We have the classic phenomenon where suddenly everyone decided it is good for your social status to say we are in an ‘AI bubble.’
Are these people short the market? Do not be silly. The conventional wisdom response to that question these days is that, as was said in 2007, ‘if the music is playing you have to keep dancing.’
So even with lots of people newly thinking there is a bubble the market has not moved down, other than (modestly) on actual news items, usually related to another potential round of tariffs, or that one time we had a false alarm during the DeepSeek Moment.
So, what’s the case we’re in a bubble? What’s the case we’re not?
People get confused about bubbles, often applying that label any time prices fall. So you have to be clear on what question is being asked.
If ‘that was a bubble’ simply means ‘number go down’ then it is entirely uninteresting to say things are bubbles.
So if we operationalize ‘bubble’ simply means that at some point there is a substantial drawdown in market values (e.g. a 20% drop in the Nasdaq sustained for 6 months) then I would be surprised by this, but the market would need to be dramatically, crazily underpriced for that not to be a plausible thing to happen.
If a bubble means something similar to the 2000 dot com bubble, as in valuations that are not plausible expectations for the net present values of future cash flows? No.
[Standard disclaimer: Nothing on this blog is ever investment advice.]
Before I dive into the details, a time sensitive point of order, that you can skip if you would not consider political donations:
When trying to pass laws, it is vital to have a champion. You need someone in each chamber of Congress who is willing to help craft, introduce and actively fight for good bills. Many worthwhile bills do not get advanced because no one will champion them.
Alex Bores did this with New York’s RAISE Act, an AI safety bill along similar lines to SB 53 that is currently on the governor’s desk. I did a full RTFB (read the bill) on it, and found it to be a very good bill that I strongly supported. It would not have happened without him championing the bill and spending political capital on it.
By far the strongest argument against the bill is that it would be better if such bills were done on the Federal level.
He’s trying to address this by running for Congress in my own distinct, NY-12, to succeed Jerry Nadler. The district is deeply Democratic, so this will have no impact on the partisan balance. What it would do is give real AI safety a knowledgeable champion in the House of Representatives, capable of championing good bills.
Eric Nayman makes an extensive case for considering donating to Alex Bores today, in his first 24 hours, as donations in the first 24 hours are extremely valuable. Sonnet 4.5 estimates that in this case, a donation on day one is worth about double what it would be worth later. If you do decide to donate, they prefer that you use this link to ensure the donation gets fully registered today.
As always, remember while considering this that political donations are public.
(Note: I intend to remove this announcement from this post after the 24 hour window closes, and move it to AI #139.)
Sagarika Jaisinghani (Bloomberg): A record share of global fund managers said artificial intelligence stocks are in a bubble following a torrid rally this year, according to a survey by Bank of America Corp.
About 54% of participants in the October poll indicated tech stocks were looking too expensive, an about-turn from last month when nearly half had dismissed those concerns. Fears that global stocks were overvalued also hit a peak in the latest survey.
So a month ago things most people thought things were fine and now it’s a bubble?
This is a very light bubble definition, as these things go.
Nothing importantly bearish happened in that month other than bullish deals, so presumably this is a ‘circular deals freak us out’ shift in mood? Or it could be a cascade effect.
There is definitely reason for concern. If you remove the label ‘bubble’ and simply say ‘AI’ then the quote from Deutsche Bank below is correct, as AI is responsible for essentially all economic growth. Also you can mostly replace ‘US’ with ‘world.’
Unusual Whales: “The AI bubble is the only thing keeping the US economy together,” Deutsche Bank has said per TechSpot.
Not quite, at this size you need some doubt involved. But the basic answer is yes.
Roon: one reason to disbelief in a sizeable bubble is when the largest financial institutions in the world are openly calling it that.
Jon Stokes: I disagree. I was in my early 20’s during the dotcom bubble and was in tech, and everyone everywhere knew it was a bubble — from the banks to the VCs down to the individual programmers in SF. Everyone talked about it openly in the last ~1yr of it, but the numbers kept going up.
I don’t think this is Dotcom 2.0 but I think it’s possible the market is getting ahead of itself. That said, I also lived through the cloud “bubble” which turned out to not be a bubble at all — I even wrote my own contributes to “are we in a bubble?” literature in like 2012. Anyone who actually traded on the idea that the cloud buildout was a bubble lost out bigtime.
Every time there’s a big new infra buildout there’s bubble talk.
My point is that is very possible to have a bubble that everyone everywhere knows is a bubble, yet it keeps on bubbling because nobody wants to miss the action & everyone thinks they can time an exit. “Enjoy the party, but dance close to the exits” was the slogan back then.
It is definitely possible to get into an Everybody Knows situation with a bubble, for various reasons, both when it is and when it isn’t actually a bubble. For example, there’s Bitcoin, and Bitcoin, and Bitcoin, and Bitcoin, but there’s also Bitcoin.
Is it evidence for or against a bubble when everyone says it’s a bubble?
My gut answer is it depends on who is everyone.
If everyone is everyone working in the industry? Then yeah, evidence for a bubble.
If everyone is everyone at the major economic institutions? Not so much.
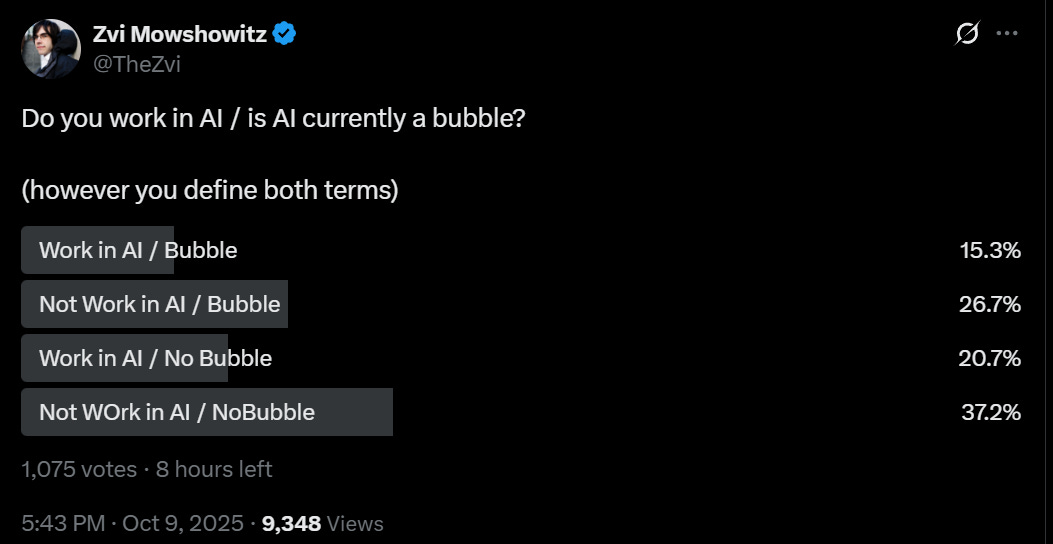
So I decided to check.
There was essentially no correlation, with 42.5% of AI workers and 41.7% of others saying there is a bubble, and that’s a large percentage, so things are certainly somewhat concerning. It certainly seems likely that certain subtypes of AI investment are ‘in a bubble’ in the sense that investors in those subtypes will lose money, which you would expect in anything like an efficient market.
In particular, consensus seems to be, and I agree with it (reminder: not investment advice), that investment in ‘companies with products in position to get steamrolled by OpenAI and other frontier labs’ are as a group not going to do well. If you want to call that an ‘AI bubble’ you can, but that seems net misleading. I also wouldn’t be excited to short that basket, since you’re exposed if even one of them hits it big. Remember that if you bought a tech stock portfolio at the dot com peak, you still got Amazon.
Whereas if you had a portfolio of ‘picks and shovels’ or of the frontier labs themselves, that still seems to me like a fine place to bet, although it is no longer a ‘I can’t believe they’re letting me buy at these prices, this is free money’ level of fine. You now have to actually have beliefs about the future and an investment thesis.
Noah Smith speculates on bubble causes and types when it comes to AI.
Noah Smith: An AI crash isn’t certain, but I think it’s more likely than people think.
Looking at the historical examples of railroads, electricity, dotcoms, and housing can help us understand what an AI crash would look like.
A burning question that’s on a lot of people’s minds right now is: Why is the U.S. economy still holding up? The manufacturing industry is hurting badly from Trump’s tariffs, the payroll numbers are looking weak, and consumer sentiment is at Great Recession levels.
… Another possibility is that tariffs are bad, but are being canceled out by an even more powerful force — the AI boom.
You could have a speculative bubble, or an extrapolative bubble, or simply a big mistake about the value of the tech. He thinks if it is a bubble it would be of the later type, proposing we use Bezos’ term ‘industrial bubble.’
Noah Smith: … When we look at the history of industrial bubbles, and of new technologies in general, it becomes clear that in order to cause a crash, AI doesn’t have to fail. It just has to mildly disappoint the most ardent optimists.
I don’t think that’s quite right. The market reflects a variety of perspectives, and it will almost always be way below where the ardent optimists would place it. The ardent optimists are the rock with the word ‘BUY!’ written on it.
What is right is that if AI over some time frame disappoints relative to expectations, sufficiently to shift forward expectations downward from their previous level, that would cause a substantial drop in prices, which could then break momentum and worsen various positions, causing a larger drop in prices.
Thus, we could have AI ultimately having a huge economic impact and ultimately being fully transformative (maybe killing everyone, maybe being amazingly great), and have nothing go that wrong along the way, but still have what people at the time would call ‘the bubble bursting.’
Indeed, if the market is at all efficient, there is a lot of ‘upside risk’ of AI being way more impactful than suggested by the market price, which means there has to be a corresponding downside risk too. Part of that risk is geopolitical, an anti-AI movement could rise, or the supply chain could be disrupted by tariff battles or a war over Taiwan. By traditional definitions of ‘bubble,’ that means a potential bubble.
Ethan Mollick: I don’t have much to add to the bubble discussion, but the “this time is different” argument is, in part, based on the sincere belief of many at the AI labs that there is a race to superintelligence & the winner gets,.. everything.
It is a key dynamic that is not discussed much.
You don’t have to believe it (or think this is a good idea), but many of the AI insiders really do. Their public statements are not much different than their private ones. Without considering that zero sum dimension, a lot of what is happening in the space makes less sense.
Even a small chance of a big upside should mean a big boost to valuation. Indeed that is the reason tech startups are funded and venture capital firms exist. If you don’t get the fully transformational level of impact, then at some point value will drop.
Consider the parallel to Bitcoin, and in thinking there is some small percentage chance of becoming ‘digital gold’ or even the new money. If you felt there was no way it could fall by a lot from any given point in time, or even if you were simply confident that it was probably not going to crash, it would be a fantastic screaming buy.
AI also has to retain expectations that providers will be profitable. If AI is useful but it is expected to not provide enough profits, that too can burst the bubble.
Matthew Yglesias: Key point in here from @Noahpinion — even if the AI tech turns out to be exactly as promising as the bulls think, it’s not totally clear whether this would mean high margin businesses.
A slightly random example but passenger jetliners have definitely worked out as a technology, tons of people use them and they are integral to the whole world economy. But the combined market cap of Boeing + Airbus is unimpressive.
Jetliners seem a lot more important and impressive than the idea of a big box building supply store, but in terms of market cap Home Depot > Boeing + Airbus. Technology is hard but then business is also hard.
Sam D’Amico: AI is going to rock but we may have a near-term capex bubble like the fiber buildout during the dotcom boom.
Matthew Yglesias writes more thoughts here, noting that AI is propping up the whole economy and offering reasons some people believe there’s a bubble and also reasons it likely isn’t one, and especially isn’t one in the pure bubble sense of cryptocurrency or Beanie babies, there’s clearly a there there.
To say confidently that there is no bubble in AI is to claim, among other things, that the market is horribly inefficient, and that AI assets are and will remain dramatically underpriced but reliably gain value as people gain situational awareness and are mugged by reality. This includes the requirement that the currently trading AI assets will be poised to capture a lot of value.
Alternatively, how about the possibility that there could be a crash for no reason?
Simeon: Agreed with Noah here. People underestimate the odds of a crash, and things like the OA x AMD deal make such things more likely. It just takes a sufficient number of people to be scared at the same time.
Remember the market reaction to DeepSeek? It can be irrational.
The DeepSeek moment is sobering, since the AI market was down quite a lot on news that should have been priced in and if anything should have made prices go up. What is to stop a similar incorrect information cascade from happening again? Other than a potential ‘Trump put’ or Fed put, very little.
Derek Thompson provides his best counterargument, saying AI probably isn’t a bubble. He also did an episode on this for the Plain English podcast with Azeem Azhar of Exponential View to balance his previous episode from September 23 on ‘how the AI bubble could burst.’
Derek Thompson: And yet, look around: Is anybody actually acting as if AI is a bubble?
… Everyone claims that they know the music is ending soon, and yet everybody is still dancing along to the music.
Well, yeah, when there’s a bubble everyone goes around saying ‘there’s a bubble’ but no one does anything about it, until they do and then there’s no bubble?
As Tyler Cowen sometimes asks, are you short the market? Me neither.
Derek breaks down the top arguments for a bubble.
-
Lofty valuations for companies with no clear path to profit.
-
Unprecedented spending on an unproven business.
-
A historic chasm between capex spending and revenue.
-
An eerie level of financial opacity.
-
A byzantine level of corporate entanglement.
A lot of overlap here. We have a lot of money being invested in and spent on AI, without much revenue. True that. The AI companies all invest in and buy from each other, at a level that yeah is somewhat suspicious. Yeah, fair. The chips are only being discounted on five year horizons and that seems a bit long? Eh, that seems fine to me, older chips are still useful as long as demand exceeds supply.
So why not a bubble? That part is gated, but his thread lays out the core responses. One, the AI companies look nothing like the joke companies in the dot com bubble.
Two, the AI companies need AI revenues to grow 100%-200% a year, and that sounds like a lot, but so far you’re seeing even more than that.
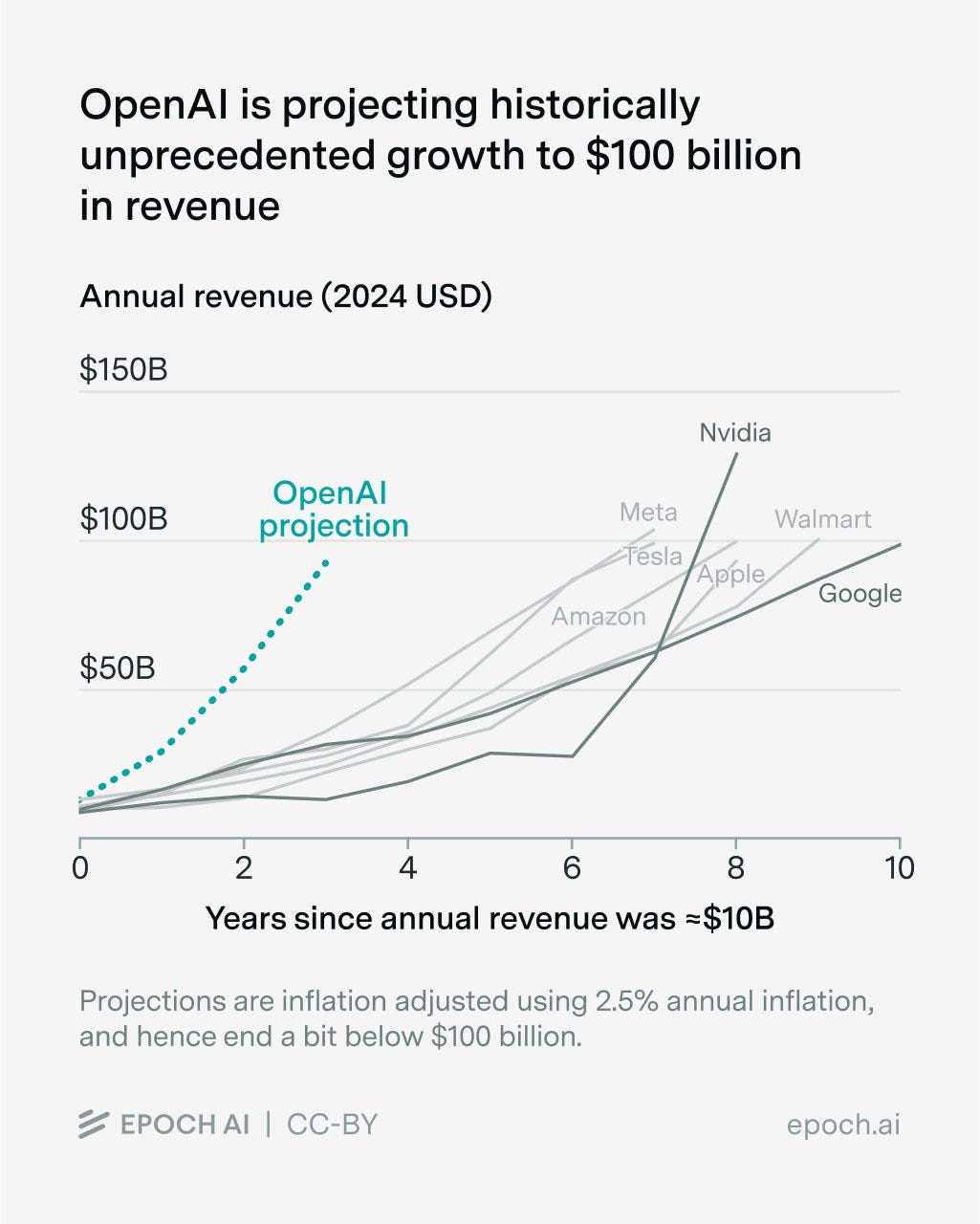
Epoch AI: One way bubbles pop: a technology doesn’t deliver value as quickly as investors bet it will. In light of that, it’s notable that OpenAI is projecting historically unprecedented revenue growth — from $10B to $100B — over the next three years.
OpenAI’s revenue growth has been extremely impressive: from <$1B to >$10B in only three years. Still, a few other companies have pulled off similar growth.
We found four such US companies in the past fifty years. Of these, only Google went on to top $100B in revenue.
Peter Wildeford: OpenAI is claiming they will double revenue three years in a row… this is historically unprecedented, but may be possible (so far they are 3x/year and NVIDIA has done 2x/yr lately)
But OpenAI has also projected revenue of $100B in 2028. We found seven companies which achieved revenue growth from $10B to $100B in under a decade.
None of them did it in six years, let alone three.
As Matt Levine says, OpenAI has a business model now, because when you need debt investors you need to have a business plan. This one strikes a balance between ‘good enough to raise money’ and ‘not so good no one will believe it.’ Which makes it well under where I expect their revenue to land.
Frankly, OpenAI is downplaying their expectations because if they used their actual projections then no one would believe them, and they might get sued if things didn’t work out. The baseline scenario is that OpenAI (and Anthropic) blow the projections out of the water.
Martha Gimbel: Ok not the main point of [Thompson’s] article but I love this line: “The whole thing is vaguely Augustinian: O Lord, make me sell my Nvidia position and rebalance toward consumer staples, but not yet.”
Timothy Lee thinks it’s probably ‘not a bubble yet,’ partly citing Thompson and partly because we are seeing differentiation on which models do tasks best. He also links to the worry that there might be no moat, as fast follows offer the same service much cheaper and kill your margin, since your product might be only slightly better.
The thing about AI is that it might in total cost a lot, but in exchange you get a ton. It doesn’t have to be ten times better to have the difference be a big deal. For most use cases of AI, you would be wise to pay twice the price for something 10% better, and often wise to pay 10 or 100 times as much. Always think absolute cost, not relative.
Vinay Sridhar: What finally caught my attention was this stat from an NYT article by Natasha Sarin (via Marginal Revolution): “To provide some sense of scale, that means the equivalent of about $1,800 per person in America will be invested this year on AI”. That is a bucketload of spending.
It is, but is it? I spend more than that on one of my AI subscriptions, and get many times that much value in return. Thinking purely in terms of present day concrete benefits, when I ask ‘how many different use cases of AI are providing me $1,800 in value?’ I can definitely include taxes and accounting, product evaluation and search, medical help, analysis of research papers, coding and general information and search. So that’s at least six.
Similarly, does this sound like a problem, given the profit margins of these companies?
Vinay Sridhar: Hyperscalers (Microsoft, Amazon, Alphabet and Meta) historically ran capex at 11-16% of revenue. Today they’re at 22%, with revenue YoY growth in the 15-25% range (ex Nvidia) – capex spending is dramatically outpacing revenue growth. The four major hyperscalers are spending approximately $320 billion combined on AI infrastructure in 2025 – with public statements on how this will likely continue in the coming years.
Similarly, Vinay notes that the valuations are only somewhat high.
Current valuations, while elevated, remain “much lower” than prior tech bubbles. The Nasdaq’s forward P/E ratio is ~28X today. At the 2000 peak, it exceeded 70X. Even in 2007 before the financial crisis, tech valuations were higher relative to earnings than they are now.
Looking more closely, the MAG7 — who are spending the majority of this capex — has a blended P/E of ~32X — expensive, as Coatue’s Laffont brothers said in June, but not extreme relative to past tech bubbles.
That’s a P/E ratio, and all this extra capex spending if anything reduces short term earnings. Does a 28x forward P/E ratio sound scary in context, with YoY growth in the 20% range? It doesn’t to me. Sure, there’s some downside, but it would be a dramatic inefficiency if there wasn’t.
Vinay offers several other notes as well.
One thing I find confusing is all the ‘look how fast the chips will lose value’ arguments. Here’s Vinay’s supremely confident claims, as another example of this:
Vinay Sridhar: 7. GPU Depreciation Schedules Don’t Match Reality
Nvidia now unveils a new AI chip every year instead of every two years. Jensen Huang said in March that “when Blackwell starts shipping in volume you couldn’t give Hoppers away”.
Meanwhile, companies keep extending depreciation schedules. Microsoft: 4 to 6 years (2022). Alphabet: 4 to 6 years (2023). Amazon and Oracle: 5 to 6 years (2024). Meta: 5 to 5.5 years (January 2025). Amazon partially reversed course in January 2025, moving some assets back to 5 years, noting this would cut operating profit by $700m.
The Economist analyzed the impact: if servers depreciate over 3 years instead of current schedules, the AI big five’s combined annual pre-tax profit falls by $26bn (8% of last year’s total). Over 2 years: $1.6trn market cap hit. If you take Huang literally at 1 year, this implies $4trn, one-third of their collective worth. Barclays estimated higher depreciation costs would shave 5-10% from earnings per share.
Hedgie takes a similar angle, calling the economics unsustainable because the lifespan of data center components is only 3-10 years due to rapid technological advances.
Hedgie: Kupperman originally assumed data center components would depreciate over 10 years, but learned from two dozen senior professionals that the actual lifespan is just 3-10 years due to rapid technology advances. His revised calculations show the industry needs $320-480 billion in revenue just to break even on 2025 data center spending alone. Current AI revenue sits around $20 billion annually.
What strikes me most is that none of the senior data center professionals Kupperman spoke with understand how the financial math works either.
No one I have seen is saying that chip capability improvements are accelerating dramatically. If that is the case we need to update our timelines.
When Nvidia releases a new chip every year, that doesn’t mean they do the 2027 chip in 2026 and then do the 2029 chip in 2027. It means they do the 2027 chip in 2027, and before that do the best chip you can do in 2026, and it also means Nvidia is good at marketing and life is coming at them fast.
Huang’s statement about free hoppers is obviously deeply silly, and everyone knows not to take such Nvidia statements seriously or literally. The existence of new better chips does not invalidate older worse chips unless supply exceeds demand by enough that the old chips cost more to run then the value they bring.
That’s very obviously not going to happen over three years let alone one or two. You can do math on the production capacity available.
If the marginal cost of hoppers in 2028 was going to be approximately zero, what does that imply?
By default? Stop thinking about capex depreciation and start thinking about whether this means we get a singularity in 2028, since you can now scale compute as long as you have power. Also, get long China, since they have unlimited power generation.
If that’s not why, then it means AI use cases turned out to be severely limited, and the world has a large surplus of compute and not much to do with it.
It kind of has to be one or the other. Neither seems plausible.
I see not only no sign of overcapacity, I see signs of undercapacity, including a scramble for every chip people can get and compute being a limiting factor on many labs in practice right now, including OpenAI and Anthropic. The price of compute has recently been rising, not falling, including the price for renting older chips.
Dave Friedman looked into the accounting here, ultimately not seeing this as a solvency or liquidity issue, but he thinks there could be an accounting optics issue.
Could recent trends reverse, and faster than expected depreciations and ability to charge for older chips cause problems for the accounting in data centers? I mean, sure, that’s obviously possible, if we actually produce enough better chips, or demand sufficiently lags expectations, or some combination thereof.
This whole question seems like a strange thing for those investing hundreds of billions and everyone trading the market to not have priced into their plans and projections? Yes, current OpenAI revenue is on the order of $20 billion, but if you project that out over 3-10 years, that number is going to be vastly higher, and there are other companies.
I mostly agree with Charles that the pro-bubble arguments are remarkably weak, given the amount of bubble talk we are seeing, and that when you combine these two facts it should move you towards there not being a bubble.
Unlike Charles, I am not about to use leverage. I consider leverage in personal investing to be reserved for extreme situations, and a substantial drop in prices is very possible. But I definitely understand.
Charles: There have been so many terrible arguments for why we’re in an AI bubble lately, and so few good ones, that I’ve been convinced the appropriate update is in the “not a bubble” direction and increased my already quite long position.
Fwiw that looks like now being 1.4x leveraged long a mix of about 50% index funds and 50% specific bets (GOOG, TSMC, AMZN the biggest of those).
Most of what changed, I think, is that there were a bunch of circular deals done in close succession, and when combined with the exponential growth expectations for AI and people’s lack of understanding the technology and what it will be able to do, and the valuations approaching the point where one can question there being any room to grow, this reasonably triggered various heuristics and freaked people out.
If we define a bubble narrowly as ‘we see a Nasdaq price decline of 20% sustained for 6 months’ I would give that on the order of 25% to happen within the next few years, including as part of a marketwide decline in prices. It has happened to the wider market as recently as 2022, and about 5 times in the last 50 years.
If a decline does happen, I predict I will probably use that opportunity to buy more.
That does not have to be true. Perhaps there will have been large shifts in anticipated future capabilities, or in the competitive landscape and ability to capture profits, or the general economic conditions, and the drop will be fully justified and reflect AI slowing down.
But most of the time this will not be what happened, and the drop will not ultimately have much effect, although it would presumably slow down progress slightly.
Connor Leahy: I want to preregister the following opinion:
I think it’s plausible, but by no means guaranteed, that we could see a massive financial crisis or bubble pop affecting AI in the next year.
I expect if this happens, it will be mostly for mundane economic reasons (overleveraged markets, financial policy of major nations, mistiming of bets even by small amounts and good ol’ fraud), not because the technology isn’t making rapid progress.
I expect such a crisis to have at most modest effects on timelines to existentially dangerous ASI being developed, but will be used by partisans to try and dismiss the risk.
Sadly, a bunch of people making poorly thought through leveraged bets on the market tells you little about underlying object reality of how powerful AI is or soon will be.
Do not be fooled by narratives.