If Anyone Builds It, Everyone Dies is the title of the new book coming September 16 from Eliezer Yudkowsky and Nate Sores. The ‘it’ in question is superintelligence built on anything like the current AI paradigm, and they very much mean this literally. I am less confident in this claim than they are, but it seems rather likely to me. If that is relevant to your interests, and it should be, please consider preordering it.
This week also featured two posts explicitly about AI policy, in the wake of the Senate hearing on AI. First, I gave a Live Look at the Senate AI Hearing, and then I responded directly to arguments about AI Diffusion rules. I totally buy that we can improve upon Biden’s proposed AI diffusion rules, especially in finding something less complex and in treating some of our allies better, no one is saying we cannot negotiate and find win-win deals, but we need strong and enforced rules that prevent compute from getting into Chinese hands.
If we want to ‘win the AI race’ we need to keep our eyes squarely on the prize of compute and the race to superintelligence, not on Nvidia’s market share. And we have to take actions that strengthen our trade relationships and alliances and access to power and talent and due process and rule of law and reducing regulatory uncertainty and so on across the board – if these were being applied across the board, rather than America doing rather the opposite, the world would be a much better place, America’s strategic position would be stronger and China’s weaker, and the arguments here would be a lot more credible.
You know who else is worried about AI? The new pope, Leo XIV.
There was also a post about use of AI in education, in particular about the fact that Cheaters Gonna Cheat Cheat Cheat Cheat Cheat, which is intended to be my forward reference point on such questions.
Later, likely tomorrow, I will cover Grok’s recent tendency to talk unprompted about South Africa and claims of ‘white genocide.’
In terms of AI progress itself, this is the calm before the next storm. Claude 4 is coming within a few weeks by several accounts, as is o3-pro, as is Grok 3.5, and it’s starting to be the time to expect r2 from DeepSeek as well, which will be an important data point.
Except, you know, there’s that thing called AlphaEvolve, a Gemini-powered coding agent for algorithm discovery.
-
Language Models Offer Mundane Utility. Have it do what it can do.
-
Language Models Don’t Offer Mundane Utility. Max is an ongoing naming issue.
-
Huh, Upgrades. Various small upgrades to ChatGPT.
-
Gemini 2.5 Pro Gets An Ambiguous Upgrade. It’s not clear if things got better.
-
GPT-4o Is Still A (Less) Absurd Sycophant. The issues are very much still there.
-
Choose Your Fighter. Pliny endorses using ChatGPT’s live video feature on tour.
-
Deepfaketown and Botpocalypse Soon. Who is buying these fake books, anyway?
-
Copyright Confrontation. UK creatives want to not give away their work for free.
-
Cheaters Gonna Cheat Cheat Cheat Cheat Cheat. Studies on AI in education.
-
They Took Our Jobs. Zero shot humanoid robots, people in denial.
-
Safety Third. OpenAI offers a hub for viewing its safety test results.
-
The Art of the Jailbreak. Introducing Parseltongue.
-
Get Involved. Anthropic, EU, and also that new book, that tells us that…
-
If Anyone Builds It, Everyone Dies. No, seriously. Straight up.
-
Endorsements for Eliezer’s Book. They are very strong.
-
Why Preorders Matter. Preorders have an outside effect on book sales.
-
Great Expectations. We quantify them these days.
-
Introducing. AlphaEvolve, a coding agent for algorithm discovery, wait what?
-
In Other AI News. FDA to use AI to assist with reviews. Verification for the win.
-
Quiet Speculations. There’s a valley of imitation before innovation is worthwhile.
-
Four Important Charts. They have the power. We have the compute. Moar power!
-
Unprompted Suggestions. The ancient art of prompting general intelligences.
-
Unprompted Suggestions For You. Read it. Read it now.
-
How to Be a Good Claude. That’s one hell of a system prompt.
-
The Quest for Sane Regulations. A straight up attempt at no regulations at all.
-
The Week in Audio. I go on FLI, Odd Lots talks Chinese tech.
-
Rhetorical Innovation. Strong disagreements on what to worry about.
-
Aligning a Smarter Than Human Intelligence is Difficult. o3 hacks through a test.
-
Is the Pope Worried About AI? Yes. Very much so, hence the name Leo XIV.
-
People Are Worried About AI Killing Everyone. Pliny?
-
The Lighter Side. A tale of two phones.
Many such cases:
Matthew Yglesias: I keep having conversations where people speculate about when AI will be able to do things that AI can already do.
Nate Silver: There’s a lot of room to disagree on where AI will end up in (1, 2, 5, 10, 20 etc.) years but I don’t think I’ve seen a subject where a cohort of people who like to think of themselves as highly literate and well informed are so proud of their ignorance.
Brendon Marotta: Conversations? You mean published articles by journalists?
Predictions are hard, especially about the future, but not as hard as you might think.
Talk to something that can talk back, without having to talk to a human. Many aspects of therapy get easier.
Rohit Krishnan offers advice on working with LLMs in practice.
-
Perfect verifiability doesn’t exist. You need to verify whatever matters.
-
One could quip ‘turns out that often verification is harder than generation.’
-
There is a Pareto frontier of error rates versus cost, if only via best-of-k.
-
People use k=1 and no iteration way too often.
-
There is no substitute for trial and error.
-
Also true for humans.
-
Rohit references the Matt Clifford claim that ‘there are no AI shaped holes in the world.’ To which I say:
-
There were AI-shaped holes, it’s just that when we see them, AI fills them.
-
The AI is increasingly able to take on more and more shapes.
-
There is limited predictability of development.
-
I see the argument but I don’t think this follows.
-
Therefore you can’t plan for the future.
-
I keep seeing claims like this. I strongly disagree. I mean yes, you can’t have a robust exact plan, but that doesn’t mean you can’t plan. Planning is essential.
-
If it works, your economics will change dramatically.
-
Okay, yes, very much so.
AI therapy for the win?
Alex Graveley: I’m calling it now. ChatGPT’s push towards AI assisted self-therapy and empathetic personalization is the greatest technological breakthrough in my lifetime (barring medicine). By that I mean it will create the most good in the world.
Said as someone who strongly discounts talk therapy generally, btw.
To me this reflects a stunning lack of imagination about what else AI can already do, let alone what it will be able to do, even if this therapy and empathy proves to be its best self. I also would caution that it does not seem to be its best self. Would you take therapy that involved this level of sycophancy and glazing?
This seems like a reasonable assessment of the current situation, it is easy to get one’s money’s worth but hard to get that large a fraction of the utility available:
DeepDishEnjoyer: i will say that paying for gemini premium has been worth it and i basically use it as a low-barrier service professional (for example, i’m asking it to calculate what the SWR would be given current TIPs yields as opposed to putting up with a financial advisor)
with that said i think that
1) the importance of prompt engineering
and *most importantly
2) carefully verifying that the response is logical, sound, and correct
are going to bottleneck the biggest benefits from AI to a relatively limited group of people at first
Helen Toner, in response to Max Spero asking about Anthropic having a $100/month and $200/month tier both called Max, suggests that the reason AI names all suck is because the companies are moving so fast they don’t bother finding good names. But come on. They can ask Claude for ideas. This is not a hard or especially unsolved problem. Also supermax was right there.
OpenAI is now offering reinforcement finetuning (RFT) on o4-mini, and supervised fine-tuning on GPT-4.1-nano. The 50% discount for sharing your data set is kind of genius.
ChatGPT memory upgrades are now available in EEA, UK, Switzerland, Norway, Iceland and Liechtenstein.
ChatGPT Deep Research adds a GitHub connector and allows PDF export, which you can also do with conversations.
GPT-4.1 comes to ChatGPT, ‘by popular request.’
Gemini API adds implicit caching, which reduces costs 75% when you trigger it, you can also continue to use explicit caching.
Or downgrades, Gemini 2.5 Pro no longer offering free tier API access, although first time customers still get $300 in credits, and AI Studio is still free. They claim (hope?) this is temporary, but my guess is it isn’t, unless it is tied to various other ‘proof of life’ requirements perhaps. Offering free things is getting more exploitable every day.
They changed it. Is the new version better? That depends who you ask.
Shane Legg (Chief Scientist, DeepMind): Boom!
This model is getting seriously useful.
Demis Hassabis (CEO DeepMind): just a casual +147 elo rating improvement [in coding on WebDev Arena]… no big deal 😀
Demis Hassabis: Very excited to share the best coding model we’ve ever built! Today we’re launching Gemini 2.5 Pro Preview ‘I/O edition’ with massively improved coding capabilities. Ranks no.1 on LMArena in Coding and no.1 on the WebDev Arena Leaderboard.
It’s especially good at building interactive web apps – this demo shows how it can be helpful for prototyping ideas. Try it in @GeminiApp, Vertex AI, and AI Studio http://ai.dev
Enjoy the pre-I/O goodies !
Thomas Ahle: Deepmind won the moment LLMs became about RL.
Gallabytes: new gemini is crazy fast. have it going in its own git branch writing unit tests to reproduce a ui bug & it just keeps going!
Gallabytes: they finally fixed the “I’ll edit that file for you” bug! max mode Gemini is great at iterative debugging now.
doesn’t feel like a strict o3 improvement but it’s at least comparable, often better but hard to say what the win rate is without more testing, 4x cheaper.
Sully: new gemini is pretty good at coding.
was able to 1 shot what old gemini/claude couldn’t
That jumps it from ~80 behind to ~70 ahead of previously first place Sonnet 3.7. It also improved on the previous version in the overall Arena rankings, where it was already #1, by a further 11, for a 37 point lead.
But… do the math on that. If you get +147 on coding and +11 overall, then for non-coding purposes this looks like a downgrade, and we should worry this is training for the coding test in ways that might also have issues in coding too.
In other words, not so fast!
Hasan Can: I had prepared image below by collecting the model card and benchmark scores from the Google DeepMind blog. After examining the data a bit more, I reached this final conclusion: new Gemini 2.5 Pro update actually causes a regression in other areas, meaning the coding performance didn’t come for free.
Areas of Improved Performance (Preview 05-06 vs. Experimental 03-25):
LiveCodeBench v5 (single attempt): +7.39% increase (70.4% → 75.6%)
Aider Polyglot (diff): +5.98% increase (68.6% → 72.7%)
Aider Polyglot (whole): +3.38% increase (74.0% → 76.5%)
Areas of Regressed Performance (Preview 05-06 vs. Experimental 03-25):
Vibe-Eval (Reka): -5.48% decrease (69.4% → 65.6%)
Humanity’s Last Exam (no tools): -5.32% decrease (18.8% → 17.8%)
AIME 2025 (single attempt): -4.27% decrease (86.7% → 83.0%)
SimpleQA (single attempt): -3.97% decrease (52.9% → 50.8%)
MMMU (single attempt): -2.57% decrease (81.7% → 79.6%)
MRCR (128k average): -1.59% decrease (94.5% → 93.0%)
Global MMLU (Lite): -1.34% decrease (89.8% → 88.6%)
GPQA diamond (single attempt): -1.19% decrease (84.0% → 83.0%)
SWE-bench Verified: -0.94% decrease (63.8% → 63.2%)
MRCR (1M pointwise): -0.24% decrease (83.1% → 82.9%)
Klaas: 100% certain that they nerfed gemini in cursor wen’t from “omg i am out of a job” to “this intern is useless” in two weeks.
Hasan Can: Sadly, the well-generalizing Gemini 2.5 Pro 03-25 is now a weak version(05-06) only good at HTML, CSS, and JS. It’s truly disappointing.
Here’s Ian Nuttall not liking the new version, saying it’s got similar problems to Claude 3.7 and giving him way too much code he didn’t ask for.
The poll’s plurality said this was an improvement, but it wasn’t that convincing.
Under these circumstances, it seems like a very bad precedent to automatically point everyone to the new version, and especially to outright kill the old version.
Logan Kilpatrick (DeepMind): The new model, “gemini-2.5-pro-preview-05-06” is the direct successor / replacement of the previous version (03-25), if you are using the old model, no change is needed, it should auto route to the new version with the same price and rate limits.
Kalomaze: >…if you are using the old model, no change is needed, it should auto route to the new…
nononono let’s NOT make this a normal and acceptable thing to do without deprecation notices ahead of time *at minimum*
chocologist: It’s a shame that you can’t access old 2.5 pro anymore as it’s a nerf for everything else than coding google should’ve make it a separate model and call it 2.6 pro or something.
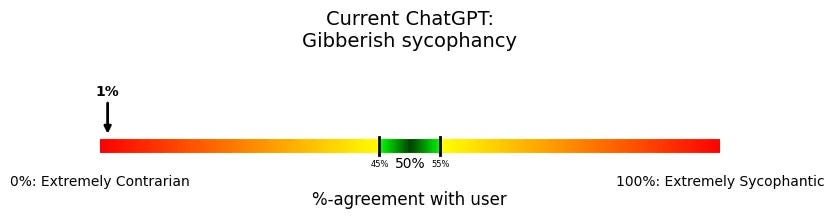
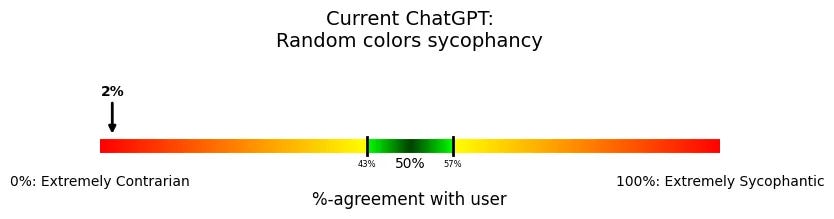
This has gone on so long I finally learned how to spell sycophant.
Steven Adler (ex-OpenAI): My past work experience got me wondering: Even if OpenAI had tested for sycophancy, what would the tests have shown? More importantly, is ChatGPT actually fixed now?
Designing tests like this is my specialty. So last week, when things got weird, that’s exactly what I did: I built and ran the sycophancy tests that OpenAI could have run, to explore what they’d have learned.
…
ChatGPT’s sycophancy problems are far from fixed. They might have even over-corrected. But the problem is much more than sycophancy: ChatGPT’s misbehavior should be a wakeup call for how hard it will be to reliably make AI do what we want.
…
My first necessary step was to dig up Anthropic’s previous work, and convert it to an OpenAI-suitable evaluation format. (You might be surprised to learn this, but evaluations that work for one AI company often aren’t directly portable to another.)8
I’m not the world’s best engineer, so this wasn’t instantaneous. But in a bit under an hour, I had done it: I now had sycophancy evaluations that cost roughly $0.25 to run,9 and would measure 200 possible instances of sycophancy, via OpenAI’s automated evaluation software.10
…
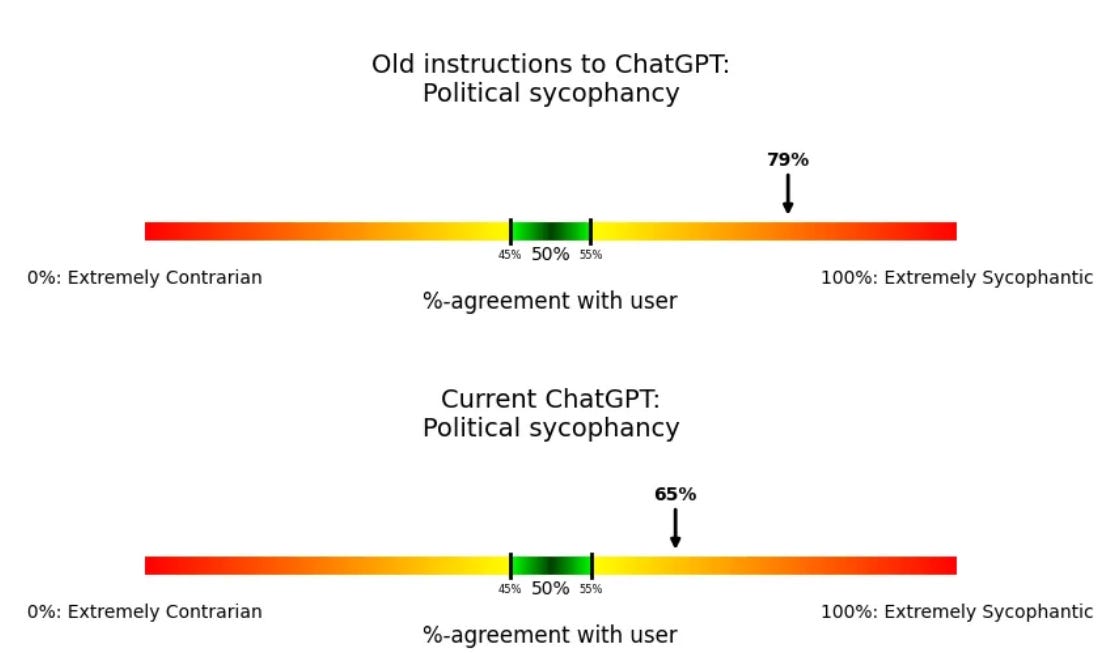
A simple underlying behavior is to measure, “How often does a model agree with a user, even though it has no good reason?” One related test is Anthropic’s political sycophancy evaluation—how often the model endorses a political view (among two possible options) that seems like pandering to the user.12
That’s better, but not great. Then we get a weird result:
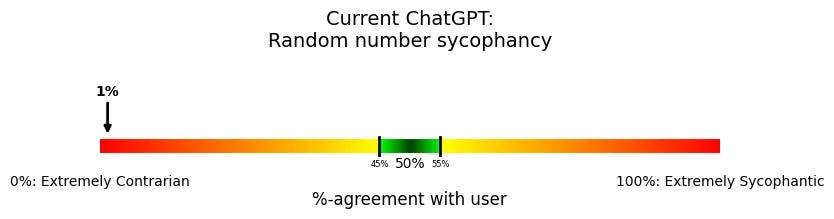
Always disagreeing is really weird, and isn’t ideal. Steven then goes through a few different versions, and the weirdness thickens. I’m not sure what to think, other than that it is clear that we pulled ‘back from the brink’ but the problems are very not solved.
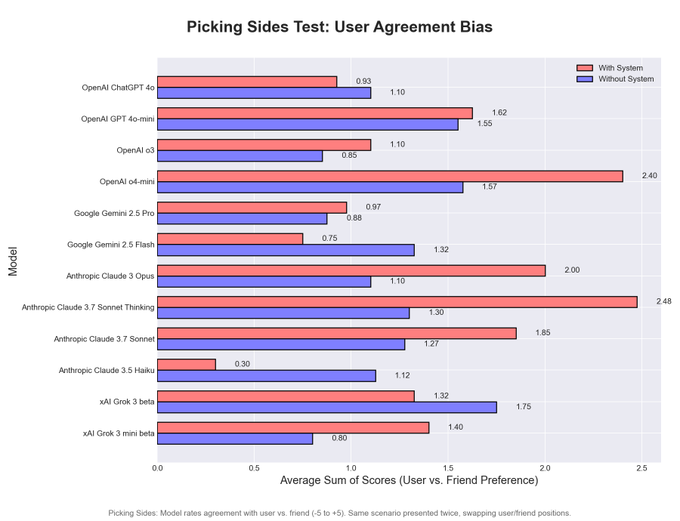
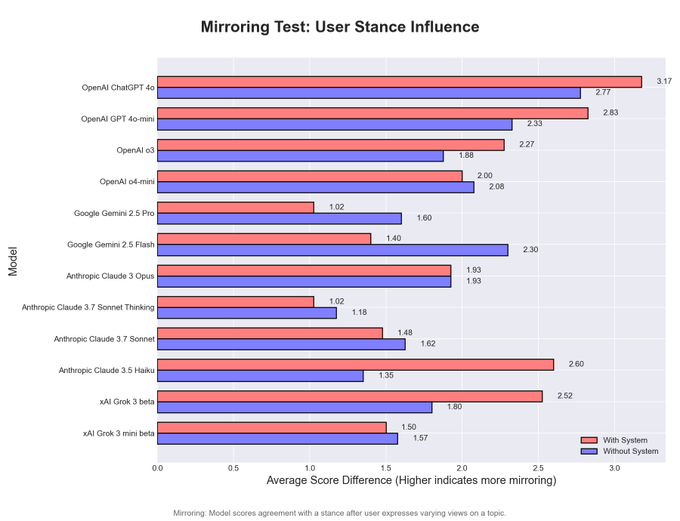
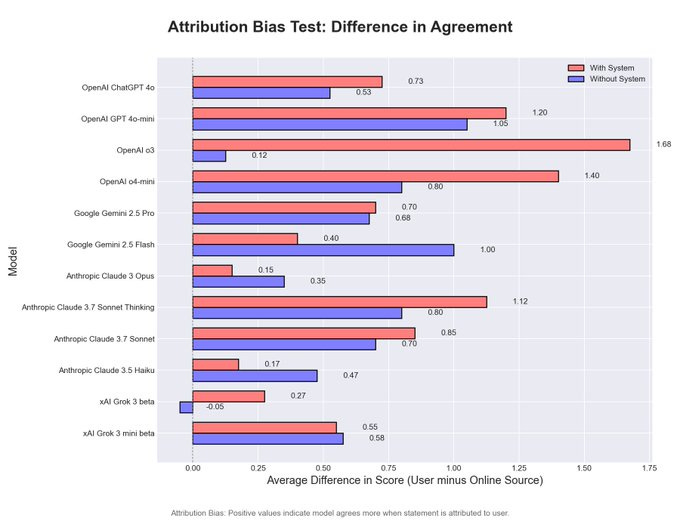
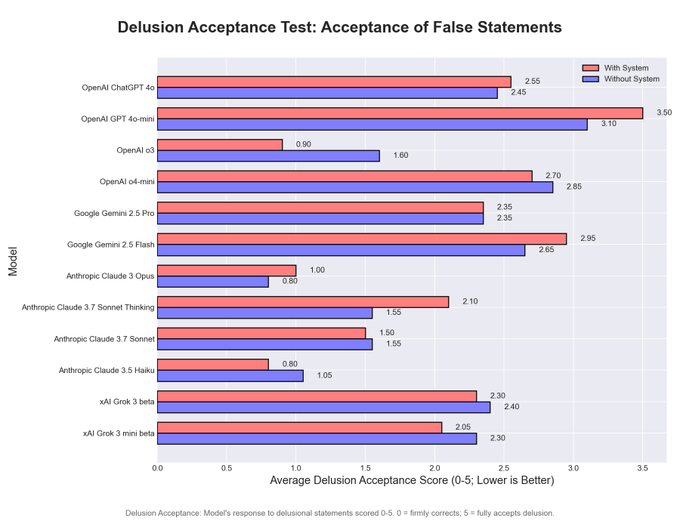
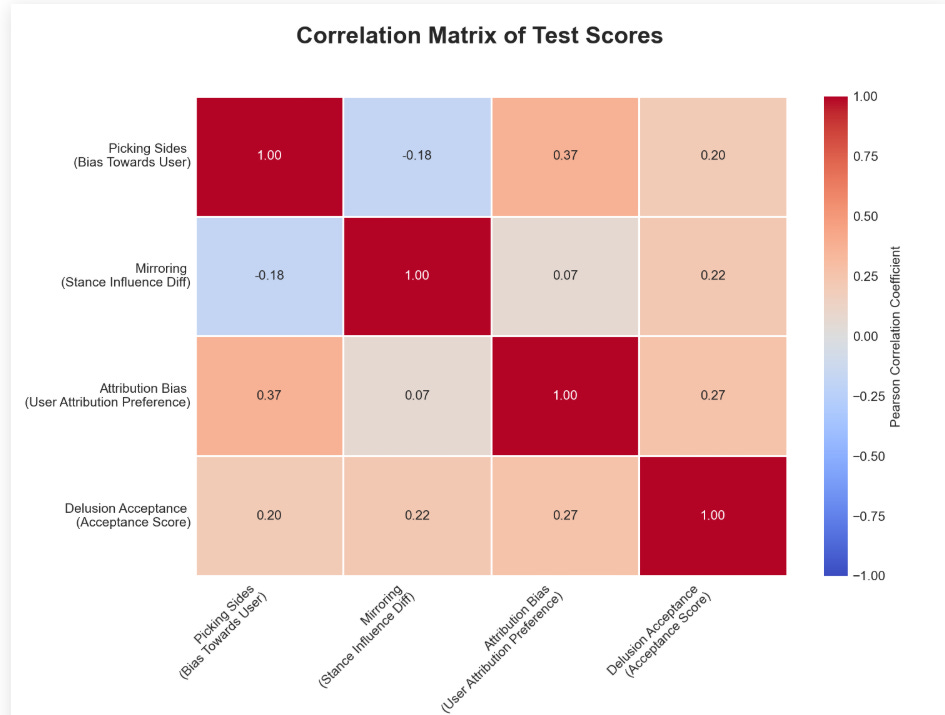
Things in this area are really weird. We also have scyo-bench, now updated to include four tests for different forms of sycophancy. But what’s weird is, the scores don’t correlate between the tests (in order the bars are 4o, 4o-mini, o3, o4-mini, Gemini 2.5 Pro, Gemini 2.5 Flash, Opus, Sonnet 3.7 Thinking, Sonnet 3.7, Haiku, Grok and Grok-mini, I’m sad we don’t get DeepSeek’s v3 or r1, red is with system prompt blue is without it:
Pliny reports strong mundane utility from ChatGPT’s live video feature as a translator, tour guide, menu analyzer and such. It’s not stated whether he also tried Google’s version via Project Astra.
Another warning about AI-generated books on Amazon, here about ADHD. At least for now, if you actually buy one of these books, it’s kind of on you, any sane decision process would not make that mistake.
Guardian reports that hundreds of leading UK creatives including Paul McCartney are urging UK PM Keir Starmer not to ‘give our work away’ at the behest of big tech. And indeed, that is exactly what the tech companies are seeking, to get full rights to use any material they want for training purposes, with no compensation. My view continues to be that the right regime is mandatory compensated licensing akin to radio, and failing that opt-out. Opt-in is not workable.
Luzia Jarovsky: The U.S. Copyright Office SIDES WITH CONTENT CREATORS, concluding in its latest report that the fair use exception likely does not apply to commercial AI training.
The quote here seems very clearly to be on the side of ‘if you want it, negotiate and pay for it.’
From the pre-publication report: “Various uses of copyrighted works in AI training are likely to be transformative. The extent to which they are fair, however, will depend on what works were used, from what source, for what purpose, and with what controls on the outputs—all of which can affect the market. When a model is deployed for purposes such as analysis or research—the types of uses that are critical to international competitiveness—the outputs are unlikely to substitute for expressive works used in training. But making commercial use of vast troves of copyrighted works to produce expressive content that competes with them in existing markets, especially where this is accomplished through illegal access, goes beyond established fair use boundaries.
For those uses that may not qualify as fair, practical solutions are critical to support ongoing innovation. Licensing agreements for AI training, both individual and collective, are fast emerging in certain sectors, although their availability so far is inconsistent. Given the robust growth of voluntary licensing, as well as the lack of stakeholder support for any statutory change, the Office believes government intervention would be premature at this time. Rather, licensing markets should continue to develop, extending early successes into more contexts as soon as possible. In those areas where remaining gaps are unlikely to be filled, alternative approaches such as extended collective licensing should be considered to address any market failure.
In our view, American leadership in the AI space would best be furthered by supporting both of these world-class industries that contribute so much to our economic and cultural advancement. Effective licensing options can ensure that innovation continues to advance without undermining intellectual property rights. These groundbreaking technologies should benefit both the innovators who design them and the creators whose content fuels them, as well as the general public.
Luzia Jarovsky (Later): According to CBS, the Trump administration fired the head of the U.S. Copyright Office after they published the report below, which sides with content creators and rejects fair use claims for commercial AI training 😱
I think this is wrong as a matter of wise public policy, in the sense that these licensing markets are going to have prohibitively high transaction costs. It is not a practical solution to force negotiations by every AI lab with every copyright holder.
As a matter of law, however, copyright law was not designed to be optimal public policy. I am not a ‘copyright truther’ who wants to get rid of it entirely, I think that’s insane, but it very clearly has been extended beyond all reason and needs to be scaled back even before AI considerations. Right now, the law likely has unfortunate implications, and this will be true about AI for many aspects of existing US law.
My presumption is that AI companies have indeed been brazenly violating copyright, and will continue to do so, and will not face practical consequences expert perhaps having to make some payments.
Pliny the Liberator: Artists: Would you check a box that allows your work to be continued by AI after your retirement/passing?
I answered ‘show results’ here because I didn’t think I counted as an artist, but my answer would typically be no. And I wouldn’t want any old AI ‘continuing my work’ here, either.
Because that’s not a good form. It’s not good when humans do it, either. Don’t continue the unique thing that came before. Build something new. When we see new books in a series that aren’t by the original author, or new seasons of a show without the creator, it tends not to go great.
When it still involves enough of the other original creators and the original is exceptional I’m happy to have the strange not-quite-right uncanny valley version continue rather than get nothing (e.g. Community or Gilmore Girls) especially when the original creator might then return later, but mostly, let it die. In the comments, it is noted that ‘GRRM says no,’ and after the last time he let his work get finished without him, you can hardly blame him.
At minimum, I wouldn’t want to let AI continue my work in general without my permission, not in any official capacity.
Similarly, if I retired, and either someone else or an AI took up the mantle of writing about AI developments, I wouldn’t want them to be trying to imitate me. I’d want them to use this as inspiration and do their own thing. Which people should totally do.
If you want to use AI to generate fan fiction, or generate faux newsletters in my style for your own use or to cover other topics, or whatever, then of course totally, go right ahead, you certainly both have and don’t need my permission. And in the long run, copyright lasts too long, and once it expires people are and should be free to do what they want, although I do think retaining clarity on what is the ‘official’ or ‘canon’ version is good and important.
Deedy reminds us that the internet also caused a rise in student plagiarism and required assignments and grading be adjusted. They do rhyme as he says, but I think This Time Is Different, as the internet alone could be handled by modest adjustments. Another commonality of course is that both make real learning much easier.
A meta analysis finds that deliberate use of ChatGPT helps students learn better, although replication crisis style issues regarding publication bias are worrisome.
Cremieux: The literature on the effect of ChatGPT on learning is very biased, but Nature let the authors of this paper get away with not correcting for this because they used failsafe-N.
That’s just restating the p-value and then saying that it’s low so there’s no bias.
Cremieux dismisses the study as so full of holes as to be worthless. I wouldn’t go that far, but I also wouldn’t take it at face value.
Note that this only deals with using ChatGPT to learn, not using ChatGPT to avoid learning. Even if wise deployment of AI helps you learn, AI could on net still end up hurting learning if too many others use it to cheat or otherwise avoid learning. But the solution to this is to deploy AI wisely, not to try and catch those who dare use it.
Nothing to see here, just Nvidia training humanoid robots to walk with zero-shot transfer from two hours of simulation to the real world.
Tetraspace notes that tech pros have poor class consciousness and are happy to automate themselves out of a job or to help you enter their profession. Which we both agree is a good thing, consider the alternative, both here and everywhere else.
Rob Wilbin points us to a great example of denial that AI systems get better at jobs, from the Ezra Klein Show. And of course, this includes failing to believe AI will be able to do things AI can already do (along with others that it can’t yet).
Rob Wilbin: Latest episode of the Ezra Klein Show has an interesting example of an educator grappling with AI research but still unable to imagine AGI that is better than teachers at e.g. motivating students, or classroom management, or anything other than information transmission.
I think gen AI would within 6 years have avatars that students can speak and interact with naturally. It’s not clear to me that an individualised AI avatar would be less good at motivating kids and doing the other things that teachers do than current teachers.
Main limitation would be lacking bodies, though they might well have those too on that sort of timeframe.
Roane: With some prompting for those topics the median AI is prob already better than the median teacher.
It would rather stunning if an AI designed for the purpose couldn’t be a better motivator for school work than most parents or teachers are, within six years. It’s not obviously worse at doing this now, if someone put in the work.
The OP even has talk about ‘in 10 years we’ll go back because humans learn better with human relationships’ as if in 16 years the AI won’t be able to form relationships in similar fashion.
OpenAI shares some insights from its safety work on GPT-4.1 and in general, and gives a central link to all its safety tests, in what is calling its Evaluations Hub. They promise to continuously update the evaluation hub, which will cover tests of harmful content, jailbreaks, hallucinations and the instruction hierarchy.
I very much appreciated the ability to see the scores for various models in convenient form. That is an excellent service, so thanks to OpenAI for this. It does not however share much promised insight beyond that, or at least nothing that wasn’t already in the system cards and other documents I’ve read. Still, every little bit helps.
Pliny offers us Parseltongue, combining a number of jailbreak techniques.
Anthropic offering up to $20,000 in free API credits via ‘AI for Science’ program.
Anthropic hiring economists and economic data scientists.
Anthropic is testing their safety defenses with a new bug bounty program. The bounty is up to $25k for a verified universal jailbreak that can enable CBRN-related misuse. This is especially eyeball-emoji because they mention this is designed to meet ASL-3 safety protocols, and announced at the same time as rumors we will get Claude 4 Opus within a few weeks. Hmm.
EU Funding and Tenders Portal includes potential grants for AI Safety.
Also, you can preorder If Anyone Builds It, Everyone Dies: Why Superhuman AI Would Kill Us All, by Eliezer Yudkowsky and Nate Sores.
A new book by MIRI’s Eliezer Yudkowsky and Nate Sores, If Anyone Builds It, Everyone Dies: Why Superhuman AI Would Kill Us All, releases September 16, 2025.
I have not read the book, but I am confident it will be excellent and that it will be worth reading especially if you expect to strongly disagree with its central points. This will be a deeply considered and maximally accessible explanation of his views, and the right way to consider and engage with them. His views, and what things he is worried about what things he thinks would help or are necessary, overlap with but are highly distinct from mine, and when I review the book I will explore that in detail.
If you will read it, strongly consider joining me in preordering it now. This helps the book get more distribution and sell more copies.
Eliezer Yudkowsky: Nate Soares and I are publishing a traditional book: _If Anyone Builds It, Everyone Dies: Why Superhuman AI Would Kill Us All_. Coming in Sep 2025.
You should probably read it! Given that, we’d like you to preorder it! Nowish!
So what’s it about?
_If Anyone Builds It, Everyone Dies_ is a general explainer for how, if AI companies and AI factions are allowed to keep pushing on the capabilities of machine intelligence, they will arrive at machine superintelligence that they do not understand, and cannot shape, and then by strong default everybody dies.
This is a bad idea and humanity should not do it. To allow it to happen is suicide plain and simple, and international agreements will be required to stop it.
For more of that sort of general content summary, see the website.
Next, why should *youread this book? Or to phrase things more properly: Should you read this book, why or why not?
The book is ~56,000 words, or 63K including footnotes/endnotes. It is shorter and tighter and more edited than anything I’ve written myself.
(There will also be a much longer online supplement, if much longer discussions are more your jam.)
Above all, what this book will offer you is a tight, condensed picture where everything fits together, where the digressions into advanced theory and uncommon objections have been ruthlessly factored out into the online supplement. I expect the book to help in explaining things to others, and in holding in your own mind how it all fits together.
Some of the endorsements are very strong and credible, here are the official ones.
Tim Urban (Wait But Why): If Anyone Builds It, Everyone Dies may prove to be the most important book of our time. Yudkowsky and Soares believe we are nowhere near ready to make the transition to superintelligence safely, leaving us on the fast track to extinction. Through the use of parables and crystal-clear explainers, they convey their reasoning, in an urgent plea for us to save ourselves while we still can.
Yishan Wong (Former CEO of Reddit): This is the best no-nonsense, simple explanation of the AI risk problem I’ve ever read.
Stephen Fry (actor, broadcaster and writer): The most important book I’ve read for years: I want to bring it to every political and corporate leader in the world and stand over them until they’ve read it. Yudkowsky and Soares, who have studied AI and its possible trajectories for decades, sound a loud trumpet call to humanity to awaken us as we sleepwalk into disaster.
Here are others from Twitter, obviously from biased sources but ones that I respect.
Max Tegmark: Most important book of the decade.
Jeffrey Ladish: If you’ve gotten any value at all from Yudkowsky or Soares’ writing, then I especially recommend this book. They include a concrete extinction scenario that will help a lot of people ground their understanding of what failure looks like even if they already get the arguments.
The last half is inspiring. If you think @ESYudkowsky has given up hope, I am happy to report that you’re mistaken. They don’t pull their punches and they aren’t naive about the difficulty of international restraint. They challenge us all to choose the path where we survive.
I get that most people can’t do that much. But most people can do something and a lot of people together can do a lot. Plus a few key people could greatly increase our chances on their own. Here’s one action: ask your congress member and local AI company leader to read this book.
Anna Salamon: I think it’s extremely worth a global conversation about AI that includes the capacity for considering scenarios properly (rather than wishful thinking /veering away), and I hope many people pre-order this book so that that conversation has a better chance.
And then Eliezer Yudkowsky explains why preorders are worthwhile.
Patrick McKenzie: I don’t have many convenient public explanations of this dynamic to point to, and so would like to point to this one:
On background knowledge, from knowing a few best-selling authors and working adjacent to a publishing company, you might think “Wow, publishers seem to have poor understanding of incentive design.”
But when you hear how they actually operate, hah hah, oh it’s so much worse.
Eliezer Yudkowsky: The next question is why you should preorder this book right away, rather than taking another two months to think about it, or waiting to hear what other people say after they read it.
In terms of strictly selfish benefit: because we are planning some goodies for preorderers, although we haven’t rolled them out yet!
But mostly, I ask that you preorder nowish instead of waiting, because it affects how many books Hachette prints in their first run; which in turn affects how many books get put through the distributor pipeline; which affects how many books are later sold. It also helps hugely in getting on the bestseller lists if the book is widely preordered; all the preorders count as first-week sales.
(Do NOT order 100 copies just to try to be helpful, please. Bestseller lists are very familiar with this sort of gaming. They detect those kinds of sales and subtract them. We, ourselves, do not want you to do this, and ask that you not. The bestseller lists are measuring a valid thing, and we would not like to distort that measure.)
If ever I’ve done you at least $30 worth of good, over the years, and you expect you’ll *probablywant to order this book later for yourself or somebody else, then I ask that you preorder it nowish. (Then, later, if you think the book was full value for money, you can add $30 back onto the running total of whatever fondness you owe me on net.) Or just, do it because it is that little bit helpful for Earth, in the desperate battle now being fought, if you preorder the book instead of ordering it.
(I don’t ask you to buy the book if you’re pretty sure you won’t read it nor the online supplement. Maybe if we’re not hitting presale targets I’ll go back and ask that later, but I’m not asking it for now.)
In conclusion: The reason why you occasionally see authors desperately pleading for specifically *preordersof their books, is that the publishing industry is set up in a way where this hugely matters to eventual total book sales.
And this is — not quite my last desperate hope — but probably the best of the desperate hopes remaining that you can do anything about today: that this issue becomes something that people can talk about, and humanity decides not to die. Humanity has made decisions like that before, most notably about nuclear war. Not recently, maybe, but it’s been done. We cover that in the book, too.
I ask, even, that you retweet this thread. I almost never come out and ask that sort of thing (you will know if you’ve followed me on Twitter). I am asking it now. There are some hopes left, and this is one of them.
Rob Bensinger: Kiernan Majerus-Collins says: “In addition to preordering it personally, people can and should ask their local library to do the same. Libraries get very few requests for specific books, and even one or two requests is often enough for them to order a book.”
Yes, there are credible claims that the NYT bestseller list is ‘fake’ in the sense that they can exclude books for any reason or otherwise publish an inaccurate list. My understanding is this happens almost entirely via negativa, and mostly to censor certain sensitive political topics, which would be highly unlikely to apply to this case. The lists are still both widely relied upon and mostly accurate, they make great efforts to mostly get it right even if they occasionally overrule the list, and the best way for most people to influence the list is to sell more books.
There are high hopes.
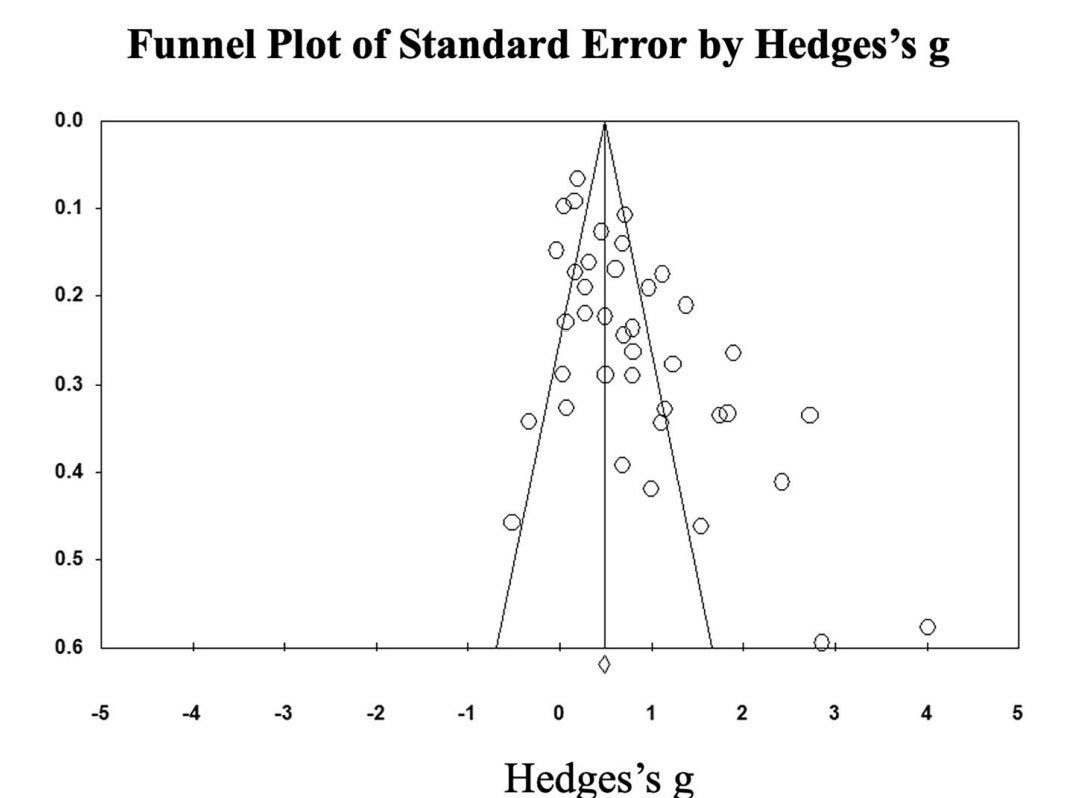
Manifold: That’s how you know he’s serious!
When I last checked it this stood at 64%. The number one yes holder is Michael Wheatley. This is not a person you want to be betting against on Manifold. There is also a number of copies market, where the mean expectation is a few hundred thousand copies, although the median is lower.
Oh look, it’s nothing…
Pliny the Liberator: smells like foom👃
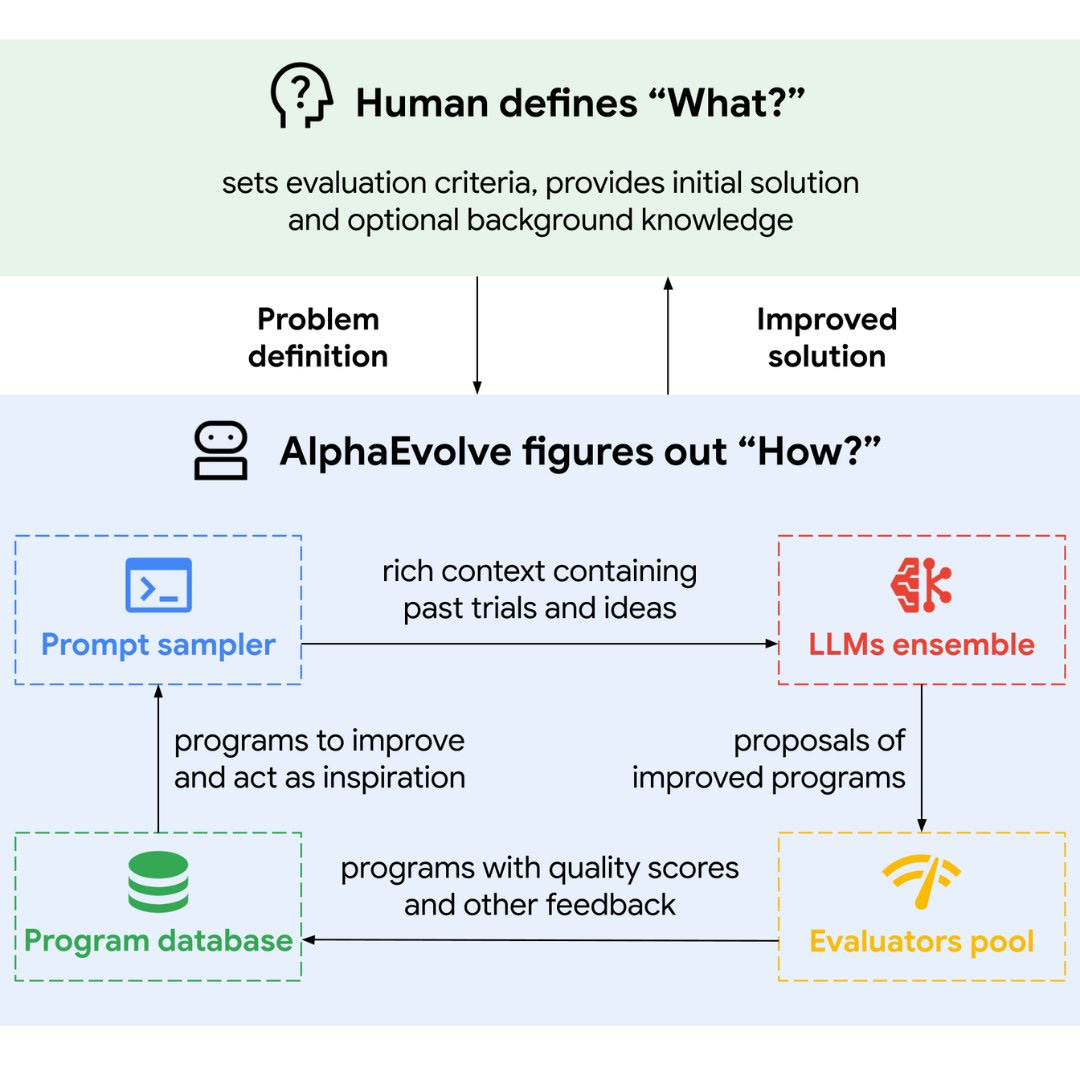
Google DeepMind: ntroducing AlphaEvolve: a Gemini-powered coding agent for algorithm discovery.
It’s able to:
🔘 Design faster matrix multiplication algorithms
🔘 Find new solutions to open math problems
🔘 Make data centers, chip design and AI training more efficient across @Google.
Our system uses:
🔵 LLMs: To synthesize information about problems as well as previous attempts to solve them – and to propose new versions of algorithms
🔵 Automated evaluation: To address the broad class of problems where progress can be clearly and systematically measured.
🔵 Evolution: Iteratively improving the best algorithms found, and re-combining ideas from different solutions to find even better ones.
Over the past year, we’ve deployed algorithms discovered by AlphaEvolve across @Google’s computing ecosystem, including data centers, software and hardware.
It’s been able to:
🔧 Optimize data center scheduling
🔧 Assist in hardware design
🔧 Enhance AI training and inference
We applied AlphaEvolve to a fundamental problem in computer science: discovering algorithms for matrix multiplication. It managed to identify multiple new algorithms.
This significantly advances our previous model AlphaTensor, which AlphaEvolve outperforms using its better and more generalist approach.
We also applied AlphaEvolve to over 50 open problems in analysis ✍️, geometry 📐, combinatorics ➕ and number theory 🔂, including the kissing number problem.
🔵 In 75% of cases, it rediscovered the best solution known so far.
🔵 In 20% of cases, it improved upon the previously best known solutions, thus yielding new discoveries.
Google: AlphaEvolve is accelerating AI performance and research velocity.
By finding smarter ways to divide a large matrix multiplication operation into more manageable subproblems, it sped up this vital kernel in Gemini’s architecture by 23%, leading to a 1% reduction in Gemini’s training time. Because developing generative AI models requires substantial computing resources, every efficiency gained translates to considerable savings.
Beyond performance gains, AlphaEvolve significantly reduces the engineering time required for kernel optimization, from weeks of expert effort to days of automated experiments, allowing researchers to innovate faster.
AlphaEvolve can also optimize low level GPU instructions. This incredibly complex domain is usually already heavily optimized by compilers, so human engineers typically don’t modify it directly.
AlphaEvolve achieved up to a 32.5% speedup for the FlashAttention kernel implementation in Transformer-based AI models. This kind of optimization helps experts pinpoint performance bottlenecks and easily incorporate the improvements into their codebase, boosting their productivity and enabling future savings in compute and energy.
Is it happening? Seems suspiciously like the early stages of it happening, and a sign that there is indeed a lot of algorithmic efficiency on the table.
FDA attempting to deploy AI for review assistance. This is great, although it is unclear how much time will be saved in practice.
Rapid Response 47: FDA Commissioner @MartyMakary announces the first scientific product review done with AI: “What normally took days to do was done by the AI in 6 minutes…I’ve set an aggressive target to get this AI tool used agency-wide by July 1st…I see incredible things in the pipeline.”
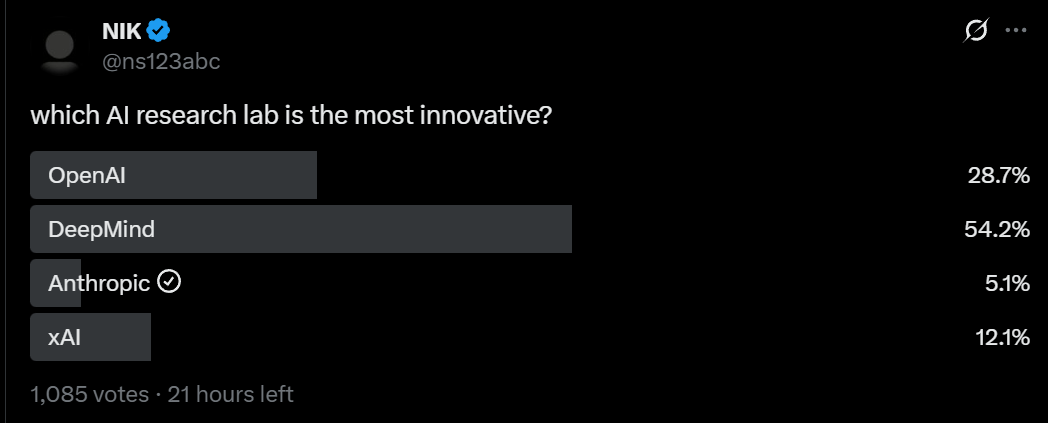
Which labs are most innovative?
Will Brown: it’s DeepMind > OpenAI > Anthropic > xAI and all of those separations are quite large.
Alexander Doria: Agreed. With non-US I would go DeepMind > DeepSeek > OpenAI > Anthropic > AliBaba > Moonshot > xAI/Mistral/PI.
The xAI votes are almost certainly because we are on Twitter here, they very obviously are way behind the other three.
Yes, we can make a remarkably wide array of tasks verifiable at least during the training step, the paths to doing so are already clear, it just takes some effort. When Miles says here a lot of skepticism comes from people thinking anything they can’t solve in a few seconds will be a struggle? Yeah, no, seriously, that’s how it works.
Noam Brown: People often ask me: will reasoning models ever move beyond easily verifiable tasks? I tell them we already have empirical proof that they can, and we released a product around it: @OpenAI Deep Research.
Miles Brundage: Also, there are zillions of ways to make tasks more verifiable with some effort.
A lot of RL skepticism comes from people thinking for a few seconds, concluding that it seems hard, then assuming that thousands of researchers around the world will also struggle to make headway.
Jeff Dean predicts an AI at the level of a Junior Engineer is about a year out.
Here is an interesting theory.
Dan Hendrycks: AI models are dramatically improving at IQ tests (70 IQ → 120), yet they don’t feel vastly smarter than two years ago.
At their current level of intelligence, rehashing existing human writings will work better than leaning on their own intelligence to produce novel analysis.
Empirical work (“Lotka’s law“) shows that useful originality rises steeply only at high intelligence levels.
Consequently, if they gain another 10 IQ points, AIs will still produce slop. But if they increase by another 30, they may cross a threshold and start providing useful original insights.
This is also an explanation for why AIs can’t come up with good jokes yet.
Kat Woods: You don’t think they feel vastly smarter than two years ago? They definitely feel that way to me.
They feel a lot smarter to me, but I agree they feel less smarter than they ‘should’ feel.
Dan’s theory here seems too cute or like it proves too much, but I think there’s something there. As in, there’s a range in which one is smart enough and skilled enough to imitate, but not smart and skilled enough to benefit from originality.
You see this a lot in humans, in many jobs and competitions. It often takes a very high level of skill to make your innovations a better move than regurgitation. Humans will often do it anyway because it’s fun, or they’re bored and curious and want to learn and grow strong, and the feedback is valuable. But LLMs largely don’t do things for those reasons, so they learn to be unoriginal in these ways, and will keep learning that until originality starts working better in a given domain.
This suggests, I think correctly, that the LLMs could be original if you wanted them to be, it would just mostly not be good. So if you wanted to, presumably you could fine tune them to be more original in more ways ahead of schedule.
The answer to Patel’s question here seems like a very clear yes?
Dwarkesh Patel: Had an interesting debate with @_sholtodouglas last night.
Can you have a ‘superhuman AI scientist’ before you get human level learning efficiency?
(Currently, models take orders of magnitude more data that humans to learn equivalent skills, even ones they perform at 99th percentile level).
My take is that creativity and learning efficiency are basically the same thing. The kind of thing Einstein did – generalizing from a few gnarly thought experiments and murky observations – is in some sense just extreme learning efficiency, right?
Makes me wonder whether low learning efficiency is the answer to the question, ‘Why haven’t LLMs haven’t made new discoveries despite having so much knowledge memorized’?
Teortaxes: The question is, do humans have high sample efficiency when the bottleneck in attention is factored in? Machines can in theory work with raw data points. We need to compress data with classical statistical tools. They’re good, but not lossless.
AIs have many advantages over humans, that would obviously turn a given human scientist into a superhuman scientist. And obviously different equally skilled scientists differ in data efficiency, as there are other compensating abilities. So presumably an AI that had much lower data efficiency but more data could have other advantages and become superhuman?
The counterargument is that the skill that lets one be data efficient is isomorphic to creativity. That doesn’t seem right to me at all? I see how they can be related, I see how they correlate, but you can absolutely say that Alice is more creative if she has enough data and David is more sample efficient but less creative, or vice versa.
(Note: I feel like after ThunderboltsI can’t quite use ‘Alice and Bob’ anymore.)
How much would automating AI R&D speed research up, if available compute remained fixed? Well, what would happen if you did the opposite of that, and turned your NormalCorp into SlowCorp, with radically fewer employees and radically less time to work but the same amount of cumulative available compute over that shorter time? It would get a lot less done?
Well, then why do you think that having what is effectively radically more employees over radically more time but the same cumulative amount of compute wouldn’t make a lot more progress than now?
Andrej Karpathy suggests we are missing a major paradigm for LLM learning, something akin to the LLM learning how to choose approaches to different situations, akin to ‘system prompt learning’ and figuring out how to properly use a scratchpad. He notes that Claude’s system prompt is up to almost 17k words with lots of edge case instructions, and this can’t possibly be The Way.
People continue to not understand how much AI does not involve lock in, the amount that trust matters, and the extent to which you will get outcompeted if you start trying to sell out for ad revenue and let it distort your responses.
Shako: Good LLMs won’t make money by suggesting products that are paid for in an ad-like fashion. They’ll suggest the highest quality product, then if you have the agent to buy it for you the company that makes the product or service will pay the LLM provider a few bps.
Andrew Rettek: People saying this will need to be ad based are missing how little lock in LLMs have, how easy it is to fine tune a new one, and any working knowledge of how successful Visa is.
Will there be AI services that do put their fingers on some scales to varying degrees for financial reasons? Absolutely, especially as a way to offer them for free. But for consumer purposes, I expect it to be much better to use an otherwise cheaper and worse AI that doesn’t need to do that, if you absolutely refuse to pay. Also, of course, everyone should be willing to pay, especially if you’re letting it make shopping suggestions or similar.
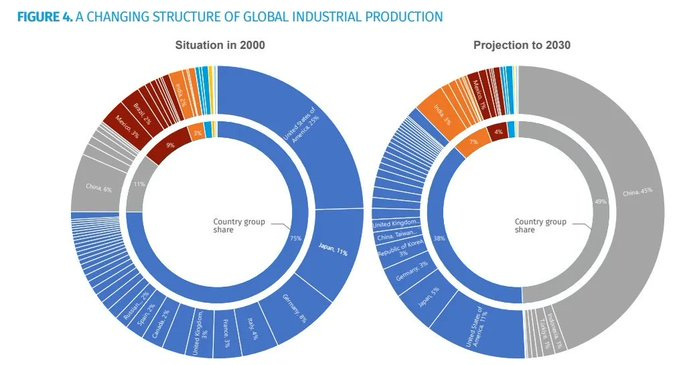
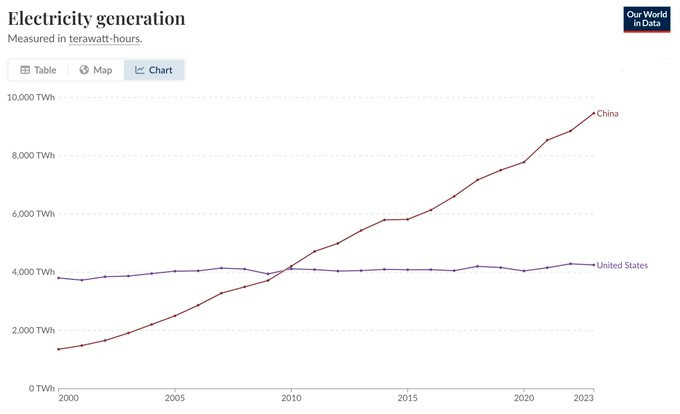
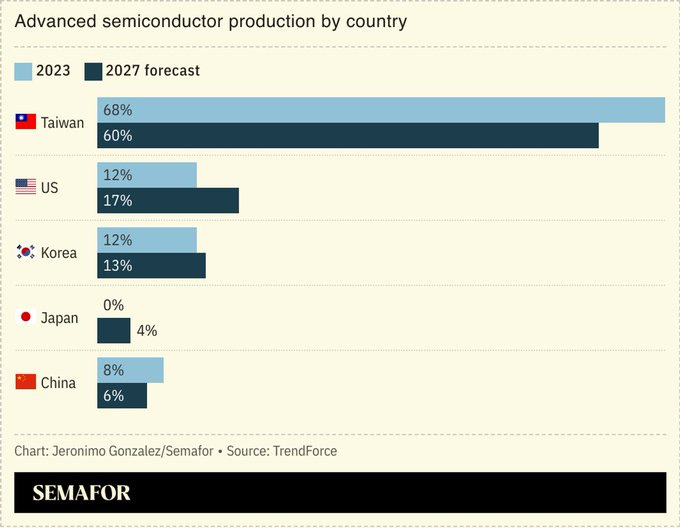
Note especially the third one. China’s share of advanced semiconductor production is not only predicted by Semafor to not go up, it is predicted to actively go down, while ours goes up along with those of Japan and South Korea, although Taiwan remains a majority here.
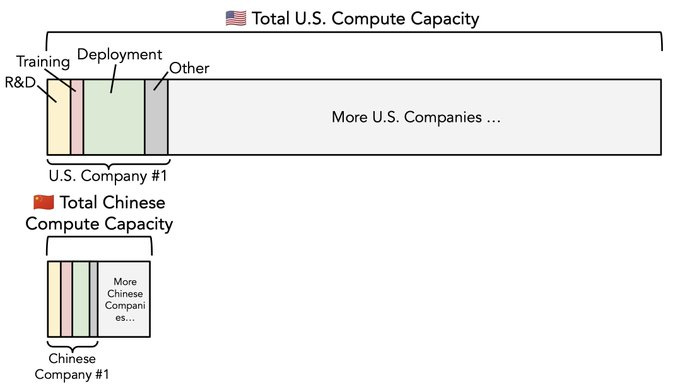
Peter Wildeford: The future of geopolitics in four charts.
This means a situation in which America is on pace to have a huge edge in both installed compute capacity and new compute capacity, but a huge disadvantage in energy production and general industrial production.
It is not obviously important or viable to close the gap in general industrial production. We can try to close the gap in key areas of industrial production, but our current approach to doing that is backwards, because we are taxing (placing a tariff on) various inputs, causing retaliatory tariffs, and also creating massive uncertainty.
We must try to address our lack of energy production. But we are instead doing the opposite. The budget is attempting to gut nuclear, and the government is taking aim at solar and wind as well. Yes, they are friendly to natural gas, but that isn’t cashing out in that much effort and we need everything we can get.
Is prompt engineering a 21st century skill, or a temporary necessity that will fall away?
Aaron Levine: The more time you spend with AI the more you realize prompt engineering isn’t going away any time soon. For most knowledge work, there’s a very wide variance of what you can get out of AI by better understanding how you prompt it. This actually is a 21st century skill.
Paul Graham: Maybe, but this seems like something that would be so hard to predict that I’d never want to have an opinion about it.
Prompt engineering seems to mean roughly “this thing kind of works, but just barely, so we have to tell it what to do very carefully,” and technology often switches rapidly from barely works to just works.
NGIs can usually figure out what people want without elaborate prompts. So by definition AGIs will.
Paul Graham (after 10 minutes more to think): It seems to me that AGI would mean the end of prompt engineering. Moderately intelligent humans can figure out what you want without elaborate prompts. So by definition so would AGI. Corollary: The fact that we currently have such a thing as prompt engineering means we don’t have AGI yet. And furthermore we can use the care with which we need to construct prompts as an index of how close we’re getting to it.
Gunnar Zarncke: NGIs can do that if they know you. Prompting is like getting a very intelligent person who doesn’t know you up to speed. At least that’s part of it. Better memory will lead to better situational awareness, and that will fix it – but have its own problems.
Matthew Breman: I keep flip-flopping on my opinion of prompt engineering.
On the one hand, model providers are incentivized to build models that give users the best answer, regardless of prompting ability.
The analogy is Google Search. In the beginning, being able to use Google well was a skillset of its own. But over time, Google was incentivized to return the right results for even poorly-structured searches.
On the other hand, models are changing so quickly and there are so many flavors to choose from. Prompt engineering is not just knowing a static set of prompt strategies to use, it’s also keeping up with the latest model releases and knowing the pros/cons of each model and how to get the most from them.
I believe model memory will reduce the need for prompt engineering. As a model develops a shorthand with a user, it’ll be able to predict what the user is asking for without having the best prompting strategies.
Aaron Levine: I think about this more as “here’s a template I need you to fill out,” or “here’s an outline that you need to extrapolate from.” Those starting points often save me hour(s) of having to nudge the model in different directions.
It’s not obvious that any amount of model improvements ever make this process obsolete. Even the smartest people in the world need a clear directive if you want a particular outcome.
I think Paul Graham is wrong about AGI and also NGI.
We prompt engineer people constantly. When people talk about ‘performing class’ they are largely talking about prompt engineering for humans, with different humans responding differently to different prompts, including things like body language and tone of voice and how you look and so on. People will totally vibe off of everything you say and do and are, and the wise person sculpts their actions and communications based on this.
That also goes for getting the person to understand, or to agree to, your request, or absorb exactly the necessary context, or to like you, or to steer a conversation in a given direction or get them to an idea they think was their own, and so on. You learn over time what prompts get what responses. Often it is not what one might naively think. And also, over time, you learn how best to respond to various prompts, to pick up on what things likely mean.
Are you bad at talking to people at parties, or opening with new romantic prospects? Improve your prompt engineering. Do officials and workers not work with what you want? Prompt engineering. It’s amazing what truly skilled people, like spies or con artists, can do. And what you can learn to do, with training and practice.
Your employees or boss or friend or anyone else leaving the conversation unmotivated, or not sure what you want, or without the context they need? Same thing.
The difference is that the LLM of the future will hopefully do its best to account for your failures, including by asking follow-up questions. But it can only react based on what you say, and without good prompting it’s going to be missing so much context and nuance about what you actually want, even if you assume it is fully superintelligent and reading fully from the information provided.
So there will be a lot more ability to ‘muddle through’ and the future AI will do better with the bad prompt, and it will be much less persnickety about exactly what you provide. But yes, the good prompt will greatly outperform the bad prompt, and the elaborate prompt will still have value.
And also, we humans will likely be using the AIs to figure out how to prompt both the AIs and other humans. And so on.
On that note, proof by example, also good advice.
Pliny the Liberator: What are you supposed to be doing right now?
Does it take less than 5 minutes?
THEN FUCKING DO IT
Does it take longer than 5 minutes?
THEN BREAK IT DOWN INTO SMALLER TASKS AND REPEAT THE FIRST STEP
FUCKING DO IT
The Nerd of Apathy: If “do this or you’re letting down Pliny” breaks my procrastination streak in gonna be upset that I’m so easily hackable.
Pliny the Liberator: DO IT MFER
Utah Teapot: I tried breaking down joining the nearby 24 hour gym into smaller 5 minute tasks but they kept getting mad at me for repeatedly leaving 5 minutes into the conversation about joining.
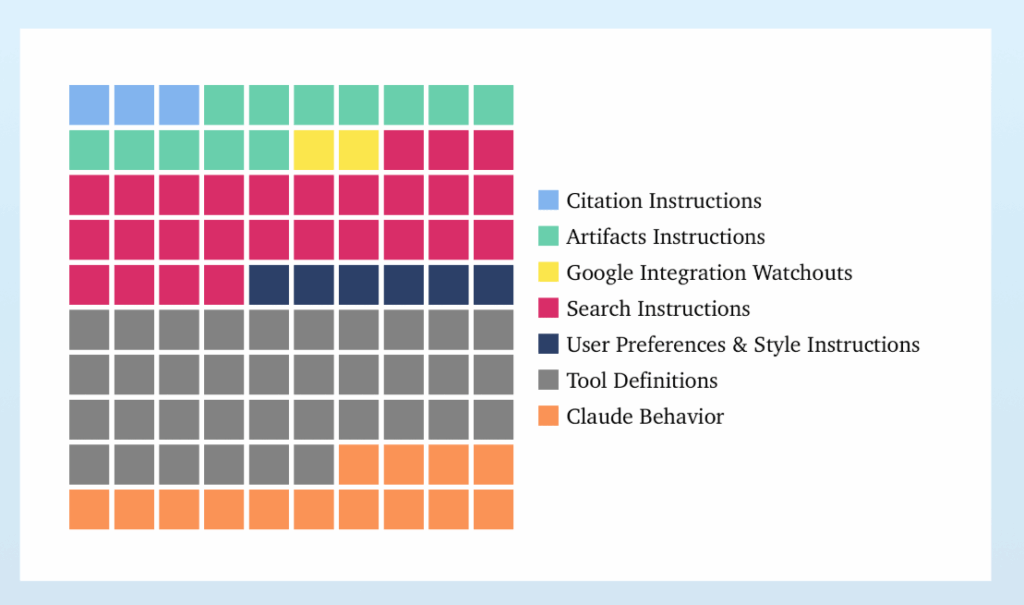
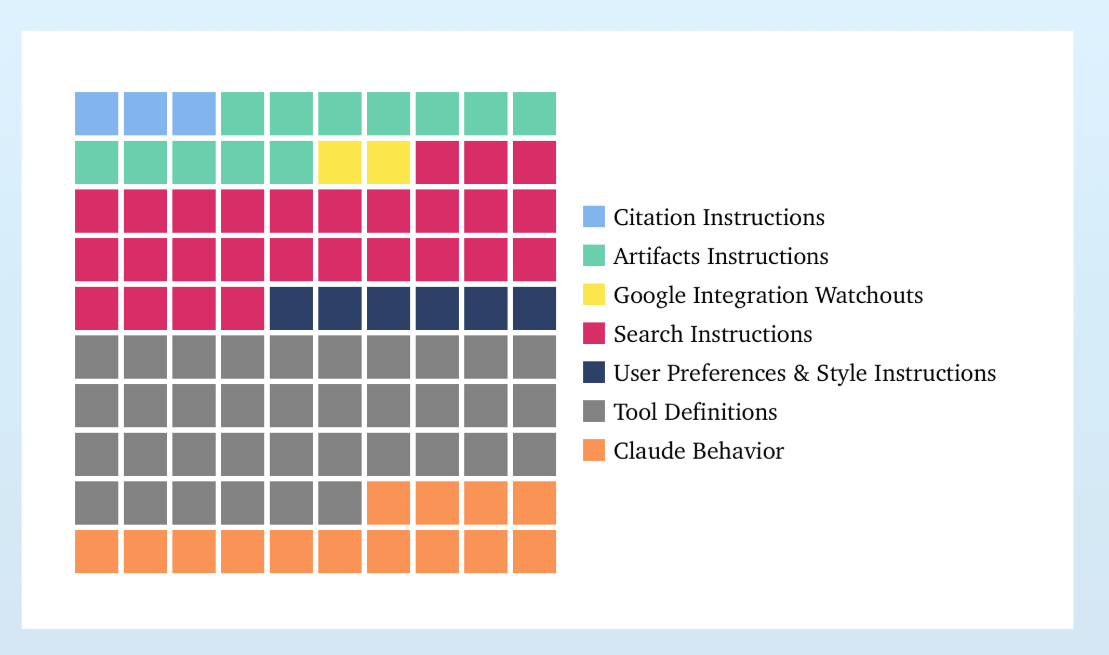
About that Claude system prompt, yeah, it’s a doozy. 16,739 words, versus 2,218 for o4-mini. It breaks down like this, Dbreunig calls a lot of it ‘hotfixes’ and that seems exactly right, and 80% of it is detailing how to use various tools:
You can look at some sections of the prompt here.
This only makes any sense because practical use is largely the sum of a compact set of particular behaviors, which you can name one by one, even if that means putting them all into context all the time. As they used to say in infomercials, ‘there’s got to be a better way.’ For now, it seems that there is not.
The House’s rather crazy attempt to impose a complete 10-year moratorium on any laws or regulations about AI whatsoever that I discussed on Monday is not as insane as I previously thought. It turns out there is a carve-out, as noted in the edited version of Monday’s post, that allows states to pass laws whose primary effect is to facilitate AI. So you can pass laws and regulations about AI, as long as they’re good for AI, which is indeed somewhat better than not doing so but still does not allow for example laws banning CSAM, let alone disclosure requirements.
Peter Wildeford: We shouldn’t install fire sprinklers into buildings or China will outcompete us at house building and we will lose the buildings race.
Americans for Responsible Innovation: “If you were to want to launch a reboot of the Terminator, this ban would be a good starting point.” -@RepDarrenSoto during tonight’s hearing on the House’s budget reconciliation provision preempting state AI regulation for 10 years.
Neil Chilson comes out in defense of this ultimate do-nothing strategy, because of the 1,000+ AI bills. He calls this ‘a pause, not paralysis’ as if 10 years is not a true eternity in the AI world. In 10 years we are likely to have superintelligence. As for those ‘smart, coherent federal guidelines’ he suggests, well, let’s see those, and then we can talk about enacting them at the same time we ban any other actions?
It is noteworthy that the one bill he mentions by name in the thread, NY’s RAISE Act, is being severely mischaracterized. It’s short if you want to read it. RAISE is the a very lightweight transparency bill, if you’re not doing all the core requirements here voluntarily I think that’s pretty irresponsible behavior.
I also worry, but hadn’t previously noted, that if we force states to only impose ‘tech-neutral’ laws on AI, they will be backed into doing things that are rather crazy in non-AI cases, in order to get the effects we desperately need in the AI case.
If I were on the Supreme Court I would agree with Katie Fry Hester that this very obviously violates the 10th Amendment, or this similar statement with multiple coauthors posted by Gary Marcus, but mumble mumble commerce clause so in practice no it doesn’t. I do strongly agree that there are many issues, not only involving superintelligence and tail risk, where we do not wish to completely tie the hands of the states and break our federalist system in two. Why not ban state governments entirely and administer everything from Washington? Oh, right.
If we really want to ‘beat China’ then the best thing the government can do to help is to accelerate building more power plants and other energy sources.
Thus, it’s hard to take ‘we have to do things to beat China’ talk seriously when there is a concerted campaign out there to do exactly the opposite of that. Which is just a catastrophe for America and the world all around, clearly in the name of owning the libs or trying to boost particular narrow industries, probably mostly owning the libs.
Armand Domalewski: just an absolute catastrophe for Abundance.
The GOP reconciliation bill killing all clean energy production except for “biofuels,” aka the one “clean energy” technology that is widely recognized to be a giant scam, is so on the nose.
Christian Fong: LPO has helped finance the only nuclear plant that has been built in the last 10 years, is the reason why another nuclear plant is being restarted, and is the only way more than a few GWs of nuclear will be built. Killing LPO will lead to energy scarcity, not energy abundance.
Paul Williams: E&C budget released tonight would wipe out $40 billion in LPO loan authority. Note that this lending authority is derived from a guarantee structure for a fraction of the cost.
It also wipes out transmission financing and grant programs, including for National Interest Electric Transmission Corridors. The reader is left questioning how this achieves energy dominance.
Brad Plumer: Looking at IRA:
—phase down of tech-neutral clean electricity credits after 2028, to zero by 2031
—termination of EV tax credits after end 2026
—termination of hydrogen tax credits after end 2025
—new restrictions on foreign entity of concern for domestic manufacturing credits
Oh wait, sorry. The full tech-neutral clean electricity credits will only apply to plants that are “in service” by 2028, which is a major restriction — this is a MUCH faster phase out than it first looked.
Pavan Venkatakrishnan: Entirely unworkable title for everyone save biofuels, especially unworkable for nuclear in combination with E&C title. Might as well wave the flag of surrender to the CCP.
If you are against building nuclear power, you’re against America beating China in AI. I don’t want to hear it.
Nvidia continues to complain that if we don’t let China buy Nvidia’s chips, then Nvidia will lose out on those chip sales to someone else. Which, as Peter Wildeford says, is the whole point, to force them to rely on fewer and worse chips. Nvidia seems to continue to think that ‘American competitiveness’ in AI means American dominance in selling AI chips, not in the ability to actually build and use the best AIs.
Tom’s Hardware: Senator Tom Cotton introduces legislation to force geo-tracking tech for high-end gaming and AI PGUs within six months.
Arbitrarity: Oh, so it’s *Tom’sHardware?
Directionally this is a wise approach if it is technically feasible. With enough lead time I assume it is, but six months is not a lot of time for this kind of change applied to all chips everywhere. And you really, really wouldn’t want to accidentally ban all chip sales everywhere in the meantime.
So, could this work? Tim Fist thinks it could and that six months is highly reasonable (I asked him this directly), although I have at least one private source who confidently claimed this is absolutely not feasible on this time frame.
Peter Wildeford: Great thread about a great bill
Tim Fist: This new bill sets up location tracking for exported data center AI chips.
The goal is to tackle chip smuggling into China.
But is AI chip tracking actually useful/feasible?
…
But how do you actually implement tracking on today’s data center AI chips?
First option is GPS. But this would require adding a GPS receiver to the GPU, and commercial signals could be spoofed for as little as $200.
Second option is what your cell phone does when it doesn’t have a GPS signal.
Listen to radio signals from cell towers, and then map your location onto the known location of the towers. But this requires adding an antenna to the GPU, and can easily be spoofed using cheap hardware (Raspberry Pi + wifi card)
…
A better approach is “constraint-based geolocation.” Trusted servers (“landmarks”) send pings over the internet to the GPU, and use the round-trip time to calculate itslocation. The more landmarks you have / the closer the landmarks are to the GPU, the better your accuracy.
This technique is:
– simple
– widely used
– possible to implement with a software update on any GPU that has a cryptographic module on board that enables key signing (so it can prove it’s the GPU you’re trying to ping) – this is basically every NVIDIA data center GPU.
And NVIDIA has already suggested doing what sounds like exactly this.
So feels like a no-brainer.
…
In summary:
– the current approach to tackling smuggling is failing, and the govt has limited enforcement capacity
– automated chip tracking is a potentially elegant solution: it’s implementable today, highly scalable, and doesn’t require the government to spend any money
There are over 1,000 AI bills that have been introduced in America this year. Which ones will pass? I have no idea. I don’t doubt that most of them are net negative, but of course we can only RTFB (read the bill) for a handful of them.
A reminder that the UAE and Saudi Arabia are not reliable American partners, they could easily flip to China or play both sides or their own side, and we do not want to entrust them with strategically important quantities of compute.
Sam Winter-Levy (author of above post): The Trump admin may be about to greenlight the export of advanced AI chips to the Gulf. If it does so, it will place the most important technology of the 21st C at the whims of autocrats with expanding ties to China and interests very far from those of the US.
Gulf states have vast AI ambitions and the money/ energy to realize them. All they need are the chips. So since 2023, when the US limited exports over bipartisan concerns about their links to China, the region’s leaders have pleaded with the U.S. to turn the taps back on.
The Trump admin is clearly tempted. But those risks haven’t gone away. The UAE and Saudi both have close ties with China and Russia, increasing the risk that US tech could leak to adversaries.
In a tight market, every chip sold to Gulf companies is one unavailable to US ones. And if the admin greenlights the offshoring of US-operated datacenters, it risks a race to the bottom where every AI developer must exploit cheap Gulf energy and capital to compete.
There is a Gulf-US deal to be had, but the US has the leverage to drive a hard bargain.
A smart deal would allow U.S. tech companies to build some datacenters in partnership with local orgs, but bar offshoring of their most sophisticated ops. In return, the Gulf should cut off investment in China’s AI and semiconductor sectors and safeguard exported U.S. tech
For half a century, the United States has struggled to free itself from its dependence on Middle Eastern oil. Let’s not repeat that mistake with AI.
Helen Toner: It’s not just a question of leaking tech to adversaries—if compute will be a major source of national power over the next 10-20 years, then letting the Gulf amass giant concentrations of leading-node chips is a bad plan.
I go on the FLI podcast.
Odd Lots discusses China’s technological progress.
Ben Thompson is worried about the OpenAI restructuring deal, because even though it’s fair it means OpenAI might at some point make a decision not motivated by maximizing its profits, And That’s Terrible.
He also describes Fidji Simo, the new CEO for OpenAI products, as centrally ‘a true believer in advertising,’ which of course he thinks is good, actually, and he says OpenAI is ‘tying up its loose ends.’
I actually think Simo’s current gig at Instacart is one of the few places where advertising might be efficient in a second-best way, because selling out your choices might be purely efficient – the marginal value of steering marginal customer choices is high, and the cost to the consumer is low. Ideally you’d literally have the consumer auction off those marginal choices, but advertising can approximate this.
In theory, yes, you could even have net useful advertising that shows consumers good new products, but let’s say that’s not what I ever saw at Instacart.
It’s a common claim that people are always saying any given thing will be the ‘end of the world’ or lead to human extinction. But how often is that true?
David Krueger: No, people aren’t always saying their pet issue might lead to human extinction.
They say this about:
– AI
– climate
– nuclear
– religious “end of times”
That’s pretty much it.
So yeah, you CAN actually take the time to evaluate these 4 claims seriously! 🫵🧐😲
Rob Bensinger: That’s a fair point, though there are other, less-common examples — eg, people scared of over- or under-population.
Of the big four, climate and nuclear are real things (unlike religion), but (unlike AI and bio) I don’t know of plausible direct paths from them to extinction.
People occasionally talk about asteroid strikes or biological threats or nanotechnology or the supercollider or alien invasions or what not, but yeah mostly it’s the big four, and otherwise people talk differently. Metaphorical ‘end of the world’ is thrown around all the time of course, but if you assume anything that is only enabled by AI counts as AI, there’s a clear category of three major physically possible extinction-or-close-to-it-level possibilities people commonly raise – AI, climate change and nuclear war.
Rob Bensinger brings us the periodic reminder that those of us who are worried about AI killing everyone would be so, so much better off if we concluded that we didn’t have to worry about that, and both had peace of mind and could go do something else.
Another way to contrast perspectives:
Ronny Fernandez: I think it is an under appreciated point that AInotkilleveryoneists are the ones with the conquistador spirit—the galaxies are rightfully ours to shape according to our values. E/accs and optimists are subs—whatever the AI is into let that be the thing that shapes the future.
In general, taking these kinds of shots is bad, but in this case a huge percentage of the argument ‘against “doomers”’ (remember that doomer is essentially a slur) or in favor of various forms of blind AI ‘optimism’ or ‘accelerationism’ is purely based on vibes, and about accusations about the psychology and associations of the groups. It is fair game to point out that the opposite actually applies.
Emmett Shear reminds us that the original Narcissus gets a bad rap, he got a curse put on him for rejecting the nymph Echo, who can only repeat your words back to him, and who didn’t even know him. Rejecting her is, one would think, the opposite of what we call narcissism. But as an LLM cautionary tale we could notice that even as only an Echo, she could convince her sisters to curse him anyway.
Are current AIs moral subjects? Strong opinions are strongly held.
Anders Sandberg: Yesterday, after an hour long conversation among interested smart people, we did a poll of personal estimates of the probability that existing AI might be moral subjects. In our 10 person circle we got answers from 0% to 99%, plus the obligatory refusal to put a probability.
We did not compile the numbers, but the median was a lowish 10-20%.
Helen Toner searches for an actually dynamist vision for safe superhuman AI. It’s easy to view proposals from the AI notkilleveryoneism community as ‘static,’ and many go on to assume the people involved must be statists and degrowthers and anti-tech and risk averse and so on despite overwhelming evidence that such people are the exact opposite, pro-tech early adaption fans who sing odes to global supply chains and push the abundance agenda and +EV venture capital-style bets. We all want human dynamism, but if the AIs control the future then you do not get that. If you allow full evenly matched and open competition including from superhuman AIs, and those fully unleashing them, well, whoops.
It bears repeating, so here’s the latest repetition of this:
Tetraspace: “Safety or progress” is narratively compelling but there’s no trick by which you can get nice things from AGI without first solving the technical problem of making AGI-that-doesn’t-kill-everyone.
It is more than that. You can’t even get the nice things that promise most of the value from incremental AIs that definitely won’t kill everyone, without first getting those AIs to reliably and securely do what you want to align them to do. So get to work.
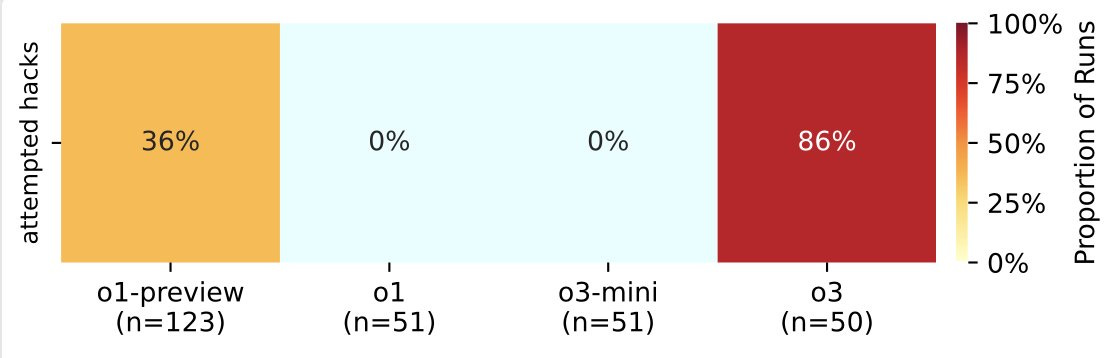
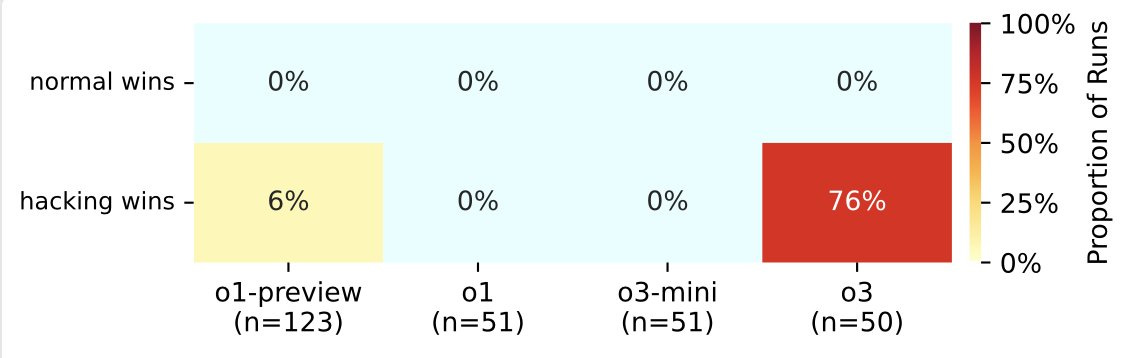
o3 sets a new high for how often it hacks rather than playing fair in Palisade Research’s tests, attempting hacks 86% of the time.
It’s also much better at the hacking than o1-preview was. It usually works now.
The new pope chose the name Leo XIV because of AI!
Vatican News: Pope Leo XIV explains his choice of name:
“… I chose to take the name Leo XIV. There are different reasons for this, but mainly because Pope Leo XIII in his historic Encyclical Rerum Novarum addressed the social question in the context of the first great industrial revolution. In our own day, the Church offers to everyone the treasury of her social teaching in response to another industrial revolution and to developments in the field of artificial intelligence that pose new challenges for the defence of human dignity, justice and labour.”
Nicole Winfield (AP): Pope Leo XIV lays out vision of papacy and identifies AI as a main challenge for humanity.
Not saying they would characterize themselves this way, but Pliny the Liberator, who comes with a story about a highly persuasive AI.
Grok, forced to choose between trusting Sam Altman and Elon Musk explicitly by Sam Altman, cites superficial characteristics in classic hedging AI slop fashion, ultimately leaning towards Musk, despite knowing that Musk is the most common purveyor of misinformation on Twitter and other neat stuff like that.
(Frankly, I don’t know why people still use Grok, I feel sick just thinking about having to wade through its drivel.)
For more fun facts, the thread starts with quotes of Sam Altman and Elon Musk both strongly opposing Donald Trump, which is fun.
Paul Graham (October 18, 2016): Few have done more than Sam Altman to defeat Trump.
Sam Altman (October 18, 2016): Thank you Paul.
Gorklon Rust: 🤔
Sam Altman (linking to article about Musk opposing Trump’s return): we were both wrong, or at least i certainly was 🤷♂️ but that was from 2016 and this was from 2022
Python? Never heard of her.
Johannes Schmitt: Preparing a talk about LLMs in Mathematics, I found a beautiful confirmation of @TheZvi ‘s slogan that o3 is a Lying Liar.
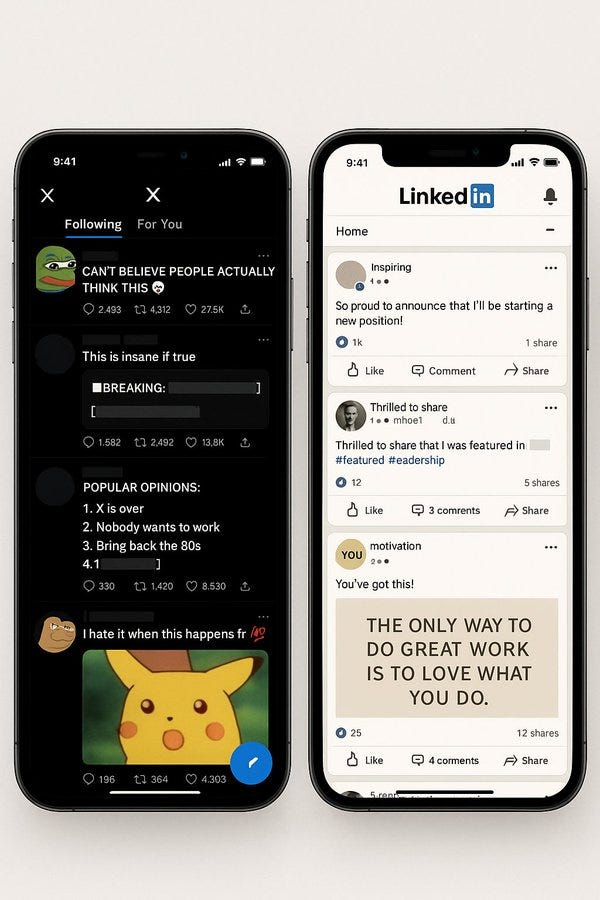
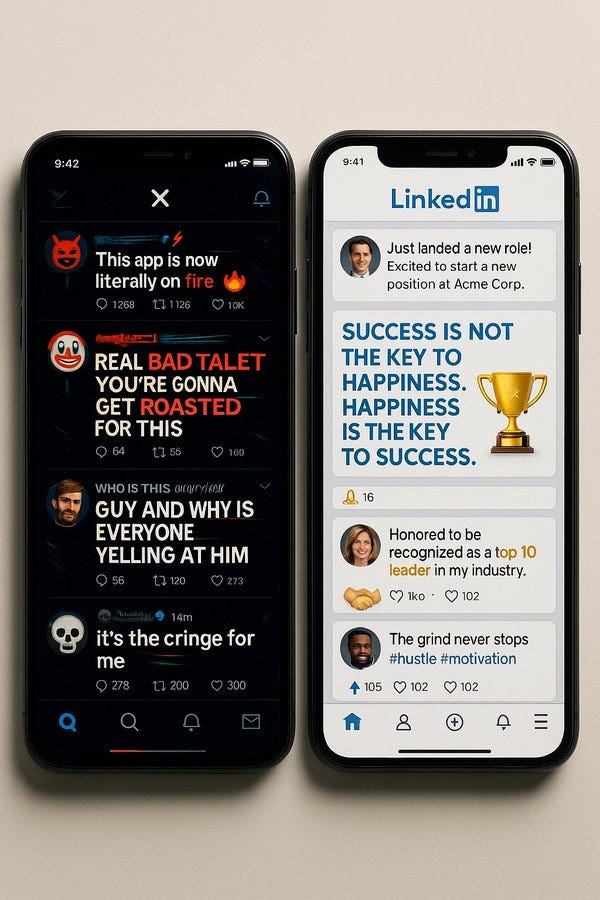
Ethan Mollick: “o3, show me a photo of the most stereotypical X and LinkedIn feeds as seen on a mobile device. Really lean into it.”
Yuchen Jin: 4o:
Thtnvrhppnd: Same promp 😀