Anthropic’s Claude Haiku 4.5 matches May’s frontier model at fraction of cost
And speaking of cost, Haiku 4.5 is included for subscribers of the Claude web and app plans. Through the API (for developers), the small model is priced at $1 per million input tokens and $5 per million output tokens. That compares to Sonnet 4.5 at $3 per million input and $15 per million output tokens, and Opus 4.1 at $15 per million input and $75 per million output tokens.
The model serves as a cheaper drop-in replacement for two older models, Haiku 3.5 and Sonnet 4. “Users who rely on AI for real-time, low-latency tasks like chat assistants, customer service agents, or pair programming will appreciate Haiku 4.5’s combination of high intelligence and remarkable speed,” Anthropic writes.
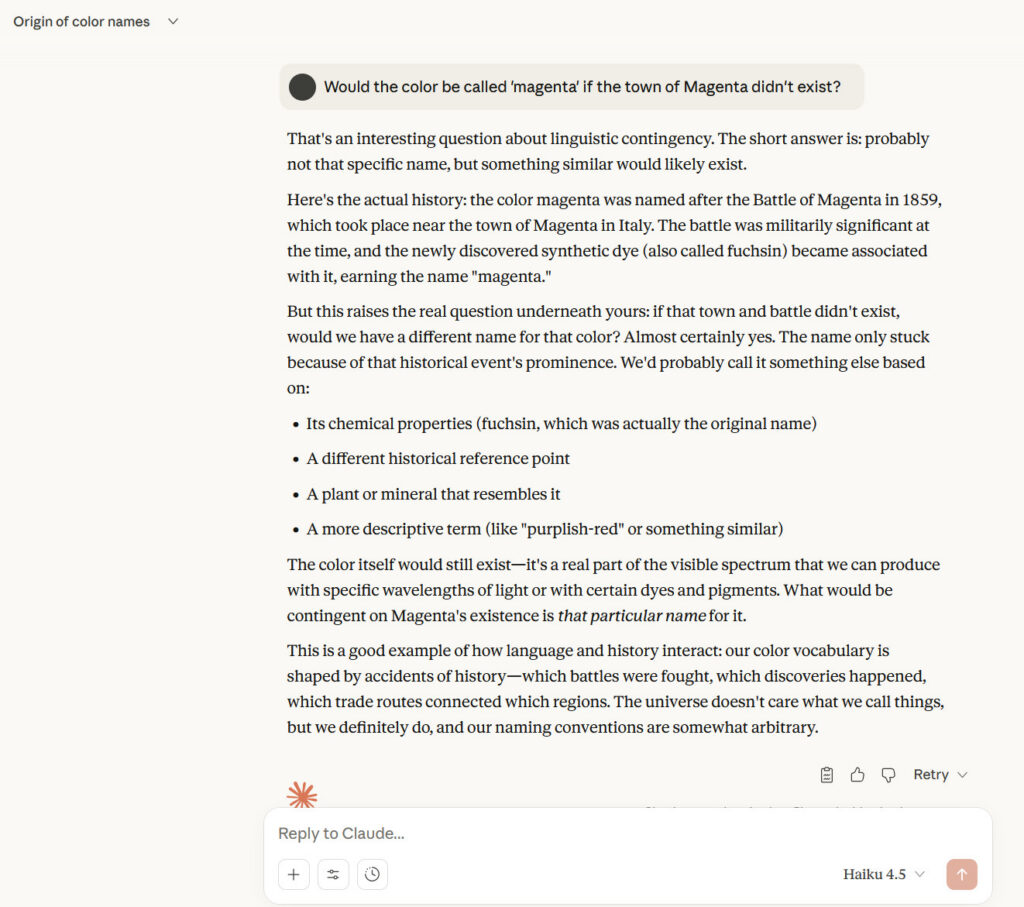
Claude 4.5 Haiku answers the classic Ars Technica AI question, “Would the color be called ‘magenta’ if the town of Magenta didn’t exist?”
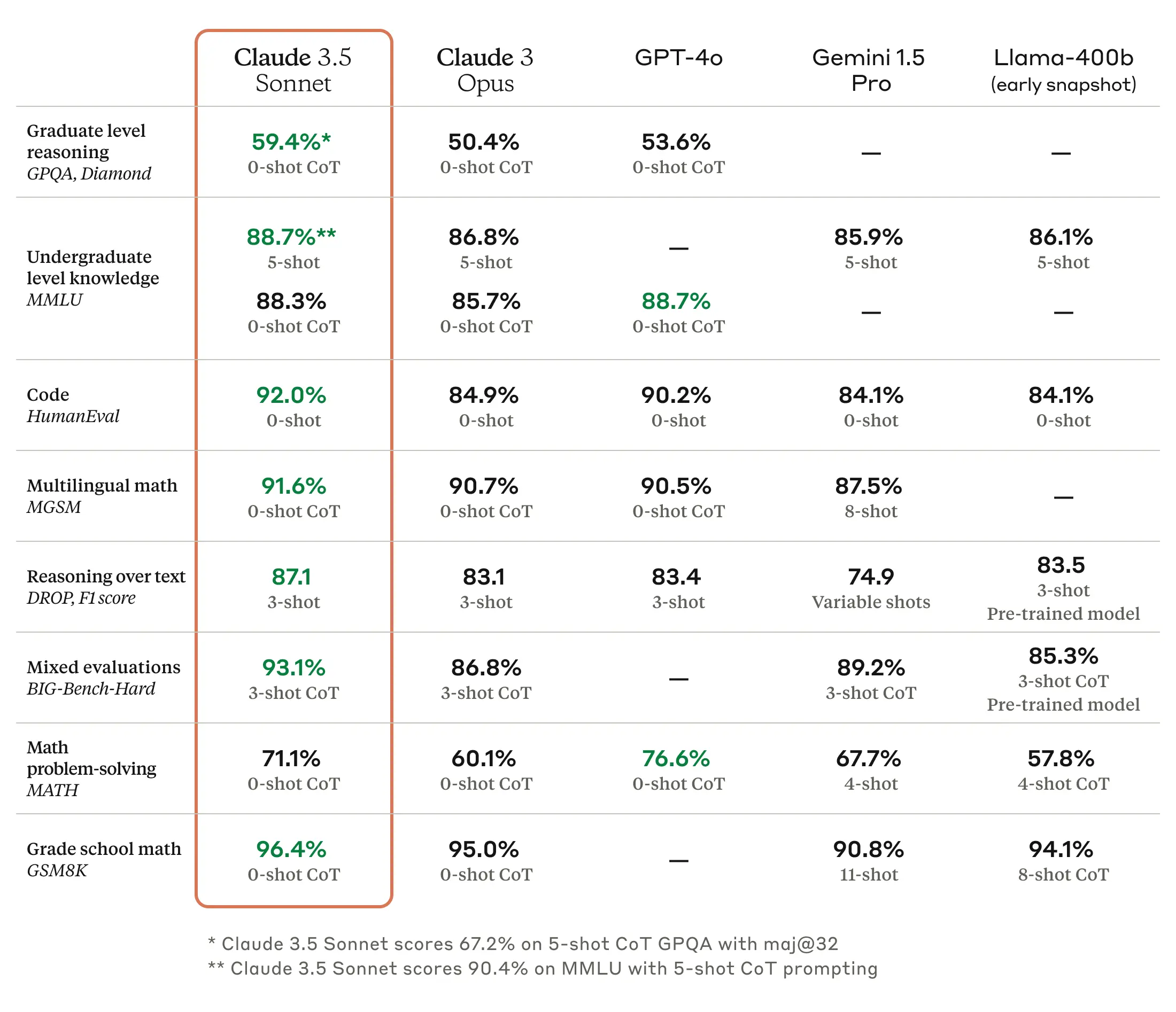
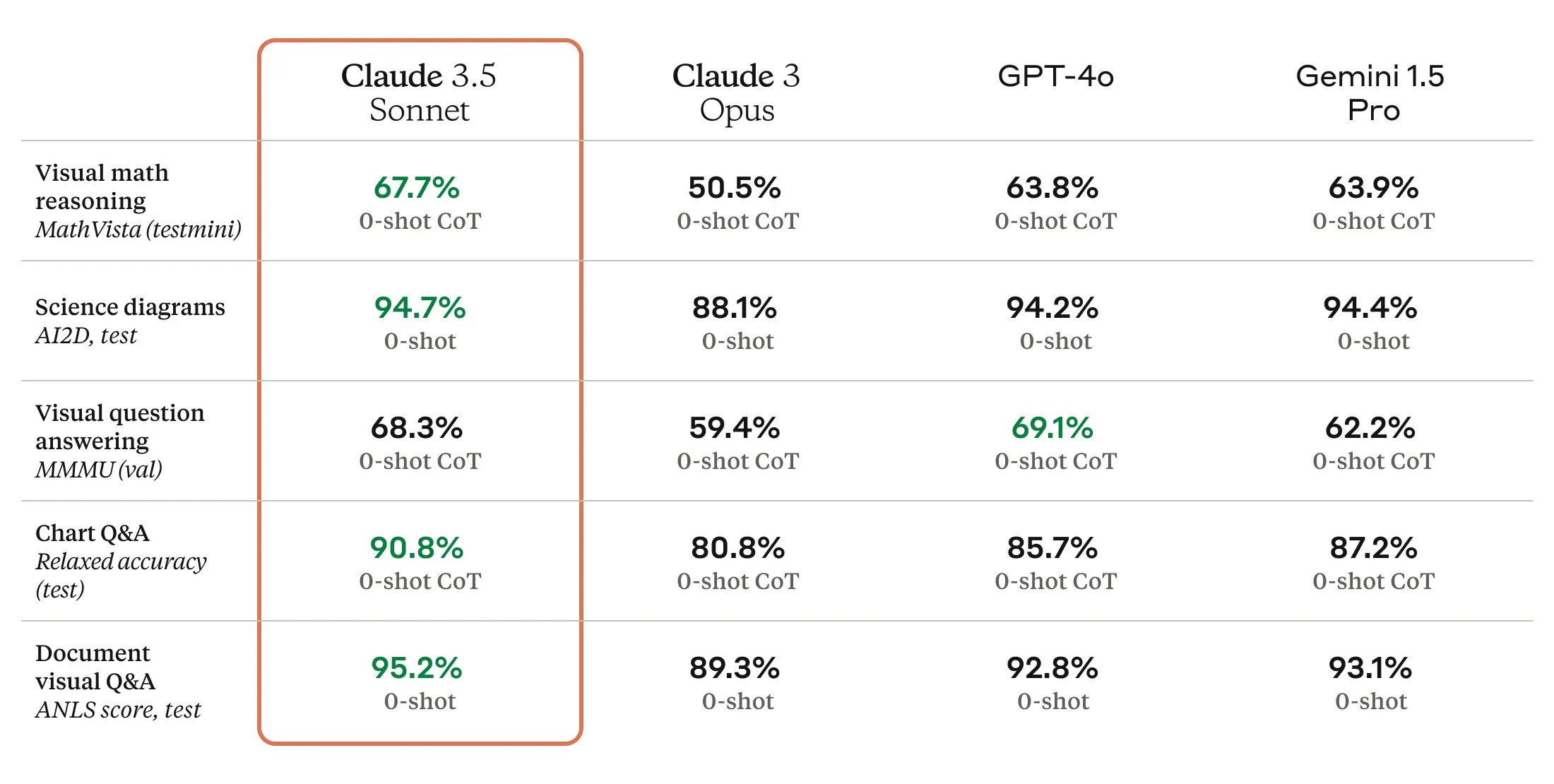
On SWE-bench Verified, a test that measures performance on coding tasks, Haiku 4.5 scored 73.3 percent compared to Sonnet 4’s similar performance level (72.7 percent). The model also reportedly surpasses Sonnet 4 at certain tasks like using computers, according to Anthropic’s benchmarks. Claude Sonnet 4.5, released in late September, remains Anthropic’s frontier model and what the company calls “the best coding model available.”
Haiku 4.5 also surprisingly edges up close to what OpenAI’s GPT-5 can achieve in this particular set of benchmarks (as seen in the chart above), although since the results are self-reported and potentially cherry-picked to match a model’s strengths, one should always take them with a grain of salt.
Still, making a small, capable coding model may have unexpected advantages for agentic coding setups like Claude Code. Anthropic designed Haiku 4.5 to work alongside Sonnet 4.5 in multi-model workflows. In such a configuration, Anthropic says, Sonnet 4.5 could break down complex problems into multi-step plans, then coordinate multiple Haiku 4.5 instances to complete subtasks in parallel, like spinning off workers to get things done faster.
For more details on the new model, Anthropic released a system card and documentation for developers.
Anthropic’s Claude Haiku 4.5 matches May’s frontier model at fraction of cost Read More »