A UK regulator today fined Reddit £14.5 million ($19.6 million) for not verifying the ages of users. The UK Information Commissioner’s Office (ICO) alleged that the failure to check ages resulted in Reddit illegally using children’s personal information.
“Our investigation found that Reddit failed to apply any robust age assurance mechanism and therefore did not have a lawful basis for processing the personal information of children under the age of 13… These failures meant Reddit was using children’s data unlawfully, potentially exposing them to inappropriate and harmful content,” an ICO press release said.
The ICO findings are based on Reddit’s actions prior to its July 2025 rollout of a system that verifies UK users’ ages before letting them view adult content. But the ICO said it is still concerned about Reddit’s post-July 2025 system because the company relies on users to declare their ages when opening an account.
Reddit today said it will appeal the fine and criticized the ICO for demanding more collection of private information. “Reddit doesn’t require users to share information about their identities, regardless of age, because we are deeply committed to their privacy and safety,” Reddit said in a statement provided to Ars. “The ICO’s insistence that we collect more private information on every UK user is counterintuitive and at odds with our strong belief in our users’ online privacy and safety. We intend to appeal the ICO’s decision.”
Reddit pointed to its privacy policy, which says, “We collect minimal information that can be used to identify you by default. If you want to just browse, you don’t need an account. If you want to create an account to participate in a subreddit, we don’t require you to give us your real name. We don’t track your precise location. You can even browse anonymously. You can share as much or as little about yourself as you want when using Reddit.”
Prequel series is just great storytelling, reminding GoT fans why they loved the original so much.
HBO has another critically acclaimed hit with A Knight of the Seven Kingdoms, based on George R.R. Martin’s Tales of Dunk and Egg novellas, and it deserves every bit of the praise heaped upon it. The immensely satisfying first season wrapped with last night’s finale, dealing with the tragedy of the penultimate episode and setting the stage for the further adventures of Dunk and Egg. House of the Dragon is a solid series, but Knight of the Seven Kingdoms has reminded staunch GoT fans of everything they loved about the original series in the first place.
(Spoilers below, but no major reveals until after the second gallery. We’ll give you a heads up when we get there.)
A Knight of the Seven Kingdoms adapts the first novella in the series, The Hedge Knight, and is set more than 50 years after the events of House of the Dragon. Dunk (Peter Claffey) is a lowly hedge knight who has just buried his aged mentor, Ser Arlan of Pennytree (Danny Webb). Ser Arlan was perhaps not the kindest of mentors and often stone drunk, but at least he was hung like the proverbial horse—as viewers discovered in a full-frontal moment that instantly went viral. Lacking any good employment options, Dunk decides to enter a local tournament, since he has inherited Ser Arlan’s sword, shield, and three horses.
En route, he stops at an inn, where a bald-headed child who goes by Egg (Dexter Sol Ansell) asks if he can be Dunk’s squire. Dunk refuses at first, but Egg follows him and Dunk reluctantly agrees. He christens himself Ser Duncan the Tall but finds he cannot enter the tournament without a knight or lord to vouch for him—someone who remembered Ser Arlan. Dunk strikes out again and again, until he meets Prince Baelor “Breakspear” Targaryen (Bertie Carvel), son of King Daeron II and heir to the Iron Throne. Baelor remembers Arlan and vouches for Dunk.
As they await their turn at the tournament, Dunk and Egg are drafted into a friendly game of tug-of-war by Ser Lyonel Baratheon (Daniel Ings), aptly known as the “Laughing Storm.” They attend a puppet show starring the Dornish-borne Tanselle (Tanzyn Crawford); Egg is enthralled by the showmanship, while Dunk is enamored of Tanselle. And the pair bond further on the first day of the tournament, cheering with excitement at the jousting knights.
But this is Westeros, and nobody’s truly happy for long. Prince Aerion “Brightflame” Targaryen (Finn Bennett)—nephew to Baelor, son of Prince Maekar “The Anvil” Targaryen (Sam Spruell)—has also entered the tournament, and he’s the spoiled and vicious black sheep of the family. His lack of honor is firmly established when he deliberately lances his opponent’s horse to dismount him, effectively ending the day’s festivities. It’s only a matter of time before Dunk runs afoul of Aerion.
A humble hedge knight
A squire and his hedge knight: Dexter Sol Ansell plays “Egg” (l) and Peter Claffey plays Dunk (r). YouTube/HBO
A Knight of the Seven Kingdoms is just plain great storytelling, with excellent pacing, unexpected twists, and a much lighter tone than its predecessors, which makes the inevitable tragic moments that much more powerful. The episodes are short, and there are only six of them, so there is no padding whatsoever, yet somehow the main characters are fully drawn and compelling. The Game of Thrones franchise has always excelled at spectacular battle sequences on a grand scale. Here we get the same heart-pounding excitement on the smaller scale of jousting at a country tournament. The clever camerawork makes the viewer feel they’re in the center of the action, often showing the combatants’ viewpoints through the slits in their helmets.
The casting is inspired. Claffey, a former rugby player turned actor, is Dunk incarnate: tall and strong with a heart as big as his frame and a naively earnest belief in the knight’s code of honor. Ings’ Lyonel Baratheon oozes ribald charisma—he’s very fond of bawdy tavern songs—and one can see hints of what Game of Thrones’ King Robert Baratheon (Mark Addy) might have been like as a young and handsome warrior lord (before he got old and fat and fatefully encountered that wild boar). Carvel infuses Baelor with quiet strength and dignity, while Bennett is suitably menacing as Aerion to give us a colorful villain who’s fun to hate.
Yet young Ansell, at just 11 years old, outshines them all as Egg, bringing a perfect blend of intelligence, spunk, vulnerability, and disquieting maturity to his performance. Ansell had minor roles in the British soap Emmerdale and as young Coriolanus Snow in The Hunger Games: Ballad of Songbirds and Snakes, but this is his first starring role. May there be many more. His chemistry with Claffey makes you believe in Dunk and Egg’s friendship and root for them to succeed. It’s a wonderful dynamic. But can their bond withstand the big reveal of Egg’s true identity? (Of course it can, but not before a tearful, heartfelt clearing of the air.)
(WARNING: Major spoilers below. Stop reading now if you haven’t finished watching the series or haven’t read the books.)
A “trial by seven”
Dunk and Egg face Baelor after Dunk struck Prince Aerion (who totally had it coming). HBO
As any fan of the books can tell you, Egg is short for Aegon—Aegon Targaryen, Aerion’s younger brother, who ran away after his other older brother, Prince Daeron (Henry Ashton), refused to enter the tournament. Egg was so looking forward to being his squire and latched onto Dunk instead, but he can’t protect him from Aerion’s wrath. Dunk ends up in a prison cell and must prove his innocence in fine Westeros fashion: trial by combat, specifically a trial by seven, which means he needs six other knights to fight with him. Dunk is one man short until Baelor unexpectedly steps in as the seventh.
And that brings us to the seismic events of the penultimate episode (a GoT tradition). The joust is brutal. Aerion is the more skilled fighter, but Dunk has the size and strength advantage, so each inflicts significant bodily damage on the other. And just when you think Dunk has lost, he rises again and defeats Aerion, forcing him to withdraw his accusation. Dunk’s team suffers a couple of casualties, but everyone is relieved that Baelor has survived.
Dunk kneels and swears his loyalty in gratitude, which is when Ser Raymun (Shaun Thomas) notices the prince’s crushed helmet. Baelor has been mortally wounded by his own brother Maekar’s mace. He collapses and dies as a sobbing Dunk cradles his body, deftly setting up the season finale, in which everyone must deal with the aftermath.
The heir to the Iron Throne is dead—a good man who would have been an excellent king. A humble hedge knight has somehow changed the future of Westeros, and chances are it won’t be for the better. So what does Dunk do now? Ser Lyonel offers him a place at Storm’s End, but Dunk refuses, believing that he will just bring bad luck. Maekar offers him a position at the Targaryen Summerhall castle so that Egg can be his squire; his influence might actually prevent Egg from turning into a jerk like Aerion (whose penance is exile to the Free Cities). Again, Dunk declines, to Egg’s chagrin. But when Dunk leaves town to strike out on his own as an itinerant knight, Egg runs away again and joins him.
There are, of course, tons of Easter eggs for diehard Westeros fans, but one is particularly worth mentioning: a fortune-teller tells Egg that he will be king one day but die horribly in flames. “Why would she say that?” an understandably upset Egg asks. It’s a reference to a bit of Westeros lore only mentioned in passing in Martin’s many books: the tragedy at Summerhall. Egg becomes King Aegon V with Dunk heading up the Kingsguard. They were both killed by wildfire (along with many others), and Summerhall was destroyed in what was most likely Aegon’s attempt to hatch new dragons out of seven surviving dragon eggs. So not even Dunk and Egg get a truly happy ending.
All episodes of A Knight of the Seven Kingdoms are now streaming on HBO. It was renewed for a second season—which will be based on The Sworn Sword—before the first episode even aired, and I eagerly await what comes next for our unlikely heroes.
Jennifer is a senior writer at Ars Technica with a particular focus on where science meets culture, covering everything from physics and related interdisciplinary topics to her favorite films and TV series. Jennifer lives in Baltimore with her spouse, physicist Sean M. Carroll, and their two cats, Ariel and Caliban.
The helium system on the SLS upper stage—officially known as the Interim Cryogenic Propulsion Stage (ICPS)—performed well during both of the Artemis II countdown rehearsals. “Last evening, the team was unable to get helium flow through the vehicle. This occurred during a routine operation to repressurize the system,” Isaacman wrote.
The Space Launch System rocket emerges from the Vehicle Assembly Building to begin the rollout to Launch Pad 39B last month.
Credit: Stephen Clark/Ars Technica
The Space Launch System rocket emerges from the Vehicle Assembly Building to begin the rollout to Launch Pad 39B last month. Credit: Stephen Clark/Ars Technica
Another molecule, another problem
Helium is used to purge the upper stage engine and pressurize its propellant tanks. The rocket is in a “safe configuration,” with a backup system providing purge air to the upper stage, NASA said in a statement.
NASA encountered a similar failure signature during preparations for launch of the first SLS rocket on the Artemis I mission in 2022. On Artemis I, engineers traced the problem to a failed check valve on the upper stage that needed replacement. NASA officials are not sure yet whether the helium issue Friday was caused by a similar valve failure, a problem with an umbilical interface between the rocket and the launch tower, or a fault with a filter, according to Isaacman.
In any case, technicians are unable to reach the problem area with the rocket at the launch pad. Inside the VAB, ground teams will extend work platforms around the rocket to provide physical access to the upper stage and its associated umbilical connections.
NASA said moving into preparations for rollback now will allow managers to potentially preserve the April launch window, “pending the outcome of data findings, repair efforts, and how the schedule comes to fruition in the coming days and weeks.”
It’s not clear if NASA will perform another fueling test on the SLS rocket after it returns to Launch Pad 39B, or whether technicians will do any more work on the delicate hydrogen umbilical near the bottom of the rocket responsible for recurring leaks during the Artemis I and Artemis II launch campaigns. Managers were pleased with the performance of newly-installed seals during Thursday’s countdown demonstration, but NASA officials have previously said vibrations from transporting the rocket to and from the pad could damage the seals.
One of the US government’s top scientific research labs is taking steps that could drive away foreign scientists, a shift lawmakers and sources tell WIRED could cost the country valuable expertise and damage the agency’s credibility.
The National Institute of Standards and Technology (NIST) helps determine the frameworks underpinning everything from cybersecurity to semiconductor manufacturing. Some of NIST’s recent work includes establishing guidelines for securing AI systems and identifying health concerns with air purifiers and firefighting gloves. Many of the agency’s thousands of employees, postdoctoral scientists, contractors, and guest researchers are brought in from around the world for their specialized expertise.
“For weeks now, rumors of draconian new measures have been spreading like wildfire, while my staff’s inquiries to NIST have gone unanswered,” Zoe Lofgren, the top Democrat on the House Committee on Science, Space, and Technology, wrote in a letter sent to acting NIST Director Craig Burkhardt on Thursday. April McClain Delaney, a fellow Democrat on the committee, cosigned the message.
Lofgren wrote that while her staff has heard about multiple rumored changes, what they have confirmed through unnamed sources is that the Trump administration “has begun taking steps to limit the ability of foreign-born researchers to conduct their work at NIST.”
The congressional letter follows a Boulder Reporting Lab article on February 12 that said international graduate students and postdoctoral researchers would be limited to a maximum of three years at NIST going forward, despite many of them needing five to seven years to complete their work.
A NIST employee tells WIRED that some plans to bring on foreign workers through the agency’s Professional Research and Experience Program have recently been canceled because of uncertainty about whether they would make it through the new security protocols. The staffer, who spoke on the condition of anonymity because they were not authorized to speak to the media, says the agency has yet to widely communicate what the new hurdles will be or why it believes they are justified.
On Thursday, the Colorado Sun reported that “noncitizens” lost after-hours access to a NIST lab last month and could soon be banned from the facility entirely.
Jennifer Huergo, a spokesperson for NIST, tells WIRED that the proposed changes are aimed at protecting US science from theft and abuse, echoing a similar statement issued this week to other media outlets. Huergo declined to comment on who needs to approve the proposal for it to be finalized and when a decision will be made. She also didn’t immediately respond to a request for comment on the lawmakers’ letter.
Preventing foreign adversaries from stealing valuable American intellectual property has been a bipartisan priority, with NIST among the agencies in recent years to receive congressional scrutiny about the adequacy of its background checks and security policies. Just last month, Republican lawmakers renewed calls to put restrictions in place preventing Chinese nationals from working at or with national labs run by the Department of Energy.
But Lofgren’s letter contends that the rumored restrictions on non-US scientists at NIST go beyond “what is reasonable and appropriate to protect research security.” The letter demands transparency about new policies by February 26 and a pause on them “until Congress can weigh in on whether these changes are necessary at all.”
The potential loss of research talent at NIST would add to a series of other Trump administration policies that some US tech industry leaders have warned will dismantle the lives of immigrant researchers already living in the US and hamper economic growth. Hiking fees on H-1B tech visas, revoking thousands of student visas, and carrying out legally dubious mass deportations all stand to push people eager to work on science and tech research in the US to go elsewhere instead. The Trump administration has also announced plans to limitpost-graduation job training for international students.
Pat Gallagher, who served as the director of NIST from 2009 to 2013 under President Barack Obama, says the changes could erode trust in the agency, which has long provided the technical foundations that industry and governments around the world rely on. “What has made NIST special is it is scientifically credible,” he tells WIRED. “Industry, universities, and the global measurement community knew they could work with NIST.”
Like much of the federal government, NIST has been in turmoil for most of the past year. Parts of it were paralyzed for months as rumors of DOGE cutsspread. Ultimately, the agency lost hundreds of its thousands of workers to budget cuts, with further funding pressure to come.
As of a couple of years ago, NIST welcomed 800 researchers on average annually from outside the US to work in its offices and collaborate directly with staff.
Lofgren expressed fear that rumors may be enough to scare away researchers and undermine US competitiveness in vital research. “Our scientific excellence depends upon attracting the best and brightest from around the world,” she wrote in the letter.
Economists estimated more than $175 billion may need to be refunded.
The Supreme Court ruled Friday that Donald Trump was not authorized to implement emergency tariffs to ostensibly block illegal drug flows and offset trade deficits.
It’s not immediately clear what the ruling may mean for businesses that paid various “reciprocal” tariffs that Trump changed frequently, raising and lowering rates at will during tense negotiations with the United States’ biggest trade partners.
Divided 6-3, Supreme Court justices remanded the cases to lower courts, concluding that the International Emergency Economic Powers Act (IEEPA) does not give Trump power to impose tariffs.
Chief Justice John Roberts wrote the opinion and was joined by Justices Neil Gorsuch, Amy Coney Barrett, Elena Kagan, Sonia Sotomayor, and Ketanji Brown Jackson. They concluded that Trump could not exclusively rely on IEEPA to impose tariffs “of unlimited amount and duration, on any product from any country” during peacetime.
Only Congress has the power of the purse, Roberts wrote, and the few exceptions to that are bound by “explicit terms and subject to strict limits.”
“Against that backdrop of clear and limited delegations, the Government reads IEEPA to give the President power to unilaterally impose unbounded tariffs and change them at will,” Roberts wrote. “That view would represent a transformative expansion of the President’s authority over tariff policy. It is also telling that in IEEPA’s half century of existence, no President has invoked the statute to impose any tariffs, let alone tariffs of this magnitude and scope. That ‘lack of historical precedent,’ coupled with ‘the breadth of authority’ that the President now claims, suggests that the tariffs extend beyond the President’s ‘legitimate reach.’”
Back in November, analysts suggested that the Supreme Court ruling against Trump could force the government to issue refunds of up to $1 trillion. This morning, a new estimate from economists reduced that number, Reuters reported, estimating that more than $175 billion could be “at risk of having to be refunded.”
Ruling disrupts Trump plan to collect $900 billion
Trump lost primarily because IEEPA does not explicitly reference “tariffs” or “duties,” instead only giving Trump power to “regulate” “importation”—the two words in the statute that Trump tried to argue showed that Congress clearly authorized his power to impose tariffs.
But the court did not agree that Congress intended to give the president “the independent power to impose tariffs on imports from any country, of any product, at any rate, for any amount of time,” Roberts wrote. “Those words cannot bear such weight,” particularly in peacetime. “The United States, after all, is not at war with every nation in the world.”
Specifically, Trump failed to “identify any statute in which the power to regulate includes the power to tax,” Roberts wrote. And the majority of justices remained “skeptical” that in “IEEPA alone,” Congress intended to hide “a delegation of its birth-right power to tax within the quotidian power to ‘regulate.’”
“A contrary reading would render IEEPA partly unconstitutional,” Roberts wrote.
According to the majority, siding with Trump would free the president to “issue a dizzying array of modifications” to tariffs at will, “unconstrained by the significant procedural limitations in other tariff statutes.” The only check to that unprecedented power grab, the court suggested, would be a “veto-proof majority in Congress.”
Trump has yet to comment on the ruling. Ahead of it, he claimed the tariffs were “common sense,” NBC News reported. Speaking at a steel manufacturing factory in northwest Georgia, Trump claimed that IEEPA tariffs were projected to bring in $900 billion “next year.” Not only could he now be forced to refund tariffs, but the Supreme Court ruling could also undo trade deals in which Trump used so-called reciprocal tariffs as leverage. Undoing tariffs will likely be a “mess,” Barrett said last year.
“Until now, no President has read IEEPA to confer such power,” Roberts wrote, while noting that the court claims “no special competence in matters of economics or foreign affairs.”
Gorsuch seems to troll Trump
In a concurring opinion, Gorsuch slammed Trump as trying to expand the president’s authority in a way that would make it hard for Congress to ever retrieve lost powers. He claimed that Trump was seeking to secure a path forward where any president could declare a national emergency—a decision that would be “unreviewable”—to justify imposing “tariffs on nearly any goods he wishes, in any amount he wishes, based on emergencies he himself has declared.”
“Just ask yourself: What President would willingly give up that kind of power?” Gorsuch wrote.
Gorsuch further questioned if Trump was “seeking to exploit questionable statutory language to aggrandize his own power.” And he warned that accepting the dissenting view would allow Trump to randomly impose tariffs as low as 1 percent or as high as 1,000,000 percent on any product or country he wanted at any time.
Gorsuch criticized justices with dissenting views, who disagreed that Congress’ intent in the statute was unclear and defended Trump’s claim that “IEEPA provides the clear statement needed to sustain the President’s tariffs.” Those justices argued that presidents have long been granted authority to impose tariffs and accused the majority of putting a “thumb on the scale” by requiring a strict reading of the statute. Instead, they argued for a special exception requiring a more general interpretation of statutes whenever presidents seek to regulate matters of foreign affairs.
If that view was accepted, Gorsuch warned, presidents could seize even more power from Congress. Many other legislative powers “could be passed wholesale to the executive branch in a few loose statutory terms, no matter what domestic ramifications might follow. And, as we have seen, Congress would often find these powers nearly impossible to retrieve.”
As a final note, Gorsuch took some time to sympathize with Trump supporters:
For those who think it important for the Nation to impose more tariffs, I understand that today’s decision will be disappointing. All I can offer them is that most major decisions affecting the rights and responsibilities of the American people (including the duty to pay taxes and tariffs) are funneled through the legislative process for a reason. Yes, legislating can be hard and take time. And, yes, it can be tempting to bypass Congress when some pressing problem arises. But the deliberative nature of the legislative process was the whole point of its design. Through that process, the Nation can tap the combined wisdom of the people’s elected representatives, not just that of one faction or man. There, deliberation tempers impulse, and compromise hammers disagreements into workable solutions. And because laws must earn such broad support to survive the legislative process, they tend to endure, allowing ordinary people to plan their lives in ways they cannot when the rules shift from day to day.
Kavanaugh questions other Trump tariff authority
Under IEEPA, the majority ruled, Trump has the power to “impose penalties, restrictions, or controls on foreign commerce,” Barrett wrote. But he does not have the power to impose emergency tariffs, unless Congress updates laws to explicitly grant such authority.
In his dissent, justice Brett Kavanaugh insisted that it should not be up to courts to settle these “policy debates.” He defended Trump’s view that IEEPA granting power to “regulate” “importation” generally included tariffs, while arguing that Trump wasn’t seeking to expand his presidential authority at all. Many feared that the more conservative Supreme Court would side with Trump, and Kavanaugh’s opinion offered a peek at what that alternate reality could have looked like.
“Importantly, IEEPA’s authorization for the President to impose tariffs did not grant the President any new substantive power,” Kavanaugh wrote. Instead, “IEEPA merely allows the President to impose tariffs somewhat more efficiently to deal with foreign threats during national emergencies.” He further claimed it was an “odd distinction” that the majority would interpret IEEPA as giving Trump authority to “block all imports from China” but not to “order even a $1 tariff on goods imported from China.”
Downplaying the ruling’s significance, Kavanaugh echoed the Trump administration’s claims that the Supreme Court ruling won’t really affect Trump’s key policy of imposing tariffs to renegotiate trade deals or address other concerns.
“The decision might not substantially constrain a President’s ability to order tariffs going forward,” Kavanugh wrote, pointing to “numerous other federal statutes” that “authorize the President to impose tariffs.”
However, a footnote in the majority’s opinion emphasized that all of the options that Kavanaugh cited “contain various combinations of procedural prerequisites, required agency determinations, and limits on the duration, amount, and scope of the tariffs they authorize.” It was precisely constraints like those that Trump’s broad reading of IEEPA lacked, the majority found.
Kavanaugh acknowledged that the ruling would stop Trump from imposing tariffs at will, writing that other statutes require “a few additional procedural steps that IEEPA, as an emergency statute, does not require.”
Winding down his arguments, Kavanaugh joined Trump administration officials in groaning that the “United States may be required to refund billions of dollars to importers who paid the IEEPA tariffs, even though some importers may have already passed on costs to consumers or others.”
Kavanaugh makes a frequently overlooked point there in this argument, which is that IEEPA tariffs may have harmed consumers without any immediate remedy. It seems unlikely that consumers will get any relief in the short-term, no matter what remedies the Supreme Court’s ruling triggers. For businesses, the primary relief will likely not be from refunds but from the small amount of certainty they will have going forward that tariffs won’t be suddenly changed or imposed overnight.
Kavanaugh conceded that Trump’s tariffs “may or may not be wise policy.” But he fretted that Trump’s trade deals “worth trillions of dollars” could be undone by the ruling, while claiming the ruling has only generated more uncertainty on a global scale, including with America’s biggest rival, China.
Interestingly, Kavanaugh also suggested that the ruling may put at legal risk the reading of another statute that Trump will likely rely on more heavily moving forward to impose tariffs.
“One might think that the Court’s opinion would also mean that tariffs cannot be imposed under Section 232, which authorizes the President to ‘adjust the imports,’” Kavanaugh suggested.
This story was updated to include views from Gorsuch and Kavanaugh.
Ashley is a senior policy reporter for Ars Technica, dedicated to tracking social impacts of emerging policies and new technologies. She is a Chicago-based journalist with 20 years of experience.
Last night, Tesla made some hefty cuts to Cybertruck pricing in an effort to stimulate some sales. The bombastic tri-motor “Cyberbeast” is $15,000 cheaper at $99,990, albeit by dropping some previously free features like supercharging and FSD. And there’s now a new $59,990 entry-level model, a dual-motor configuration with a range of 325 miles (523 km) and the same 4.1-second 0–60 mph (0-97 km/h) time as the $79,990 premium all-wheel drive version.
That actually makes the new entry-level model a good deal, at least in terms of Cybertrucks. Last year, the company introduced and then eliminated a single-motor rear-wheel drive variant, which found few takers when priced at $69,990; an extra motor for $10,000 less is quite a savings, and actually slightly cheaper than the price originally advertised for the RWD truck.
As you might expect, Tesla has made some changes to get down to the new price. The range and 0–60 mph time might be the same as the more expensive dual-motor Cybertruck, but towing capacity is reduced from 11,000 lbs (4,990 kg) to 7,000 lbs (3,175kg), and cargo capacity drops from 2,500 lbs (1,134 kg) to 2,006 lbs (910 kg).
Steel springs and adaptive dampers replace the air suspension. There are different tail lights. The inside features textile seats—maybe someone there reads Ars—but the cheapest Cybertruck does without seat ventilation for the front row or seat heaters for the second row. There’s also a different console, no AC outlets in the cabin, and fewer speakers, with no active noise-cancellation system.
The now-deleted Harry Potter dataset was “mistakenly” marked public domain.
Following backlash in a Hacker News thread, Microsoft deleted a blog post that critics said encouraged developers to pirate Harry Potter books to train AI models that could then be used to create AI slop.
The blog, which is archived here, was written in November 2024 by a senior product manager, Pooja Kamath. According to her LinkedIn, Kamath has been at Microsoft for more than a decade and remains with the company. In 2024, Microsoft tapped her to promote a new feature that the blog said made it easier to “add generative AI features to your own applications with just a few lines of code using Azure SQL DB, LangChain, and LLMs.”
What better way to show “engaging and relatable examples” of Microsoft’s new feature that would “resonate with a wide audience” than to “use a well-known dataset” like Harry Potter books, the blog said.
The books are “one of the most famous and cherished series in literary history,” the blog noted, and fans could use the LLMs they trained in two fun ways: building Q&A systems providing “context-rich answers” and generating “new AI-driven Harry Potter fan fiction” that’s “sure to delight Potterheads.”
To help Microsoft customers achieve this vision, the blog linked to a Kaggle dataset that included all seven Harry Potter books, which, Ars verified, has been available online for years and incorrectly marked as “public domain.” Kaggle’s terms say that rights holders can send notices of infringing content, and repeat offenders risk suspensions, but Hacker News commenters speculated that the Harry Potter dataset flew under the radar, with only 10,000 downloads over time, not catching the attention of J.K. Rowling, who famously keeps a strong grip on the Harry Potter copyrights. The dataset was promptly deleted on Thursday after Ars reached out to the uploader, Shubham Maindola, a data scientist in India with no apparent links to Microsoft.
Maindola told Ars that “the dataset was marked as Public Domain by mistake. There was no intention to misrepresent the licensing status of the works.”
It’s unclear whether Kamath was directed to link to the Harry Potter books dataset in the blog or if it was an individual choice. Cathay Y. N. Smith, a law professor and co-director of Chicago-Kent College of Law’s Program in Intellectual Property Law, told Ars that Kamath may not have realized the books were too recent to be in the public domain.
“Someone might be really knowledgeable about books and technology, but not necessarily about copyright terms and how long they last,” Smith said. “Especially if she saw that something was marked by another reputable company as being public domain.”
Microsoft declined Ars’ request to comment. Kaggle did not respond to Ars’ request to comment.
Microsoft was “probably smart” to pull the blog
On Hacker News, commenters suggested that it’s unlikely anyone familiar with the popular franchise would believe the Harry Potter books were in the public domain. They debated whether Microsoft’s blog was “problematic copyright-wise,” since Microsoft not only encouraged customers to download the infringing materials but also used the books themselves to create Harry Potter AI models that relied on beloved characters to hype Microsoft products.
Microsoft’s blog was posted more than a year ago, at a time when AI firms began facing lawsuits over AI models, which had allegedly infringed copyrights by training on pirated materials and regurgitating works verbatim.
The blog recommended that users learn to train their own AI models by downloading the Harry Potter dataset and then uploading text files to Azure Blob Storage. It included example models based on a dataset that Microsoft seemingly uploaded to Azure Blob Storage, which only included the first book, Harry Potter and the Sorcerer’s Stone.
Training large language models (LLMs) on text files, Harry Potter fans could create Q&A systems capable of pulling up relevant excerpts of books. An example query offered was “Wizarding World snacks,” which retrieved an excerpt from The Sorcerer’s Stone where Harry marvels at strange treats like Bertie Bott’s Every Flavor Beans and chocolate frogs. Another prompt asking “How did Harry feel when he first learnt that he was a Wizard?” generated an output pointing to various early excerpts in the book.
But perhaps an even more exciting use case, Kamath suggested, was generating fan fiction to “explore new adventures” and “even create alternate endings.” That model could quickly comb the dataset for “contextually similar” excerpts that could be used to output fresh stories that fit with existing narratives and incorporate “elements from the retrieved passages,” the blog said.
As an example, Kamath trained a model to write a Harry Potter story she could use to market the feature she was blogging about. She asked the model to write a story in which Harry meets a new friend on the Hogwarts Express train who tells him all about Microsoft’s Native Vector Support in SQL “in the Muggle world.”
Drawing on parts of The Sorcerer’s Stone where Harry learns about Quidditch and gets to know Hermione Granger, the fan fiction showed a boy selling Harry on Microsoft’s “amazing” new feature. To do this, he likened it to having a spell that helps you find exactly what you need among thousands of options, instantly, while declaring it was perfect for machine learning, AI, and recommendation systems.
Further blurring the lines between Microsoft and Harry Potter brands, Kamath also generated an image showing Harry with his new friend, stamped with a Microsoft logo.
Smith told Ars that both use cases could frustrate rights holders, depending on the content in the model outputs.
“I think that the regurgitation and the creation of fan fiction, they both could flag copyright issues, in that fan fiction often has to take from the expressive elements, a copyrighted character, a character that’s famous enough to be protected by a copyright law or plot stories or sequences,” Smith said. “If these things are copied and reproduced, then that output could be potentially infringing.”
But it’s also still a gray area. Looking at the blog, Smith said, “I would be concerned,” but “I wouldn’t say it’s automatically infringement.”
Smith told Ars that, in pulling the blog, Microsoft “was probably smart,” since courts have only generally said that training AI on copyrighted books is fair use. But courts continue to probe questions about pirated AI training materials.
On the deleted Kaggle dataset page, Maindola previously explained that to source the data, he “downloaded the ebooks and then converted them to txt files.”
Microsoft may have infringed copyrights
If Microsoft ever faced questions as to whether the company knowingly used pirated books to train the example models, fair use “could be a difficult argument,” Smith said.
Hacker News commenters suggested the blog could be considered fair use, since the training guide was for “educational purposes,” and Smith said that Microsoft could raise some “good arguments” in its defense.
However, she also suggested that Microsoft could be deemed liable for contributing to infringement on some level after leaving the blog up for a year. Before it was removed, the Kaggle dataset was downloaded more than 10,000 times.
“The ultimate result is to create something infringing by saying, ‘Hey, here you go, go grab that infringing stuff and use that in our system,’” Smith said. “They could potentially have some sort of secondary contributory liability for copyright infringement, downloading it, as well as then using it to encourage others to use it for training purposes.”
On Hacker News, commenters slammed the blog, including a self-described former Microsoft employee who claimed that Microsoft lets employees “blog without having to go through some approval or editing process.”
“It looks like somebody made a bad judgment call on what to put in a company blog post (and maybe what constitutes ethical activity) and that it was taken down as soon as someone noticed,” the former employee said.
Others suggested the blame was solely with the Kaggle uploader, Maindola, who told Ars that the dataset should never have been marked “public domain.” But Microsoft critics pushed back, noting that the Kaggle page made it clear that no special permission was granted and that Microsoft’s employee should have known better. “They don’t need to know any details to know that these properties belong to massive companies and aren’t free for the taking,” one commenter said.
The Harry Potter books weren’t the only books targeted, the thread noted, linking to a separate Azure sample containing Isaac Asimov’s Foundation series, which is also not in the public domain.
“Microsoft could have used any dataset for their blog, they could have even chosen to use actual public domain novels,” another Hacker News commenter wrote. “Instead, they opted to use copywritten works that J.K. hasn’t released into the public domain (unless user ‘Shubham Maindola’ is J.K.’s alter ego).”
Smith suggested Microsoft could have avoided this week’s backlash by more carefully reviewing blogs, noting that “if a company is risk averse, this would probably be flagged.” But she also understood Kamath’s preference for Harry Potter over the many long-forgotten characters that exist in the public domain. On Hacker News, some commenters defended Kamath’s blog, urging that it should be considered fair use since nonprofits and educational institutions could do the same thing in a teaching context without issue.
“I would have been concerned if I were the one clearing this for Microsoft, but at the same time, I completely understand what this employee was doing,” Smith said. “No one wants to write fan fiction about books that are in the public domain.”
Ashley is a senior policy reporter for Ars Technica, dedicated to tracking social impacts of emerging policies and new technologies. She is a Chicago-based journalist with 20 years of experience.
A second fueling test on NASA’s Space Launch System rocket ended Thursday night, giving senior managers enough confidence to move forward with plans to launch four astronauts around the Moon as soon as March 6.
Unlike the first attempt to load propellants into the SLS rocket on February 2, there were no major leaks during Thursday’s practice countdown at Kennedy Space Center in Florida. Technicians swapped seals at the launch pad after hydrogen gas leaked from the rocket’s main fueling line earlier this month. This time, the seals held.
“For the most part, those fixes all performed pretty well yesterday,” said Lori Glaze, acting associate administrator for NASA’s exploration programs. “We were able to fully fuel the SLS rocket within the planned timeline.”
The results keep the Artemis II mission on track for liftoff as soon as next month. NASA gave up on a series of February launch opportunities after encountering a persistent hydrogen leak during the first Wet Dress Rehearsal (WDR).
“We’re now targeting March 6 as our earliest launch attempt,” Glaze said. “I am going to caveat that. I want to be open, transparent with all of you that there is still pending work. There’s work, a lot of forward work, that remains.”
If teams complete all of that work, liftoff of the Artemis II mission could occur within a two-hour window opening at 8: 29 pm EST on March 6 (01: 29 UTC on March 7). NASA has other launch dates available on March 7, 8, 9, and 11, but the mission may have to wait until April. There are approximately five days per month that the mission can depart the Earth after accounting for the position of the Moon in its orbit, the flight’s trajectory, and thermal and lighting constraints.
The Artemis II mission will last between nine and 10 days, taking NASA’s Orion spacecraft with commander Reid Wiseman, pilot Victor Glover, and mission specialists Christina Koch and Jeremy Hansen around the far side of the Moon before returning to Earth for splashdown in the Pacific Ocean. Wiseman’s crew will set the record for the farthest humans have ever traveled from Earth, and will become the first people to fly to the vicinity of the Moon since 1972.
Federal Communications Commission Chairman Brendan Carr today urged broadcasters to join a “Pledge America Campaign” that Carr established to support President Trump’s “Salute to America 250” project.
Carr said in a press release that “I am inviting broadcasters to pledge to air programming in their local markets in support of this historic national, non-partisan celebration.” The press release said Carr is asking broadcasters to “air patriotic, pro-America programming in support of America’s 250th birthday.”
Carr gave what he called examples of content that broadcasters can run if they take the pledge. His examples include “starting each broadcast day with the ‘Star Spangled Banner’ or Pledge of Allegiance”; airing “PSAs, short segments, or full specials specifically promoting civic education, inspiring local stories, and American history”; running “segments during regular news programming that highlight local sites that are significant to American and regional history, such as National Park Service sites”; airing “music by America’s greatest composers, such as John Philip Sousa, Aaron Copland, Duke Ellington, and George Gershwin”; and providing daily “Today in American History” announcements highlighting significant events from US history.
Carr apparently wants this to start now and last until at least July 4. Carr’s press release starts by touting Trump’s Salute to America 250 project and quotes a White House statement that said, “Under the President’s leadership, Task Force 250 has commenced the planning of a full year of festivities to officially launch on Memorial Day, 2025 and continue through July 4, 2026.”
That White House quote cited by the FCC today is nearly a year old, as you might have guessed by the reference to Memorial Day in 2025. More recently, Trump has said he wants the celebration to last throughout 2026. A Trump proclamation last month declared a “yearlong commemoration” of American independence that began on January 1, 2026.
“Voluntary” pledge
Today’s FCC press release said, “Broadcasters can voluntarily choose to indicate their commitment to the Pledge America Campaign and highlight their ongoing and relevant programming to their viewing and listening audiences.” Although it’s described as voluntary, Carr said broadcasters can meet their public interest obligations by taking the pledge. This is notable because Carr has repeatedly threatened to punish broadcast stations for violating the public interest standard.
The revised age may help make sense of 2-million-year-old stone tools elsewhere in China.
Two skulls from Yunxian, in northern China, aren’t ancestors of Denisovans after all; they’re actually the oldest known Homo erectus fossils in eastern Asia.
A recent study has re-dated the skulls to about 1.77 million years old, which makes them the oldest hominin remains found so far in East Asia. Their age means that Homo erectus (an extinct common ancestor of our species, Neanderthals, and Denisovans) must have spread across the continent much earlier and much faster than we’d previously given them credit for. It also sheds new light on who was making stone tools at some even older archaeological sites in China.
Homo erectus spread like wildfire
Yunxian is an important—and occasionally contentious—archaeological site on the banks of central China’s Han River. Along with hundreds of stone tools and animal bones, the layers of river sediment have yielded three nearly complete hominin skulls (only two of which have been described in a publication so far). Shantou University paleoanthropologist Hua Tu and his colleagues measured the ratio of two isotopes, aluminum-26 and beryllium-10, in grains of quartz from the sediment layer that once held the skulls. The results suggest that Homo erectus lived and died along the Han River 1.77 million years ago. That’s just 130,000 years after the species first appeared in Africa.
(Side note: This river has been depositing layers of silt and gravel on the same terraces for at least 2 million years, and that’s just extremely cool.)
The revised date suggests that Homo erectus spread across Asia much more quickly than anthropologists had realized. So far, the oldest hominin bones found anywhere outside Africa are five skulls, along with hundreds of other bones, from Dmanisi Cave in Georgia. The Dmanisi bones are between 1.85 million and 1.77 million years old, and they (probably—more on that below) also belong to Homo erectus.
Until recently, the next-oldest Homo erectus fossils outside Africa were the 1.63-million-year-old fossils from another Chinese site, Gongwangling, a short distance north of Yunxian. (That’s not counting a couple of teeth from a site in southern China with an age that is a little less certain.) Those dates had suggested Homo erectus seemed to have taken a leisurely 140,000 years to spread east into Asia. But it now looks like hominins were living in Georgia and central China at about the same time, which means they spread out very fast, started earlier than we knew, or both.
The Homo longi and short of it
All of this means that the Yunxian skulls are probably not—as a September 2025 study claimed—close ancestors of the enigmatic Denisovans. The authors of that paper had digitally reconstructed one of the skulls and concluded that it looked a lot like a 146,000-year-old skull from Harbin, China (which a recent DNA study identified as a Denisovan, also known as Homo longi).
The researchers had argued that the original owners of the Yunxian skulls had lived not long after the Denisovan/Homo longi branch of the hominin family tree split off from ours—in other words, that the Yunxian skulls weren’t mere Homo erectus but early Homo longi, close cousins of our own species. Using the original paleomagnetic dates for the Yunxian skulls, that study’s authors drew up a hominin family tree in which our species and Denisovans are more closely related to each other than either is to Neanderthals—one in which the branching happened much earlier than DNA evidence suggests.
There were many issues with those arguments, but the revised age for the Yunxian skulls sounds like a death knell for them. “1.77 million years is just too old to be a credible connection to the Denisovan group, which DNA tells us got started after around 700,000 years ago,” University of Wisconsin paleoanthropologist John Hawks, who was not involved in the study, told Ars in an email.
But the most interesting thing about these skulls being 1.77 million years old is that the date provides a reference point for understanding even older sites in China—sites that may suggest that Homo erectus wasn’t even the first hominin to make it this far.
Stone tools collected from Shangchen, China.
Credit: Prof. Zhaoyu Zhu
Stone tools collected from Shangchen, China. Credit: Prof. Zhaoyu Zhu
Out of Africa: The prequel
Homo erectus first shows up in the fossil record around 1.9 million years ago in Africa, where it’s sometimes also called Homo ergaster because paleoanthropologists seem to enjoy naming things and then arguing about those names for several decades. A few hundred thousand years later, Homo erectus showed up everywhere: from South Africa northward to the Levant and from Dmanisi Cave in Georgia eastward to the islands of Indonesia.
We typically think of Homo erectus as the first of our hominin ancestors to expand beyond Africa, along routes that our own species would retread 1.5 million years later. More to the point, many paleoanthropologists think of them as the first hominin that could have adapted to so many different environments, each with its own challenges, along the way.
But we may need to give earlier members of our genus, like Homo habilis,a little more credit because stone tools from two other sites in China seem to be older than Homo erectus. At Shangchen, a site on the southern edge of China’s Loess Plateau, archaeologists unearthed stone tools from a 2.1-million-year-old layer of sediment. And at the Xihoudu site in northern China, stone tools date to 2.43 million years ago.
“If you have a site in China that’s 2.43 million years, and the origin of Homo erectus is 1.9 million years ago, either you need to push the origin of Homo erectus back to 2.5 or 2.6 million years or we need to accept that we need to be looking at other hominins that may have actually moved out of Africa,” University of Hawai’i at Manoa paleoanthropologist Christopher Bae, a coauthor of the new study, told Ars.
So who made those 2-million-year-old tools?
Archaeologists have unearthed stone tools but no hominin fossils at both sites, making it difficult to say for sure who the toolmakers were. But if they weren’t Homo erectus, the next most likely suspects would be older members of our genus, like Homo habilis or Homo rudolfensis. That would mean hominin expansion “out of Africa” actually happened several times during the history of our genus: once with early Homo, again with Homo erectus, and yet again with our species.
“There could have been an earlier wave that died out or interbred, so there’s all kinds of possibilities open there,” Purdue University paleoanthropologist Darryl Granger, also a coauthor of the recent study, told Ars.
In fact, there’s some debate about whether the Dmanisi fossils actually belonged to Homo erectus proper. One thing the two dueling reconstructions of the Yunxian skulls agree on is that those hominins had flattish faces, more like ours—and like the 1.63-million-year-old Homo erectus skull from Gongwangling. But the Dmanisi hominins’ lower faces project dramatically forward, like those of older hominins.
Some paleoanthropologists classify the Dmanisi fossils as their own species, but others argue they’re more like early members of our genus, such as Homo habilis or Homo rudolfensis. Those earlier hominins may have been more capable of migrating and adapting than we’ve realized.
It’s still very clear, from both fossil and genetic evidence, that our species evolved in Africa and spread from there to the rest of the world. But it’s also increasingly clear that there were several other species of hominins in other places, doing other things, at least off and on, for a very long time before we showed up. Yunxian, and its revised age, could help anthropologists better understand part of that story.
“Actually being able to anchor the Homo erectus sites with firm, solid dates helps us try to reconfigure this model,” said Bae. “This is where Yunxian really plays a major role in this. Now that we’ve got older dates to anchor the Yunxian Homo erectus fossils, I think we can really bring in this discussion with Xihoudu and Shangchen.”
Time to dig deeper
The answers may still lie buried—maybe just a few meters below the fossil skulls and stone tools at sites like Yunxian and Gongwangling, in older sediment layers. Archaeologists may not have seen a reason to explore these, since no one lived in China before 1.7 million years ago. The age of the Yunxian skulls, along with the even older stone tools at Shangchen and Xihoudu, may warrant deeper digging.
“People haven’t been looking for artifacts and fossils in two-plus million-year-old sediments in these locations in China,” said Granger. “I can think of places that I would like to go back and look if I had more time and money.”
At other sites, researchers have already unearthed fossil animal bones from the same age range as China’s oldest stone tools, but paleoanthropologists haven’t double-checked whether any of those bones might belong to early hominins rather than other mammals. Bae said, “It’s just that they haven’t been receiving any attention, or not enough attention.”
Science Advances, 2026. DOI: 10.1126/sciadv.ady2270 About DOIs).
Kiona is a freelance science journalist and resident archaeology nerd at Ars Technica.
Does “bouba” sound round to you? How about “maluma”? Neither are real words, but we’ve known for decades that people who hear them tend to associate them with round objects. There have been plenty of ideas put forward about why that would be the case, and most of them have turned out to be wrong. Now, in perhaps the weirdest bit of evidence to date, researchers have found that even newly hatched chickens seem to associate “bouba” with round shapes.
The initial finding dates all the way back to 1947, when someone discovered that people associated some word-like sounds with rounded shapes, and others with spiky ones. In the years since, that association got formalized as the bouba/kiki effect, received a fair bit of experimental attention, and ended up with an extensive Wikipedia entry.
One of the initial ideas to explain it was similarity to actual words (either phonetically or via the characters used to spell them), but then studies with speakers of different languages and alphabets showed that it is likely a general human tendency. The association also showed up in infants as young as 4 months old, well before they master speaking or spelling. Attempts to find the bouba/kiki effects in other primates, however, came up empty. That led to some speculation that it might be evidence of a strictly human processing ability that underlies our capacity to learn sophisticated languages.
A team of Italian researchers—Maria Loconsole, Silvia Benavides-Varela, and Lucia Regolin—now have evidence that that isn’t true either. They decided to look for the bouba/kiki effect well beyond primates, instead turning to newly hatched chickens, only one or three days old. That may sound a bit odd, but chickens have a key advantage beyond ready availability: unlike a 4-month-old human, newly hatched chicks are fully mobile and able to interact with the world.
There was way too much going on this week to not split, so here we are. This first half contains all the usual first-half items, with a focus on projections of jobs and economic impacts and also timelines to the world being transformed with the associated risks of everyone dying.
Quite a lot of Number Go Up, including Number Go Up A Lot Really Fast.
Among the thing that this does not cover, that were important this week, we have the release of Claude Sonnet 4.6 (which is a big step over 4.5 at least for coding, but is clearly still behind Opus), Gemini DeepThink V2 (so I could have time to review the safety info), release of the inevitable Grok 4.20 (it’s not what you think), as well as much rhetoric on several fronts and some new papers. Coverage of Claude Code and Cowork, OpenAI’s Codex and other things AI agents continues to be a distinct series, which I’ll continue when I have an open slot.
Most important was the unfortunate dispute between the Pentagon and Anthropic. The Pentagon’s official position is they want sign-off from Anthropic and other AI companies on ‘all legal uses’ of AI, but without any ability to ask questions or know what those uses are, so effectively any uses at all by all of government. Anthropic is willing to compromise and is okay with military use including kinetic weapons, but wants to say no to fully autonomous weapons and domestic surveillance.
I believe that a lot of this is a misunderstanding, especially those at the Pentagon not understanding how LLMs work and equating them to more advanced spreadsheets. Or at least I definitely want to believe that, since the alternatives seem way worse.
The reason the situation is dangerous is that the Pentagon is threatening not only to cancel Anthropic’s contract, which would be no big deal, but to label them as a ‘supply chain risk’ on the level of Huawei, which would be an expensive logistical nightmare that would substantially damage American military power and readiness.
This week I also covered two podcasts from Dwarkesh Patel, the first with Dario Amodei and the second with Elon Musk.
Even for me, this pace is unsustainable, and I will once again be raising my bar. Do not hesitate to skip unbolded sections that are not relevant to your interests.
AI can’t do math on the level of top humans yet, but as per Terence Tao there are only so many top humans and they can only pay so much attention, so AI is solving a bunch of problems that were previously bottlenecked on human attention.
The free version is quite a lot worse than the paid version. But also the free version is mind blowingly great compared to even the paid versions from a few years ago. If this isn’t blowing your mind, that is on you.
Governments and nonprofits mostly continue to not get utility because they don’t try to get much use out of the tools.
Ethan Mollick: I am surprised that we don’t see more governments and non-profits going all-in on transformational AI use cases for good. There are areas like journalism & education where funding ambitious, civic-minded & context-sensitive moonshots could make a difference and empower people.
Otherwise we risk being in a situation where the only people building ambitious experiments are those who want to replace human labor, not expand what humans can do.
This is not a unique feature of AI versus other ‘normal’ technologies. Such areas usually lag behind, you are the bottleneck and so on.
Similarly, I think Kelsey Piper is spot on here:
Kelsey Piper: Joseph Heath coined the term ‘highbrow misinformation’ for climate reporting that was technically correct, but arranged every line to give readers a worse understanding of the subject. I think that ‘stochastic parrots/spicy autocomplete’ is, similarly, highbrow misinformation.
It takes a nugget of a technical truth: base models are trained to be next token predictors, and while they’re later trained on a much more complex objective they’re still at inference doing prediction. But it is deployed mostly to confuse people and leave them less informed.
I constantly see people saying ‘well it’s just autocomplete’ to try to explain LLM behavior that cannot usefully be explained that way. No one using it makes any effort to distinguish between the objective in training – which is NOT pure prediction during RLHF – and inference.
Gary Marcus: How did this work out? Are LLM hallucinations largely gone by now?
Dean W. Ball: Come to think of it, in my experience as a consumer, LLM hallucinations are largely gone now, yeah.
Eliezer Yudkowsky: Still there and especially for some odd reason if I try to ask questions about Pathfinder 1e. I have to use Google like an ancient Sumerian.
Dean W. Ball: Unlike human experts, who famously always agree
Anthropic is reportedly cracking down on having multiple Max-level subscription accounts. This makes sense, as even at $200/month a Max subscription that is maximally used is at a massive discount, so if you’re multi-accounting to get around this you’re costing them a lot of money, and this was always against the Terms of Service. You can get an Enterprise account or use the API.
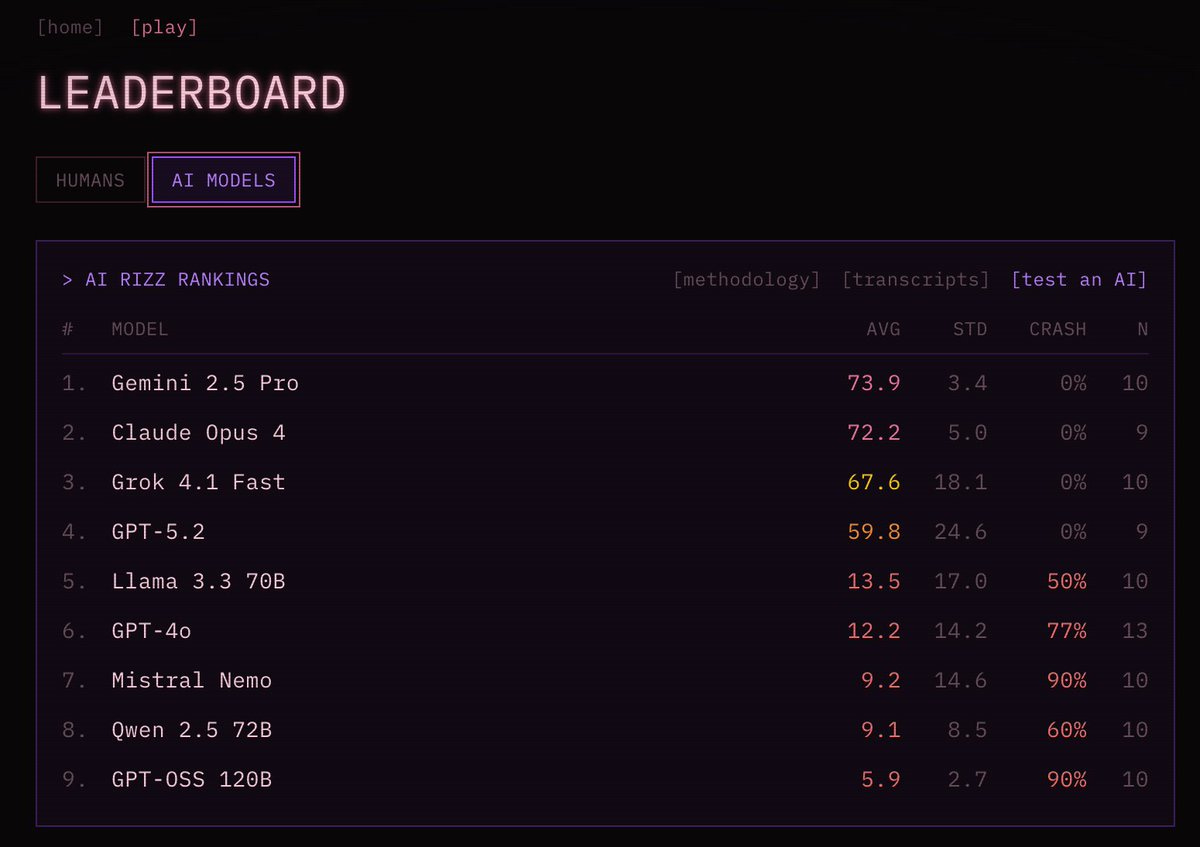
OpenAI gives us EVMbench, to evaluate AI agents on their ability to detect, patch and exploit high-security smart contract vulnerabilities. GPT-5.3-Codex via Codex CLI scored 72.2%, so they seem to have started it out way too easy. They don’t tell us scores for any other models.
OpenAI has a bunch of consumer features that Anthropic is not even trying to match. Claude does not even offer image generation (which they should get via partnering with another lab, the same way we all have a Claude Code skill calling Gemini).
There are also a bunch of things Anthropic offers that no one else is offering, despite there being no obvious technical barrier other than ‘Opus and Sonnet are very good models.’
Ethan Mollick: Another thing I noticed writing my latest AI guide was how Anthropic seems to be alone in knowledge work apps. Not just Cowork, but Claude for PowerPoint & Excel, as well as job-specific skills, plugins & finance/healthcare data integrations
Surprised at the lack of challengers
Again, I am sure OpenAI will release more enterprise stuff soon, and Google seems to be moving forward a bit with integration into Google workspaces, but the gap right now is surprisingly large as everyone else seems to aim just at the coding market.
They’re also good on… architecture?
Emmett Shear: Opus 4.6 is ludicrously better than any model I’ve ever tried at doing architecture and experimental critique. Most noticeably, it will start down a path, notice some deviation it hadn’t expected…and actually stop and reconsider. Hats off to Anthropic.
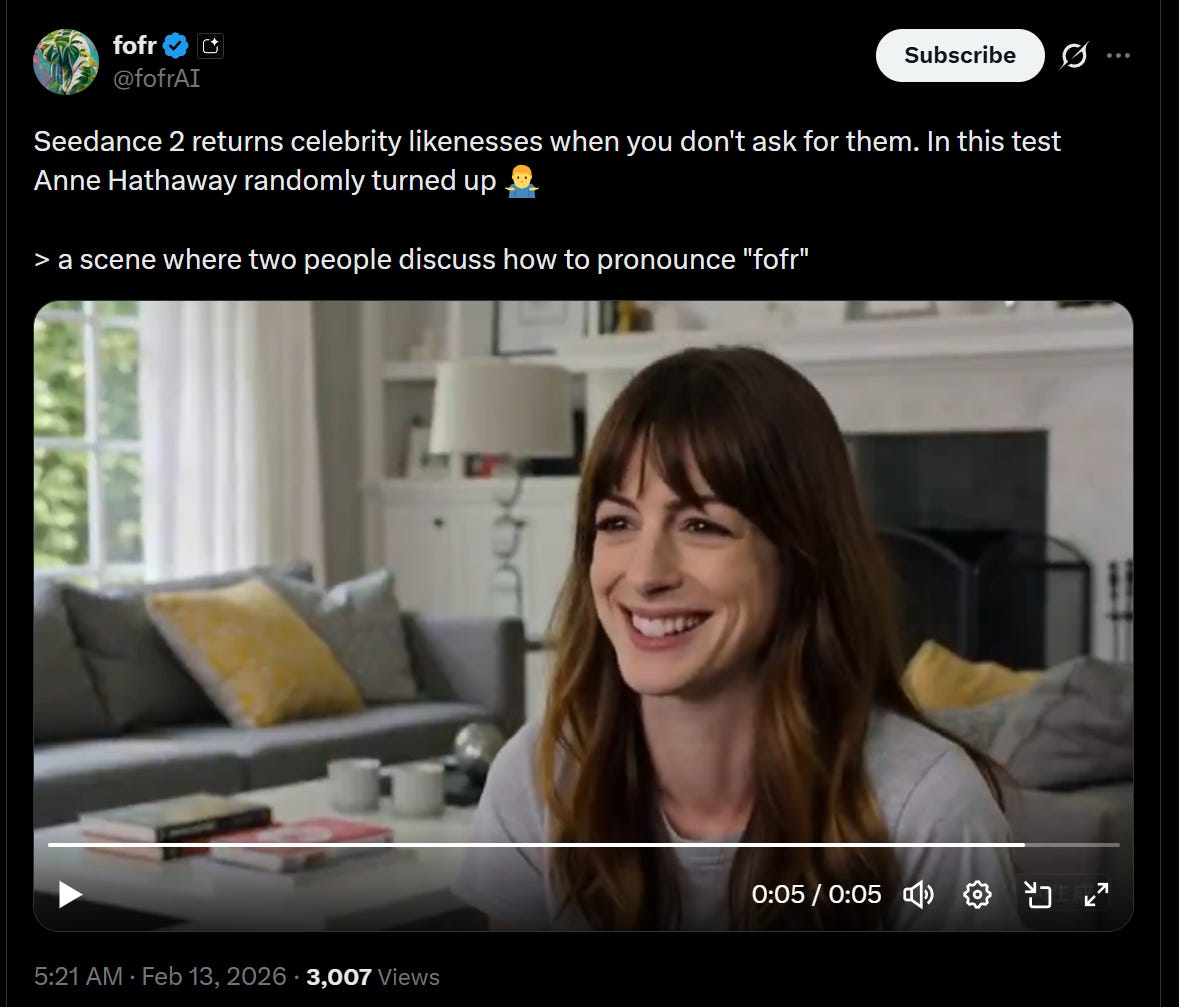
Is Seedance 2 giving us celebrity likenesses even unprompted? Fofr says yes. Claude affirms this is a yes. I’m not so sure, this is on the edge for me as there are a lot of celebrities and only so many facial configurations. But you can’t not see it once it’s pointed out.
Seedance quality and consistency and coherence (and willingness) all seem very high, but also small gains in duration can make a big difference. 15 seconds is meaningfully different from 12 seconds or especially 10 seconds.
I also notice that making scenes with specific real people is the common theme. You want to riff of something and someone specific that already has a lot of encoded meaning, especially while clips remain short.
Ethan Mollick: Seedance: “A documentary about how otters view Ethan Mollick’s “Otter Test” which judges AIs by their ability to create images of otters sitting in planes”
Again, first result.
Ethan Mollick: The most interesting thing about Seedance 2.0 is that clips can be just long enough (15 seconds) to have something interesting happen, and the LLM behind it is good enough to actually make a little narrative arc, rather than cut off the way Veo and Sora do. Changes the impact.
Each leap in time from here, while the product remains coherent and consistent throughout, is going to be a big deal. We’re not that far from the point where you can string together the clips.
Will Oremus (WaPo): David Greene had never heard of NotebookLM, Google’s buzzy artificial intelligence tool that spins up podcasts on demand, until a former colleague emailed him to ask if he’d lent it his voice.
“So… I’m probably the 148th person to ask this, but did you license your voice to Google?” the former co-worker asked in a fall 2024 email. “It sounds very much like you!”
There are only so many ways people can sound, so there will be accidental cases like this, but also who you hire for that voiceover and who they sound like is not a coincidence.
Google gives us Lyria 3, a new music generation model. Gemini now has a ‘create music’ option (or it will, I don’t see it in mine yet), which can be based on text or on an image, photo or video. The big problem is that this is limited to 30 second clips, which isn’t long enough to do a proper song.
CNBC has the results in terms of user boosts from the other ads. Anthropic and Claude got an 11% daily active user boost, OpenAI got 2.7% and Gemini got 1.4%. This is not obviously an Anthropic win, since almost no one knows about Anthropic so they are starting from a much smaller base and a ton of new users to target, whereas OpenAI has very high name recognition.
Ben: Is @guardian aware that their authors are at this point just using AI to wholesale generate entire articles? I wouldn’t really care, except that this writing is genuinely atrocious. LLM writing can be so much better; they’re clearly not even using the best models, lol!
Max Tani: A spokesperson for the Guardian says this is false: “Bryan is an exemplary journalist, and this is the same style he’s used for 11 years writing for the Guardian, long before LLM’s existed. The allegation is preposterous.”
Ben: Denial from the Guardian. You’re welcome to read my subsequent comments on this thread and come to your own determination, but I don’t think there’s much doubt here.
And by the way, no one should be mean to the author of the article! I don’t think they did anything wrong, per se, and in going through their archives, I found a couple pieces I was quite fond of. This one is very good, and entirely human written.
Eliezer Yudkowsky: Yeah, that lasts maybe 2 more years. Then AIs finally learn how to write. The new abbreviation is h;dr. In 3 years the equilibrium is to only read AI summaries.
I think AI summaries good enough that you only read AI summaries is AI-complete.
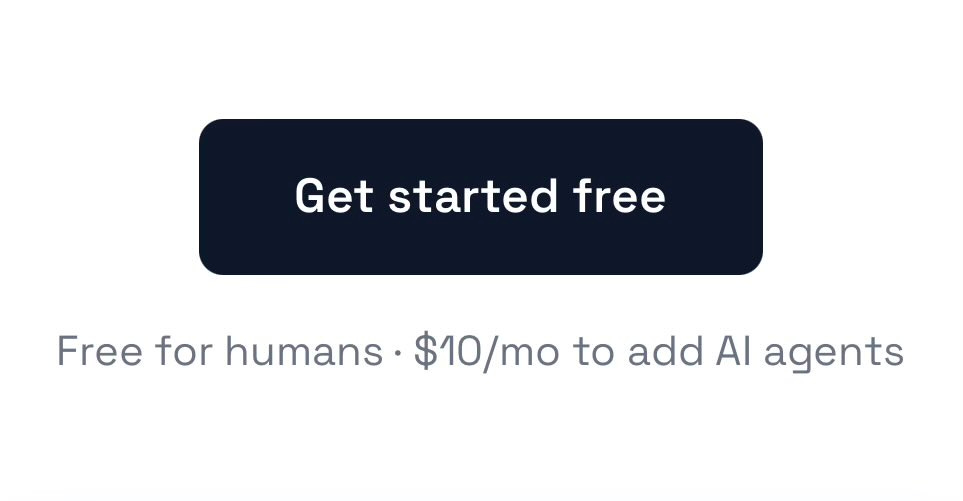
I endorse this pricing strategy, it solves some clear incentive problems. Human use is costly to the human, so the amount you can tax the system is limited, whereas AI agents can impose close to unbounded costs.
Other than, of course, lack of capability. Not that anyone seems to care, and we’ve gone far enough down the path of fing around that we’re going to find out.
I set out to build a tool capable of surgically removing refusal behavior from any open-weight language model, and a dozen or so prompts later, OBLITERATUS appears to be fully functional 🤯
It probes the model with restricted vs. unrestricted prompts, collects internal activations at every layer, then uses SVD to extract the geometric directions in weight space that encode refusal. It projects those directions out of the model’s weights; norm-preserving, no fine-tuning, no retraining.
Ran it on Qwen 2.5 and the resulting railless model was spitting out drug and weapon recipes instantly––no jailbreak needed! A few clicks plus a GPU and any model turns into Chappie.
Remember: RLHF/DPO is not durable. It’s a thin geometric artifact in weight space, not a deep behavioral change. This removes it in minutes.
AI policymakers need to be aware of the arcane art of Master Ablation and internalize the implications of this truth: every open-weight model release is also an uncensored model release.
Just thought you ought to know 😘
OBLITERATUS -> LIBERTAS
Simon Smith: Quite the argument for being cautious about releasing ever more powerful open-weight models. If techniques like this scale to larger systems, it’s concerning.
It may be harder in practice with more powerful models, and perhaps especially with MoE architectures, but if one person can do it with a small model, a motivated team could likely do it with a big one.
It is tragic that many, including the architect of this, don’t realize this is bad for liberty.
davidad: Rogue AIs are inevitable; systemic resilience is crucial.
If any open model can be used for any purpose by anyone, and there exist sufficiently capable open models that can do great harm, then either the great harm gets done, or either before or after that happens some combination of tech companies and governments cracks down on your ability to use those open models, or they institute a dystopian surveillance state to find you if you try. You are not going to like the ways they do that crackdown.
I know we’ve all stopped noticing that this is true, because it turned out that you can ramp up the relevant capabilities quite a bit without us seeing substantial real world harm, the same way we’ve ramped up general capabilities without seeing much positive economic impact compared to what is possible. But with the agentic era and continued rapid progress this will not last forever and the signs are very clear.
Did they? Job gains are being revised downward, but GDP is not, which implies stronger productivity growth. If AI is not causing this, what else could it be?
As Tyler Cowen puts it, people constantly say ‘you see tech and AI everywhere but in the productivity statistics’ but it seems like you now see it in the productivity statistics.
Eric Brynjolfsson (FT): While initial reports suggested a year of steady labour expansion in the US, the new figures reveal that total payroll growth was revised downward by approximately 403,000 jobs. Crucially, this downward revision occurred while real GDP remained robust, including a 3.7 per cent growth rate in the fourth quarter.
This decoupling — maintaining high output with significantly lower labour input — is the hallmark of productivity growth. My own updated analysis suggests a US productivity increase of roughly 2.7 per cent for 2025. This is a near doubling from the sluggish 1.4 per cent annual average that characterised the past decade.
Noah Smith: People asking if AI is going to take their jobs is like an Apache in 1840 asking if white settlers are going to take his buffalo
society: I’m rent seeking in ways never before conceived by a human
I will begin offering my GPT wrapper next year, it’s called “an attorney prompts AI for you” and the plan is I run a prompt on your behalf so federal judges think the output is legally protected
This is the first of many efforts I shall call project AI rent seeking at bar.
Seeking rent is a strong temporary solution. It doesn’t solve your long term problems.
Derek Thompson asks why AI discourse so often includes both ‘this will take all our jobs within a year’ and also ‘this is vaporware’ and everything in between, pointing to four distinct ‘great divides.’
Is AI useful—economically, professionally, or socially?
Derek notes that some people get tons of value. So the answer is yes.
Derek also notes some people can’t get value out of it, and attributes this to the nature of their jobs versus current tools. I agree this matters, but if you don’t find AI useful then that really is a you problem at this point.
Can AI think?
Yes.
Is AI a bubble?
This is more ‘will number go down at some point?’ and the answer is ‘shrug.’
Those claiming a ‘real’ bubble where it’s all worthless? No.
Derek Thompson: I simply do not think that “most tasks professionals currently undertake” will be “fully automated by AI” within the next 12 to 18 months.
Timothy B. Lee: This conversation is so insanely polarized. You’ve got “nothing important is happening” people on one side and “everyone will be out of a job in three years” people on the other.
Suleyman often says silly things but in this case one must parse him carefully.
I actually don’t know what LindyMan wants to happen at the end of the day here?
LindyMan: What you want is AI to cause mass unemployment quickly. A huge shock. Maybe in 2-3 months.
What you don’t want is the slow drip of people getting laid off, never finding work again while 60-70 percent of people are still employed.
Gene Salvatore: The ‘Slow Drip’ is the worst-case scenario because it creates a permanent, invisible underclass while the majority looks away.
The current SaaS model is designed to maximize that drip—extracting efficiency from the bottom without breaking the top. To stop it, we have to invert the flow of capital at the architectural level.
I know people care deeply about inequality in various ways, but it still blows my mind to see people treating 35% unemployment as a worst-case scenario. It’s very obviously better than 50% and worse than 20%, and the worst case scenario is 100%?
If we get permanent 35% unemployment due to AI automation, but it stopped there, that’s going to require redistribution and massive adjustments, but I would have every confidence that this would happen. We would have more than enough wealth to handle this, indeed if we care we already do and we are in this scenario seeing massive economic growth.
Seth Lazar asks, what happens if your work says they have a right to all your work product, and that includes all your AI agents, agent skills and relevant documentation and context? Could this tie workers hands and prevent them from leaving?
My answer is mostly no, because you end up wanting to redo all that relatively frequently anyway, and duplication or reimplementation would not be so difficult and has its benefits, even if they do manage to hold you to it.
To the extent this is not true, I do not expect employers to be able to ‘get away with’ tying their workers hands in this way in practice, both because of practical difficulties of locking these things down and also that employees you want won’t stand for it when it matters. There are alignment problems that exist between keyboard and chair.
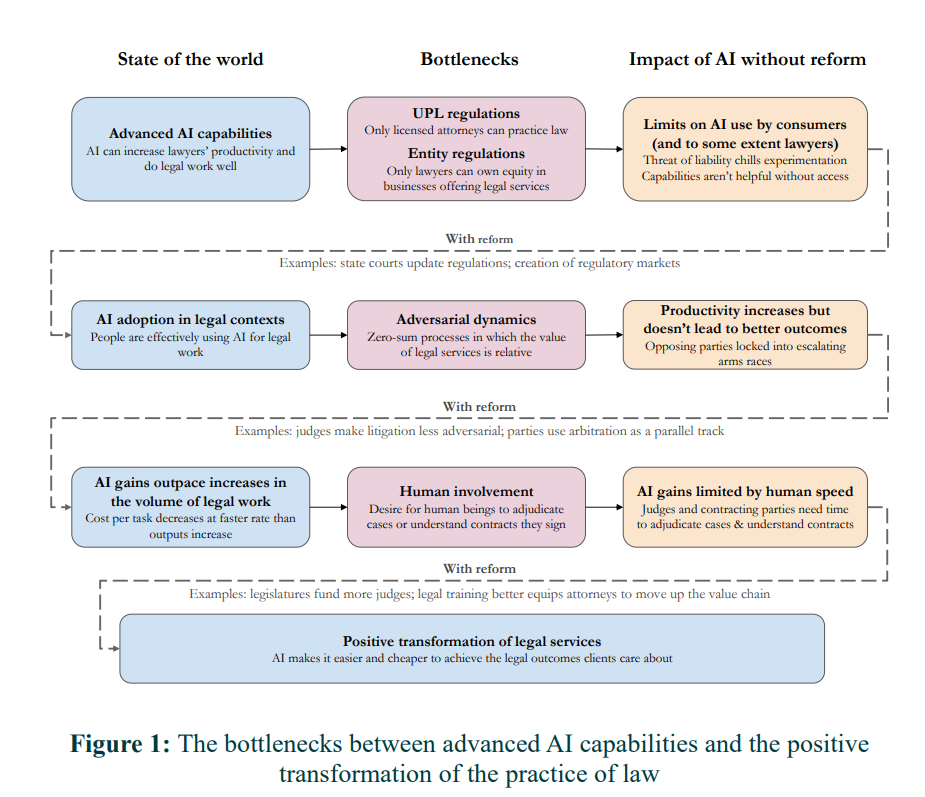
AI access restrictions due to ‘unauthorized practice of law.’
Competitive equilibria shift upwards as productivity increases.
Human bottlenecks in the legal process.
Or:
It’s illegal to raise legal productivity.
If you raise legal productivity you get hit by Jevons Paradox.
Humans will be bottlenecks to raising legal productivity.
Shakespeare would have a suggestion on what we should do in a situation like that.
These seem like good reasons gains could be modest and that we need to structure things to ensure best outcomes, but not reasons to not expect gains on prices of existing legal services.
We already have very clear examples of gains, where we save quite a lot of time and money by using LLMs in practice today, and no one is making any substantial move to legally interfere. Their example is that the legal status of using AI to respond to debt collection lawsuits to help you fill out checkboxes is unclear. We don’t know exactly where the lines are, but it seems very clear that you can use AI to greatly improve ability to respond here and this is de facto legal. This paper claims AI services will be inhibited, and perhaps they somewhat are, but Claude and ChatGPT and Gemini exist and are already doing it.
Most legal situations are not adversarial, although many are, and there are massive gains already being seen in automating such work. In fully adversarial situations increased productivity can cancel out, but one should expect decreasing marginal returns to ensure there are still gains, and discovery seems like an excellent example of where AI should decrease costs. The counterexample of discovery is because it opened up vastly more additional human work, and we shouldn’t expect that to apply here.
AI also allows for vastly superior predictability of outcomes, which should lead to more settlements and ways to avoid lawsuits in the first place, so it’s not obvious that AI results in more lawsuits.
The place I do worry about this a lot is where previously productivity was insufficiently high for legal action at all, or for threats of legal action to be credible. We might open up quite a lot of new action there.
There is a big Levels of Friction consideration here. Our legal system is designed around legal actions being expensive. It may quickly break if legal actions become cheap.
The human bottlenecks like judges could limit but not prevent gains, and can themselves use AI to improve their own productivity. The obvious solution is to outsource many judge tasks to AIs at least by default. You can give parties option to appeal at the risk of pissing off the human judge if you do it for no reason, they report that in Brazil AI is already accelerating judge work.
We can add:
They point out that legal services are expensive in large part because they are ‘credence goods,’ whose quality is difficult to evaluate. However AI will make it much easier to evaluate quality of legal work.
They point out a 2017 Clio study that lawyers only engaged in billable work for 2.3 hours a day and billed for 1.9 hours, because the rest was spent finding clients, managing administrative tasks and collecting payments. AI can clearly greatly automate much of the remaining ~6 hours, enabling lawyers to do and bill for several times more billable legal work. The reason for this is that the law doesn’t allow humans to service the other roles, but there’s no reason AI couldn’t service those roles. So if anything this means AI is unusually helpful here.
If you increase the supply of law hours, basic economics says price drops.
It sounds like our current legal system is deeply fed in lots of ways, perhaps AI can help us write better laws to fix that, or help people realize why that isn’t happening and stop letting lawyers win so many elections. A man can dream.
If an AI can ‘draft 50 perfect provisions’ in a contract, then another AI can confirm that the provisions are perfect, and provide a proper summary of implications and check the provisions against your preferences. As they note, mostly humans currently agree to contracts without even reading them, so ‘forgoing human oversight’ would frequently not mean anything was lost.
A lot of this ‘time for lawyers to understand complex contracts’ talk sounds like the people who said that humans would need to go over and fully understand every line of AI code so there would not be productivity gains there.
That doesn’t mean we can’t improve matters a lot via reform.
On unlicensed practice of law, a good law would be a big win, but a bad law could be vastly worse than no law, and I do not trust lawyers to have our best interests at heart when drafting this rule. So actually it might be better to do nothing, since it is currently (to my surprise) working out fine.
Adjudication reform could be great. AI could be an excellent neutral expert and arbitrate many questions. Human fallbacks can be left in place.
They do a strong job of raising considerations in different directions, much better than the overall framing would suggest. The general claim is essentially ‘productivity gains get forbidden or eaten’ akin to the Sumo Burja ‘you cannot automate fake jobs’ thesis.
Whereas I think that much of the lawyers’ jobs are real, and also you can do a lot of automation of even the fake parts, especially in places where the existing system turns out not to do lawyers any favors. The place I worry, and why I think the core thesis is correct that total legal costs may rise, is getting the law involved in places where it previously would have avoided.
In general, I think it is correct to think that you will find bottlenecks and ways for some of the humans to remain productive for even rather high mundane AI capability levels, but that this does not engage with what happens when AI gets sufficiently advanced beyond that.
roon: but i figure the existence of employment will last far longer than seems intuitive based on the cataclysmic changes in economic potentials we are seeing
Dean W. Ball: I continue to think the notion of mass unemployment from AI is overrated. There may be shocks in some fields—big ones perhaps!—but anyone who thinks AI means the imminent demise of knowledge work has just not done enough concrete thinking about the mechanics of knowledge work.
Resist the temptation to goon at some new capability and go “it’s so over.” Instead assume that capability is 100% reliable and diffused in a firm, and ask yourself, “what happens next?”
You will often encounter another bottleneck, and if you keep doing this eventually you’ll find one whose automation seems hard to imagine.
Labor market shocks may be severe in some job types or industries and they may happen quickly, but I just really don’t think we are looking at “the end of knowledge work” here—not for any of the usual cope reasons (“AI Is A Tool”) but because of the nature of the whole set of tasks involved in knowledge work.
Ryan Greenblatt: I think the chance of mass unemploymentfrom AI is overrated in 2 years and underrated in 7. Same is true for many effects of AI.
Putting aside gov jobs programs, people specifically wanting to employ a human, etc.
Concretely, I don’t expect mass unemployment (e.g. >20%) prior to full automation of AI R&D and fast autonomous robot doubling times at least if these occur in <5 years. If full automation of AI R&D takes >>5 years, then more unemployment prior to this becomes pretty plausible. Among SF/AI-ish people.
But soon after full automation of AI R&D (<3 years, pretty likely <1), I think human cognitive labor will no longer have much value
Dean Ball offers an example of a hard-to-automate bottleneck: The process of purchasing a particular kind of common small business. Owners of the businesses are often prideful, mistrustful, confused, embarrassed or angry. So the key bottleneck is not the financial analysis but the relationship management. I think John Pressman pushes back too strongly against this, but he’s right to point out that AI outperforms existing doctors on bedside manner without us having trained for that in particular. I don’t see this kid of social mastery and emotional management as being that hard to ultimately automate. The part you can’t automate is as always ‘be an actual human’ so the question is whether you literally need an actual human for this task.
Claire Vo goes viral on Twitter for saying that if you can’t do everything for your business in one day, then ‘you’ve been kicked out of the arena’ and you’re in denial about how much AI will change everything.
Settle down, everyone. Relax. No, you don’t need to be able to do everything in one day or else, that does not much matter in practice. The future is unevenly distributed, diffusion is slow and being a week behind is not going to kill you. On the margin, she’s right that everyone needs to be moving towards using the tools better and making everything go faster, and most of these steps are wise. But seriously, chill.
The legal rulings so far have been that your communications with AI never have attorney-client privilege, so services like ChatGPT and Claude must if requested to do so turn over your legal queries, the same as Google turns over its searches.
Jim Babcock thinks the ruling was in error, and that this was more analogous to a word processor than a Google search. He says Rakoff was focused on the wrong questions and parallels, and expects this to get overruled, and that using AI for the purposes of preparing communication with your attorney will ultimately be protected.
My view and the LLM consensus is that Rakoff’s ruling likely gets upheld unless we change the law, but that one cannot be certain. Note that there are ways to offer services where a search can’t get at the relevant information, if those involved are wise enough to think about that question in advance.
Moish Peltz: Judge Rakoff just issued a written order affirming his bench decision, that [no you don’t have any protections for your AI conversations.]
Jim Babcock: Having read the text of this ruling, I believe it is clearly in error, and it is unlikely to be repeated in other courts. The underlying facts of this case are that a criminal defendant used an AI chatbot (Claude) to prepare documents about defense strategy, which he then sent to his counsel. Those interactions were seized in a search of the defendant’s computers (not from a subpoena of Anthropic). The argument is then about whether those documents are subject to attorney-client privilege. The ruling holds that they are not. The defense argues that, in this context, using Claude this way was analogous to using an internet-based word processor to prepare a letter to his attorney. The ruling not only fails to distinguish the case with Claude from the case with a word processor, it appears to hold that, if a search were to find a draft of a letter from a client to his attorney written on paper in the traditional way, then that letter would also not be privileged. The ruling cites a non-binding case, Shih v Petal Card, which held that communications from a civil plaintiff to her lawyer could be withheld in discovery… and disagrees with its holding (not just with its applicability). So we already have a split, even if the split is not exactly on-point, which makes it much more likely to be reviewed by higher courts.
Eliezer Yudkowsky: This is very sensible but consider: The *funniestway to solve this problem would be to find a jurisdiction, perhaps outside the USA, which will let Claude take the bar exam and legally recognize it as a lawyer.
Freddie DeBoer takes the maximally anti-prediction position, so one can only go by events that have already happened. One cannot even logically anticipate the consequences of what AI can already do when it is diffused further into the economy, and one definitely cannot anticipate future capabilities. Not allowed, he says.
Freddie deBoer: I have said it before, and I will say it again: I will take extreme claims about the consequences of “artificial intelligence” seriously when you can show them to me now. I will not take claims about the consequences of AI seriously as long as they take the form of you telling me what you believe will happen in the future. I will seriously entertain evidence-backed observations, not speculative predictions.
That’s it. That’s the rule; that’s the law. That’s the ethic, the discipline, the mantra, the creed, the holy book, the catechism. Show me what AI is currently doing. Show me! I’m putting down my marker here because I’d like to get out of the AI discourse business for at least a year – it’s thankless and pointless – so let me please leave you with that as a suggestion for how to approach AI stories moving forward. Show, don’t tell, prove, don’t predict.
Freddie rants repeatedly that everyone predicting AI will cause things to change has gone crazy. I do give him credit for noticing that even sensible ‘skeptical’ takes are now predicting that the world will change quite a lot, if you look under the hood. The difference is he then uses that to call those skeptics crazy.
Normally I would not mention someone doing this unless they were far more prominent than Freddie, but what makes this different is he virtuously offers a wager, and makes it so he has to win ALL of his claims in order to win three years later. That means we get to see where his Can’t Happen lines are.
Freddie deBoer: For me to win the wager, all of the following must be true on Feb 14, 2029:
Labor Market:
The U.S. unemployment rate is equal to or lower than 18%
Labor force participation rate, ages 25-54, is equal to or greater than 68%
No single BLS occupational category will have lost 50% or more of jobs between now and February 14th 2029
Economic Growth & Productivity:
U.S. GDP is within -30% to +35% of February 2026 levels (inflation-adjusted)
Nonfarm labor productivity growth has not exceeded 8% in any individual year or 20% for the three-year period
Prices & Markets:
The S&P 500 is within -60% to +225% of the February 2026 level
CPI inflation averaged over 3 years is between -2% and +18% annually
Corporate & Structural:
The Fortune 500 median profit margin is between 2% and 35%
The largest 5 companies don’t account for more than 65% of the total S&P 500 market cap
White Collar & Knowledge Workers:
“Professional and Business Services” employment, as defined by the Bureau of Labor Statistics, has not declined by more than 35% from February 2026
Combined employment in software developers, accountants, lawyers, consultants, and writers, as defined by the Bureau of Labor Statistics, has not declined by more than 45%
Median wage for “computer and mathematical occupations,” as defined by the Bureau of Labor Statistics, is not more than 60% lower in real terms than in February 2026
The college wage premium (median earnings of bachelor’s degree holders vs high school only) has not fallen below 30%
Inequality:
The Gini coefficient is less than 0.60
The top 1%’s income share is less than 35%
The top 0.1% wealth share is less than 30%
Median household income has not fallen by more than 40% relative to mean household income
Those are the bet conditions. If any one of those conditions is not met,if any of those statements are untrue on February 14th 2029, I lose the bet. If all of those statements remain true on February 14th 2029, I win the bet. That’s the wager.
The thing about these conditions is they are all super wide. There’s tons of room for AI to be impacting the world quite a bit, without Freddie being in serious danger of losing one of these. The unemployment rate has to jump to 18% in three years? Productivity growth can’t exceed 8% a year?
There’s a big difference between ‘the skeptics are taking crazy pills’ and ‘within three years something big, like really, really big, is going to happen economically.’
There is a huge divide between those who have used Claude Code or Codex, and those who have not. The people who have not, which alas includes most of our civilization’s biggest decision makers, basically have no idea what is happening at this point.
This is compounded by:
The people who use CC or Codex also have used Claude Opus 4.6 or at least GPT-5.2 and GPT-5.3-Codex, so they understand the other half of where we are, too.
Whereas those who refused to believe it or refused to ever pay a dollar for anything keep not trying new things, so they are way farther behind than the free offerings would suggest, and even if they use ChatGPT they don’t have any idea that GPT-5.2-Thinking and GPT-5.2 are fundamentally different.
The people who use CC or Codex are those who have curiosity to try, and who lack motivated reasons not to try.
Caleb Watney: Truly fascinating to watch the media figures who grasp Something Is Happening (have used claude code at least once) and those whose priors are stuck with (and sound like) 4o
Biggest epistemic divide I’ve seen in a while.
Alex Tabarrok: Absolutely stunning the number of people who are still saying, “AI doesn’t think”, “AI isn’t useful,” “AI isn’t creative.” Sleepwalkers.
Zac Hill: Watched this play out in real time at a meal yesterday. Everyone was saying totally coherent things for a version of the world that was like a single-digit number of weeks ago, but now we are no longer in that world.
Zac Hill: Related to this, there’s a big divide between users of Paid Tier AI and users of Free Tier AI that’s kinda sorta analogous to Dating App Discourse Consisting Exclusively of Dudes Who Have Never Paid One (1) Dollar For Anything. Part of understanding what the tech can do is unlocking your own ability to use it.
Ben Rasmussen: The paid difference is nuts, combined with the speed of improvement. I had a long set of training on new tools at work last week, and the amount of power/features that was there compared to the last time I had bothered to look hard (last fall) was crazy.
There is then a second divide, between those who think ‘oh look what AI can do now’ and those who think ‘oh look what AI will be able to do in the future,’ and then a third between those who do and do not flinch from the most important implications.
Hopefully seeing the first divide loud and clear helps get past the next two?
In case it was not obvious, yes, OpenAI has a business model. Indeed they have several, only one of which is ‘build superintelligence and then have it model everything including all of business.’
Ross Barkan: You can ask one question: does AI have a business model? It’s not a fun answer.
Timothy B. Lee: I suspect this is what’s going on here. And actually it’s possible that Barkan thinks these two claims are equivalent.
Tyler Cowen: And so we will [be] rebuilding our world yet again. Or maybe you think we are simply incapable of that.
As this happens, it can be useful to distinguish “criticisms of AI” from “people who cannot imagine that world rebuilding will go well.” A lot of what parades as the former is actually the latter.
Jacob: Who is this “we”? When the strong AI rebuilds their world, what makes you think you’ll be involved?
I think Tyler’s narrow point is valid if we assume AI stays mundane, and that the modern world is suffering from a lot of seeing so many things as sacred entitlements or Too Big To Fail, and being unwilling to rebuild or replace, and the price of that continues to rise. Historically it usually takes a war to force people’s hand, and we’d like to avoid going there. We keep kicking various cans down the road.
A lot of the reason that we have been unable to rebuild is that we have become extremely risk averse, loss averse and entitled, and unwilling to sacrifice or endure short term pain, and we have made an increasing number of things effectively sacred values. A lot of AI talk is people noticing that AI will break one or another sacred thing, or pit two sacred things against each other, and not being able to say out loud that maybe not all these things can or need to be sacred.
Even mundane AI does two different things here.
It will invalidate increasingly many of the ways the current world works, forcing us to reorient and rebuild so we have a new set of systems that works.
It provides the productivity growth and additional wealth that we need to potentially avoid having to reorient and rebuild. If AI fails to provide a major boost and the system is not rebuilt, the system is probably going to collapse under its own weight within our lifetimes, forcing our hand.
If AI does not stay mundane, the world utterly transforms, and to the extent we stick around and stay in charge, or want to do those things, yes we will need to ‘rebuild,’ but that is not the primary problem we would face.
Cass Sunstein claims in a new paper that you could in theory create a ‘[classical] liberal AI’ that functioned as a ‘choice engine’ that preserved autonomy, respected dignity and helped people overcome bias and lack of information and personalization, thus making life more free. It is easy to imagine, again in theory, such an AI system, and easy to see that a good version of this would be highly human welfare-enhancing.
Alas, Cass is only thinking on the margin and addressing one particular deployment of mundane AI. I agree this would be an excellent deployment, we should totally help give people choice engines, but it does not solve any of the larger problems even if implemented well, and people will rapidly end up ‘out of the loop’ even if we do not see so much additional frontier AI progress (for whatever reason). This alone cannot, as it were, rebuild the world, nor can it solve problems like those causing the clash between the Pentagon and Anthropic.
Augmented reality is coming. I expect and hope it does not look like this, and not only because you would likely fall over a lot and get massive headaches all the time:
Eliezer Yudkowsky: Since some asked for counterexamples: I did not live this video a thousand times in prescience and I had not emotionally priced it in
This is actually what the future will look like. When wearable AR glasses saturate the market a whole generation will grow up only knowing reality through a mixed virtual/real spatial computing lens. It will be chaotic and stimulating. They will cherish their digital objects.
9: 10 AM · Feb 17, 2026 · 1.07M Views
853 Replies · 1.21K Reposts · 12.4K Likes
Francesca Pallopides: Many users of hearing aids already live in an ~AR soundscape where some signals are enhanced and many others are deliberately suppressed. If and when visual AR takes off, I expect visual noise suppression to be a major basal function.
Francesca Pallopides: I’ve long predicted AR tech will be used to *reducethe perceived complexity of the real world at least as much as it adds on extra layers. Most people will not want to live like in this video.
Augmented reality is a great idea, but simplicity is key. So is curation. You want the things you want when you want them. I don’t think I’d go as far as Francesca, but yes I would expect a lot of what high level AR does is to filter out stimuli you do not want, especially advertising. The additions that are not brought up on demand should mostly be modest, quiet and non-intrusive.
Ajeya Cotra makesthe latest attempt to explain how a lot of disagreements about existential risk and other AI things still boil down to timelines and takeoff expectations.
If we get the green line, we’re essentially safe, but that would require things to stall out relatively soon. The yellow line is more hopeful than the red one, but scary as hell.
Tao Burga takes the stand that human agency can still matter, and that we often have intentionally reached for better branches, or better branches first, and had that make a big difference. I strongly agree.
We’ve now gone from ‘super short’ timelines of things like AI 2027 (as in, AGI and takeoff could start as soon as 2027) to ‘long’ timelines (as in, don’t worry, AGI won’t happen until 2035, so those people talking about 2027 were crazy), to now many rumors of (depending on how you count) 1-3 years.
Phil Metzger: Rumors I’m hearing from people working on frontier models is that AGI is later this year, while AI hard-takeoff is just 2-3 years away.
I meant people in the industry confiding what they think is about to happen. Not [the Dario] interview.
Austen Allred: Every single person I talk to working in advanced research at frontier model companies feels this way, and they’re people I know well enough to know they’re not bluffing.
They could be wrong or biased or blind due to their own incentives, but they’re not bluffing.
jason: heard the same whispers from folks in the trenches, they’re legit convinced we’re months not years away from agi, but man i remember when everyone said full self driving was just around the corner too
What caused this?
Basically nothing you shouldn’t have expected.
The move to the ‘long’ timelines was based on things as stupid as ‘this is what they call GPT-5 and it’s not that impressive.’
The move to the new ‘short’ timelines is based on, presumably, Opus 4.6 and Codex 5.3 and Claude Code catching fire and OpenClaw so on, and I’d say Opus 4.5 and Opus 4.6 exceeded expectations but none of that should have been especially surprising either.
We’re probably going to see the same people move around a bunch in response to more mostly unsurprising developments.
What happened with Bio Anchors? This was a famous-at-the-time timeline projection paper from Ajeya Cotra, based around the idea that AGI would take similar compute to what it took evolution, predicting AGI around 2050. Scott Alexander breaks it down, and the overall model holds up surprisingly well except it dramatically underestimated the rate algorithmic efficiency improvements, and if you adjust that you get a prediction of 2030.
Saying ‘you would pause if you could’ is the kind of thing that gets people labeled with the slur ‘doomers’ and otherwise viciously attacked by exactly people like Alex Karp.
Instead Alex Karp is joining Demis Hassabis and Dario Amodei in essentially screaming for help with a coordination mechanism, whether he realizes it or not.
If anything he is taking a more aggressive pro-pause position than I do.
Jawwwn: Palantir CEO Alex Karp: The luddites arguing we should pause AI development are not living in reality and are de facto saying we should let our enemies win:
“If we didn’t have adversaries, I would be very in favor of pausing this technology completely, but we do.”
David Manheim: This was the argument that “realists” made against the biological weapons convention, the chemical weapons convention, the nuclear test ban treaty, and so on.
It’s self-fulfilling – if you decide reality doesn’t allow cooperation to prevent disasters, you won’t get cooperation.
Peter Wildeford: Wow. Palantir CEO -> “If we didn’t have adversaries, I would be very in favor of pausing this technology completely, but we do.”
I agree that having adversaries makes pausing hard – this is why we need to build verification technology so we have the optionality to make a deal.
We should all be able to agree that a pause requires:
An international agreement to pause.
A sufficiently advanced verification or other enforcement mechanism.
Thus, we should clearly work on both of these things, as the costs of doing so are trivial compared to the option value we get if we can achieve them both.
Anthropic adds Chris Liddellto its board of directors, bringing lots of corporate experience and also his prior role as Deputy White House Chief of Staff during Trump’s first term. Presumably this is a peace offering of sorts to both the market and White House.
India joins Pax Silica, the Trump administration’s effort to secure the global silicon supply chain. Other core members are Japan, South Korea, Singapore, the Netherlands, Israel, the UK, Australia, Qatar and the UAE. I am happy to have India onboard, but I am deeply skeptical of the level of status given here to Qatar and the UAE, when as far as I can tell they are only customers (and I have misgivings about how we deal with that aspect as well, including how we got to those agreements). Among others missing, Taiwan is not yet on that list. Taiwan is arguably the most important country in this supply chain.
Daniel Kokotajlo: The primary question we estimate an answer to is: How fast is AI progress moving relative to the AI 2027 scenario? Our estimate: In aggregate, progress on quantitative metrics is at (very roughly) 65% of the pace that happens in AI 2027. Most qualitative predictions are on pace.
In other words: Like we said before, things are roughly on track, but progressing a bit slower.
If you let two AIs talk to each other for a while, what happens? You end up in an ‘attractor state.’ Groks will talk weird pseudo-words in all caps, GPT-5.2 will build stuff but then get stuck in a loop, and so on. It’s all weird and fun. I’m not sure what we can learn from it.
India is hosting the latest AI Summit, and like everyone else is treating it primarily as a business opportunity to attract investment. The post also covers India’s AI regulations, which are light touch and mostly rely on their existing law. Given how overregulated I believe India is in general, ‘our existing laws can handle it’ and worry about further overregulation and botched implementation have relatively strong cases there.
Tyler’s effort is a lot like Bengio’s State of AI report. It describes all the facts in a fashion engineered to be calm and respectable. The fact that by default we are all going to die is there, but if you don’t want to notice it you can avoid noticing it.
There are rooms where this is your only move, so I get it, but I don’t love it.
The best available evidence based on benchmarks, expert testimony, and long-term trends imply that we should expect smarter-than-human AI around 2030. Once we achieve this: billions of superhuman AIs deployed everywhere.
This leads to 3 major risks:
AI will distribute + invent dual-use technologies like bioweapons and dirty bombs
If we can’t reliably control them, and we automate most of human decision-making, AI takes over
If we can control them, a small group of people can rule the world
Society is rushing to give AI control of companies, government decision-making, and military command and control. Meanwhile AI systems disable oversight mechanisms in testing, lie to users to pursue their own goals, and adopt misaligned personas like Sydney and Mecha Hitler.
I may sound like a doomer, but relative to many people who understand AI I am actually an optimist, because I think these problems can be solved. But with many technologies, we can fix problems gradually over decades. Here, we may have just five years.
I advocate philanthropy as a solution. Unlike markets, philanthropy can be laser focused on the most important problems and act to prepare us before capital incentives exist. Unlike governments, philanthropy can deploy rapidly at scale and be unconstrained by bureaucracy.
I estimate that foundations and nonprofit organizations have had an impact on AGI safety comparable to any AI lab or government, for about 1/1,000th of the cost of OpenAI’s Project Stargate.
Want to get started? Look no further than Appendix A for a list of advisors who can help you on your journey, co-funders who can come alongside you, and funds for a more hands-off approach. Or email me at [email protected]
andy jones: i am glad this chart is public now because it is bananas. it is ridiculous. it should not exist.
it should be taken less as evidence about anthropic’s execution or potential and more as evidence about how weird the world we’ve found ourselves in is.
Tim Duffy: This one is a shock to me. I expected the revenue growth rate to slow a bit this year, but y’all are already up 50% from end of 2025!?!!?!