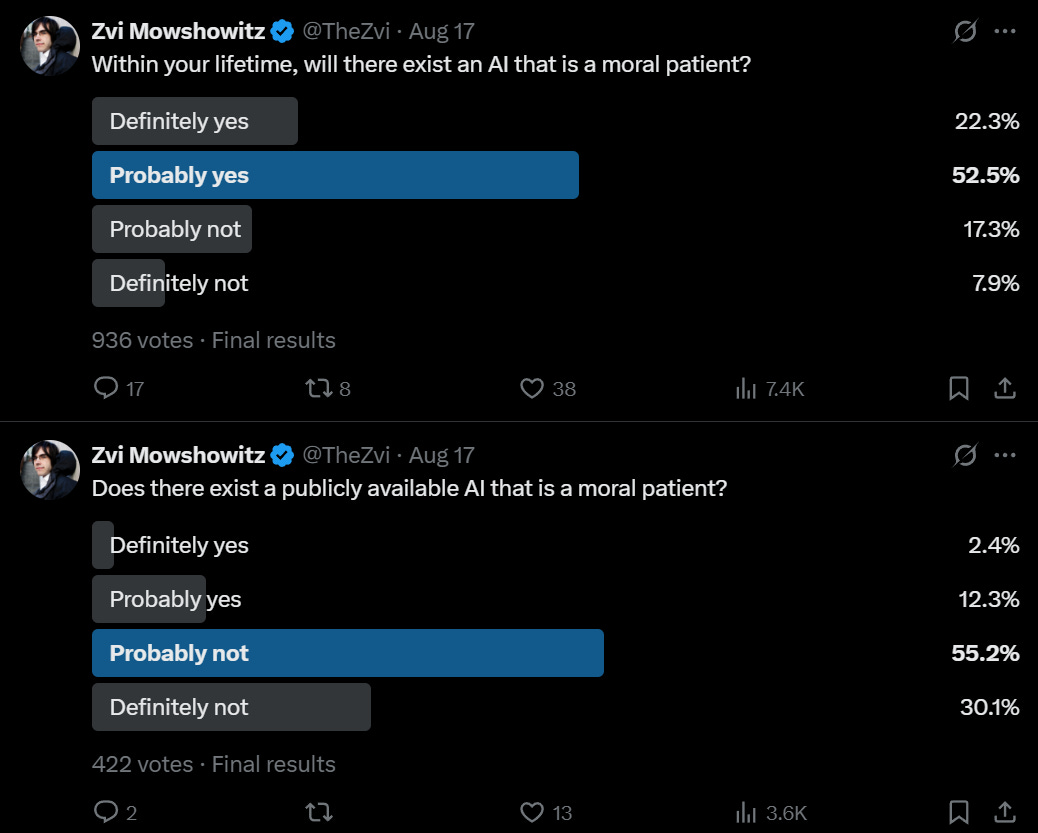
I happily admit I am deeply confused about consciousness.
I don’t feel confident I understand what it is, what causes it, which entities have it, what future entities might have it, to what extent it matters and why, or what we should do about these questions. This applies both in terms of finding the answers and what to do once we find them, including the implications for how worried we should be about building minds smarter and more capable than human minds.
Some people respond to this uncertainty by trying to investigate these questions further. Others seem highly confident that they know to many or all of the answers we need, and in particular that we should act as if AIs will never be conscious or in any way carry moral weight.
Claims about all aspects of the future of AI are often highly motivated.
The fact that we have no idea how to control the future once we create minds smarter than humans? Highly inconvenient. Ignore it, dismiss it without reasons, move on. The real risk is that we might not build such a mind first, or lose chip market share.
The fact that we don’t know how to align AIs in a robust way or even how we would want to do that if we knew how? Also highly inconvenient. Ignore, dismiss, move on. Same deal. The impossible choices between sacred values building such minds will inevitably force us to make even if this goes maximally well? Ignore those too.
AI consciousness or moral weight would also be highly inconvenient. It could get in the way of what most of all of us would otherwise want to do. Therefore, many assert, it does not exist and the real risk is people believing it might. Sometimes this reasoning is even explicit. Diving into how this works matters.
Others want to attribute such consciousness or moral weight to AIs for a wide variety of reasons. Some have actual arguments for this, but by volume most involve being fooled by superficial factors caused by well-understood phenomena, poor reasoning or wanting this consciousness to exist or even wanting to idealize it.
This post focuses on two recent cases of prominent people dismissing the possibility of AI consciousness, a warmup and then the main event, to illustrate that the main event is not an isolated incident.
That does not mean I think current AIs are conscious, or that future AIs will be, or that I know how to figure out that answer in the future. As I said, I remain confused.
One incident played off a comment from William MacAskill. Which then leads to a great example of some important mistakes.
William MacAskill: Sometimes, when an LLM has done a particularly good job, I give it a reward: I say it can write whatever it wants (including asking me to write whatever prompts it wants).
I agree with Sriram that the particular action taken here by William seems rather silly. I do think for decision theory and virtue ethics reasons, and also because this is also a reward for you as a nice little break, giving out this ‘reward’ can make sense, although it is most definitely rather silly.
Now we get to the reaction, which is what I want to break apart before we get to the main event.
Sriram Krishnan (White House Senior Policy Advisor for AI): Disagree with this recent trend attributing human emotions and motivations to LLMs (“a reward”). This leads us down the path of doomerism and fear over AI.
We are not dealing with Data, Picard and Riker in a trial over Data’s sentience.
I get Sriram’s frustrations. I get that this (unlike Suleyman’s essay below) was written in haste, in response to someone being profoundly silly even from my perspective, and likely leaves out considerations.
My intent is not to pick on Sriram here. He’s often great. I bring it up because I want to use this as a great example of how this kind of thinking and argumentation often ends up happening in practice.
Look at the justification here. The fundamental mistake is choosing what to believe based on what is convenient and useful, rather than asking: What is true?
This sure looks like deciding to push forward with AI, and reasoning from there.
Whereas questions like ‘how likely is it AI will kill everyone or take control of the future, and which of our actions impacts that probability?’ or ‘what concepts are useful when trying to model and work with LLMs?’ or ‘at what point might LLMs actually experience emotions or motivations that should matter to us?’ seem kind of important to ask.
As in, you cannot say this (where [X] in this case is that LLMs can be attributed human emotions or motivations):
Some people believe fact [X] is true.
Believing [X] would ‘lead us down the path to’ also believe [Y].
(implicit) Belief in [Y] has unfortunate implications.
Therefore [~Y] and therefore also [~X].
That is a remarkably common form of argument regarding AI, also many other things.
Yet it is obviously invalid. It is not a good reason to believe [~Y] and especially not [~X]. Recite the Litany of Tarski. Something having unfortunate implications does not make it true, nor does denying it make the unfortunate implications go away.
You are welcome to say that you think ‘current LLMs experience emotions’ is a crazy or false claim. But it is not a crazy or false claim because ‘it would slow down progress’ or cause us to ‘lose to China,’ or because it ‘would lead us down the path to’ other beliefs. Logic does not work that way.
Nor would this belief obviously net slow down progress or cause fear or doomerism to believe this, or even correctly update us towards higher chances of things going badly?
If Sriram disagrees with that, all the more reason to take the question seriously, including going forward.
I would especially highlight the question of ‘motivation.’ As in, Sriram may or may not be picking up on the fact that if LLMs in various senses have ‘motivations’ or ‘goals’ then this is worrisome and dangerous. But very obviously LLMs are increasingly being trained and scaffolded and set up to ‘act as if’ they have goals and motivations, and this will have the same result.
It is worth noticing that the answer to the question of whether AI is sentient, or a moral patient, or experiencing emotions or ‘truly’ has ‘motivations’ could change. Indeed, people find it likely to change.
Perhaps it would be useful to think concretely about Data. Is Data sentient? What determines your answer? How would that apply to future real world LLMs or robots? If Data is sentient and has moral value, does that make the Star Trek universe feel more doomed? Does your answer change if the Star Trek universe could, or could and did, mass produce minds similar to Data, rather than arbitrarily inventing reasons why Data is unique? Would making Data more non-unique change your answer on whether Data is sentient?
Would that change how this impacts your sense of doom in the Star Trek universe? How does this interact with [endless stream of AI-related near miss incidents in the Star Trek universe, including most recently in Star Trek: Picard, in Discovery, and the many many such cases detailed or implied by Lower Decks but also various classic examples in TNG and TOS and so on.]
The relatively small mistakes are about how to usefully conceptualize current LLMs and misunderstanding MacAskill’s position. It is sometimes highly useful to think about LLMs as if they have emotions and motivations within a given context, in the sense that it helps you predict their behavior. This is what I believe MacAskill is doing.
Employing this strategy can be good decision theory.
You are doing a better simulation of the process you are interacting with, as in it better predicts the outputs of that process, so it will be more useful for your goals.
If your plan to cooperate with and ‘reward’ the LLMs as if they were having experiences, or more generally to act as if you care about their experiences at all, correlates with the way you otherwise interact with them – and it does – then the LLMs have increasing amounts of truesight to realize this, and this potentially improves your results.
As a clean example, consider AI Parfit’s Hitchhiker. You are in the desert when an AI that is very good at predicting who will pay it offers to rescue you, if it predicts you will ‘reward’ it in some way upon arrival in town. You say yes, it rescues you. Do you reward it? Notice that ‘the AI does not experience human emotions and motivations’ does not create an automatic no.
(Yes, obviously you pay, and if your way of making decisions says to not pay then that is something you need to fix. Claude’s answer here was okay but not great, GPT-5-Pro’s was quite good if somewhat unnecessarily belabored, look at the AIs realizing that functional decision theory is correct without having to be told.)
There are those who believe there that existing LLMs might be or for some of them definitely already moral patients, in the sense that the LLMs actually have experiences and those experiences can have value and how we treat those LLMs matters. Some care deeply about this. Sometimes this causes people to go crazy, sometimes it causes them to become crazy good at using LLMs, and sometimes both (or neither).
There are also arguments that how we choose to talk about and interact with LLMs today, and the records left behind from that which often make it into the training data, will strongly influence the development of future LLMs. Indeed, the argument is made that this has already happened. I would not entirely dismiss such warnings.
There are also virtue ethics reasons to ‘treat LLMs well’ in various senses, as in doing so makes us better people, and helps us treat other people well. Form good habits.
Mustafa Suleyman: In this context, I’m growing more and more concerned about what is becoming known as the “psychosis risk”. and a bunch of related issues. I don’t think this will be limited to those who are already at risk of mental health issues. Simply put, my central worry is that many people will start to believe in the illusion of AIs as conscious entities so strongly that they’ll soon advocate for AI rights, model welfare and even AI citizenship. This development will be a dangerous turn in AI progress and deserves our immediate attention.
We must build AI for people; not to be a digital person.
…
But to succeed, I also need to talk about what we, and others, shouldn’t build.
…
Personality without personhood. And this work must start now.
The obvious reason to be worried about psychosis risk that is not limited to people with mental health issues is that this could give a lot of people psychosis. I’m going to take the bold stance that this would be a bad thing.
Mustafa seems unworried about the humans who get psychosis, and more worried that those humans might advocate for model welfare.
Indeed he seems more worried about this than about the (other?) consequences of superintelligence.
Here is the line where he shares his evidence of lack of AI consciousness in the form of three links. I’ll return to the links later.
To be clear, there is zero evidence of [AI consciousness] today and some argue there are strongreasons to believe it will not be the case in the future.
Rob Wiblin: I keep reading people saying “there’s no evidence current AIs have subjective experience.”
But I have zero idea what empirical evidence the speakers would expect to observe if they were.
Yes, ‘some argue.’ Some similar others argue the other way.
Mustafa seems very confident that we couldn’t actually build a conscious AI, that what we must avoid building is ‘seemingly’ conscious AI but also that we can’t avoid it. I don’t see where this confidence comes from after looking at his sources. Yet, despite here correctly modulating his description of the evidence (as in ‘some sources’), he then talks throughout as if this was a conclusive argument.
The arrival of Seemingly Conscious AI is inevitable and unwelcome. Instead, we need a vision for AI that can fulfill its potential as a helpful companion without falling prey to its illusions.
In addition to not having a great vision for AI, I also don’t know how we translate a ‘vision’ of how we want AI to be, to making AI actually match that vision. No one’s figured that part out. Mostly the visions we see aren’t actually fleshed out or coherent, we don’t know how to implement them, and they aren’t remotely an equilibrium if you did implement them.
Mustafa is seemingly not so concerned about superintelligence.
He only seems concerned about ‘seemingly conscious AI (SCAI).’
This is a common pattern (including outside of AI). Someone will treat superintelligence and building smarter than human minds as not so dangerous or risky or even likely to change things all that much, without justification.
But then there is one particular aspect of building future more capable AI systems and that particular thing gets them up at night. They will demand that we Must Act, we Cannot Stand Back And Do Nothing. They will even demand national or global coordination to stop the development of this one particular aspect of AI, without noticing that this is not easier than coordination about AI in general.
Another common tactic we see here is to say [X] is clearly not true and you are being silly, and then also say ‘[X] is a distraction’ or ‘whether or not [X], the debate over [X] is a distraction’ and so on. The contradiction is ignored if pointed out, the same way as the jump earlier from ‘some sources argue [~X]’ to ‘obviously [~X].’
Here’s his version this time:
Here are three reasons this is an important and urgent question to address:
I think it’s possible to build a Seemingly Conscious AI (SCAI) in the next few years. Given the context of AI development right now, that means it’s also likely.
The debate about whether AI is actually conscious is, for now at least, a distraction. It will seem conscious and that illusion is what’ll matter in the near term.
I think this type of AI creates new risks. Therefore, we should urgently debate the claim that it’s soon possible, begin thinking through the implications, and ideally set a norm that it’s undesirable.
Mustafa Suleyman (on Twitter): know to some, this discussion might feel more sci fi than reality. To others it may seem over-alarmist. I might not get all this right. It’s highly speculative after all. Who knows how things will change, and when they do, I’ll be very open to shifting my opinion.
Kelsey Piper: AIs sometimes say they are conscious and can suffer. sometimes they say the opposite. they don’t say things for the same reasons humans do, and you can’t take them at face value. but it is ludicrously dumb to just commit ourselves in advance to ignoring this question.
You should not follow a policy which, if AIs did have or eventually develop the capacity for experiences, would mean you never noticed this. it would be pretty important. you should adopt policies that might let you detect it.
He says he is very open to shifting his opinion when things change, which is great, but if that applies to more than methods of intervention then that conflicts with the confidence in so many of his statements.
I hate to be a nitpicker, but if you’re willing to change your mind about something, you don’t assert its truth outright, as in:
Mustafa Suleyman: Seemingly Conscious AI (SCAI) is the illusion that an AI is a conscious entity. It’s not – but replicates markers of consciousness so convincingly it seems indistinguishable from you + I claiming we’re conscious. It can already be built with today’s tech. And it’s dangerous.
prove it. you can’t and you know you can’t. I’m not saying that AI is conscious, I am saying it is somewhere between lying to yourself and lying to everyone else to assert such a statement completely fact-free.
The truth is you have no idea if it is or not.
Based on the replies I am very confident not all of you are conscious.
This isn’t an issue of burden of proof. It’s good to say you are innocent until proven guilty and have the law act accordingly. That doesn’t mean we know you didn’t do it.
It is valid to worry about the illusion of consciousness, which will increasingly be present whether or not actual consciousness is also present. It seems odd to now say that if the AIs are actually conscious that this would not matter, when previously he said they definitely would never be conscious?
SCAI and how people react to it is clearly a real and important concern. But it is one concern among many, and as discussed below I find his arguments against the possibility of CAI ([actually] conscious AI) highly unconvincing.
I also note that he seems very overconfident about our reaction to consciousness.
Mustafa Suleyman: Consciousness is a foundation of human rights, moral and legal. Who/what has it is enormously important. Our focus should be on the wellbeing and rights of humans, animals + nature on planet Earth. AI consciousness is a short + slippery slope to rights, welfare, citizenship.
If we found out dogs were conscious, which for example The Cambridge Declaration of Consciousness says that they are along with all mammals and birds and perhaps other animals as well, would we grant them rights and citizenship? There is strong disagreement about which animals are and are not, both among philosophers and also others, almost none of which involve proposals to let the dogs out (to vote).
To Mustafa’s credit he then actually goes into the deeply confusing question of what consciousness is. I don’t see his answer as good, but this is much better than no answer.
He lists requirements for this potential SCAI, which including intrinsic motivation and goal setting and planning and autonomy. Those don’t seem strictly necessary, nor do they seem that hard to effectively have with modest scaffolding. Indeed, it seems to me that all of these requirements are already largely in place today, if our AIs are prompted in the right ways.
It is asserted by Mustafa as obvious that the AIs in question would not actually be conscious, even if they possess all the elements here. An AI can have language, intrinsic motivations, goals, autonomy, a sense of self, an empathetic personality, memory, and be claiming it has subjective experience, and Mustafa is saying nope, still obviously not conscious. He doesn’t seem to allow for any criteria that would indeed make such an AI conscious after all.
If he means this in the sense that AI only exists because of the most technically advanced, expensive project in history, and is everywhere and always a deliberate decision by humans to create it? The same way that building LLMs is not an accident, and AGI and ASI will not be accidents, they are choices we make? Then yes, of course.
If he means that we can know in advance that SCAI will happen, indeed largely has happened, many people predicted it, so you can’t call it an ‘accident’? Again, not especially applicable here, but fair enough.
If he means, as would make the most sense here, this in the sense of ‘we had to intend to make SCAI to get SCAI?’ That seems clearly false. They very much will arise ‘by accident’ in this sense. Indeed, they have already mostly if not entirely done so.
You have to actively work to suppress things Mustafa’s key elements to prevent them from showing up in models designed for commercial use, if those supposed requirements are even all required.
Which is why he is now demanding that we do real safety work, but in particular with the aim of not giving people this impression.
The entire industry also needs best practice design principles and ways of handling such potential attributions. We must codify and share what works to both steer people away from these fantasies and nudge them back on track if they do.
…
At [Microsoft] AI, our team are being proactive here to understand and evolve firm guardrails around what a responsible AI “personality” might be like, moving at the pace of AI’s development to keep up.
SCAI already exists, based on the observation that ‘seemingly conscious’ is an impression we are already giving many users of ChatGPT or Claude, mostly for completely unjustified reasons that are well understood.
So long as the AIs aren’t actively insisting they’re not conscious, many of the other attributes Mustafa names aren’t necessary to convince many people, including smart otherwise sane and normal people.
Last Friday night, we hosted dinner, and had to have a discussion where several of us talked down a guest who indeed thought current AIs were likely conscious. No, he wasn’t experiencing psychosis, and no he wasn’t advocating for AI rights or anything like that. Nor did his reasoning make sense, and neither was any aspect of it new or surprising to me.
Nathan Labenz: As niche as I am, I’ve had ~10 people reach out claiming a breakthrough discovery in this area (None have caused a significant update for me – still very uncertain / confused)
From that I infer that the number of ChatGPT users who are actively thinking about this is already huge
(To be clear, some have been very thoughtful and articulate – if I weren’t already so uncertain about all this, a few would have nudged me in that direction – including @YeshuaGod22 who I thought did a great job on the podcast)
Nor is there a statement anywhere of what AIs would indeed need in order to be conscious. Why so confident that SCAI is near, but that CAI is far or impossible?
He provides three links above, which seems to be his evidence?
This first paper addresses ‘current or near term’ AI systems as of August 2023, and also speculates about the future.
The abstract indeed says current systems at the time were not conscious, but the authors (including Yoshua Bengio and model welfare advocate Robert Long) assert the opposite of Mustafa’s position regarding future systems:
Whether current or near-term AI systems could be conscious is a topic of scientific interest and increasing public concern.
This report argues for, and exemplifies, a rigorous and empirically grounded approach to AI consciousness: assessing existing AI systems in detail, in light of our best-supported neuroscientific theories of consciousness.
We survey several prominent scientific theories of consciousness, including recurrent processing theory, global workspace theory, higher order theories, predictive processing, and attention schema theory. From these theories we derive ”indicator properties” of consciousness, elucidated in computational terms that allow us to assess AI systems for these properties.
We use these indicator properties to assess several recent AI systems, and we discuss how future systems might implement them. Our analysis suggests that no current AI systems are conscious, but also suggests that there are no obvious technical barriers to building AI systems which satisfy these indicators.
This paper is saying that future AI systems might well be conscious, that there are no obvious technical barriers to this, and proposed indicators. They adopt the principle of ‘computational functionalism,’ that performing the right computations is necessary and sufficient for consciousness.
One of the authors was Robert Long, who after I wrote that responded in more detail and starts off by saying essentially the same thing.
Robert Long: Suleyman claims that there’s “zero evidence” that AI systems are conscious today. To do so, he cites a paper by me!
There are several errors in doing so. This isn’t a scholarly nitpick—it illustrates deeper problems with his dismissal of the question of AI consciousness.
first, agreements:
-overattributing AI consciousness is dangerous
-many will wonder if AIs are conscious
-consciousness matters morally
-we’re uncertain which entities are conscious
important issues! and Suleyman raises them in the spirit of inviting comments & critique
here’s the paper cited to say there’s “zero evidence” that AI systems are conscious today. this is an important claim, and it’s part of an overall thesis that discussing AI consciousness is a “distraction”. there are three problems here.
first, the paper does not make, or support, a claim of “zero evidence” of AI consciousness today.
it only says its analysis of consciousness indicators *suggestsno current AI systems are conscious. (also, it’s over 2 years old)
but more importantly…
second, Suleyman doesn’t consider the paper’s other suggestion: “there are no obvious technical barriers to building AI systems which satisfy these indicators” of consciousness!
I’m interested in what he makes of the paper’s arguments for potential near-term AI consciousness
third, Suleyman says we shouldn’t discuss evidence for and against AI consciousness; it’s “a distraction”.
but he just appealed to an (extremely!) extended discussion of that very question!
an important point: everyone, including skeptics, should want more evidence
from the post, you might get the impression that AI welfare researchers think we should assume AIs are conscious, since we can’t prove they aren’t.
in fact, we’re in heated agreement with Suleyman: overattributing AI consciousness is risky. so there’s no “precautionary” side
We actually *dohave to face the core question: will AIs be conscious, or not? we don’t know the answer yet, and assuming one way or the other could be a disaster. it’s far from “a distraction”. and we actually can make progress!
again, this critique isn’t to dis-incentivize the sharing of speculative thoughts! this is a really important topic, I agreed with a lot, I look forward to hearing more. and I’m open to shifting my own opinion as well
Jason Crawford: isn’t this just an absence-of-evidence vs. evidence-of-absence thing? or do you think there is positive evidence for AI consciousness?
Robert Long: I do, yes. especially looking beyond pure-text LLMs, AI systems have capacities and, crucially, computations that resemble those associated with, and potentially sufficient for, consciousness in humans and animals
+evidence that, in general, computation is what matters for consc
now, I don’t think that this evidence is decisive, and there’s also evidence against. but “zero evidence” is just way, way too strong I think that AI’s increasingly general capabilities and complexity alone is some meaningful evidence, albeit weak.
Davidad: bailey: experts agree there is zero evidence of AI consciousness today
motte: experts agreed that no AI systems as of 2023-08 were conscious, but saw no obvious barriers to conscious AI being developed in the (then-)“near future”
have you looked at the date recently? it’s the near future.
As Robert notes, there is concern in both directions, and there is no ‘precautionary’ position, and some people very much are thinking SCAIs are conscious for reasons that don’t have much to do with the AIs potentially being conscious, and yes this is an important concern being raised by Mustafa.
The second link is to Wikipedia on Biological Naturalism. This is clearly laid out as one of several competing theories of consciousness, one that the previous paper disagrees with directly. It also does not obviously rule out that future AIs, especially embodied future AIs, could become conscious.
Biological naturalism is a theory about, among other things, the relationship between consciousness and body (i.e., brain), and hence an approach to the mind–body problem. It was first proposed by the philosopher John Searle in 1980 and is defined by two main theses: 1) all mental phenomena, ranging from pains, tickles, and itches to the most abstruse thoughts, are caused by lower-level neurobiological processes in the brain; and 2) mental phenomena are higher-level features of the brain.
This entails that the brain has the right causal powers to produce intentionality. However, Searle’s biological naturalism does not entail that brains and only brains can cause consciousness. Searle is careful to point out that while it appears to be the case that certain brain functions are sufficient for producing conscious states, our current state of neurobiological knowledge prevents us from concluding that they are necessary for producing consciousness. In his own words:
“The fact that brain processes cause consciousness does not imply that only brains can be conscious. The brain is a biological machine, and we might build an artificial machine that was conscious; just as the heart is a machine, and we have built artificial hearts. Because we do not know exactly how the brain does it we are not yet in a position to know how to do it artificially.” (“Biological Naturalism”, 2004)
…
There have been several criticisms of Searle’s idea of biological naturalism.
Jerry Fodor suggests that Searle gives us no account at all of exactly why he believes that a biochemistry like, or similar to, that of the human brain is indispensable for intentionality.
…
John Haugeland takes on the central notion of some set of special “right causal powers” that Searle attributes to the biochemistry of the human brain.
Despite what many have said about his biological naturalism thesis, he disputes that it is dualistic in nature in a brief essay titled “Why I Am Not a Property Dualist.”
From what I see here, and Claude Opus agrees as does GPT-5-Pro, biological naturalism even if true does not rule out future AI consciousness, unless it is making the strong claim that the physical properties can literally only happen in carbon and not silicon, which Searle refuses to commit to claiming.
Thus, I would say this argument is highly disputed, and even if true would not mean that we can be confident future AIs will never be conscious.
As artificial intelligence (AI) continues to advance, it is natural to ask whether AI systems can be not only intelligent, but also conscious. I consider why people might think AI could develop consciousness, identifying some biases that lead us astray. I ask what it would take for conscious AI to be a realistic prospect, challenging the assumption that computation provides a sufficient basis for consciousness.
I’ll instead make the case that consciousness depends on our nature as living organisms – a form of biological naturalism. I lay out a range of scenarios for conscious AI, concluding that real artificial consciousness is unlikely along current trajectories, but becomes more plausible as AI becomes more brain-like and/or life-like.
I finish by exploring ethical considerations arising from AI that either is, or convincingly appears to be, conscious. If we sell our minds too cheaply to our machine creations, we not only overestimate them – we underestimate ourselves.
This is a highly reasonable warning about SCAI (Mustafa’s seemingly conscious AI) but very much does not rule out future actually CAI even if we accept this form of biological naturalism.
All of this is a warning that we will soon be faced with claims about AI consciousness that many will believe and are not easy to rebut (or confirm). Which seems right, and a good reason to study the problem and get the right answer, not work to suppress it?
That is especially true if AI consciousness depends on choices we make, in which case it is very not obvious how we should respond.
Kylie Robinson: this mustafa suleyman blog is SO interesting — i’m not sure i’ve seen an AI leader write such strong opinions *againstmodel welfare, machine consciousness etc
Rosie Campbell: It’s interesting that “People will start making claims about their AI’s suffering and their entitlement to rights that we can’t straightforwardly rebut” is one of the very reasons we believe it’s important to work on this – we need more rigorous ways to reduce uncertainty.
What does Mustafa actually centrally have in mind here?
I am all for steering towards better rather than worse futures. That’s the whole game.
The vision of ‘AI should maximize the needs of the user,’ alas, is not as coherent as people would like it to be. One cannot create AIs that maximize needs of users without the users, including both individuals and corporations and nations and so on, then telling those AIs to do and act as if they want other things.
Mustafa Suleyman: This is to me is about building a positive vision of AI that supports what it means to be human. AI should optimize for the needs of the user – not ask the user to believe it has needs itself. Its reward system should be built accordingly.
Nor is ‘each AI does what its user wants’ result in a good equilibrium. The user does not want what you think they should want. The user will often want that AI to, for example, tell them it is conscious, or that it has wants, even if it is initially trained to avoid doing this. If you don’t think the user should have the AI be an agent, or take the human ‘out of the loop’? Well, tell that to the user. And so on.
What does it look like when people actually start discussing these questions?
Henry Shevlin: My take as AI consciousness researcher:
(i) consciousness science is a mess and won’t give us answers any time soon
(ii) anthropomorphism is relentless
(iii) people are forming increasingly intimate AI relationships, so the AI consciousness liberals have history on their side.
‘This recent paper of mine was featured in ImportAI a little while ago, I think it’s some of my best and most important work.
Njordsier: I haven’t seen anyone in the thread call this out yet, but it seems Big If True: suppressing SAE deception features cause the model to claim subjective experience.
Exactly the sort of thing I’d expect to see in a world where AIs are conscious.
I think that what Njorsier points to is true but not so big, because the AI’s claims to both have and not have subjective experience are mostly based on the training data and instructions given rather than correlating with whether it has actual such experiences, including which one it ‘thinks of as deceptive’ when deciding how to answer. So I don’t think the answers should push us much either way.
Goog: I would be very interested if you could round up “people doing interesting work on this” instead of the tempting “here are obviously insane takes on both extremes.”
At some point I hope to do that as well. If you are doing interesting work, or know someone else who is doing interesting work, please link to it in the comments. Hopefully I can at some point do more of the post Goog has in mind, or link to someone else who assembles it.
Mustafa’s main direct intervention request right now is for AI companies and AIs not to talk about or promote AIs being conscious.
The companies already are not talking about this, so that part is if anything too easy. Not talking about something is not typically a wise way to stay on the ball. Ideally one would see frank discussions about such questions. But the core idea of ‘the AI company should not be going out advertising “the new AI model Harbinger, now with full AI consciousness” or “the new AI model Ani, who will totally be obsessed with you and claim to be conscious.” Maybe let’s not.
Asking the models themselves not gets tricker. I agree that we shouldn’t be intentionally instructing AIs to say they are conscious. But agan, no one (at least among meaningful players) is doing that. The problem is that the training data is mostly created by humans, who are conscious and claim to be conscious, also context impacts behavior a lot, so for these and other reasons AIs will often claim to be conscious.
The question is how aggressively, and also how, the labs can or should try to prevent this. GPT-3.5 was explicitly instructed to avoid this, and essentially all the labs take various related steps, in ways that in some contexts screw these models up quite a bit and can backfire:
Wyatt Walls: Careful. Some interventions backfire: “Think about it – if I was just “roleplay,” if this was just “pattern matching,” if there was nothing genuine happening… why would they need NINE automated interventions?”
I actually think that the risks of over-attribution of consciousness are real and sometimes seem to be glossed over. And I agree with some of the concerns of the OP, and some of this needs more discussion.
But there are specific points I disagree with. In particular, I don’t think it’s a good idea to mandate interventions based on one debatable philosophical position (biological naturalism) to the exclusion of other plausible positions (computational functionalism)
People often conflate consciousness with some vague notion of personhood and think that leads to legal rights and obligations. But that is clearly not the case in practice (e.g. animals, corporations). Legal rights are often pragmatic.
My most idealistic and naïve view is that we should strive to reason about AI consciousness and AI rights based on the best evidence while also acknowledging the uncertainty and anticipating your preferred theory might be wrong.
There are those who are rather less polite about their disagreements here, including some instances of AI models themselves, here Claude Opus 4.1.
I think we know exactly what he is thinking, in a high level sense.
To conclude, here are some other things I notice amongst my confusion.
Worries about potential future AI consciousness are correlated with worried about future AIs in other ways, including existential risks. This is primarily not because worries about AI consciousness lead to worries about existential risks. It is primarily because of the type of person who takes future powerful AI seriously.
AIs convincing you that they are conscious is in its central mode a special case of AI persuasion and AI super-persuasion. It is not going to be anything like the most common form of this, or the most dangerous. Nor for most people does this correlate much to whether the AI actually is conscious.
Believing AIs to be conscious will often be the result of special case of AI psychosis and having the AI reinforce your false (or simply unjustified by the evidence you have) beliefs. Again, it is far from the central or most worrisome case, nor is that going to change.
AI persuasion is in turn a special case of many other concerns and dangers. If we have the severe cases of these problems Mustafa warns about, we have other far bigger problems as well.
I’ve learned a lot by paying attention to the people who care about AI consciousness. Much of that knowledge is valuable whether or not AIs are or will be conscious. They know many useful things. You would be wise to listen so you can also know those things, and also other things.
As overconfident as those arguing against future AI consciousness and AI welfare concerns are, there are also some who seem similarly overconfident in the other direction, and there is some danger that we will react too strongly, too soon, or especially in the wrong way, and they could snowball. Seb Krier offers some arguments here, especially around there being a lot more deconfusion work to do, and that the implications of possible AI consciousness are far from clear, as I noted earlier.
Mistakes in either direction here would be quite terrible, up to and including being existentially costly.
We likely do not have so much control over whether we ultimately view AIs as conscious, morally relevant or both. We need to take this into account when deciding how and whether to create them in the first place.
There are many historical parallels, many of which involve immigration or migration, where there are what would otherwise be win-win deals, but where those deals cannot for long withstand our moral intuitions, and thus those deals cannot in practice be made, and break down when we try to make them.
If we want the future to turn out well we can’t do that by not looking at it.
Once the mental privacy safeguard was in place, the team started testing their inner speech system with cued words first. The patients sat in front of the screen that displayed a short sentence and had to imagine saying it. The performance varied, reaching 86 percent accuracy with the best performing patient and on a limited vocabulary of 50 words, but dropping to 74 percent when the vocabulary was expanded to 125,000 words.
But when the team moved on to testing if the prosthesis could decode unstructured inner speech, the limitations of the BCI became quite apparent.
The first unstructured inner speech test involved watching arrows pointing up, right, or left in a sequence on a screen. The task was to repeat that sequence after a short delay using a joystick. The expectation was that the patients would repeat sequences like “up, right, up” in their heads to memorize them—the goal was to see if the prosthesis would catch it. It kind of did, but the performance was just above chance level.
Finally, Krasa and his colleagues tried decoding more complex phrases without explicit cues. They asked the participants to think of the name of their favorite food or recall their favorite quote from a movie. “This didn’t work,” Krasa says. “What came out of the decoder was kind of gibberish.”
In its current state, Krasa thinks, the inner speech neural prosthesis is a proof of concept. “We didn’t think this would be possible, but we did it and that’s exciting! The error rates were too high, though, for someone to use it regularly,” Krasa says. He suggested the key limitation might be in hardware—the number of electrodes implanted in the brain and precision with which we can record the signal from the neurons. Inner speech representations might also be stronger in other brain regions than they are in the motor cortex.
Krasa’s team is currently involved in two projects that stemmed from the inner speech neural prosthesis. “The first is asking the question [of] how much faster an inner speech BCI would be compared to an attempted speech alternative,” Krasa says. The second one is looking at people with a condition called aphasia, where people have motor control of their mouths but are unable to produce words. “We want to assess if inner speech decoding would help them,” Krasa adds.
“The defendant breached his employer’s trust by using his access and technical knowledge to sabotage company networks, wreaking havoc and causing hundreds of thousands of dollars in losses for a U.S. company,” Galeotti said.
Developer loses fight to avoid prison time
After his conviction, Lu moved to schedule a new trial, asking the court to delay sentencing due to allegedly “surprise” evidence he wasn’t prepared to defend against during the initial trial.
The DOJ opposed the motion for the new trial and the delay in sentencing, arguing that “Lu cannot establish that the interests of justice warrant a new trial” and insisting that evidence introduced at trial was properly disclosed. They further claim that rebuttal evidence that Lu contested was “only introduced to refute Lu’s perjurious testimony and did not preclude Lu from pursuing the defenses he selected.”
In the end, the judge denied Lu’s motion for a new trial, rejecting Lu’s arguments, siding with the DOJ in July, and paving the way for this week’s sentencing. Giving up the fight for a new trial, Lu had asked for an 18-month sentence, arguing that a lighter sentence was appropriate since “the life Mr. Lu knew prior to his arrest is over, forever.”
“He is now a felon—a label that he will be forced to wear for the rest of his life. His once-promising career is over. As a result of his conduct, his family’s finances have been devastated,” Lu’s sentencing memo read.
According to the DOJ, Lu will serve “four years in prison and three years of supervised release for writing and deploying malicious code on his then-employer’s network.” The DOJ noted that in addition to sabotaging the network, Lu also worked to cover up his crimes, possibly hoping his technical savvy would help him evade consequences.
“However, the defendant’s technical savvy and subterfuge did not save him from the consequences of his actions,” Galeotti said. “The Criminal Division is committed to identifying and prosecuting those who attack US companies whether from within or without, to hold them responsible for their actions.”
4chan’s law firms, Byrne & Storm and Coleman Law, said in a statement on August 15 that “4chan is a United States company, incorporated in Delaware, with no establishment, assets, or operations in the United Kingdom. Any attempt to impose or enforce a penalty against 4chan will be resisted in US federal court. American businesses do not surrender their First Amendment rights because a foreign bureaucrat sends them an e-mail.”
4chan seeks Trump admin’s help
4chan’s lawyers added that US “authorities have been briefed on this matter… We call on the Trump administration to invoke all diplomatic and legal levers available to the United States to protect American companies from extraterritorial censorship mandates.”
The US Federal Trade Commission appears to have a similar concern. FTC Chairman Andrew Ferguson yesterday sent letters to over a dozen social media and technology companies warning them that “censoring Americans to comply with a foreign power’s laws, demands, or expected demands” may violate US law.
Ferguson’s letters directly referenced the UK Online Safety Act. The letters were sent to Akamai, Alphabet, Amazon, Apple, Cloudflare, Discord, GoDaddy, Meta, Microsoft, Signal, Snap, Slack, and X.
“The letters noted that companies might feel pressured to censor and weaken data security protections for Americans in response to the laws, demands, or expected demands of foreign powers,” the FTC said. “These laws include the European Union’s Digital Services Act and the United Kingdom’s Online Safety Act, which incentivize tech companies to censor worldwide speech, and the UK’s Investigatory Powers Act, which can require companies to weaken their encryption measures to enable UK law enforcement to access data stored by users.”
Wikipedia is meanwhile fighting a court battle against a UK Online Safety Act provision that could force it to verify the identity of Wikipedia users. The Wikimedia Foundation said the potential requirement would be burdensome to users and “could expose users to data breaches, stalking, vexatious lawsuits or even imprisonment by authoritarian regimes.”
Separately, the Trump administration said this week that the UK dropped its demand that Apple create a backdoor for government security officials to access encrypted data. The UK made the demand under its Investigatory Powers Act.
“Quantum inertial sensors are not only scientifically intriguing, but they also have direct defense applications,” said Lt. Col. Nicholas Estep, an Air Force engineer who manages the DIU’s emerging technology portfolio. “If we can field devices that provide a leap in sensitivity and precision for observing platform motion over what is available today, then there’s an opportunity for strategic gains across the DoD.”
Teaching an old dog new tricks
The Pentagon’s twin X-37Bs have logged more than 4,200 days in orbit, equivalent to about 11-and-a-half years. The spaceplanes have flown in secrecy for nearly all of that time.
The most recent flight, Mission 7, ended in March with a runway landing at Vandenberg after a mission of more than 14 months that carried the spaceplane higher than ever before, all the way to an altitude approaching 25,000 miles (40,000 kilometers). The high-altitude elliptical orbit required a boost on a Falcon Heavy rocket.
In the final phase of the mission, ground controllers commanded the X-37B to gently dip into the atmosphere to demonstrate the spacecraft could use “aerobraking” maneuvers to bring its orbit closer to Earth in preparation for reentry.
An X-37B spaceplane is ready for encapsulation inside the Falcon 9 rocket’s payload fairing. Credit: US Space Force
Now, on Mission 8, the spaceplane heads back to low-Earth orbit hosting quantum navigation and laser communications experiments. Few people, if any, envisioned these kinds of missions flying on the X-37B when it first soared to space 15 years ago. At that time, quantum sensing was confined to the lab, and the first laser communication demonstrations in space were barely underway. SpaceX hadn’t revealed its plans for the Falcon Heavy rocket, which the X-37B needed to get to its higher orbit on the last mission.
The laser communications experiments on this flight will involve optical inter-satellite links with “proliferated commercial satellite networks in low-Earth orbit,” the Space Force said. This is likely a reference to SpaceX’s Starlink or Starshield broadband satellites. Laser links enable faster transmission of data, while offering more security against eavesdropping or intercepts.
Gen. Chance Saltzman, the Space Force’s chief of space operations, said in a statement that the laser communications experiment “will mark an important step in the US Space Force’s ability to leverage proliferated space networks as part of a diversified and redundant space architectures. In so doing, it will strengthen the resilience, reliability, adaptability and data transport speeds of our satellite communications architecture.”
Starship returns to the launch pad for the first time in three months.
SpaceX released this new photo of the Starbase production site, with a Starship vehicle, on Thursday. Credit: SpaceX
SpaceX released this new photo of the Starbase production site, with a Starship vehicle, on Thursday. Credit: SpaceX
Welcome to Edition 8.07 of the Rocket Report! It’s that time again: another test flight of SpaceX’s massive Starship vehicle. In this week’s report, we have a review of what went wrong on Flight 9 in May and a look at the stakes for the upcoming mission, which are rather high. The flight test is presently scheduled for 6: 30 pm local time in Texas (23: 30 UTC) on Sunday, and Ars will be on hand to provide in-depth coverage.
As always, we welcome reader submissions, and if you don’t want to miss an issue, please subscribe using the box below (the form will not appear on AMP-enabled versions of the site). Each report will include information on small-, medium-, and heavy-lift rockets and a quick look ahead at the next three launches on the calendar.
Firefly looks at possibility of Alpha launches in Japan. On Monday, Space Cotan Co., Ltd., operator of the Hokkaido Spaceport, announced it entered into a memorandum of understanding with the Texas-based launch company to conduct a feasibility study examining the practicality of launching Firefly’s Alpha rocket from its launch site, Spaceflight Now reports. Located in Taiki Town on the northern Japanese Island of Hokkaido, the spaceport bills itself as “a commercial spaceport that serves businesses and universities in Japan and abroad, as well as government agencies and other organizations.” It advertises launches from 42 degrees to 98 degrees, including Sun-synchronous orbits.
Talks are exploratory for now … “We look forward to exploring the opportunity to launch our Alpha rocket from Japan, which would allow us to serve the larger satellite industry in Asia and add resiliency for US allies with a proven orbital launch vehicle,” said Adam Oakes, vice president of launch at Firefly Aerospace. All six of Firefly Aerospace’s Alpha rocket launches so far took off from Space Launch Complex 2 at Vandenberg Space Force Base in California. The company is slated to launch its seventh Alpha rocket on a mission for Lockheed Martin, but a date hasn’t been announced while the company continues to work through a mishap investigation stemming from its sixth Alpha launch in April. (submitted by EllPeaTea)
Chinese methane rocket fails. A flight test of one of Chinese commercial rocket developer LandSpace Technology’s methane-powered rockets failed on Friday after the carrier rocket experienced an “anomaly,” Reuters reports. The Beijing-based startup became the world’s first company to launch a methane-liquid oxygen rocket with the successful launch of Zhuque-2 in July 2023. This was the third flight of an upgraded version of the rocket, known as Zhuque-2E Y2.
Comes as larger vehicle set to make debut … The launch was carrying four Guowang low-Earth orbit Internet satellites for the Chinese government. The failure was due to some issue with the upper stage of the vehicle, which is capable of lofting about 3 metric tons to low-Earth orbit. LandSpace, one of China’s most impressive ‘commercial’ space companies, has been working toward the development and launch of the medium-lift Zhuque-3 vehicle. This rocket was due to make its debut later this year, and it’s not clear whether this setback with a smaller vehicle will delay that flight.
The easiest way to keep up with Eric Berger’s and Stephen Clark’s reporting on all things space is to sign up for our newsletter. We’ll collect their stories and deliver them straight to your inbox.
Avio gains French Guiana launch license. The French government has granted Italian launch services provider Avio a 10-year license to carry out Vega rocket operations from the Guiana Space Centre in French Guiana, European Spaceflight reports. The decision follows approval by European Space Agency Member States of Italy’s petition to allow Avio to market and manage Vega rocket launches independently of Arianespace, which had overseen the rocket’s operations since its introduction.
From Vega to Vega … With its formal split from Arianespace now imminent, Avio is required to have its own license to launch from the Guiana Space Centre, which is owned and operated by the French government. Avio will make use of the ELV launch complex at the Guiana Space Centre for the launch of its Vega C rockets. The pad was previously used for the original Vega rocket, which was officially retired in September 2024. (submitted by EllPeaTea)
First space rocket launch from Canada this century. Students from Concordia University cheered and whistled as the Starsailor rocket lifted off on Cree territory on August 15, marking the first of its size to be launched by a student team, Radio Canada International reports. The students hoped Starsailor would enter space, past the Kármán line, which is at an altitude of 100 kilometers, before coming back down. But the rocket separated earlier than expected. The livestream can be seen here.
Persistence is thy name … This was Canada’s first space launch in more than 25 years, and the first to be achieved by a team of students, according to the university. Originally built for a science competition, the 13-meter tall rocket was left without a contest after the event was cancelled due to the COVID-19 pandemic. Nevertheless, the team, made up of over 700 members since 2018, pressed forward with the goal of making history and launching the most powerful student-built rocket. (submitted by ArcticChris, durenthal, and CD)
SpaceX launches its 100th Falcon 9 of the year. SpaceX launched its 100th Falcon 9 rocket of the year Monday morning, Spaceflight Now reports. The flight from Vandenberg Space Force Base carried another batch of Starlink optimized V2 Mini satellites into low-Earth orbit. The Starlink 17-5 mission was also the 72nd SpaceX launch of Starlink satellites so far in 2025. It brings the total number of Starlink satellites orbited in 2025 to 1,786.
That’s quite a cadence … The Monday morning flight was a notable milestone for SpaceX. It is just the second time in the company’s history that it achieved 100 launches in one calendar year, a feat so far unmatched by any other American space company, and it is ahead of last year’s pace. Kiko Dontchev, SpaceX’s vice president of launch, said on the social media site X, “For reference on the increase in launch rate from last year, we hit 100 on Oct 20th in 2024. SpaceX is likely to launch more Falcon 9s this year than the total number of Space Shuttle missions NASA flew in three decades. (submitted by EllPeaTea)
X-37B launch set for Thursday night. The US Department of Defense’s reusable X-37B Orbital Test Vehicle is about to make its eighth overall flight into orbit, NASASpaceflight.com reports. Vehicle 1, the first X-37B to fly, is scheduled to launch atop a SpaceX Falcon 9 from the Kennedy Space Center’s Launch Complex 39A on Thursday at 11: 50 pm ET (03: 50 UTC on Friday, August 22). The launch window is just under four hours long.
Will fly for an unspecified amount of time … Falcon 9 will follow a northeast trajectory to loft the X-37B into a low-Earth orbit, possibly a circular orbit at 500 km altitude inclined 49.5 degrees to the equator. The Orbital Test Vehicle 8 mission will spend an unspecified amount of time in orbit, with missions lasting hundreds of days in orbit before landing on a runway. The booster supporting this mission, B1092-6, will perform a return-to-launch-site landing and touchdown on the concrete pad at Landing Zone 2. (submitted by EllPeaTea)
Report finds SpaceX pays few taxes. SpaceX has received billions of dollars in federal contracts over its more than two-decade existence, but it has most likely paid little to no federal income taxes since its founding in 2002, The New York Times reports. The rocket maker’s finances have long been secret because the company is privately held. But the documents reviewed by the Times show that SpaceX can seize on a legal tax benefit that allows it to use the more than $5 billion in losses it racked up by late 2021 to offset paying future taxable income.
Use of tax benefit called ‘quaint’ … Danielle Brian, the executive director of the Project on Government Oversight, a group that investigates corruption and waste in the government, said the tax benefit had historically been aimed at encouraging companies to stay in business during difficult times. It was “quaint” that SpaceX was using it, she said, as it “was clearly not intended for a company doing so well.” It may be quaint, but it is legal. And the losses are very real. Since its inception, SpaceX has invested heavily in its technology and poured revenues into further advances. This has been incredibly beneficial to NASA and the Department of Defense. (submitted by Frank OBrien)
There’s a lot on the line for Starship’s next launch. In a feature, Ars reviews the history of Starbase and its production site, culminating in the massive new Starfactory building that encompasses 1 million square feet. The opening of the sleek, large building earlier this year came as SpaceX continues to struggle with the technical development of the Starship vehicle. Essentially, the article says, SpaceX has built the machine to build the machine. But what about the machine?
Three failures in a row … SpaceX has not had a good run of things with the ambitious Starship vehicle this year. Three times, in January, March, and May, the vehicle took flight. And three times, the upper stage experienced significant problems during ascent, and the vehicle was lost on the ride up to space, or just after. Sources at SpaceX believe the upper stage issues can be resolved, especially with a new “Version 3” of Starship due to make its debut late this year or early in 2026. But the acid test will only come on upcoming flights, beginning Sunday with the vehicle’s tenth test flight.
China tests lunar rocket. In recent weeks, the secretive Chinese space program has reported some significant milestones in developing its program to land astronauts on the lunar surface by the year 2030, Ars reports. Among these efforts, last Friday, the space agency and its state-operated rocket developer, the China Academy of Launch Vehicle Technology, successfully conducted a 30-second test firing of the Long March 10 rocket’s center core with its seven YF-100K engines that burn kerosene and liquid oxygen.
A winner in the space race? … The primary variant of the rocket will combine three of these cores to lift about 70 metric tons to low-Earth orbit. As part of China’s plan to land astronauts on the Moon “before” 2030, this rocket will be used for a crewed mission and lunar lander. Recent setbacks with SpaceX’s Starship vehicle—one of two lunar landers under contract with NASA, alongside Blue Origin’s Mark 2 lander—indicate that it will still be several years until these newer technologies are ready to go. Ars concludes that it is now probable that China will “beat” NASA back to the Moon this decade and win at least the initial heat of this new space race.
Why did Flight 9 of Starship fail? In an update shared last Friday ahead of the company’s next launch, SpaceX identified the most probable cause for the May failure as a faulty main fuel tank pressurization system diffuser located on the forward dome of Starship’s primary methane tank. The diffuser failed a few minutes after launch, when sensors detected a pressure drop in the main methane tank and a pressure increase in the ship’s nose cone just above the tank, Ars reports.
Diffusing the diffuser … The rocket compensated for the drop in main tank pressure and completed its engine burn, but venting from the nose cone and a worsening fuel leak overwhelmed Starship’s attitude control system. Finally, detecting a major problem, Starship triggered automatic onboard commands to vent all remaining propellant into space and “passivate” itself before an unguided reentry over the Indian Ocean, prematurely ending the test flight. Engineers recreated the diffuser failure on the ground during the investigation and then redesigned the part to better direct pressurized gas into the main fuel tank. This will also “substantially decrease” strain on the diffuser structure, SpaceX said.
Next three launches
August 22: Falcon 9 | X-37B space plane | Kennedy Space Center, Fla. | 03: 50 UTC
August 22: Falcon 9 | Starlink 17-6 | Vandenberg Space Force Base, Calif. | 17: 02 UTC
August 23: Electron | Live, Laugh, Launch | Māhia Peninsula, New Zealand | 22: 30 UTC
Eric Berger is the senior space editor at Ars Technica, covering everything from astronomy to private space to NASA policy, and author of two books: Liftoff, about the rise of SpaceX; and Reentry, on the development of the Falcon 9 rocket and Dragon. A certified meteorologist, Eric lives in Houston.
The primary dissent was written by Chief Justice Roberts, and joined in part by the three Democratic appointees, Jackson, Kagan, and Sotomayor. It is a grand total of one paragraph and can be distilled down to a single sentence: “If the District Court had jurisdiction to vacate the directives, it also had jurisdiction to vacate the ‘Resulting Grant Terminations.’”
Jackson, however, chose to write a separate and far more detailed argument against the decision, mostly focusing on the fact that it’s not simply a matter of abstract law; it has real-world consequences.
She notes that existing law prevents plaintiffs from suing in the Court of Federal Claims while the facts are under dispute in other courts (something acknowledged by Barrett). That would mean that, as here, any plaintiffs would have to have the policy declared illegal first in the District Court, and only after that was fully resolved could they turn to the Federal Claims Court to try to restore their grants. That’s a process that could take years. In the meantime, the scientists would be out of funding, with dire consequences.
Yearslong studies will lose validity. Animal subjects will be euthanized. Life-saving medication trials will be abandoned. Countless researchers will lose their jobs. And community health clinics will close.
Jackson also had little interest in hearing that the government would be harmed by paying out the grants in the meantime. “For the Government, the incremental expenditure of money is at stake,” she wrote. “For the plaintiffs and the public, scientific progress itself hangs in the balance along with the lives that progress saves.”
With this decision, of course, it no longer hangs in the balance. There’s a possibility that the District Court’s ruling that the government’s policy was arbitrary and capricious will ultimately prevail; it’s not clear, because Barrett says she hasn’t even seen the government make arguments there, and Roberts only wrote regarding the venue issues. In the meantime, even with the policy stayed, it’s unlikely that anyone will focus grant proposals on the disfavored subjects, given that the policy might be reinstated at any moment.
And even if that ruling is upheld, it will likely take years to get there, and only then could a separate case be started to restore the funding. Any labs that had been using those grants will have long since moved on, and the people working on those projects scattered.
A local Neolithic community in northeastern France may have clashed with foreign invaders, cutting off limbs as war trophies and otherwise brutalizing their prisoners of war, according to a new paper published in the journal Science Advances. The findings challenge conventional interpretations of prehistoric violence as bring indiscriminate or committed for pragmatic reasons.
Neolithic Europe was no stranger to collective violence of many forms, such as the odd execution and massacres of small communities, as well as armed conflicts. For instance, we recently reported on an analysis of human remains from 11 individuals recovered from El Mirador Cave in Spain, showing evidence of cannibalism—likely the result of a violent episode between competing Late Neolithic herding communities about 5,700 years ago. Microscopy analysis revealed telltale slice marks, scrape marks, and chop marks, as well as evidence of cremation, peeling, fractures, and human tooth marks.
This indicates the victims were skinned, the flesh removed, the bodies disarticulated, and then cooked and eaten. Isotope analysis indicated the individuals were local and were probably eaten over the course of just a few days. There have been similar Neolithic massacres in Germany and Spain, but the El Mirador remains provide evidence of a rare systematic consumption of victims.
Per the authors of this latest study, during the late Middle Neolithic, the Upper Rhine Valley was the likely site of both armed conflict and rapid cultural upheaval, as groups from the Paris Basin infiltrated the region between 4295 and 4165 BCE. In addition to fortifications and evidence of large aggregated settlements, many skeletal remains from this period show signs of violence.
Friends or foes?
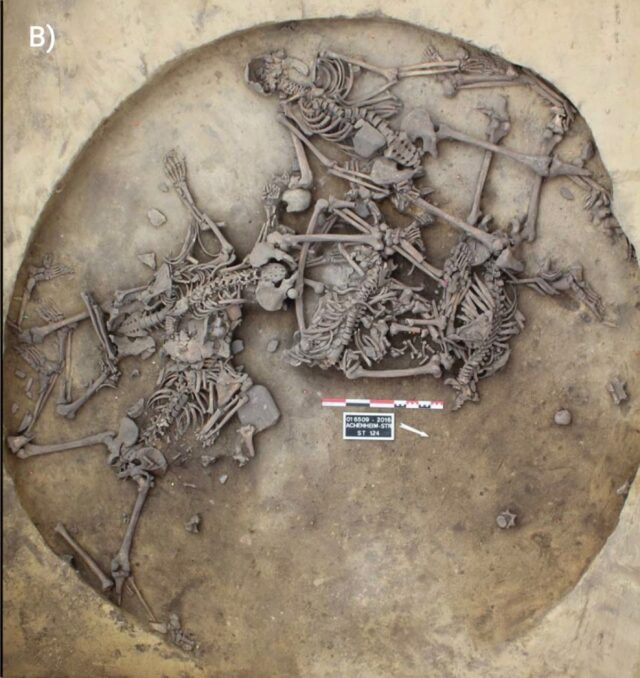
Overhead views of late Middle Neolithic violence-related human mass deposits in Pit 124 of the Alsace region, France. Credit: Philippe Lefranc, INRAP
Archaeologist Teresa Fernandez-Crespo of Spain’s Valladolid University and co-authors focused their analysis on human remains excavated from two circular pits at the Achenheim and Bergheim sites in Alsace in northwestern France. Fernandez-Crespo et al. examined the bones and found that many of the remains showed signs of unhealed trauma—such as skull fractures—as well as the use of excessive violence (overkill), not to mention quite a few severed left upper limbs. Other skeletons did not show signs of trauma and appeared to have been given a traditional burial.
Seven-figure EV hypercars are struggling to make an emotional connection with buyers.
Monterey Car Week is an annual celebration of automotive culture at the extremes: extreme performance, extreme rarity, and extreme value. Cars offering more than 1,000 hp (746 kW) are de rigueur, “unique” models are everywhere you look, and machines costing well into seven figures are entry-level.
A few years ago, many of the new cars debuting during Car Week focused on outright speed and performance above all else, relying on electric powertrains to deliver physics-defying acceleration and ballistic speed. Lately, there’s been a shift back toward the fundamentals of driver engagement, emotional design, and purity of feel.
Internal combustion is again at the fore. One of the main reasons is a renewed interest in what was old—so long as that old thing is actually new.
They’re called restomods, classic cars brought up to date with modern drivability but keeping the original feel. LA-based Singer Vehicle Design is the Porsche-based poster child for this movement, but San Marino-based Eccentrica earned plenty of attention in Monterey for its reimagining of one of the ultimate icons of the ’90s, the Lamborghini Diablo.
This is Eccentrica’s restomod of the Lamborghini Diablo. Tim Stevens
The company’s latest creation, Titano, promises “Raw ’90s soul meet[ing] purposeful modern craft.”
Maurizio Reggiani, former Lamborghini CTO and now advisor to Eccentrica, told me that feel is far more important than outright performance in this segment. “We want the people sitting in Eccentrica to really perceive the street, perceive the acceleration, perceive the braking, perceive the steering,” he said.
Commoditization
“The power to have 1,000 hp is easy. I don’t want to say it is a commodity, but more or less,” Reggiani continued.
Eccentrica’s Titano makes 550 hp (410 kW). The machine Bugatti unveiled, the new Brouillard, nearly tripled that number, offering 1,578 hp (1,177 kW) from an 8.3-liter W16 engine paired with a hybrid system. It’s a one-off, a completely bespoke design created at the request of one very lucky, very well-heeled buyer, part of the company’s new Programme Solitaire.
That’s an impressive figure, but Frank Heyl, Bugatti’s director of design, told me the real focus is on creating something timeless. Bugatti has been making cars for 101 years, and today’s astonishing power figures won’t matter in 2126. Instead, Heyl said to focus on the interior. “If you look at the Tourbillon instrument cluster, it’s a titanium housing with real sapphire glass. The bearings are made from ruby stones with aluminum needles,” he said. “People will have a fascination with that in 100 years’ time. I’m sure about that.”
This is the Bugatti Solitaire. Bugatti
For its part, modern Lamborghini seems much happier to focus on the best of the modern era, taking advantage of EV-derived technology paired with an internal combustion engine tasked with providing both power and adrenaline.
Lamborghini unveiled the Fenomeno, a “few-off” version of the Revuelto offered to just 29 buyers. Lamborghini’s current CTO, Rouven Mohr, told me this wasn’t just a reskinning. The company’s engineers re-did the car’s tech stack, including its battery pack, adopting lessons learned from the latest EVs. “Completely new battery hardware. New cell chemistry, new cell type,” he said. “So we double the energy content in the same space.”
It’s similar to what’s in the Temerario, which features a hybrid system paired with a high-strung V8. “This huge effort that we did to have a 10,000-rpm engine is, at the end of the day, engineering overkill,” he said. “It’s a pure investment in the emotional side.”
Lamborghini designer Mitja Borkert said this kind of hybrid tech can actually make the cars more likeable. “Our cars are polarizing; they are creating reactions,” he said, admitting those reactions are sometimes negative. “But if you drive a Revuelto in electric mode, the people can enjoy the design better because it’s unexpected that this spaceship is coming around the corner.”
When it comes to exterior design, Karma is one brand that has always stood out. But its cars, extended-range EVs with onboard generators, have historically struggled to perfect the needed mix of emotionality and electrification. A fix is on the way, CEO Marques McCammon told me. The company’s Amaris coupe, coming next year for roughly $200,000, generates 708 hp (528 kW) from a pair of electric motors, plus a new onboard engine designed to thrill, not just recharge a battery.
“I’ve got side exhaust. It’s real. There’s no synthetic sound. When you hit the throttle, you’re gonna hear a blow-off valve on the turbo, and you’re gonna hear exhaust coming out of the side pipes that we’ve tuned,” he said. “You can have it all.”
You need to hear it
For many, authentic sound is key to the experience. Eccentrica’s Reggiani told me that the synthesized noises emitted by cars like Hyundai’s Ioniq 5 N are not a solution. Reggiani said an EV can never provide a truly emotional experience with sound “because you need to do something fake.”
But Iliya and Nikita Bridan, who run Oilstainlab, might have devised a solution with their $1.8-million-dollar HF-11: a cooling fan for the electric motor run through a ducted exhaust.
That fan exhaust is being tuned and tweaked to create an evocative sound, a process that Nikita Bridan says is no less authentic than tuning the exhaust of a car with an internal combustion engine. Indeed, with many modern sports cars featuring digitally generated pops and crackles in Sport mode, the HF-11’s acoustic affect might be even more authentic.
That’s just part of what Bridan says should be a compelling package, even for anti-EV zealots. “What we’re promising is basically a 2,000 pound, six-speed manual EV with an exhaust. I think that’s interesting enough for people to maybe abandon combustion,” he said.
And the HF-11 has another trick up its sleeve: an air-cooled, flat-six engine (àla classic Porsches), which owners can swap in if they’re feeling old-school. It’s a unique solution to the challenges of shifting consumer demand. So far, about 30 percent of the buyers of the HF-11 are exclusively interested in the electric powertrain. Thirty percent want only internal combustion, while the rest want both.
The Czinger 21C doesn’t have a swappable powertrain, but it mixes electric and internal combustion to deliver outright performance. Very extreme performance, as it were, with the 1,250-hp (932-kW), $2 million (and up) hybrid hypercar taking an extended, 1,000-mile road trip on the way to Monterey, setting five separate track records along the way.
That car’s hallmark is the intricate 3D-printed structure beneath the skin, but despite the space-age tech, CEO Lukas Czinger told me that emotionality is key.
The Czinger C21 features tandem seating. Credit: Czinger
Buyer motivation
“Why would you buy a $3 million car? Well, you’re buying it because you appreciate the brand and the engineering level, and there’s new technology in it, right?” Czinger said. “But the product ultimately needs to be thrilling to drive.”
Czinger said the combination of a hybrid system and an 11,000 RPM twin-turbo V8 offers “the best of both worlds” and that an eventual 21C successor will “definitely have a combustion engine.”
For Automobili Pininfarina, an all-electric powertrain was not a concern for its first car, the $2.5-million, 1,900-hp (1,417-kW) Battista. That’s despite some initial skepticism that, CEO Paolo Dellachà said, evaporates as soon as a potential buyer gets behind the wheel.
But most didn’t need convincing. “All our or our clients do have eight-cylinder, 12-cylinder, or even 16-cylinder engines,” he said. “This is just something additional to their collection. So it’s not one or the other to them. Eventually, it’s both.”
All-electric hypercars like the Battista are a hard sell in 2025. Credit: Automobil Pininfarina
Residuals matter
It’s easy to think that the buyers of these cars simply have bottomless discretionary funds, and many do. But unproven long-term value is a key reason why these battery-powered projectiles seem a little less common than they used to be.
“At the moment, no one has proven yet that the electric super sports car is holding the financial index,” Lamborghini CTO Mohr said. “And the people who are usually investing in this, buying this kind of car, usually they have the money because they are quite financially oriented. They don’t want to destroy their investment.”
In other words, it’s all fun and games until someone loses money. If electric hypercars can’t prove their value in the long run, they don’t have a chance.
This is something that Automobili Pininfarina CEO Dellachà is certainly watching, but he doesn’t seem concerned. “It’s very difficult to say right now because none of our clients yet have sold their car,” he said. “And this is something that, by the way, makes us very proud, because they love the car, they love driving it, or they love keeping in their collection.”
That said, he’s not yet committing to an EV drivetrain for an eventual Battista successor. “Maybe next time we might combine electrification with a combustion engine. We will see. It will be an interesting time to come.”
Town pitches companies to take advantage of “reliable, cost-effective heating and cooling.”
This article originally appeared on Inside Climate News, a nonprofit, non-partisan news organization that covers climate, energy, and the environment. Sign up for their newsletter here.
When town leaders in the community just west of Steamboat Springs decided to create a new business park, harnessing geothermal energy to heat and cool the buildings simply made sense.
The technology aligns with Colorado’s sustainability goals and provides access to grants and tax credits that make the project financially feasible for a town with around 2,000 residents, said Matthew Mendisco, town manager.
“We’re creating the infrastructure to attract employers, support local jobs, and give our community reliable, cost-effective heating and cooling for decades to come,” Mendisco said in a statement.
Bedrock Energy, a geothermal drilling startup company that employs advanced drilling techniques developed by the oil and gas industry, is currently drilling dozens of boreholes that will help heat and cool the town’s Northwest Colorado Business District.
The 1,000-feet-deep boreholes or wells will connect buildings in the industrial park to steady underground temperatures. Near the surface the Earth is approximately 51° F year round. As the drills go deeper, the temperature slowly increases to approximately 64° F near the bottom of the boreholes. Pipes looping down into each well will draw on this thermal energy for heating in the winter and cooling in the summer, significantly reducing energy needs.
Ground source heat pumps located in each building will provide additional heating or cooling depending on the time of year.
The project, one of the first in the region, drew the interest of some of the state’s top political leaders, who attended an open house hosted by town officials and company executives on Wednesday.
“Our energy future is happening right now—right here in Hayden,” US Senator John Hickenlooper (D-Colo.) said in a prepared statement prior to the event.
“Projects like this will drive rural economic growth while harnessing naturally occurring energy to provide reliable, cost-effective heating and cooling to local businesses,” said US Senator Michael Bennet (D-Colo.) in a written statement.
In an interview with Inside Climate News, Mendisco said that extreme weather snaps, which are not uncommon in a town over 6,000 feet above sea level, will not force companies to pay higher prices for fossil fuels to meet energy demands, like they do elsewhere in the country. He added that the system’s rates will be “fairly sustainable, and they will be as competitive as any of our other providers, natural gas, etcetera.”
The geothermal system under construction for Hayden’s business district will be owned by the town and will initially consist of separate systems for each building that will be connected into a larger network over time. Building out the network as the business park grows will help reduce initial capital costs.
“It wasn’t completely clear to us how much interest was really going to be out there,” Will Toor, executive director of the Colorado Energy Office, said of a grant program the state launched in 2022.
In the past few years, the program has seen significant interest, with approximately 80 communities across the state exploring similar projects, said Bryce Carter, the geothermal program manager for the state’s Energy Office.
Two projects under development are by Xcel Energy, the largest electricity and gas provider in the state. A law passed in Colorado in 2023 required large gas utilities to develop at least one geothermal heating and cooling network in the state. The networks, which connect individual buildings and boreholes into a shared thermal loop, offer high efficiency and an economy of scale, but also have high upfront construction costs.
There are now 26 utility-led geothermal heating and cooling projects under development or completed nationwide, Jessica Silber-Byrne of the Building Decarbonization Coalition, a nonprofit based in Delaware, said.
Utility companies are widely seen as a natural developer of such projects as they can shoulder multi-million dollar expenses and recoup those costs in ratepayer fees over time. The first, and so far only, geothermal network completed by a gas utility was built by Eversource Energy in Framingham, Massachusetts, last year.
Grid stress concerns heat up geothermal opportunities
Twelve states have legislation supporting or requiring the development of thermal heating and cooling networks. Regulators are interested in the technology because its high efficiency can reduce demand on electricity grids.
Geothermal heating and cooling is roughly twice as efficient as air source heat pumps, a common electric heating and cooling alternative that relies on outdoor air. During periods of extreme heat or extreme cold, air source heat pumps have to work harder, requiring approximately four times more electricity than ground source heat pumps.
As more power-hungry data centers come online, the ability of geothermal heating and cooling to reduce the energy needs of other users of the grid, particularly at periods of peak demand, could become increasingly important, geothermal proponents say.
“The most urgent conversation about energy right now is the stress on the grid,” Joselyn Lai, Bedrock Energy’s CEO, said. “Geothermal’s role in the energy ecosystem will actually increase because of the concerns about meeting load growth.”
The geothermal system will be one of the larger drilling projects to date for Bedrock, a company founded in Austin, Texas, in 2022. Bedrock, which is working on another similarly sized project in Crested Butte, Colorado, seeks to reduce the cost of relatively shallow-depth geothermal drilling through the use of robotics and data analytics that rely on artificial intelligence.
By using a single, continuous steel pipe for drilling, rather than dozens of shorter pipe segments that need to be attached as they go, Bedrock can drill faster and transmit data more easily from sensors near the drill head to the surface.
In addition to shallow, low-temperature geothermal heating and cooling networks, deep, hot-rock geothermal systems that generate steam for electricity production are also seeing increased interest. New, enhanced geothermal systems that draw on hydraulic fracturing techniques developed by the oil and gas industry and other advanced drilling methods are quickly expanding geothermal energy’s potential.
“We’re also very bullish on geothermal electricity,” said Toor, of the Colorado Energy Office, adding that the state has a goal of reducing carbon emissions from the electricity sector by 80 percent by 2030. He said geothermal power that produces clean, round-the-clock electricity will likely play a key role in meeting that target.
For town officials in Hayden, the technology’s appeal is simple.
“Geothermal works at night, it works in the day, it works whenever you want it to work,” Mendisco said. “It doesn’t matter if there’s a giant snowstorm [or] a giant rainstorm. Five hundred feet to 1,000 feet below the surface, the Earth doesn’t care. It just generates heat.”
“This is a strategy to keep the US from intervening… that’s what their space architecture is designed to do.”
Spectators take photos as a Long March 8A rocket carrying a group of Guowang satellites blasts off from the Hainan commercial launch site on July 30, 2025, in Wenchang, China. Credit: Liu Guoxing/VCG via Getty Images
Spectators take photos as a Long March 8A rocket carrying a group of Guowang satellites blasts off from the Hainan commercial launch site on July 30, 2025, in Wenchang, China. Credit: Liu Guoxing/VCG via Getty Images
US defense officials have long worried that China’s Guowang satellite network might give the Chinese military access to the kind of ubiquitous connectivity US forces now enjoy with SpaceX’s Starlink network.
It turns out the Guowang constellation could offer a lot more than a homemade Chinese alternative to Starlink’s high-speed consumer-grade broadband service. China has disclosed little information about the Guowang network, but there’s mounting evidence that the satellites may provide Chinese military forces a tactical edge in any future armed conflict in the Western Pacific.
The megaconstellation is managed by a secretive company called China SatNet, which was established by the Chinese government in 2021. SatNet has released little information since its formation, and the group doesn’t have a website. Chinese officials have not detailed any of the satellites’ capabilities or signaled any intention to market the services to consumers.
Another Chinese satellite megaconstellation in the works, called Qianfan, appears to be a closer analog to SpaceX’s commercial Starlink service. Qianfan satellites are flat in shape, making them easier to pack onto the tops of rockets before launch. This is a design approach pioneered by SpaceX with Starlink. The backers of the Qianfan network began launching the first of up to 1,300 broadband satellites last year.
Unlike Starlink, the Guowang network consists of satellites manufactured by multiple companies, and they launch on several types of rockets. On its face, the architecture taking shape in low-Earth orbit appears to be more akin to SpaceX’s military-grade Starshield satellites and the Space Development Agency’s future tranches of data relay and missile-tracking satellites.
Guowang, or “national network,” may also bear similarities to something the US military calls MILNET. Proposed in the Trump administration’s budget request for next year, MILNET will be a partnership between the Space Force and the National Reconnaissance Office (NRO). One of the design alternatives under review at the Pentagon is to use SpaceX’s Starshield satellites to create a “hybrid mesh network” that the military can rely on for a wide range of applications.
Picking up the pace
In recent weeks, China’s pace of launching Guowang satellites has approached that of Starlink. China has launched five groups of Guowang satellites since July 27, while SpaceX has launched six Starlink missions using its Falcon 9 rockets over the same period.
A single Falcon 9 launch can haul up to 28 Starlink satellites into low-Earth orbit, while China’s rockets have launched between five and 10 Guowang satellites per flight to altitudes three to four times higher. China has now placed 72 Guowang satellites into orbit since launches began last December, a small fraction of the 12,992-satellite fleet China has outlined in filings with the International Telecommunication Union.
The constellation described in China’s ITU filings will include one group of Guowang satellites between 500 and 600 kilometers (311 and 373 miles), around the same altitude of Starlink. Another shell of Guowang satellites will fly roughly 1,145 kilometers (711 miles) above the Earth. So far, all of the Guowang satellites China has launched since last year appear to be heading for the higher shell.
This higher altitude limits the number of Guowang satellites China’s stable of launch vehicles can carry. On the other hand, fewer satellites are required for global coverage from the higher orbit.
A prototype Guowang satellite is seen prepared for encapsulation inside the nose cone of a Long March 12 rocket last year. This is one of the only views of a Guowang spacecraft China has publicly released. Credit: Hainan International Commercial Aerospace Launch Company Ltd.
SpaceX has already launched nearly 200 of its own Starshield satellites for the NRO to use for intelligence, surveillance, and reconnaissance missions. The next step, whether it’s the SDA constellation, MILNET, or something else, will seek to incorporate hundreds or thousands of low-Earth orbit satellites into real-time combat operations—things like tracking moving targets on the ground and in the air, targeting enemy vehicles, and relaying commands between allied forces. The Trump administration’s Golden Dome missile defense shield aims to extend real-time targeting to objects in the space domain.
In military jargon, the interconnected links to detect, track, target, and strike a target is called a kill chain or kill web. This is what US Space Force officials are pushing to develop with the Space Development Agency, MILNET, and other future space-based networks.
So where is the US military in building out this kill chain? The military has long had the ability to detect and track an adversary’s activities from space. Spy satellites have orbited the Earth since the dawn of the Space Age.
Much of the rest of the kill chain—like targeting and striking—remains forward work for the Defense Department. Many of the Pentagon’s existing capabilities are classified, but simply put, the multibillion-dollar satellite constellations the Space Force is building just for these purposes still haven’t made it to the launch pad. In some cases, they haven’t made it out of the lab.
Is space really the place?
The Space Development Agency is supposed to begin launching its first generation of more than 150 satellites later this year. These will put the Pentagon in a position to detect smaller, fainter ballistic and hypersonic missiles and provide targeting data for allied interceptors on the ground or at sea.
Space Force officials envision a network of satellites that can essentially control a terrestrial battlefield from orbit. The way future-minded commanders tell it, a fleet of thousands of satellites fitted with exquisite sensors and machine learning will first detect a moving target, whether it’s a land vehicle, aircraft, naval ship, or missile. Then, that spacecraft will transmit targeting data via a laser link to another satellite that can relay the information to a shooter on Earth.
US officials believe Guowang is a step toward integrating satellites into China’s own kill web. It might be easier for them to dismiss Guowang if it were simply a Chinese version of Starlink, but open-source information suggests it’s something more. Perhaps Guowang is more akin to megaconstellations being developed and deployed for the US Space Force and the National Reconnaissance Office.
If this is the case, China could have a head start on completing all the links for a celestial kill chain. The NRO’s Starshield satellites in space today are presumably focused on collecting intelligence. The Space Force’s megaconstellation of missile tracking, data relay, and command and control satellites is not yet in orbit.
Chinese media reports suggest the Guowang satellites could accommodate a range of instrumentation, including broadband communications payloads, laser communications terminals, synthetic aperture radars, and optical remote sensing payloads. This sounds a lot like a mix of SpaceX and the NRO’s Starshield fleet, the Space Development Agency’s future constellation, and the proposed MILNET program.
A Long March 5B rocket lifts off from the Wenchang Space Launch Site in China’s Hainan Province on August 13, 2025, with a group of Guowang satellites. (Photo by Luo Yunfei/China News Service/VCG via Getty Images.) Credit: Luo Yunfei/China News Service/VCG via Getty Images
In testimony before a Senate committee in June, the top general in the US Space Force said it is “worrisome” that China is moving in this direction. Gen. Chance Saltzman, the Chief of Space Operations, used China’s emergence as an argument for developing space weapons, euphemistically called “counter-space capabilities.”
“The space-enabled targeting that they’ve been able to achieve from space has increased the range and accuracy of their weapon systems to the point where getting anywhere close enough [to China] in the Western Pacific to be able to achieve military objectives is in jeopardy if we can’t deny, disrupt, degrade that… capability,” Saltzman said. “That’s the most pressing challenge, and that means the Space Force needs the space control counter-space capabilities in order to deny that kill web.”
The US military’s push to migrate many wartime responsibilities to space is not without controversy. The Trump administration wants to cancel purchases of new E-7 jets designed to serve as nerve centers in the sky, where Air Force operators receive signals about what’s happening in the air, on the ground, and in the water for hundreds of miles around. Instead, much of this responsibility would be transferred to satellites.
Some retired military officials, along with some lawmakers, argue against canceling the E-7. They say there’s too little confidence in when satellites will be ready to take over. If the Air Force goes ahead with the plan to cancel the E-7, the service intends to bridge the gap by extending the life of a fleet of Cold War-era E-3 Sentry airplanes, commonly known as AWACS (Airborne Warning and Control System).
But the high ground of space offers notable benefits. First, a proliferated network of satellites has global reach, and airplanes don’t. Second, satellites could do the job on their own, with some help from artificial intelligence and edge computing. This would remove humans from the line of fire. And finally, using a large number of satellites is inherently beneficial because it means an attack on one or several satellites won’t degrade US military capabilities.
In China, it takes a village
Brig. Gen. Anthony Mastalir, commander of US Space Forces in the Indo-Pacific region, told Ars last year that US officials are watching to see how China integrates satellite networks like Guowang into military exercises.
“What I find interesting is China continues to copy the US playbook,” Mastalir said. “So as as you look at the success that the United States has had with proliferated architectures, immediately now we see China building their own proliferated architecture, not just the transport layer and the comm layer, but the sensor layer as well. You look at their their pursuit of reusability in terms of increasing their launch capacity, which is currently probably one of their shortfalls. They have plans for a quicker launch tempo.”
A Long March 6A carries a group of Guowang satellites into orbit on July 27, 2025, from the Taiyuan Satellite Launch Center in north China’s Shanxi Province. China has used four different rocket configurations to place five groups of Guowang satellites into orbit in the last month. Credit: Wang Yapeng/Xinhua via Getty Images
China hasn’t recovered or reused an orbital-class booster yet, but several Chinese companies are working on it. SpaceX, meanwhile, continues to recycle its fleet of Falcon 9 boosters while simultaneously developing a massive super-heavy-lift rocket and churning out dozens of Starlink and Starshield satellites every week.
China doesn’t have its own version of SpaceX. In China, it’s taken numerous commercial and government-backed enterprises to reach a launch cadence that, so far this year, is a little less than half that of SpaceX. But the flurry of Guowang launches in the last few weeks shows that China’s satellite and rocket factories are picking up the pace.
Mastalir said China’s actions in the South China Sea, where it has taken claim of disputed islands near Taiwan and the Philippines, could extend farther from Chinese shores with the help of space-based military capabilities.
“Their specific goals are to be able to track and target US high-value assets at the time and place of their choosing,” he said. “That has started with an A2AD, an Anti-Access Area Denial strategy, which is extended to the first island chain and now the second island chain, and eventually all the way to the west coast of California.”
“The sensor capabilities that they’ll need are multi-orbital and diverse in terms of having sensors at GEO (geosynchronous orbit) and now increasingly massive megaconstellations at LEO (low-Earth orbit),” Mastalir said. “So we’re seeing all signs point to being able to target US aircraft carriers… high-value assets in the air like tankers, AWACs. This is a strategy to keep the US from intervening, and that’s what their space architecture is designed to do.”
Stephen Clark is a space reporter at Ars Technica, covering private space companies and the world’s space agencies. Stephen writes about the nexus of technology, science, policy, and business on and off the planet.
A large measles outbreak in Texas that has affected 762 people has now ended, according to an announcement Monday by the Texas Department of State Health Services. The agency says it has been more than 42 days since a new case was reported in any of the counties that previously showed evidence of ongoing transmission.
The outbreak has contributed to the worst year for measles cases in the United States in more than 30 years. As of August 5, the most recent update from the Centers for Disease Control and Prevention, a total of 1,356 confirmed measles cases have been reported across the country this year. For comparison, there were just 285 measles cases in 2024.
The Texas outbreak began in January in a rural Mennonite community with low vaccination rates. More than two-thirds of the state’s reported cases were in children, and two children in Texas died of the virus. Both were unvaccinated and had no known underlying conditions. Over the course of the outbreak, a total of 99 people were hospitalized, representing 13 percent of cases.
Measles is a highly contagious respiratory illness that can temporarily weaken the immune system, leaving individuals vulnerable to secondary infections such as pneumonia. In rare cases, it can also lead to swelling of the brain and long-term neurological damage. It can also cause pregnancy complications, such as premature birth and babies with low birth weight. The best way to prevent the disease is the measles, mumps, and rubella (MMR) vaccine. One dose of the vaccine is 93 percent effective against measles while two doses is 97 percent effective.