“It’s a lemon”—OpenAI’s largest AI model ever arrives to mixed reviews
Perhaps because of the disappointing results, Altman had previously written that GPT-4.5 will be the last of OpenAI’s traditional AI models, with GPT-5 planned to be a dynamic combination of “non-reasoning” LLMs and simulated reasoning models like o3.
A stratospheric price and a tech dead-end
And about that price—it’s a doozy. GPT-4.5 costs $75 per million input tokens and $150 per million output tokens through the API, compared to GPT-4o’s $2.50 per million input tokens and $10 per million output tokens. (Tokens are chunks of data used by AI models for processing). For developers using OpenAI models, this pricing makes GPT-4.5 impractical for many applications where GPT-4o already performs adequately.
By contrast, OpenAI’s flagship reasoning model, o1 pro, costs $15 per million input tokens and $60 per million output tokens—significantly less than GPT-4.5 despite offering specialized simulated reasoning capabilities. Even more striking, the o3-mini model costs just $1.10 per million input tokens and $4.40 per million output tokens, making it cheaper than even GPT-4o while providing much stronger performance on specific tasks.
OpenAI has likely known about diminishing returns in training LLMs for some time. As a result, the company spent most of last year working on simulated reasoning models like o1 and o3, which use a different inference-time (runtime) approach to improving performance instead of throwing ever-larger amounts of training data at GPT-style AI models.
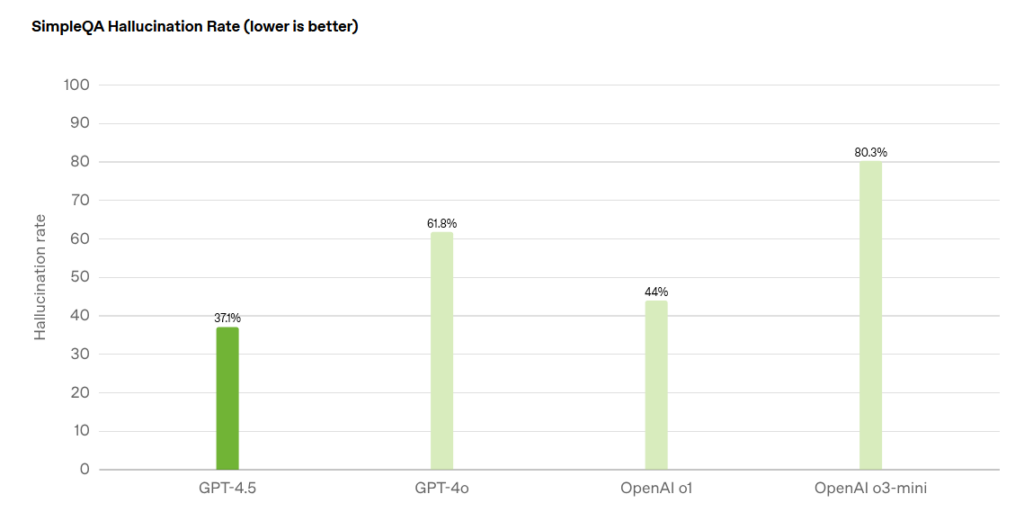
OpenAI’s self-reported benchmark results for the SimpleQA test, which measures confabulation rate. Credit: OpenAI
While this seems like bad news for OpenAI in the short term, competition is thriving in the AI market. Anthropic’s Claude 3.7 Sonnet has demonstrated vastly better performance than GPT-4.5, with a reportedly more efficient architecture. It’s worth noting that Claude 3.7 Sonnet is likely a system of AI models working together behind the scenes, although Anthropic has not provided details about its architecture.
For now, it seems that GPT-4.5 may be the last of its kind—a technological dead-end for an unsupervised learning approach that has paved the way for new architectures in AI models, such as o3’s inference-time reasoning and perhaps even something more novel, like diffusion-based models. Only time will tell how things end up.
GPT-4.5 is now available to ChatGPT Pro subscribers, with rollout to Plus and Team subscribers planned for next week, followed by Enterprise and Education customers the week after. Developers can access it through OpenAI’s various APIs on paid tiers, though the company is uncertain about its long-term availability.
“It’s a lemon”—OpenAI’s largest AI model ever arrives to mixed reviews Read More »