Enlarge/ Robert Wickens looks out from the cockpit of the Formula E GenBeta test car in Portland, Oregon.
Formula E
PORTLAND, Ore.—The timing of Robert Wickens’ life-altering crash at Pocono Raceway in 2018 could hardly have been more cruel. After landing a full-time seat in IndyCar, he was named rookie of the year at the Indy 500 in June, finally showing the world his talent in a single-seat race car. F1’s loss was IndyCar’s gain, and the prospect of championships seemed certain. But a bad wreck derailed all of that, leaving Wickens paralyzed from the waist down. This past weekend, he made his return to the cockpit of a single-seater, testing a Formula E car with hand controls at Portland International Raceway.
It wasn’t his first time in a racing car since 2018—for the last few years he’s been running in IMSA’s Michelin Pilot Challenge series, taking the 2023 TCR championship in a Hyundai Elantra N. But Formula E’s GenBeta car weighs almost 900 lbs less than Wickens’ Hyundai and boasts far more power and that immediate electric torque. More power than the Gen3 Formula E cars that lined up to race the following day, too—the 530 hp (395 kW) GenBeta machine is Formula E’s test bed and is able to deploy energy from its front electric motor (in addition to the rear motor) instead of just regenerating energy under braking.
I spoke with Wickens a few hours before his test and asked what he was expecting in terms of performance. “It’s an entirely different beast to an IndyCar,” he said. “So I know here in Portland that they actually had the exact same straight line speed as IndyCar [170 mph/275 km/h], obviously achieving in very different ways. The aerodynamic differences between the two and the whole philosophy of the series are entirely different. You’ll never really compare them, apples to apples, I don’t think, but, I’m really excited to give the Gen beta car a go,” Wickens said.
Enlarge/ The GenBeta car is Formula E’s rolling test bed.
Formula E
Unlike the steering wheel and accelerator and brake pedals most of us use, there’s no standard hand control setup, especially for a racing car. When Alex Zanardi competed in the 2019 Rolex 24, he used a wheel-mounted hand throttle to accelerate, but braked using a hand lever. That would be a challenge to fit into the tight confines of a single-seater cockpit, but that’s not the only reason Wickens and Formula E haven’t gone that route.
Hand controls
“When I was very early in my recovery, I had the luxury to talk to Alex several times. And he told me that if you need something easy, doing the brake lever off the steering wheel is the quickest solution to get into a car. But if you want to be as competitive as you can be, you have to have the brake on the steering wheel in some capacity,” Wickens said.
“It’s not like a sequential gearbox where you just downshift and then your two hands are on the steering wheel turning in—you’re trail-braking all the way to the apex. In Daytona, for example, you’re in the whole first section of the bus stop one handed—it’s like you can’t be 100 percent committed to the corner entry with one hand,” he explained.
I suggested that sounded like trying to race someone while holding a cellphone at the same time. “Pretty much yeah. But then unfortunately that cell phone is manipulating the balance of the car,” Wickens pointed out.
The advantage of a lever is the amount of force it allows the driver to send to the master cylinder. In his current setup in the TCR car, there’s a pneumatic actuator that helps apply sufficient brake pressure, “because I can only squeeze so much with my hands. And the difficulty with it is, there’s a small latency in achieving peak brake pressure. And that latency is not the same every time,” he said. While most of us would be rightfully terrified at having inconsistent brakes on track, Wickens adapted his driving style, something he says won’t transition to faster cars, though.
The US Supreme Court today agreed to hear a challenge to the Texas law that requires age verification on porn sites. A list of orders released this morning shows that the court granted a petition for certiorari filed by the Free Speech Coalition, an adult-industry lobby group.
In March, the US Court of Appeals for the 5th Circuit ruled that Texas could continue enforcing the law while litigation continues. In a 2-1 decision, 5th Circuit judges wrote that “the age-verification requirement is rationally related to the government’s legitimate interest in preventing minors’ access to pornography. Therefore, the age-verification requirement does not violate the First Amendment.”
The dissenting judge faulted the 5th Circuit majority for reviewing the law under the “rational-basis” standard instead of the more stringent strict scrutiny. The Supreme Court “has unswervingly applied strict scrutiny to content-based regulations that limit adults’ access to protected speech,” Judge Patrick Higginbotham wrote at the time.
Though the 5th Circuit majority upheld the age-verification rule, it also found that a requirement to display health warnings about pornography “unconstitutionally compel[s] speech” and cannot be enforced.
While the Supreme Court could eventually overturn the age-verification law, it is being enforced in the meantime. In April, the Supreme Court declined a request to temporarily block the Texas law.
Pornhub disabled site in Texas
After losing that April decision, the Free Speech Coalition said: “[We] remain hopeful that the Supreme Court will grant our petition for certiorari and reaffirm its lengthy line of cases applying strict scrutiny to content-based restrictions on speech like those in the Texas statute we’ve challenged.”
The Texas law, which took effect in September 2023, applies to websites in which more than one-third of the content “is sexual material harmful to minors.” Those websites must “use reasonable age verification methods” to limit their material to adults.
In February 2024, Texas Attorney General Ken Paxton alleged in a lawsuit that Pornhub owner Aylo (formerly MindGeek) violated the law. Pornhub disabled its website in Texas after the 5th Circuit ruling and has gone dark in other states in response to similar age laws.
The Free Speech Coalition’s petition for certiorari said that the Supreme Court “has repeatedly held that States may rationally restrict minors’ access to sexual materials, but such restrictions must withstand strict scrutiny if they burden adults’ access to constitutionally protected speech.” The group asked the court to determine whether the 5th Circuit “erred as a matter of law in applying rational-basis review to a law burdening adults’ access to protected speech, instead of strict scrutiny as this Court and other circuits have consistently done.”
“While purportedly seeking to limit minors’ access to online sexual content, the Act imposes significant burdens on adults’ access to constitutionally protected expression,” the petition said. “Of central relevance here, it requires every user, including adults, to submit personally identifying information to access sensitive, intimate content over a medium—the Internet—that poses unique security and privacy concerns.”
Enlarge/ Tires are a growing source of microplastic pollution. Michelin says it wants to change that.
Getty Images
Reduce, Reuse, Recycle—it’s more than just a fun alliteration tagline. It’s also a set of instructions for how to consume in a way that’s less destructive to our environment. We reduce our consumption and reuse what we already have, then recycle it once it no longer has any use. Unfortunately, many are going straight to recycling and calling it a day.
At its sustainability summit in Northern California at the Sonoma Raceway, Michelin laid out a new roadmap for its plans to become a more sustainable company. Most importantly, the company shared what it’s been doing for decades to reduce the harm done to the world by its tires.
The company reiterated its desire to have 100 percent renewable tires by 2050. Companies make a lot of pronouncements like this, and they only sometimes come to fruition. But looking at Michelin’s present efforts and past record, the company has a decent chance of succeeding.
The now
Michelin currently has a demonstration tire made of 42 percent renewable materials. The company has plenty of time to reach its goal in 2050, so it’s trying to make the change in the most profitable way possible.
“We are guided by a sustainable world view of organizing principles that is in every business decision we make. We balance it across three domains: the people, the planet, the profits,” Michelin North America President and CEO Alexis Garcin said during a presentation.
The “People, Planet, Profit” principles emphasize eco-consciousness but also remind everyone that Michelin is a company that needs to make money to keep tires rolling off the lines.
During the event, Michelin said that its research into more sustainable tires requires teams to show that the materials they use are readily available and that the tire can be produced at scale. This is a vast improvement over companies that unveil unrealistic, feel-good items that won’t ever see production.
The then
In 1992, Michelin introduced its first fuel-efficient tire. It had a lower rolling resistance, allowing drivers to potentially save money on gas and reduce their carbon footprint (although, to be fair, most probably didn’t think about that).
The company has been stress-testing the stuff that goes into tires, too. In 2019, it introduced new racing tires for IMSA’s WeatherTech Sportscar Championship that used 30 percent renewable and recycled materials, with no real drop-off in performance.
There’s also the reputation for longevity. According to a 2023 study by the German ADAC (Allgemeiner Deutscher Automobil-Club—think Germany’s AAA), Michelin’s average tire abrasion rate was 28 percent lower than the rate in average tires from other brands on the road in Germany.
The abrasion rate is how much of the tire is shed while driving. The higher the abrasion rate, the more particulates are left on the asphalt, which migrate to the soil and eventually end up in the water supply. Much has been said about these particles that have permeated our environment, little of it good.
Tires are a major source of microplastics, and as our vehicles get larger and heavier due to an insatiable appetite for large vehicles and our transition to EVs, tire companies have a spotlight on them to reduce their product abrasion rates. Here, Michelin seems to be ahead of the curve.
The later
Eighty percent of a tire’s environmental impact comes from the time that it’s sitting on a vehicle. Building a more sustainable tire can’t be done by just relying on different materials, especially if those materials wear down quicker than what’s already on the road. Michelin’s lifecycle assessment looks at the cradle-to-grave impact of a product as an ecosystem.
“For us, it’s people, profit, planet. We care about all of them at the same time with the same intensity, and that’s how we think we’re going to be sustainable,” Garcin said. If the company keeps sight of the goal, it might just pull it off.
Hellboy: The Crooked Man is based on a 2008 limited series by Mike Mignola and artist Richard Corben.
It has only been a few years since David Harbour starred in the 2019 reboot of the Hellboy film franchise—a critical and box office failure, although Harbour’s performance earned praise. But via Entertainment Weekly, we learned that there’s a new reboot coming our way: Hellboy: The Crooked Man. The project wrapped filming in May and now has a teaser—inexplicably released in 480p—giving us our first glimpse of star Jack Kesy’s (Claws, Deadpool 2) take on Mike Mignola’s iconic character.
It’s definitely a very different look and vibe from the previous big studio releases. Director Brian Taylor (Crank) is clearly leaning into the low-budget folk horror genre for this, but will fans embrace a bargain-basement Hellboy reboot—even one co-written by Mignola himself?
Mignola based his script on a 2008 Hellboy limited series he created, with artwork by Richard Corben. That story features a younger Hellboy wandering in the Appalachian Mountains in 1958 after “finishing up some stuff down South.” He meets regional native Tom Ferrell, coming home after decades away. When he was young, Tom was initiated as a witch and has returned to atone for that, even though he has never actually practiced magic—apart from a magical “witch-bone” he carries with him.
Tom and Hellboy team up to protect a young witch named Cora from having her soul reaped by the Crooked Man, aided by a blind pastor, the Reverend Watts. The Crooked Man was an 18th-century war profiteer named Jeremiah Witkins. Witkins was hanged for his crimes but returned from Hell and became the resident devil in those parts. Witkins wants Cora’s soul, and he also covets Tom’s witch-bone, but his evil machinations prove to be no match for Hellboy.
Enlarge/ Jack Kesy steps into the role of Hellboy, following in the footsteps of Ron Perlman and David Harbour.
Ketchup Entertainment
The new film seems to hew fairly closely to the source material—understandably so given Mignola’s direct involvement. Per the official premise: “In the 1950s, Hellboy and a rookie BPRD (Bureau of Paranormal Research and Defense) agent, stranded in rural Appalachia, discover a small community haunted by witches, led by a local devil with a troubling connection to Hellboy’s past: the Crooked Man.”
In addition to Kesy, the cast includes Jefferson White as Tom Ferrell; Adeline Rudolph as rookie BPRD agent Bobbie Jo Song; Joseph Marcell as Reverend Nathaniel Armstrong Watts; Leah McNamara as Effie Kolb; Hannah Margetson as Cora Fisher; and Martin Bassindale in a dual role: Trevor “Broom” Bruttenholm, founder and head of the BPRD and Hellboy’s adoptive father, and Jeremiah Witkins, aka the Crooked Man.
The teaser opens with some scenic shots of Appalachia as Hellboy makes ominous comments in a voiceover about “evil” lurking and how the forest “smells like death.” It doesn’t take long for that evil to make itself known, as a levitating woman is bitten by a snake, plagues of insects and other creatures wreak havoc, and Hellboy is assured that “all your friends are gonna die.” The poor quality of the teaser is unfortunate and frankly does not instill tons of confidence, but I like the folk horror vibe; some of those scenes look hella scary. Tonally, the teaser feels a bit like The Blair Witch Project meets The Conjuring or The Witch.
What it doesn’t feel like is the Hellboy we have come to know and love. Look, diehard fans are still mad that Guillermo del Toro never got to complete his planned trilogy after the massive success of Hellboy (2004) and Hellboy II: The Golden Army (2008). Originally titled Hellboy III: Dark Worlds, the project was canceled due to lack of financing, and the fans haven’t forgotten… or forgiven.
Lionsgate tried to reboot the franchise instead with Harbour in the titular role, but that film turned out to be one of the biggest flops of 2019. Director Neil Marshall actually disowned the film, calling it “godawful” and “the worst professional experience of my life.” He had pitched the project as a darker, R-rated horror version of Hellboy, but studio interference meant he had very little creative control in the end. Now it’s Taylor’s turn to bring us his own darker, horrific R-rated vision, working on a smaller scale—if nothing else, it hopefully reduced the aforementioned studio interference. There’s not yet a release date, but we’ll see how it turned out soon enough.
Enlarge/ Right now, the software doesn’t do arms, so don’t go taking on any aliens with it.
20th Century Fox
Exoskeletons today look like something straight out of sci-fi. But the reality is they are nowhere near as robust as their fictional counterparts. They’re quite wobbly, and it takes long hours of handcrafting software policies, which regulate how they work—a process that has to be repeated for each individual user.
To bring the technology a bit closer to Avatar’s Skel Suits or Warhammer 40k power armor, a team at North Carolina University’s Lab of Biomechatronics and Intelligent Robotics used AI to build the first one-size-fits-all exoskeleton that supports walking, running, and stair-climbing. Critically, its software adapts itself to new users with no need for any user-specific adjustments. “You just wear it and it works,” says Hao Su, an associate professor and co-author of the study.
Tailor-made robots
An exoskeleton is a robot you wear to aid your movements—it makes walking, running, and other activities less taxing, the same way an e-bike adds extra watts on top of those you generate yourself, making pedaling easier. “The problem is, exoskeletons have a hard time understanding human intentions, whether you want to run or walk or climb stairs. It’s solved with locomotion recognition: systems that recognize human locomotion intentions,” says Su.
Building those locomotion recognition systems currently relies on elaborate policies that define what actuators in an exoskeleton need to do in each possible scenario. “Let’s take walking. The current state of the art is we put the exoskeleton on you and you walk on a treadmill for an hour. Based on that, we try to adjust its operation to your individual set of movements,” Su explains.
Building handcrafted control policies and doing long human trials for each user makes exoskeletons super expensive, with prices reaching $200,000 or more. So, Su’s team used AI to automatically generate control policies and eliminate human training. “I think within two or three years, exoskeletons priced between $2,000 and $5,000 will be absolutely doable,” Su claims.
His team hopes these savings will come from developing the exoskeleton control policy using a digital model, rather than living, breathing humans.
Digitizing robo-aided humans
Su’s team started by building digital models of a human musculoskeletal system and an exoskeleton robot. Then they used multiple neural networks that operated each component. One was running the digitized model of a human skeleton, moved by simplified muscles. The second neural network was running the exoskeleton model. Finally, the third neural net was responsible for imitating motion—basically predicting how a human model would move wearing the exoskeleton and how the two would interact with each other. “We trained all three neural networks simultaneously to minimize muscle activity,” says Su.
One problem the team faced is that exoskeleton studies typically use a performance metric based on metabolic rate reduction. “Humans, though, are incredibly complex, and it is very hard to build a model with enough fidelity to accurately simulate metabolism,” Su explains. Luckily, according to the team, reducing muscle activations is rather tightly correlated with metabolic rate reduction, so it kept the digital model’s complexity within reasonable limits. The training of the entire human-exoskeleton system with all three neural networks took roughly eight hours on a single RTX 3090 GPU. And the results were record-breaking.
Bridging the sim-to-real gap
After developing the controllers for the digital exoskeleton model, which were developed by the neural networks in simulation, Su’s team simply copy-pasted the control policy to a real controller running a real exoskeleton. Then, they tested how an exoskeleton trained this way would work with 20 different participants. The averaged metabolic rate reduction in walking was over 24 percent, over 13 percent in running, and 15.4 percent in stair climbing—all record numbers, meaning their exoskeleton beat every other exoskeleton ever made in each category.
This was achieved without needing any tweaks to fit it to individual gaits. But the neural networks’ magic didn’t end there.
“The problem with traditional, handcrafted policies was that it was just telling it ‘if walking is detected do one thing; if walking faster is detected do another thing.’ These were [a mix of] finite state machines and switch controllers. We introduced end-to-end continuous control,” says Su. What this continuous control meant was that the exoskeleton could follow the human body as it made smooth transitions between different activities—from walking to running, from running to climbing stairs, etc. There was no abrupt mode switching.
“In terms of software, I think everyone will be using this neural network-based approach soon,” Su claims. To improve the exoskeletons in the future, his team wants to make them quieter, lighter, and more comfortable.
But the plan is also to make them work for people who need them the most. “The limitation now is that we tested these exoskeletons with able-bodied participants, not people with gait impairments. So, what we want to do is something they did in another exoskeleton study at Stanford University. We would take a one-minute video of you walking, and based on that, we would build a model to individualize our general model. This should work well for people with impairments like knee arthritis,” Su claims.
Enlarge/ Extreme sportsman Ross Edgley comes face to face with a great hammerhead shark in the waters of Bimini in the Bahamas.
National Geographic/Nathalie Miles
Ultra-athlete Ross Edgley is no stranger to pushing his body to extremes. He once ran a marathon while pulling a one-ton car; ran a triathlon while carrying a 100-pound tree; and climbed a 65-foot rope over and over again until he’d climbed the equivalent of Mt. Everest—all for charity. In 2016, he set the world record for the world’s longest staged sea swim around the coastline of Great Britain: 1780 miles over 157 days.
At one point during that swim, a basking shark appeared and swam alongside Edgley for a day and a half. That experience ignited his curiosity about sharks and eventually led to his new National Geographic documentary, Shark vs. Ross Edgley—part of four full weeks of 2024 SHARKFEST programming. Edgley matches his athletic prowess against four different species of shark. He tries to jump out of the water (polaris) like a great white shark; withstand the G forces produced by a hammerhead shark‘s fast, rapid turns; mimic the extreme fasting and feasting regimen of a migrating tiger shark; and match the swimming speed of a mako shark.
“I love this idea of having a goal and then reverse engineering and deconstructing it,” Edgley told Ars. “[Sharks are] the ultimate ocean athletes. We just had this idea: what if you’re crazy enough to try and follow in the footsteps of four amazing sharks? It’s an impossible task. You’re going to fail, you’re going to be humbled. But in the process, we could use it as a sports/shark science experiment, almost like a Trojan horse to bring science and ocean conservation to a new audience.”
And who better than Edgley to take on that impossible challenge? “The enthusiasm he brings to everything is really infectious,” marine biologist and shark expert Mike Heithaus of Florida International University told Ars. “He’s game to try anything. He’d never been in the water with sharks and we’re throwing him straight in with big tiger sharks and hammerheads. He’s loving the whole thing and just devoured all the information.”
That Edgley physique doesn’t maintain itself, so the athlete was up at 4 AM swimming laps and working out every morning before the rest of the crew had their coffee. “I’m doing bicep curls with my coffee cup and he’s doing bicep curls with the 60-pound underwater camera,” Heithaus recalled. “For the record, I got one rep in and I’m very proud of that.” Score one for the shark expert.
(Spoilers below for the various shark challenges.)
Ross vs. the great white shark
Ross Edgley gets some tips on how to power (polaris) his body out of the water like a white shark from synchronized swimmer Samantha Wilson
National Geographic/Nathalie Miles
The Aquabatix synchronized swim team demonstrates the human equivalent to a white shark’s polaris.
National Geographic/Nathalie Miles
Edgley tries out a mono fin to improve his polaris performance.
National Geographic/Nathalie Miles
Edgley propelling 3/4 of his body out of the pool to mimic a white shark’s polaris movement
National Geographic/Bobby Cross
For the first challenge, Edgley took on the great white shark, a creature he describes as a “submarine with teeth.” These sharks are ambush hunters, capable of propelling their massive bodies fully out of the water in an arching leap. That maneuver is called a polaris, and it’s essential to the great white shark’s survival. It helps that the shark has 65 percent muscle mass, particularly concentrated in the tail, as well as a light skeleton and a large liver that serves as buoyancy device.
Edgley, by comparison, is roughly 45 percent muscle mass—much higher than the average human but falling short of the great white shark. To help him try to match the great white’s powerful polaris maneuver, Edgley sought tips on biomechanics from the Aquabatix synchronized swim team, since synchronized swimmers must frequently launch their bodies fully out of the water during routines. They typically get a boost from their teammates to do so.
The team did manage to boost Edgley out of the water, but sharks don’t need a boost. Edgley opted to work with a monofin, frequently used in underwater sports like free diving or finswimming, to see what he could achieve on his own power. After a bit of practice, he succeeded in launching 75 percent of his body (compared to the shark’s 100 percent) out of the water. Verdict: Edgley is 75 percent great white shark.
Ross vs. the hammerhead shark
Edgley vs. a hammerhead shark. He will try to match the animal’s remarkable agility underwater.
National Geographic/Nathalie Miles
A camera team films a hammerhead shark making sharp extreme turns
National Geographic/Nathalie Miles
Edgley prepares to go airborne in a stunt plane to try and mimic the agility of a hammerhead shark in the water.
National Geographic/Nathalie Miles
A standard roll produces 2 g’s, while pulling up is 3 g’s
YouTube/National Geographic
Edgley is feeling a bit queasy.
YouTube/National Geographic
Next up: Edgley pitted himself against the remarkable underwater agility of a hammerhead shark. Hammerheads are known for being able to swim fast and turn on a dime, thanks to a flexible skeleton that enables them to bend and contort their bodies nearly in half. They’re able to withstand some impressive G forces (up to 3 G’s) in the process. According to Heithaus, these sharks feed on other rays and other sharks, so they need to be built for speed and agility—hence their ability to accelerate and turn rapidly.
The NatGeo crew captured impressive underwater footage of the hammerheads in action, including Edgley meeting a 14.7 hammerhead named “Queenie”—one of the largest great hammerheads that visits Bimini in the Bahamas during the winter. That footage also includes shots of divers feeding fish to some of the hammerheads by hand. “They know every shark by name and the sharks know the feeders,” said Heithaus. “So you can safely get close to these big amazing creatures.”
For years, scientists had wondered about the purpose of the distinctive hammer-shaped head. It may help them scan a larger area of the ocean floor while hunting. Like all sharks, hammerheads have sensory pores called ampullae of Lorenzini that allow them to detect electrical signals and hence possible prey. The hammer-shaped head distributes those pores over a wider span.
But according to Heithaus, the hammer shape also operates a bit like the big broad flap of an airplane wing, resulting in excellent hydrodynamics. Moving at high speeds, “You can just tilt the head a tiny bit and bank a huge degree,” he said. “So if a ray turns 180 degrees to escape, the hammerhead can track with it. Other species would take a wider turn and fall behind.”
The airplane wing analogy gave Edgley an idea for how he could mimic the tight turns and high G forces of a hammerhead shark: take a flight in a small stunt plane. The catch: Edgley is not a fan of flying. And as he’d feared, he became horribly airsick during the challenge, even puking into a little airbag at one point. “It looks so cool in the clip,” he said. “But at the time, I was in a world of trouble.” Pilot Mark Greenfield finally cut the experiment short when he determined that Edgley was too sick to continue. Verdict: Edgley is 0 percent hammerhead shark.
Ross vs. the tiger shark
Shark expert Mike Heithaus holds a gelatin shark “lolliop” while Edgley flexes.
National Geographic/Nathalie Miles
Edgley and Heithaus underwater with a tiger shark, tempting it with a gelatin lollipop.
National Geographic/Nathalie Miles
Success! A tiger shark takes a nice big bite.
National Geographic/Nathalie Miles
Edgley flexes with the giant gelatin lollipop with a large bite taken out of it by a tiger shark
National Geographic/Nathalie Miles
Edgley gets his weight and body volume measured in the “Bodpod” before his tiger shark challenge.
National Geographic/Bobby Cross
Edgley fasted and exercised for 24 hours to mimic a tiger shark on a migration route. He dropped 14 pounds.
National Geographic/Nathalie Miles
After all that fasting and exercise, Edgley then gorged himself for 24 hours to put the weight back on. He gained 22 pounds.
National Geographic/Nathalie Miles
The third challenge was trying to match the fortitude of a migrating tiger shark as it makes its way over thousands of miles without food, only feasting at journey’s end. “I was trying to understand the psychology of a tiger shark because there’s just nothing for them to eat [on the journey],” said Ross. And once they arrive at their destination, “they can chow down on entire whale carcasses and eat just about anything. That idea of feast and famine is something we humans used to do all the time. We live quite comfortably now so we’ve lost touch with that.”
The first step was to figure out just how many calories a migrating tiger shark can consume in a single bite. Heithaus has been part of SHARKFEST for several years now and recalled one throwback show, Sharks vs. Dolphins, in which he tried to determine which species of of shark were attacking dolphins, and just how big those sharks might be. He hit upon the idea of making a dolphin shape out of gelatin—essentially the same stuff FIU’s forensic department uses for ballistic tests—and asked his forensic colleagues to make one for him, since the material has the same weight and density of dolphin blubber.
For the Edgley documentary, they made a large gelatin lollipop the same density as whale blubber, and he and Edgley dove down and managed to get an 11-foot tiger shark to take a big 6.2-pound bite out of it. We know how many calories are in whale blubber so Heithaus was able to deduce from that how many calories per bite a tiger shark consumed (6.2 pounds of whale meet is equivalent to about 25,000 calories).
Such field work also lets him gather ever mire specimens of shark bites from a range of species for his research. “The great thing about SHARKFEST is that you’re seeing new, cutting-edge science that may or may not work,” said Heithaus. “But that’s what science is about: trying things and advancing our knowledge even if it doesn’t work al the time, and then sharing that information and excitement with the public.”
Then it was time for Edgley to make like a migrating shark and embark on a carefully designed famine-and-feast regime. First, his weight and body volume were measured in a “Bodpod”: 190.8 pounds and 140.8 pints. Then Edgley fasted and exercised almost continuously for 24 hours with a mix of weight training, running, swimming, sitting in the sauna, and climate chamber cycling. (He did sleep for a few hours.) He dropped 14 pounds and lost twelve pints, ending up at a weight of 177 pounds and a volume of 128.7 pints. Instead of food, what he craved most at the end was water. “When you are in a completely deprived state, you find out what your body actually needs, not what it wants,” said Edgley.
After slaking his thirst, it was time to gorge. Over the next 24 hours, Edgley consumed an eye-popping 35,103 calories in carefully controlled servings. It’s quite the menu: Haribo mix, six liters of Lucozade, a Hulk smoothie, pizza, five slices of lemon blueberry cheesecake, five slices of chocolate mint cheesecake, fish and chips, burgers and fries, two cinnamon loaves, four tubs of Ben & Jerry’s ice cream, two full English breakfasts, five liters of custard, four mars bars, and four mass gainer shakes.
When his weight and volume were measured one last time in the Bodpod, Edgley had regained a whopping 22 pounds for a final weight of 199 pounds. “I wish I had Ross’s ability to eat that much and remain at 0 percent body fat,” said Heithaus. Verdict: Edgley is 28 percent tiger shark.
Ross vs. the mako shark
In 2018, Edgely set the world record for longest assisted sea swim.
National Geographic/Nathalie Miles
Edgley tries to match the speed of a mako shark in the waters of the Menai Strait in Wales.
National Geographic/Nathalie Miles
Finally, Edgley pitted himself against the mighty mako shark. Mako sharks are the speediest sharks in the ocean, capable of swimming at speeds up to 43 MPH. Edgley is a long-distance swimmer, not a sprinter, so he threw himself into training at Loughborough University with British Olympians coaching him. He fell far short of a mako shark’s top speed. The shape of the human body is simply much less hydrodynamic than that of a shark. He realized that despite his best efforts, “I was making up hundredths of a second, which is huge in sprinting,” he said. “That could be the difference between a gold medal at the Paris Olympics and not. But I needed to make up many kilometers per hour.”
So Edgley decided to “think like a shark” and employ a shark-like strategy of riding the ocean currents to increase his speed. He ditched the pool and headed to the Menai Strait in Wales for some open water swimming. Ultimately he was able to hit 10.24 MPH—double what an Olympic swimmer could manage in a pool, but just 25 percent of a mako shark’s top speed. And he managed with the help or a team of 20-30 people dropping him into the fastest tide possible. “A mako shark would’ve just gone, ‘This is a Monday morning, this isn’t an event for me, I’m off,'” said Edgley. Verdict: Edgley is 24 percent mako shark
When the results of all four challenges were combined, Edgley came out at 32 percent overall, or nearly one-third shark. While Edgley confessed to being humbled by his limitations, “I don’t think there’s anyone else out there who could do so as well across the board in comparison,” said Heithaus.
The ultimate goal of Shark vs. Ross Edgley—and indeed all of the SHARKFEST programming—is to help shift public perceptions of sharks. “The great Sir David Attenborough said that the problems facing us in terms of conservation is as much a communication issue as a scientific one,” Edgley said. “The only way we can combat that is by educating people.”
Shark populations have declined sharply by 70 percent or more over the last 50 years. “It’s really critical that we protect and restore these populations,” Heithaus said. Tiger sharks, for instance, eat big grazers like turtles and sea cows, and thus protect the sea grass. (Among other benefits, the sea grass sequesters carbon dioxide.) Sharks are also quite sophisticated in their behavior. “Some have social connections with other sharks, although not to the same extent as dolphins,” said Heithaus. “They’re more than just loners, and they may have personalities. We see some sharks that are more bold, and others that are more shy. There’s a lot more to sharks than we would have thought.”
People who hear about Edgley’s basking shark encounter invariably assume he’d been in danger. However, “We were friends. I’m not on its menu,” Edgley said. “There are so many different species.” He likened it to being chased by a dog. People might assume it was a rottweiler giving chase, when in fact the basking shark is the equivalent of a poodle. “Hopefully what people take away from this is moving from a fear and misunderstanding of sharks to respect and admiration,” Edgley said. “That’ll make the RAF fighter pilot plane worth it.”
And he’s game to take on even more shark challenges in the future. There are a lot more shark species out there, after all, just waiting to go head-to-head with a human ultra-athlete.
Shark vs. Ross Edgley premieres on Sunday, June 30, 2024, on Disney+.
Enlarge/ Preparing to install the floppy disk edition of FreeDOS 1.3 in a virtual machine.
Andrew Cunningham
Two big things happened in the world of text-based disk operating systems in June 1994.
The first is that Microsoft released MS-DOS version 6.22, the last version of its long-running operating system that would be sold to consumers as a standalone product. MS-DOS would continue to evolve for a few years after this, but only as an increasingly invisible loading mechanism for Windows.
The second was that a developer named Jim Hall wrote a post announcing something called “PD-DOS.” Unhappy with Windows 3.x and unexcited by the project we would come to know as Windows 95, Hall wanted to break ground on a new “public domain” version of DOS that could keep the traditional command-line interface alive as most of the world left it behind for more user-friendly but resource-intensive graphical user interfaces.
PD-DOS would soon be renamed FreeDOS, and 30 years and many contributions later, it stands as the last MS-DOS-compatible operating system still under active development.
While it’s not really usable as a standalone modern operating system in the Internet age—among other things, DOS is not really innately aware of “the Internet” as a concept—FreeDOS still has an important place in today’s computing firmament. It’s there for people who need to run legacy applications on modern systems, whether it’s running inside of a virtual machine or directly on the hardware; it’s also the best way to get an actively maintained DOS offshoot running on legacy hardware going as far back as the original IBM PC and its Intel 8088 CPU.
To mark FreeDOS’ 20th anniversary in 2014, we talked with Hall and other FreeDOS maintainers about its continued relevance, the legacy of DOS, and the developers’ since-abandoned plans to add ambitious modern features like multitasking and built-in networking support (we also tried, earnestly but with mixed success, to do a modern day’s work using only FreeDOS). The world of MS-DOS-compatible operating systems moves slowly enough that most of this information is still relevant; FreeDOS was at version 1.1 back in 2014, and it’s on version 1.3 now.
For the 30th anniversary, we’ve checked in with Hall again about how the last decade or so has treated the FreeDOS project, why it’s still important, and how it continues to draw new users into the fold. We also talked, strange as it might seem, about what the future might hold for this inherently backward-looking operating system.
FreeDOS is still kicking, even as hardware evolves beyond it
Running AsEasyAs, a Lotus 1-2-3-compatible spreadsheet program, in FreeDOS.
Jim Hall
If the last decade hasn’t ushered in The Year of FreeDOS On The Desktop, Hall says that interest in and usage of the operating system has stayed fairly level since 2014. The difference is that, as time has gone on, more users are encountering FreeDOS as their first DOS-compatible operating system, not as an updated take on Microsoft and IBM’s dusty old ’80s- and ’90s-era software.
“Compared to about 10 years ago, I’d say the interest level in FreeDOS is about the same,” Hall told Ars in an email interview. “Our developer community has remained about the same over that time, I think. And judging by the emails that people send me to ask questions, or the new folks I see asking questions on our freedos-user or freedos-devel email lists, or the people talking about FreeDOS on the Facebook group and other forums, I’d say there are still about the same number of people who are participating in the FreeDOS community in some way.”
“I get a lot of questions around September and October from people who ask, basically, ‘I installed FreeDOS, but I don’t know how to use it. What do I do?’ And I think these people learned about FreeDOS in a university computer science course and wanted to learn more about it—or maybe they are already working somewhere and they read an article about it, never heard of this “DOS” thing before, and wanted to try it out. Either way, I think more folks in the user community are learning about “DOS” at the same time they are learning about FreeDOS.”
Enlarge/ A European ATV cargo freighter reenters the atmosphere over the Pacific Ocean in 2013.
Since the beginning of the year, landowners have discovered several pieces of space junk traced to missions supporting the International Space Station. On all of these occasions, engineers expected none of the disposable hardware would survive the scorching heat of reentry and make it to Earth’s surface.
These incidents highlight an urgency for more research into what happens when a spacecraft makes an uncontrolled reentry into the atmosphere, according to engineers from the Aerospace Corporation, a federally funded research center based in El Segundo, California. More stuff is getting launched into space than ever before, and the trend will continue as companies deploy more satellite constellations and field heavier rockets.
“The biggest immediate need now is just to do some more work to really understand this whole process and to be in a position to be ready to accommodate new materials, new operational approaches as they happen more quickly,” said Marlon Sorge, executive director of Aerospace’s Center for Orbital and Reentry Debris Studies. “Clearly, that’s the direction that spaceflight is going.”
Ideally, a satellite or rocket body at the end of its life could be guided to a controlled reentry into the atmosphere over a remote part of the ocean. But this is often cost-prohibitive because it would require carrying extra fuel for the de-orbit maneuvers, and in many cases, a spacecraft doesn’t have any rocket thrusters at all.
In March, a fragment from a battery pack jettisoned from the space station punched a hole in the roof of a Florida home, a rare instance of terrestrial property damage attributed to a piece of space junk. In May, a 90-pound chunk of a SpaceX Dragon spacecraft that departed the International Space Station fell on the property of a “glamping” resort in North Carolina. At the same time, a homeowner in a nearby town found a smaller piece of material that also appeared to be from the same Dragon mission.
These events followed the discovery in April of another nearly 90-pound piece of debris from a Dragon capsule on a farm in the Canadian province of Saskatchewan. NASA and SpaceX later determined the debris fell from orbit in February, and earlier this month, SpaceX employees came to the farm to retrieve the wreckage, according to CBC.
Pieces of a Dragon spacecraft also fell over Colorado last year, and a farmer in Australia found debris from a Dragon capsule on his land in 2022.
Enlarge/ A Vision Pro on display at an Apple Store in Tokyo.
Apple
Apple’s Vision Pro headset went on sale outside the United States for the first time today, in the first of two waves of expanded availability.
The $3,499 “spatial computing” device launched back in February in the US, but it hasn’t taken the tech world by storm. Part of that has been its regional launch, with some of the biggest markets still lacking access.
Apple announced that the product would be sold internationally during its keynote at the Worldwide Developers Conference earlier this month.
The first new markets to get Vision Pro shipments are China, Japan, and Singapore—those are the ones where it went on sale today.
A second wave will come on July 12, with the headset rolling out in Australia, Canada, France, Germany, and the United Kingdom.
When we first tested the Vision Pro in February, we wrote that it was a technically impressive device with a lot of untapped potential. It works very well as a personal entertainment device for frequent travelers, in particular. However, its applications for productivity and gaming still need to be expanded to justify the high price.
Of course, there have been conflicting rumors of late about just how expensive Apple plans to keep its mixed reality devices. One report claimed that the company put the brakes on a new version of the Vision Pro for now, opting instead to develop a cheaper alternative for a 2025 launch.
But another report in Bloomberg suggested that’s an overstatement. It simply noted that the Vision Pro 2 has been slightly delayed from its original target launch window and reported that the cheaper model will come first.
In any case, availability will have to expand and the price will ultimately have to come down if augmented reality can become the major computing revolution that Apple CEO Tim Cook has predicted. This international rollout is the next step to test whether there’s a market for that.
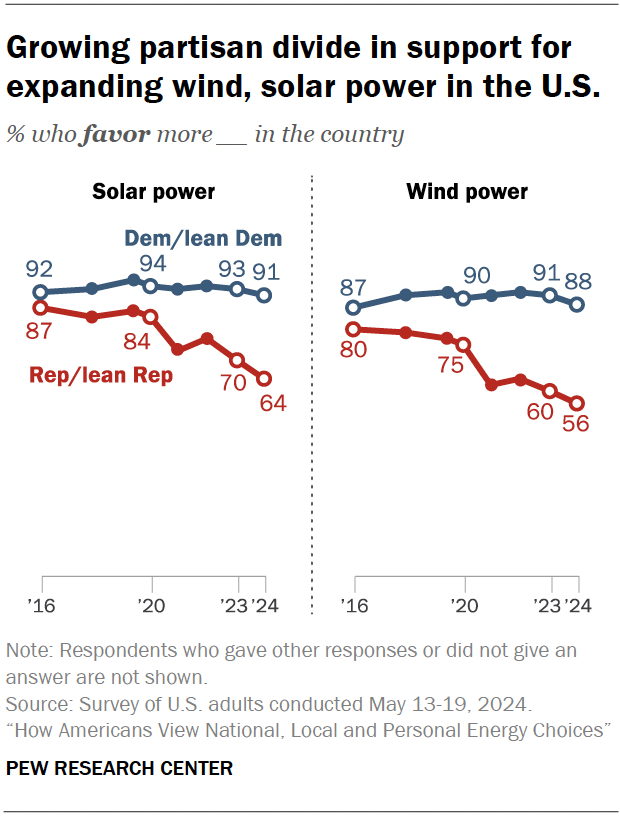
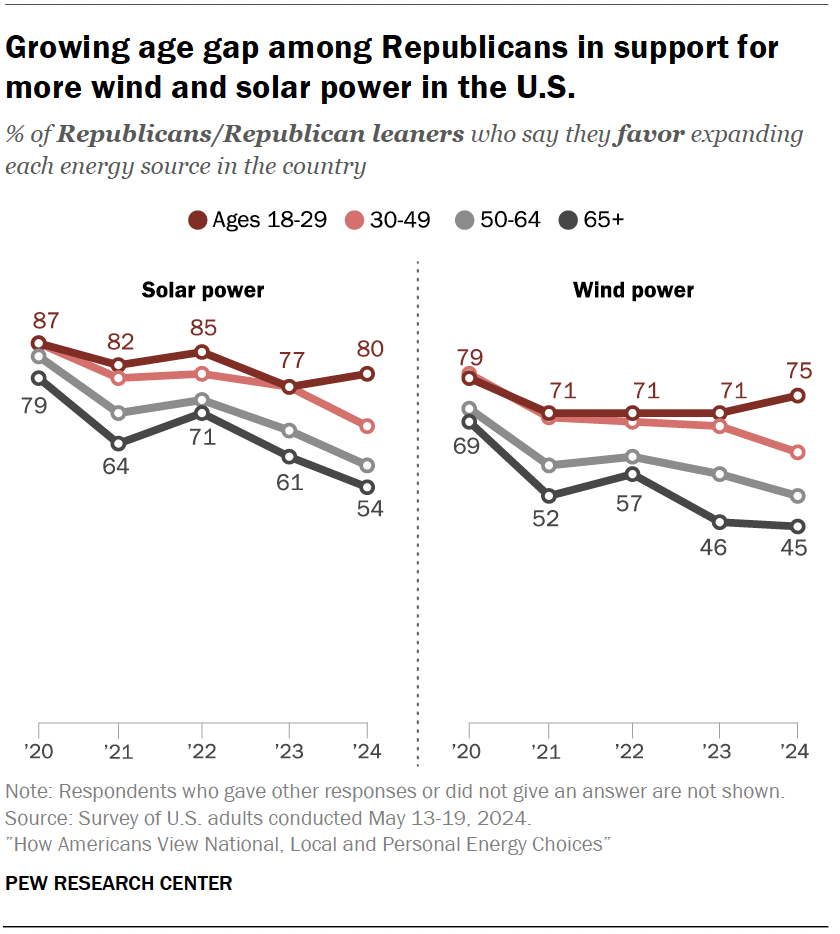
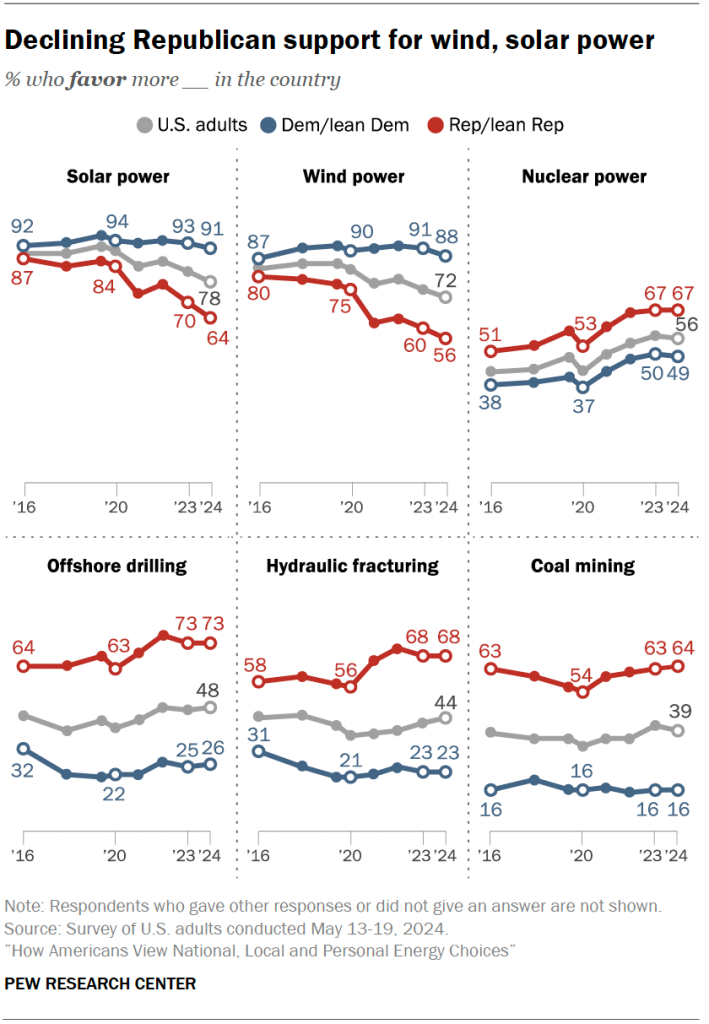
One of the most striking things about the explosion of renewable power that’s happening in the US is that much of it is going on in states governed by politicians who don’t believe in the problem wind and solar are meant to address. Acceptance of the evidence for climate change tends to be lowest among Republicans, yet many of the states where renewable power has boomed—wind in Wyoming and Iowa, solar in Texas—are governed by Republicans.
That’s partly because, up until about 2020, there was a strong bipartisan consensus in favor of expanding wind and solar power, with support above 75 percent among both parties. Since then, however, support among Republicans has dropped dramatically, approaching 50 percent, according to polling data released this week.
Renewables enjoyed solid Republican support until recently.
To a certain extent, none of this should be surprising. The current leader of the Republican Party has been saying that wind turbines cause cancer and offshore wind is killing whales. And conservative-backed groups have been spreading misinformation in order to drum up opposition to solar power facilities.
Meanwhile, since 2022, the Inflation Reduction Act has been promoted as one of the Biden administration’s signature accomplishments and has driven significant investments in renewable power, much of it in red states. Negative partisanship is undoubtedly contributing to this drop in support.
One striking thing about the new polling data, gathered by the Pew Research Center, is how dramatically it skews with age. When given a choice between expanding fossil fuel production or expanding renewable power, Republicans under the age of 30 favored renewables by a 2-to-1 margin. Republicans over 30, in contrast, favored fossil fuels by margins that increased with age, topping out at a three-to-one margin in favor of fossil fuels among those in the 65-and-over age group. The decline in support occurred in those over 50 starting in 2020; support held steady among younger groups until 2024, when the 30–49 age group started moving in favor of fossil fuels.
Among younger Republicans, support for renewable energy remains high.
Democrats, by contrast, break in favor of renewables by 75 points, with little difference across age groups and no indication of significant change over time. They’re also twice as likely to think a solar farm will help the local economy than Republicans are.
Similar differences were apparent when Pew asked about policies meant to encourage the sale of electric vehicles, with 83 percent of Republicans opposed to having half of cars sold be electric in 2032. By contrast, nearly two-thirds of Democrats favored this policy.
There’s also a rural/urban divide apparent (consistent with Republicans getting more support from rural voters). Forty percent of urban residents felt that a solar farm would improve the local economy; only 25 percent of rural residents agreed. Rural residents were also more likely to say solar farms made the landscape unattractive and take up too much space. (Suburban participants were consistently in between rural and urban participants.)
What’s behind these changes? The single biggest factor appears to be negative partisanship combined with the election of Joe Biden.
For Republicans, 2020 represented an inflection point in terms of support for different types of energy. That wasn’t true for Democrats.
Among Republicans, support for every single form of power started to change in 2020—fossil fuels, renewables, and nuclear. Among Democrats, that’s largely untrue. Their high level of support for renewable power and aversion to fossil fuels remained largely unchanged. The lone exception is nuclear power, where support rose among both Democrats and Republicans (the Biden administration has adopted a number of pro-nuclear policies).
This isn’t to say that non-political factors are playing no role. The rapid expansion of renewable power means that many more people are seeing facilities open near them, and viewing that as an indication of a changing society. Some degree of backlash was almost inevitable and, in this case, the close ties between conservative lobbyists and fossil fuel interests were ready to take advantage of it.
Ryan Reynolds and Hugh Jackman star in Deadpool and Wolverine.
It’s safe to say that Marvel Studios’ Deadpool and Wolverine is one of the most hotly anticipated releases of the summer. We’ve had a teaser and full trailer, and now the studio has released a second one-minute trailer with a surprise appearance bound to delight X-Men fans everywhere. It’s none other than Sabretooth, played by the same actor, Tyler Mane, who portrayed the character in 2000’s X-Men. And he’s got a score to settle with Wolverine.
As previously reported, Ryan Reynolds found the perfect fit with 2016’s Deadpool, starring as Wade Wilson, a former Canadian special forces operative (dishonorably discharged) who develops regenerative healing powers that heal his cancer but leave him permanently disfigured with scars all over his body. Wade decides to become a masked vigilante, turning down an invitation to join the X-Men and abandon his bad-boy ways. The first Deadpool was a big hit, racking up $782 million at the global box office, critical praise, and a couple of Golden Globe nominations for good measure. Deadpool 2 was released in 2018 and was just as successful.
Deadpool and Wolverine reunites Reynolds with many familiar faces from the first two films. Morena Baccarin is back as Wade’s girlfriend Vanessa, along with Leslie Uggams as Blind Al; Karan Soni as Wade’s personal chauffeur, taxi driver Dopinder; Brianna Hildebrand as Negasonic Teenage Warhead; Stefan Kapičić as the voice of Colossus; Shioli Kutsuna as Negasonic’s mutant girlfriend, Yukio; Randal Reeder as Buck; and Lewis Tan as X-Force member Shatterstar.
We’re also getting some characters drawn from various films under the 20th Century Fox Marvel umbrella: Pyro (Aaron Stanford)—last seen in 2006’s X-Men: The Last Stand—and Jennifer Garner’s Elektra, who appeared in the 2003 Daredevil film as well as 2005’s Elektra. Along with Sabretooth, the mutants Toad and Dogpool should be on hand to make some trouble. New to the franchise are Matthew MacFadyen as a Time Variance Authority agent named Paradox and Emma Corrin as the lead villain. There have been rumors that Owen Wilson’s Mobius and the animated Miss Minutes from Loki may also appear in the film.
The battle is going pretty well and this dynamic duo wants to know: “Who’s next?”
YouTube/Marvel Studios
“Oh. My. God. Sabretooth.” Our feelings exactly.
YouTube/Marvel Studios
Deadpool calls for a timeout because Wolverine “looks ridiculous” with all those weapons sticking out of him.
YouTube/Marvel Studios
Wolverine is not amused.
YouTube/Marvel Studios
Battle!!!
YouTube/Marvel Studios
Marvel released a two-minute teaser for the new movie during the Super Bowl in February, featuring the trademark cheeky irreverence that made audiences embrace Reynold’s R-rated superhero in the first place, plus a glimpse of Hugh Jackman’s Wolverine—or rather, his distinctive shadow. And yes, Marvel is retaining that R rating—a big step given that all the prior MCU films have been resoundingly PG-13. Marvel dropped a full trailer in April that was chock-full of off-color witticisms, meta-references, slo-mo action, and a generous sprinkling of F-bombs. (But no cocaine! Wade promised Kevin Feige!)
This latest trailer has a lot of the same footage as that April trailer until the 26-second mark. That’s when Wolverine growls, “Who’s next?” after battling a horde of foes. Who should jump into the fray with an answering growl but Sabretooth. We are all Deadpool when he exclaims, “Oh. My. God.” Sabretooth breaks out his claws and asks Wolverine if he’s ready to die. That’s when Deadpool calls a timeout to pull a few weapons out of his frenemy and offer a few tips on how to defeat the other mutant, to Wolverine’s annoyance.
“People have waited decades for this fight,” Deadpool insists. “It’s not gonna be easy. Baby knife. Shoot the devil, you take him down. Side control. Then full mount, and you ground and pound until he makes no sound because he’s dead. OK, good luck, I’m a huge fan.” We’ll have to wait a few more weeks to find out if Wolverine takes any of that advice.
Deadpool and Wolverine hits theaters on July 26, 2024.
Enlarge/ SpaceX’s 10th Falcon Heavy rocket climbs into orbit with a new US government weather satellite.
Welcome to Edition 6.50 of the Rocket Report! SpaceX launched its 10th Falcon Heavy rocket this week with the GOES-U weather satellite for NOAA, and this one was a beauty. The late afternoon timing of the launch and atmospheric conditions made for great photography. Falcon Heavy has become a trusted rocket for the US government, and its next flight in October will deploy NASA’s Europa Clipper spacecraft on the way to explore one of Jupiter’s enigmatic icy moons.
As always, we welcome reader submissions, and if you don’t want to miss an issue, please subscribe using the box below (the form will not appear on AMP-enabled versions of the site). Each report will include information on small-, medium-, and heavy-lift rockets as well as a quick look ahead at the next three launches on the calendar.
Sir Peter Beck dishes on launch business. Ars spoke with the recently knighted Peter Beck, founder and CEO of Rocket Lab, on where his scrappy company fits in a global launch marketplace dominated by SpaceX. Rocket Lab racked up the third-most number of orbital launches by any US launch company (it’s headquartered in California but primarily assembles and launches rockets in New Zealand). SpaceX’s rideshare launch business with the Falcon 9 rocket is putting immense pressure on small launch companies like Rocket Lab. However, Beck argues his Electron rocket is a bespoke solution for customers desiring to put their satellite in a specific place at a specific time, a luxury they can’t count on with a SpaceX rideshare.
Ruthlessly efficient … A word that Beck returned to throughout his interview with Ars was “ruthless.” He said Rocket Lab’s success is a result of the company being “ruthlessly efficient and not making mistakes.” At one time, Rocket Lab was up against Virgin Orbit in the small launch business, and Virgin Orbit had access to capital through billionaire Richard Branson. Now, SpaceX is the 800-pound gorilla in the market. “We have a saying here at Rocket Lab that we have no money, so we have to think. We’ve never been in a position to outspend our competitors. We just have to out-think them. We have to be lean and mean.”
Firefly reveals plans for new launch sites. Firefly Aerospace plans to use the state of Virginia-owned launch pad at NASA’s Wallops Flight Facility for East Coast launches of its Alpha small-satellite rocket, Aviation Week reports. The company plans to use Pad 0A for US military and other missions, particularly those requiring tight turnaround between procurement and launch. This is the same launch pad previously used by Northrop Grumman’s Antares rocket, and it’s the soon-to-be home of the Medium Launch Vehicle (MLV) jointly developed by Northrop and Firefly. The launch pad will be configured for Alpha launches beginning in 2025, according to Firefly, which previously planned to develop an Alpha launch pad at Cape Canaveral Space Force Station in Florida. Now, Alpha and MLV rockets will fly from the same site on the East Coast, while Alpha will continue launching from the West Coast at Vandenberg Space Force Base, California.
Hello, Sweden… A few days after the announcement for launches from Virginia, Firefly unveiled a collaborative agreement with Swedish Space Corporation to launch Alpha rockets from the Esrange Space Center in Sweden as soon as 2026. Esrange has been the departure point for numerous suborbital and sounding rocket for nearly 50 years, but the spaceport is being upgraded for orbital satellite launches. A South Korean startup named Perigee Aerospace announced in May it signed an agreement to be the first user of Esrange’s orbital launch capability. Firefly is the second company to make plans to launch satellites from the remote site in northern Sweden. (submitted by Ken the Bin and brianrhurley)
The easiest way to keep up with Eric Berger’s space reporting is to sign up for his newsletter, we’ll collect his stories in your inbox.
China hops closer to reusable rockets. The Shanghai Academy of Spaceflight Technology (SAST), part of China’s apparatus of state-owned aerospace companies, has conducted the country’s highest altitude launch and landing test so far as several teams chase reusable rocket capabilities, Space News reports. A 3.8-meter-diameter (9.2-foot) test article powered by three methane liquid-oxygen engines lifted off from the Gobi Desert on June 23 and soared to an altitude of about 12 kilometers (7.5 miles) before setting down successfully for a vertical propulsive touchdown on landing legs at a nearby landing area. SAST will follow up with a 70-kilometer (43.5-mile) suborbital test using grid fins for better control. A first orbital flight of the new reusable rocket is planned for 2025.
Lots of players … If you don’t exclusively follow China’s launch sector, you should be forgiven for being unable to list all the companies working on new reusable rockets. Late last year, a Chinese startup named iSpace flew a hopper rocket testbed to an altitude of several hundred meters as part of a development program for the company’s upcoming partially reusable Hyperbola 2 rocket. A company named Space Pioneer plans to launch its medium-class Tianlong 3 rocket for the first time later this year. Tianlong 3 looks remarkably like SpaceX’s Falcon 9, and its first stage will eventually be made reusable. China recently test-fired engines for the government’s new Long March 10, a partially reusable rocket planned to become China’s next-generation crew launch vehicle. These are just a few of the reusable rocket programs in China. (submitted by Ken the Bin)
Spanish launch startup invests in Kourou. PLD Space says it is ready to start construction at a disused launch complex at the Guiana Space Center in Kourou, French Guiana. The Spanish launch startup announced this week a 10 million euro ($10.7 million) investment in the launch complex for its Miura 5 rocket, with preparations of the site set to begin “after the summer.” The launch pad was previously used by the French Diamant rocket in the 1970s and is located several miles away from the launch pads used by the European Ariane 6 and Vega rockets. PLD Space is on track to become the first fully commercial company to launch from the spaceport in South America.
Free access to space … Also this week, PLD Space announced a new program to offer space aboard the first two flights of its Miura 5 rocket for free, European Spaceflight reports. The two-stage Miura 5 rocket will be capable of delivering about a half-ton of payload mass into a Sun-synchronous orbit. PLD Space will offer free launch services aboard the first two Miura 5 flights, which are expected to take place in late 2025 and early 2026. The application process will close on July 30, and winning proposals will be announced on November 30. (submitted by Ken the Bin and EllPeaTea)























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}