smart and killing everyone” and i was like. Well. Yeah.
Oh no.