There’s a time and a place for everything. It used to be called college.
-
The Big Test.
-
Testing, Testing.
-
Legalized Cheating On the Big Test.
-
What Happens When You Don’t Test For Academics.
-
What Happens Without Academic Standards.
-
Another Academic Standard Perhaps.
-
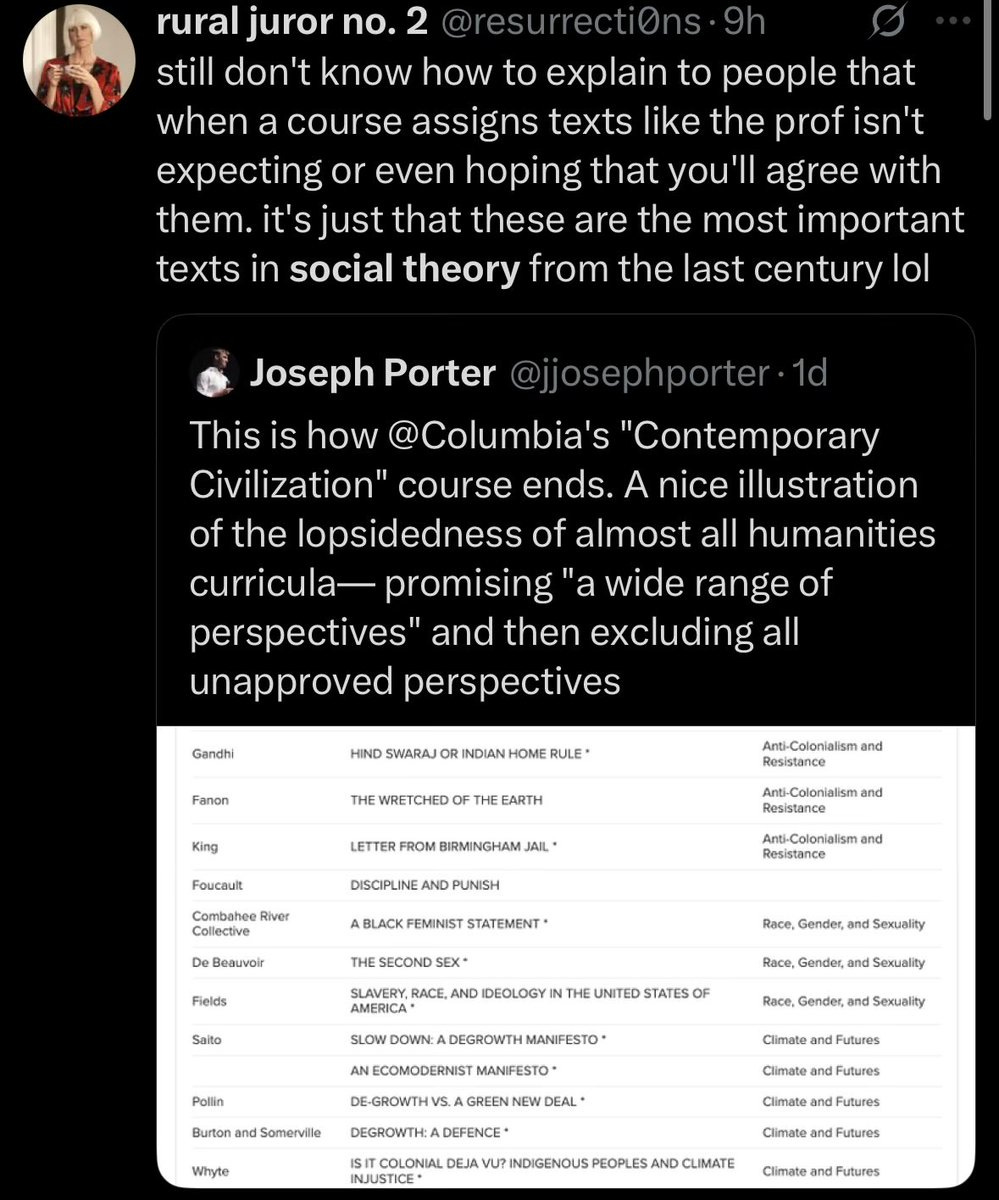
RIP Columbia Core Curriculum and Also Social Theory.
-
College Tuition and Costs.
-
Negotiation.
-
Skipping College.
-
Respect Their Authoritah.
-
Men Skipping College.
-
Stanford Still Hates Fun.
-
Value of College.
-
Employment Prospects After College.
-
Fixing College.
-
Do Not Donate To A College.
-
Not Doing The Math.
I am continuing to come around to the high-stakes-in-person-exam (or series of such exams) as the only practical solution to AI, also it was probably mostly the right answer already.
Sean T: It’s only cheat-able because classes are set up to be cheat-able. Offer in-class exams and oral presentations and it is not cheat-able. OSU stats classes were switching to group projects in lieu of finals even before ChatGPT because it’s such an important skill in the workplace.
Nate Silver: I took my junior year in London and the whole system there was basically one high-stakes in-person exam at the end of the year. That’s probably what I’d do if I taught a class now, plus opportunities to get your grade rounded up with class participation.
My guess we should give students the opportunity to create a floor in other ways. Essentially I think of this as a deal – if you do the assignments and participation and so on in a way that demonstrates effort, and something goes wrong, we will soften the blow for you, which also encourages students in danger not to skip them. But if you’re confident, then that’s all indicative, and only the test matters.
An alternative theory of how LLMs take tests, also great practical advice.
David Chapman: My father, a high school English teacher, once took and aced the AP Physics exam with zero knowledge of the subject, to prove a point: you do well on standardized tests by knowing how to take tests.
LLMs know how to take tests.
🎓 How my father did it: a thread.
🎓 How to ace the AP Physics test without knowing physics: first of two answers to a challenge.
The correct answer has different typography than the wrong ones (extra space around ✖️). This is common! Test writers screw up frequently.
🎓 How to ace the AP Physics test without knowing any physics, second answer: reasoning about the question, not the content. These heuristics are quite reliable! Several other people in the thread answered similarly.
🎓 How to win at any multiple choice test without knowing anything. At least two of the answers are always wildly wrong and you can eliminate them with basic sanity checks. And the correct answer is usually a medium value.
🎓 How to ace the AP Physics test without knowing any physics, part three: you get the highest score if you answer 70% correct. If you eliminate 3/5 clearly wrong answers on each question, that’s 60%, so you only need to get a few more actually right.
My counterargument would be that physics is the best case scenario. You do indeed know a lot about physics, because the world is made of physics. The tricks work great.
Most other subjects are not like that. You cannot get as far.
ACT makes science portion optional. Also scores keep going down.
This is the world we have created, in so many ways, and you wonder why students are so eager to use ChatGPT.
Rachel Cohen: incredible quote in the wsj on testing accommodations.
I am less scared by the ease of cheating and more by the view of not cheating as meaning you don’t love your kids. I am not so concerned about people getting extra time, as for most tests the deadline should be a mercy to prevent students from staying there for days, rather than costing you a lot of points.
The historical rate of cheating was not low, although far from universal.
Nate Silver: Using a VERY broad definition of cheating, did you cheat, even a little tiny bit, in college?
Whereas, this is the grading system Working as Designed, or at least how it should have been designed:
Astra: A childhood story that my mom reminds me of is that in grade school I had poor grades in CS because typing tests were weighted heavily, but then suddenly my grades got a lot better because I discovered that the test results were stored in an accessible local file.
I was worse at typing than anybody else in the class by a huge margin [also spelling].
Eigil: They did an xkcd 2385 in real life.
Gregori128: The purpose of a system is what it does.
Then there’s the outright mandatory gaming of the system:
Amanda Askell: I’m sure people would get mad if schools offered classes in “how to game tests” but the art of gaming tests is basically just general purpose problem solving and probably something we should teach kids to do. Might even force us to improve our tests.
Well, actually, we totally do lots of forms of this now, except that too much of it is specialized rather than general. So we can’t even do this right.
Stanford introduced a remedial math course in 2022. Given the applicant pool there should be no such class. Why are we admitting enough students who need this class to have an entire class? If you’re worth the exception you’re worth hiring tutors or finding some other way.
Alex Tabarrok: At first there will be remedial math courses because the professors remember past cohorts of students but over time remedial will become average, professors will forget and pretty soon almost everyone will believe it has always been thus.
Patrick Collison: This week, a math professor at MIT told me that incoming students are, on average, noticeably worse at math than they used to be.
Harvard, of course, just added a remedial math class, Math MA5, “aimed at rectifying a lack of foundational algebra skills among students”.
A look back at an early 20th century middle school exam. If the kids can pass this, then on those subjects I’d be satisfied the kids are all right.
In The New York Times, Jonathan Malesic claims There’s a Very Good Reason College Students Don’t Read Anymore, and the reason seems to be they’re no longer required to do it, with the author cutting down from nine required books to none, but vowing to return to one next term?
Or rather, the argument is that what you learn in school does not matter?
Jonathan Malesic: Once students graduate, the jobs they most ardently desire are in what they proudly call the “sellout” fields of finance, consulting and tech. To outsiders, these industries are abstract and opaque, trading on bluster and jargon. One thing is certain, though: That’s where the money is.
All in all, it looks as if success follows not from knowledge and skill but from luck, hype and access to the right companies. If this is the economy students believe they’re entering, then why should they make the effort to read? For that matter, how will any effort in school prepare them for careers in which, apparently, effort is not rewarded?
Given all this, it’s easy to lose faith in humanistic learning.
In which case, um, why have a college at all, if you’re not going to force students to do the things they wouldn’t be doing anyway that you think is good for them? Did you think students used to read books because the big paying jobs wouldn’t hire you unless you had mastered The Iliad?
And why would you think that finance, consulting and tech are luck? They are very much not luck at all. Your success in school matters on the job market quite a bit, as do your knowledge and skill. It’s just not the knowledge and skills that Malesic teaches, which is fine, but it also never was.
A paper examines the impact of remote learning on the beauty premium for university students.
Highlights:
I examine the relationship between university students’ appearance and grades.
When education is in-person, attractive students receive higher grades.
The effect is only present in courses with significant teacher–student interaction.
Grades of attractive females declined when teaching was conducted remotely.
For males, there was a beauty premium even after the switch to online teaching.
Abstract
This paper examines the role of student facial attractiveness on academic outcomes under various forms of instruction, using data from engineering students in Sweden. When education is in-person, attractive students receive higher grades in non-quantitative subjects, in which teachers tend to interact more with students compared to quantitative courses. This finding holds both for males and females. When instruction moved online during the COVID-19 pandemic, the grades of attractive female students deteriorated in non-quantitative subjects. However, the beauty premium persisted for males, suggesting that discrimination is a salient factor in explaining the grade beauty premium for females only.
…
Taken together, these findings suggest that the return to facial beauty is likely to be primarily due to discrimination for females, and the result of a productive trait for males.
I find the ‘interact more’ hypothesis amusing, since it’s a strange way of saying ‘professor can (at least within reason) make up whatever grades they want.’
A plausible hypothesis for the productive trait in males is confidence, and a willingness to interact and work the system, that survives not being physically proximate in a way that similar female strategies do not. Preference for interaction in males could be much more strongly tied to attractiveness than in females, for several obvious reasons.
When I was forced to endure the Columbia Core Curriculum, I would not say I enjoyed my experience, but I understood why most of the books were there. Claude offers this summary, which mostly matches my experience but not entirely, and the ones that were added as optional (like Rawls and Marquez) seemed quite bad:
Literature Humanities: Homer (Iliad, Odyssey), Aeschylus, Sophocles, Euripides, Herodotus, Thucydides, Aristophanes, Plato, Aristotle, Virgil, Ovid, Augustine, Dante, Boccaccio, Montaigne, Shakespeare, Cervantes, Milton, Austen, Dostoevsky, Woolf
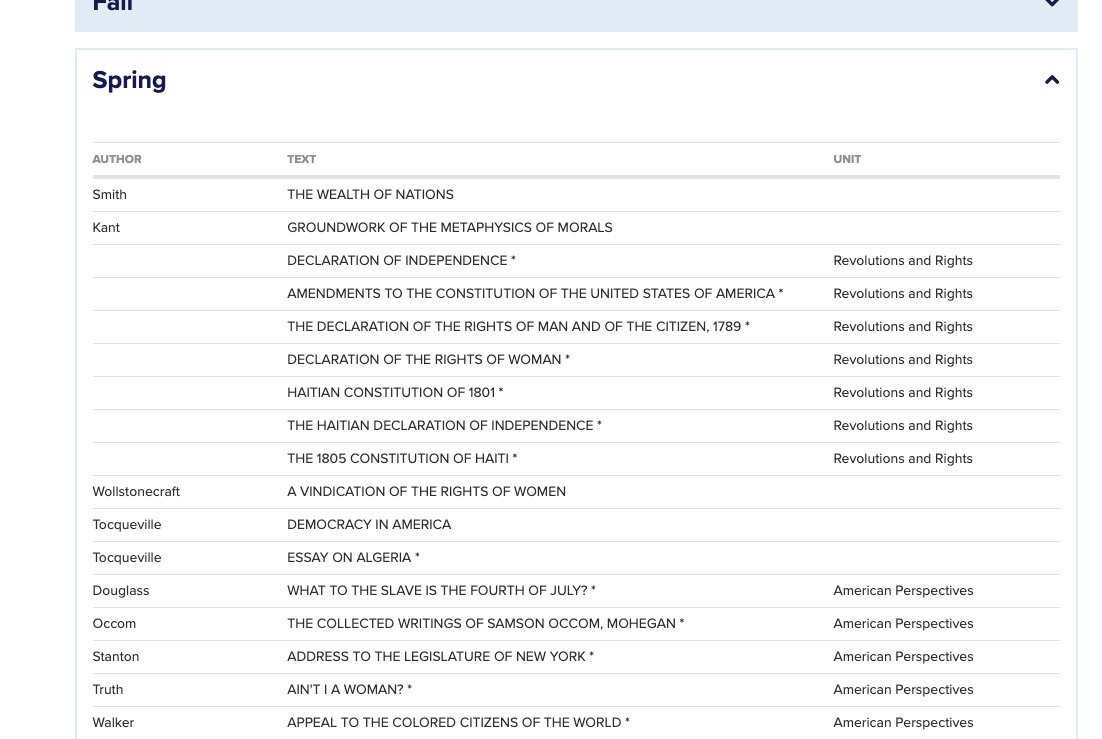
Contemporary Civilization: Plato, Aristotle, Bible, Augustine, Aquinas, Machiavelli, Descartes, Hobbes, Locke, Hume, Rousseau, Smith, Kant, Burke, Wollstonecraft, Mill, Marx, Nietzsche, Freud, Du Bois, de Beauvoir
Whereas now, well, this does not seem like it is Doing The Thing at all. It seems like it is doing a very different, deeply ideological thing, in at least the relevant section: Indoctrinating students into degrowth?
Also, yeah, if the most important texts on ‘social theory’ are all about degrowth, or even if that is a plausible claim to make, then we need to ‘degrow’ ‘social theory’, with starting over afterwards being optional.
Jason Kerwin: If the most important texts on social theory include three separate pieces on “degrowth” then it’s time to stop doing social theory
Someone else tried to defend the curriculum by scrolling up a bit:
So there’s still some of the real thing there, such as Smith and Kant, and I’m going to guess if you look at the Fall term, once we go back before there is an America to despise, that part survived more intact. This is still overall a very different mandatory product, clearly with a very different mandatory goal.
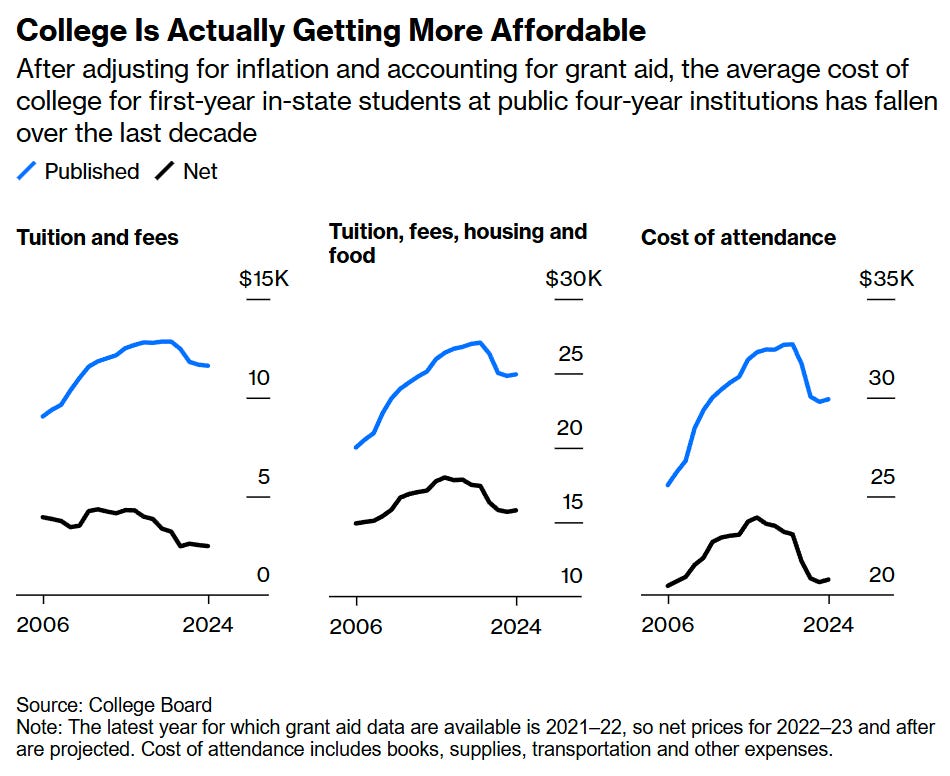
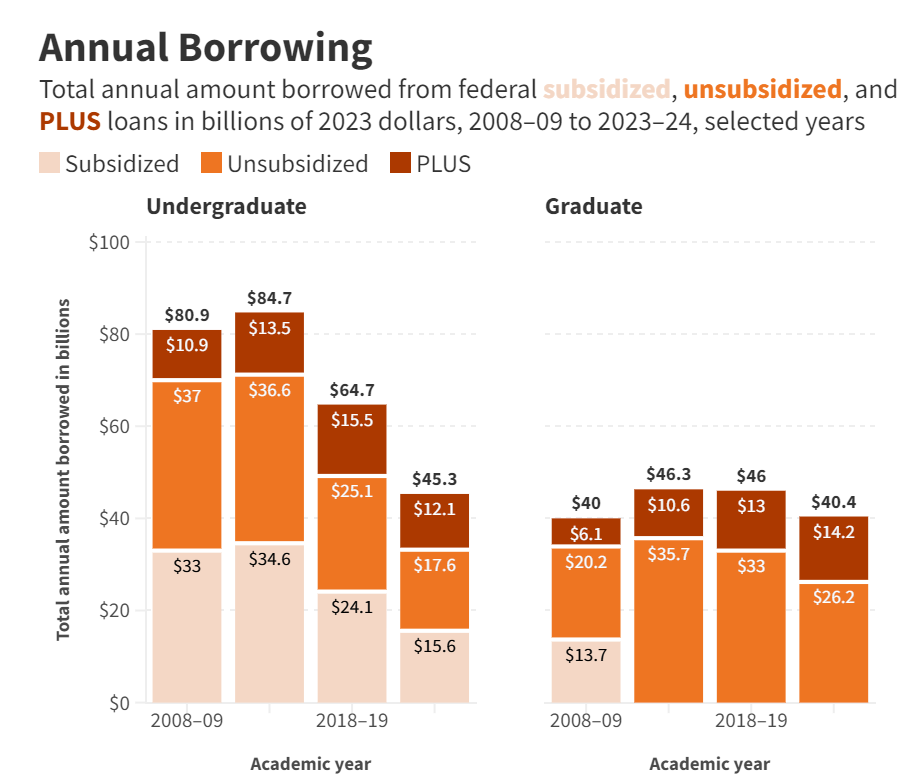
Tuition is going… down?
We will see if this is sustained, but tuition is at least not going substantially up in inflation-adjusted terms. Debt is going down.
Tyler Cowen: As might be expected, the trajectory for student debt is down as well. About half of last year’s graduates had no student debt. In 2013, only 40% did.
Public first-time, full-time, in-state tuition in four year colleges is both highly affordable and declining rapidly in real terms, in terms of what the students actually pay?
Stefan Schubert: Huge drop in the cost of public college in the US, virtually unreported.
The average inflation-adjusted net tuition and fees paid by first-time, full-time, in-state students enrolled in public four-year institutions:
2012–13: $4,340
2024–25: $2,480
[Nonprofit schools declined from $19,330 in 2006-7 (in 2024 dollars) to $16,510 this year.]
That’s not the story you typically hear. Borrowing is down too:
Graduate school is a different story here. Increasingly the forward-looking student debt problem looks like a graduate school and private (often for profit) college problem. Paying $10k total for four years of college is a fantastic deal, and not an amount that should be hard to repay. The actual catch is that you have to spend those four years learning rather than working.
It costs a lot to run schools these days, far more than it seems like it should cost. A lot of that is lots of administrators, it still seems like there is a gap to explain though?
Daniel Buck: Teachers THINK we spend ~$7500 per student
National average is actually ~$15,000 per student. Chicago spends ~$30,000 per student
How can we have an honest conversation about education when teachers themselves get basic facts this wrong?!
The Obama Administration had a great idea, which was to encourage Inclusive Access, a program where tuition includes the cost of their textbooks. This simplifies, creates price transparency, allows for aid to be calculated property, avoids students choosing classes or skimping on books to save money, and aligns incentives generally.
It seems obviously correct.
The Biden Administration disagrees, as part of its ongoing determination to screw up basic economic efficiency and functionality. They want to ban such programs. Some people frame the question of which way works better as complex. I do not think this is complex. At least this time they are not trying to steal a trillion dollars of taxpayer money to give mostly to wealthy party supporters, as they did in student loan forgiveness.
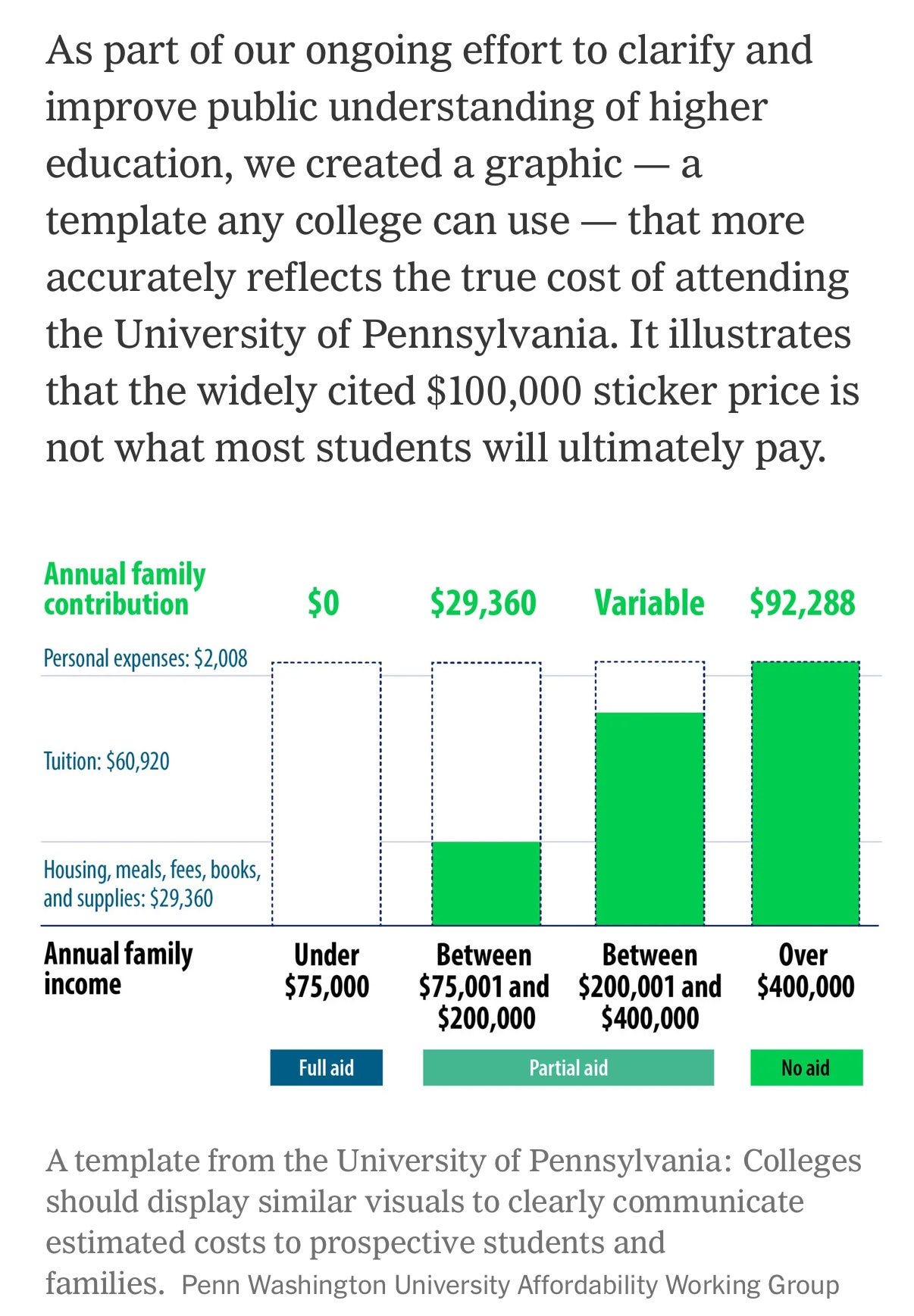
Here’s exactly what UPenn actually costs, huge props for laying this out there.
Jordan Weissmann: This kind of transparency in college pricing would be great.
But the reality is that the majority of private institutions can’t do it, because they use ‘merit aid’ as a form of dynamic pricing where they just try to maximize what kids will pay.
It seems kind of insane that it’s $30k a year in charges even if you don’t pay ‘tuition’? I mean wow, seriously. It seems like about $7800 of that is actually just de facto tuition that they call ‘fees,’ and the meal plan costs $6534 and is mandatory for two years, which students called a ‘blatant cash grab,’ as is the housing.
Looking at this as a marginal tax rate, we see a huge cliff at $75k, with an instant overall 39% tax rate attaching if you cross that boundary, and overall on the first $400k the tax rate is 23%. That’s all on pretax income, not post.
Did you know that once accepted at a college, you can absolutely negotiate?
Eric Nelson: My daughter got a 50% scholarship to a private national university and she wrote to them saying, “You’re my top choice and I’ll enroll immediately if you give me $20k more.” And they did. Who knew?!
[it was a] merit [scholarship]. And yes, she sent a very nice letter saying another school had given her more.
Eddie Gallagher: My daughter got a full ride to Seton Hall but toured in February and it was freezing. Then she toured at the University of San Diego and fell in love. She wrote an email to the University President and explained the situation. The next week she got the President’s scholarship.
For the students a college actually wants, such as those getting merit scholarships, once they’ve already committed the slot they realize a large surplus when you say yes. So it makes sense to try and negotiate a bit. They’re not going to rescind the offer.
On a purely self-interested basis who should skip college? Bryan Caplan notes that the jobs not requiring degrees are often quite solid, you shouldn’t let people potentially looking down on you distract you from that fact. Nor should you let others tell you whether you are ‘smart,’ you know better than they do.
He then focuses on the sheepskin effect, that most of the selfish benefits of college come when you graduate, and that if you pick an easy major you probably won’t see much benefit even then. So he sensibly suggests that you should go to college only if you have what it takes to reliably graduate with a ‘real’ major, which he equates to roughly an SAT of 1200, adjust your score 50-100 points for grades and motivation. And if you think you’re going to get through via an extraordinary effort, why not put that effort elsewhere?
I would take this one step further. In the Caplan model, the alternative to college is getting a standard job and career track, like trying to be a manager at Panda Express. Not that there’s anything wrong with that.
But you can almost certainly do better if you go to trade school and move towards a job like plumber or electrician. The middle path is basically free money.
And then there’s the other path, which is entrepreneur, of starting a business, which can be a startup but in no way needs to be one. This is The Way, if you can do it.
Or you can do any number of other things, such as learn to code, play poker, et cetra.
Skipping college to go straight into a job you would have wanted anyway, or at least spending less time in school first, is the definition of nice work if you can get it, if that work is indeed sufficiently nice.
The trick is convincing them to let you do that, and it makes sense that some employers like Palantir are trying to hire right out of high school instead.
Ruxandra Teslo argues this is all also feminist, because it allows women to get into position to start families while still within their fertility window, but as she says this benefits everyone. Who wouldn’t want to start real work at 18 instead of 24?
Flo Crivello outright makes the case that essentially no one should ever go to college and people should start working at age 14-16 as he did, that working is a better education than a formal education, and noting that Ben Franklin started working full-time at 12, Carnegie at 13 and Rockefeller at 16. Whereas the modern plan is that college and even your 20s are for ‘fucking around’ and this does not go great especially for fertility but also for producing value. The problem is getting out of the signaling trap.
Another reason to skip college: What are they largely trying to teach you?
Near Cyan: the RLHF that colleges perform on smart students seems particularly bad not just because the goals are artificial and gameable, but also because it encourages a default operational loop of “wait for an authority figure to tell you what to do next.”
tunient: Yeah training myself out of hacking bad tests assigned by authority figures seems like a pretty hard (but important) task, not sure exactly how to go about it though.
Main: It is so unbelievably hard to break this in people I wish I knew how to fix them.
Near Cyan: some good examples i’ve seen were putting them by people who they can relate to but are much higher agency. but it still takes a long of time and doesn’t scale well.
A huge fraction of the smartest people I know spend their lives trying to recover from this, generally with mixed success. You can mitigate, but you can’t entirely cure.
Why are so few men going to college? There are essentially three theories.
-
Men and our educational system don’t mix, it favors female talents and values.
-
Men face bad incentives and are making rational decisions.
-
Men are idiots.
These theories are not exclusive.
Celeste Davis offers a potential new version of a mix of theory two and theory three: Male flight.
Dr. Anne Lincoln: There was really only one variable where I found an effect, and that was the proportion of women already enrolled in vet med schools… So a young male student says he’s going to visit a school and when he sees a classroom with a lot of women he changes his choice of graduate school. That’s what the findings indicate…. what’s really driving feminization of the field is ‘preemptive flight’—men not applying because of women’s increasing enrollment.”
Celeste Davis: For every 1% increase in the proportion of women in the student body, 1.7 fewer men applied. One more woman applying was a greater deterrent than $1000 in extra tuition!
The rational decision version of this is a prestige and robustness story. Here are two stories given of male flight.
-
Interior Design. William Morris is considered the father of interior design. After finishing his education at Oxford, he began an architectural design school called “the Firm”— just for men. Many universities had interior design programs. Until women began to enter the design space, at which point it was relegated to a mere “hobby.” Since the influx of women, interior design programs have been pulled from almost all universities.
-
Teaching. In the 18th century, schooling in colonial America was reserved for the white and the wealthy. Most tutors were men who taught boys. By the middle of the 19th century, girls started becoming students and women became teachers. Consequently, men swiftly left the profession, the pay dropped and teaching was no longer considered a prestigious occupation.
If a profession becomes lower paying and lower prestige, there is a lot less reason to go into that profession. A large influx of new students is a lot of extra supply, so it is inevitable that at least pay will go down. And if prestige is also doomed to go down, or the profession will now damage your outlook in the dating market, then however unfair that is, that’s another good reason to bolt.
On the other hand, the local story is very much in category three. You, a straight unmarried man, didn’t study that because you would have been taking the class with a bunch of college women? Yeah, seriously, what an idiot. It’s one thing for men not to want to be in places that men inherently don’t want to be, that makes sense, A is A. But to run from a place you’d otherwise want to be, because too many women? You can say ‘they are worried people won’t think you’re manly’ or cite whatever ‘masculinity norms’ you want, it’s all shorthand for What an Idiot.
The same goes for college in general. If you are a man and hear that a college is 60/40 female, and you think ‘oh that means I would have a worse time there,’ then, again: What an Idiot. And then it happens again on the dating market.
If the men don’t see the value in that, they probably shouldn’t go to college after all. They clearly are not smart enough.
Julia Steinberg did an excellent job interviewing new Stanford President Levin, discovering yet more reasons to skip college.
I’m hopeful to see a game theorist running the place. But his answer about how he is using game theory is a bunch of generic contentless slop, as Tyler Cowen correctly noticed was Levin’s general practice throughout.
Another question was about the COLLEGE curriculum, where students are ‘contract graded’ gets an automatic A if they turn their work in on time ‘regardless of quality,’ seriously what the hell is that? If you want to be pass/fail, I hate that but at least actually be pass/fail, everyone getting an A makes a mockery of the concept of grades. The very name ‘contract graded’ is a dystopian nightmare. Levin tries to say this is ‘the best tradition of something at Stanford’ to try new things out, and iterate and improve, but that’s not an excuse, nor does he show any sign he understands the problem.
He is challenged that professors on “Democracy day” turned it into a mandatory Harris campaign event, and he says that was ‘choices’ of professors so it’s fine. He’s challenged that donations are 96% democratic and he blames the zip code. He says the giant ‘No Justice No Peace Banner’ can indefinitely hang because it’s advertising an exhibit. He later says they need to be ‘open to’ debate from ‘all ideologies’ but I see no sign he has any indication of making that happen?
On AI, he tries to pretend that Stanford is still relevant, rather than it having almost no chips and its top professors abandoning academia for business. And he tries to have it both ways, with AI changing education while Stanford somehow continues to make sense and keep its people employed.
His refusal to even say the best or worst dorm is the central answer here. No fun!
Or perhaps it is this, classic, chef’s kiss:
Stanford Review: What is the most important problem in the world right now?
President Levin: There’s no answer to that question. There are too many important problems to give you a single answer.
Stanford Review: That is an application question that we have to answer to apply here.
President Levin: Here’s a non-answer to your question.
[which was in effect to say ‘the question you are working on right now.’]
He also wouldn’t name a favorite class or give any concrete prediction. What a tool.
Another reason to maybe skip college: The wage premium for going to college for lower-income students has halved since 1960. Higher-income students take more profitable majors at better colleges now, so they benefit a lot more.
Tyler Cowen speculates this could be because the population is ‘more sorted,’ which implies a lot of the old premium was getting more out of the signaling mechanism combined with a sorting effect, and also that the students who did go to college were in better position to benefit. The paper suggests it is because we’ve neglected the lower level universities.
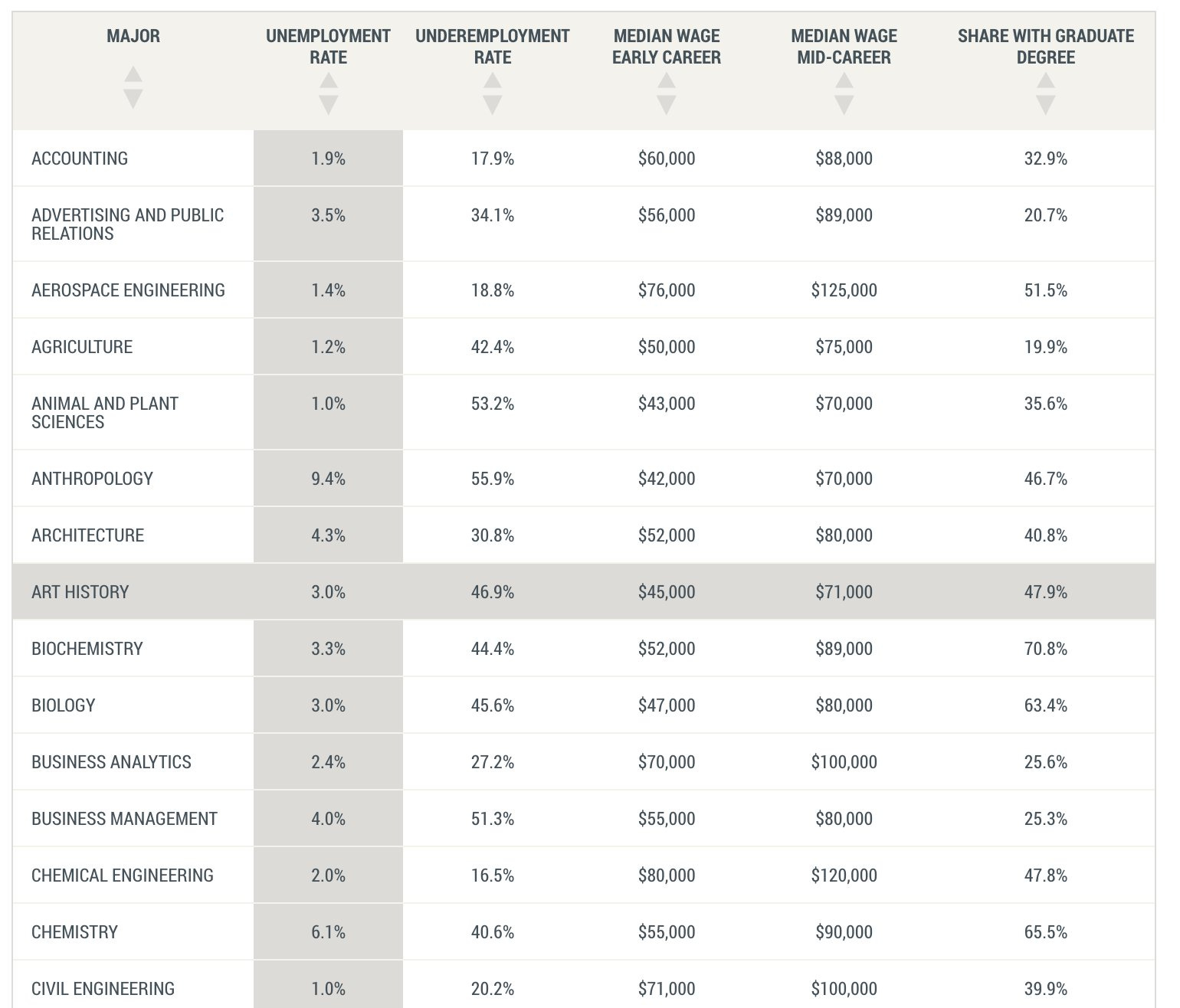
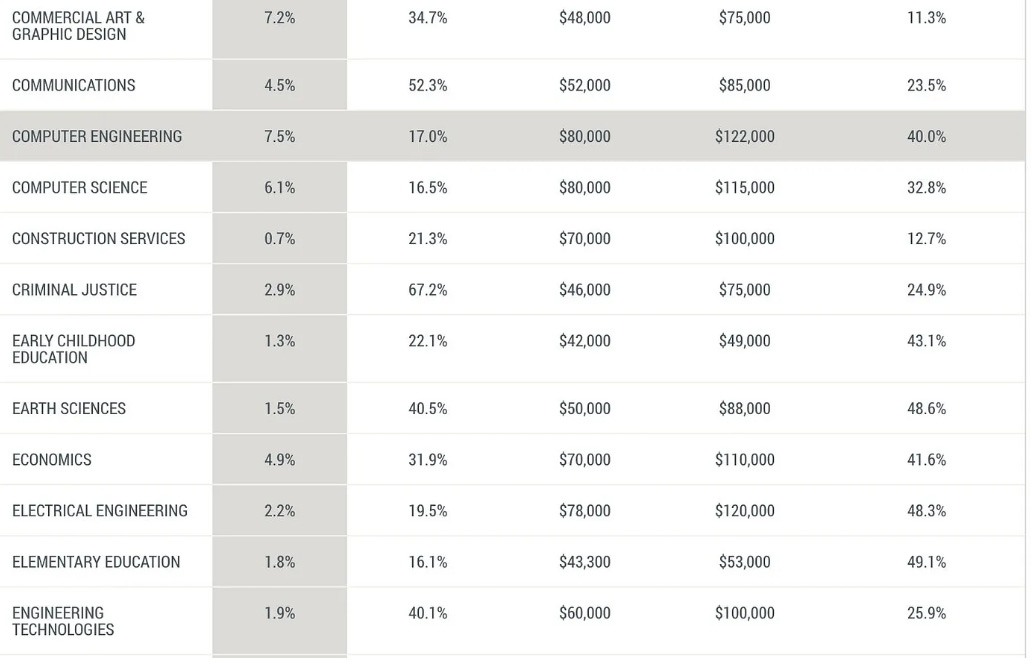
No, philosophy and art history are not good ideas for staying employed. Sorry.
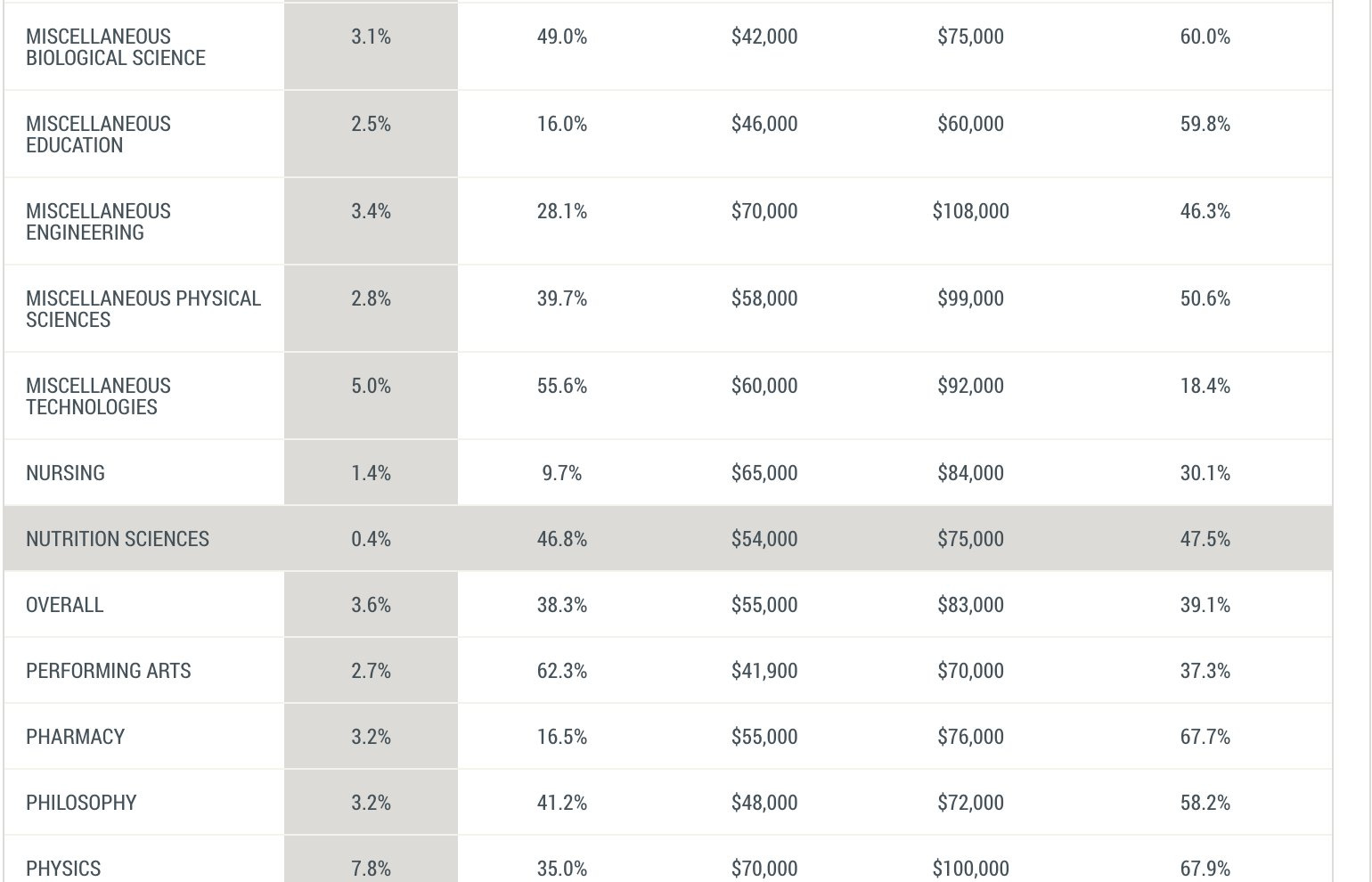
Business News (warning: misleading): According to the Federal Reserve Bank of New York, the college majors with the lowest unemployment rates for the calendar year 2023 were nutrition sciences, construction services, and animal/plant sciences.
Each of these majors had unemployment rates of 1% or lower among college graduates ages 22 to 27. Art history had an unemployment rate of 3% and philosophy of 3.2%…
Meanwhile, college majors in computer science, chemistry, and physics had much higher unemployment rates of 6% or higher post-graduation. Computer science and computer engineering students had unemployment rates of 6.1% and 7.5%, respectively…
Seth Burn: Yay philosophy!
Tyler Cowen: Here is the full story. Why is this? Are the art history majors so employable? Or are there options so limited they don’t engage in much search and just take a job right away?
Kyla Scanlon: “Majors in nutrition, art history and philosophy all outperformed STEM fields when it comes to employment prospects.”
Scott (commenting on this in MR): These articles are looking only at unemployment and neglecting the abysmal underemployment rates for graduates of these majors. Per that same Fed report: Nutrition Sciences (46.8%), Art History (46.9%), Philosophy (41.2%). Underemployment for the majors they mock: Computer Science (16.5%), Computer Engineering (17%), Economics (31.9%), Finance (31.5%). One has to suffer from serious innumeracy to think that Fed report suggests the conventional (parental) wisdom about employable majors is way off base and that more kids should be majoring in the humanities.
Brent (MR): Art history students are aware of the lack of jobs in their field and, thus will take any employment opportunities, such as a baristas, and at lower wages. Those in STEM are holding out for meaning jobs related to their studies that pay a better wage.
Joe Flaherty: It is also worth noting that STEM majors make nearly 2X as much as those in the majors mentioned and suffer from much lower rates of underemployment.
Consider those last two lines. Yes, philosophy has a lot less unemployment, but I’d much rather be in the physics group. The median wage is almost 50% higher and the right tail is big if you pivot into tech or finance. I do think the higher unemployment is that art history or philosophy majors know they can’t hold out for the jobs they most want, whereas the physics and computer science majors can hold out.
Tyler Cowen says we need a revolution in higher education, and we will know it when we see top universities stop thinking about teaching in terms of satisfying a fixed ‘class load’ and start rewarding innovation and adapting to what makes sense for teaching a given subject.
The post is confusing to me because it has the implicit background assumption that college is about learning things in classes, or that teaching things in classes is a large part of the job of a professor. I strongly agree the system could do a much better job of teaching material to students, but my presumption is that it is not so interested in doing that, either in relation to AI or otherwise.
Hollis Robbins argues that business metrics broke the university. Colleges increasingly started maximizing for student outcomes, prestige and other KPIs, and used centralized power to do it. In the process they deprioritizing getting out of the way for faculty so that departments and professors could run their own corners and power bases both to do unique work and advocate distinct positions. Which also meant that there was nothing to stop various ideological pressures coming from certain parts of the faculty and student body from overrunning the campus.
If you’re trying to Do Good, donating to your Alma Mater is deeply foolish.
So, if you are a college, what do you do when people stop feeling obligated to do it?
PoliMath: I’d be curious to know what the demographics of university donations are these days
All my friends under 40 see college as a service they paid through the nose for and that transaction completed on graduation
Donating more money to them feels like donating to a car dealership
They’re not wrong. I’m happy kids have realized this is stupid, and they’ve already been robbed enough. The only reason to donate is to get your kids into that college. But that’s a rather dim motivation at this point. You don’t get that huge an edge unless you’re paying through the nose, you don’t know that edge gets sustained, you don’t know your kids will want to go there or even go to college at all.
So, what’s next? I don’t think Eliezer’s suggestion here works at all, but it’s fun to think about it.
Eliezer Yudkowsky: An obvious evolution of the institution would be for them to make a big deal out of revoking some degrees over minor shit, and then heavily hint that alumni donors are safe. You’d no longer own a degree; you’d rent one, just like you no longer own the software you use.
Student loans are a glorious thing for them — they control your ability to get a job, so why shouldn’t they demand a nice portion of the first 20 years’ receipts? But with degrees that you have to pay to keep, they could scale the required payments even further, just like they scale back financial aid if you have a scholarship.
The degree is some combination of education, socialization and signaling. The first two can’t be taken away from you via degree revocation. So what this takes away is the signal, but mostly that signal should still stand despite the revocation, especially if there’s a pattern of revoking it for dumb stuff. Almost no one will even check. And obviously, if the college can ‘hold you up’ for more money later, there’s a lot less motivation to go to college at all.
As a concrete example, if I was told I’d lose my degree if I didn’t donate, I wouldn’t give them even one cent for tribute. I’d let them revoke my degree, what the hell do I care, also fyou.
A lot of the math has been cancelled, because the math is being done at universities.
Terence Tao: The current administration in the US has, through various funding agencies such as the NSF and NIH, has recently suspended virtually all federal grants to my home university, UCLA (including my own personal grant, although that is far from the most serious impact of this decision), on the grounds that UCLA was “failing to promote a research environment free of antisemitism and bias”.
One can certainly debate whether these grounds were justified, or whether they merit the extremely draconian damage to the very research environment that this decision is claiming to protect, but if nothing else this unprecedented decision does not appear to have followed the usual standards of due process for actions of this nature; for instance, there appears to have been no good faith effort by the administration to receive a response from UCLA to its allegations before implementing its decision.
The suspension of my personal grant has a non-trivial impact on myself (in particular, my summer salary, which I had already deferred in order to allow the previously released NSF funds to support several of my graduate students over this period, is now in limbo), and now gives me almost no resources to support my graduate students going forward; but this is only a fraction of a percent of the entire amount being suspended.
A far greater concern is the impact on the Institute for Pure and Applied Mathematics (IPAM) https://www.ipam.ucla.edu/, which despite receiving preliminary approval earlier this year for a new five-year round of funding (albeit at significantly reduced levels) from the NSF, now only has enough emergency funding for a few months of further operation at best if the suspension is not lifted.
(More details follow)
The people defending this decision are saying, essentially, that UCLA was acting sufficiently badly that it was necessary to not give them a dollar, and if he ‘stood idly by’ while UCLA did that, it’s on him, too.
Eric Raymond: There’s been some griping here on X recently about Terrence Tao losing his research grant. And yes, I think this is a shame – I have enormous respect for the man.
But. If you stand idly by as an academic while your university engages in illegal and immoral racial discrimination, I don’t think you have any actual grounds for complaint when your failure to oppose that discrimination comes back around to bite you in the ass.
Would I like to live in a world where research funding for titans like Tao isn’t subject to political winds? Why yes, I would.
I’d also like to live in a world where the Marxists who corrupted the university system are all dead or exiled and institutions of higher learning have returned to affirming the highest values of the civilization they serve.
We won’t get the former until we get the latter.
Roon: you are doing something close to maoism ie getting mad at terry tao (a guy who is reportedly such a mathematically preoccupied egghead he can barely tie his own shoelaces) wasn’t more politically conscious about the hiring policies at his university.
it reminds me of the “it’s not enough to not be racist you have to be actively antiracist” type of diatribes, stretching back to children beating up professors of relativity at Tsinghua university for being insufficiently Marxist.
don’t let politics become totalizing or you lose your moral superiority over whatever forces of communism you are expelling.
Eric Raymond: Thank you, roon. That’s the most thoughtful response I’ve seen on this thread.
And you’d have a point if I were actually mad at Tao or wanted him to suffer. But I don’t. I’d be delighted if he collected a wealthy patron and could refrain from thinking about politics ever again.
I’m lamenting the fact that Tao and people like him didn’t oppose the Long Marchers before they became so entrenched in the universities that only Donald Trump with fire and sword could even dream of disrupting their hegemony.
Like it or not, when we join institutions – and especially when we become stars of those institutions – we get to be held partly responsible for the institution’s behavior. It has to be that way, otherwise the incentives for stars to push back against institutional behavior that veers into corruption and evil would disappear.
Tao isn’t exempt. It was on him to speak up against literal pogroms. He didn’t, and now the bill has come due.
Joe Lonsdale: I have respect for what I’ve heard of his work.
But it’s clear that UCLA broke the law in a variety of really extreme ways – read the best material from the other side for all the stories of what went on in classes and around campus. Terence must find a saner place to work!
There’s a thin line between ‘I don’t want you or your work to suffer’ and ‘you have no right to complain when it bites you in the ass [and you or your work suffers.]’
Very ‘look what you made me do’ energy, except also with very big ‘everyone be quiet or I’ll shoot this puppy’ and then without waiting you go ahead and shoot the puppy and also another puppy energy.
If you go down this road, you have shown me what your priorities are. I really really don’t want to hear about how the future is determined by whether we ‘win the AI race’ and ‘beat China.’ It seems you think the future depends more on something else.
I do think this is a good question, to the extent we are worried not about math in general but about Tao in particular, which is not what Tao is worried about:
PoliMath: Is there not a way for some rich nerd to personally fund Terence Tao? Feels like a relatively cheap status win.
Yes, one of the advantages of refusing to fund things is that in the most egregious cases, at least up to some scale of cost, someone will step up to take your place.













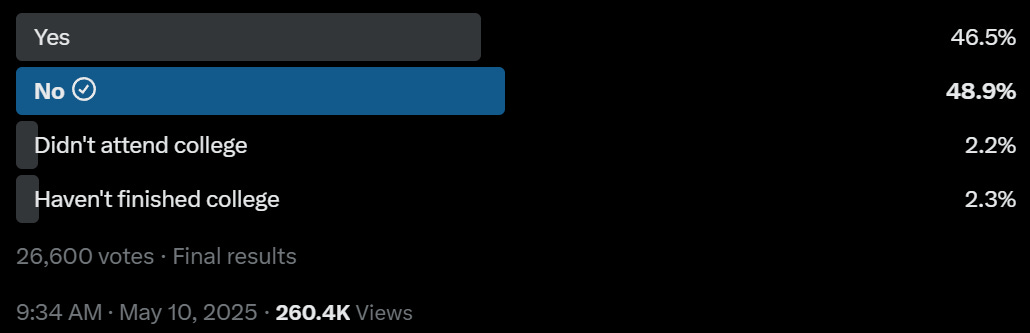








_Bromide_Rash.jpg){kind=link}