GitHub Copilot moves beyond OpenAI models to support Claude 3.5, Gemini
The large language model-based coding assistant GitHub Copilot will switch from using exclusively OpenAI’s GPT models to a multi-model approach over the coming weeks, GitHub CEO Thomas Dohmke announced in a post on GitHub’s blog.
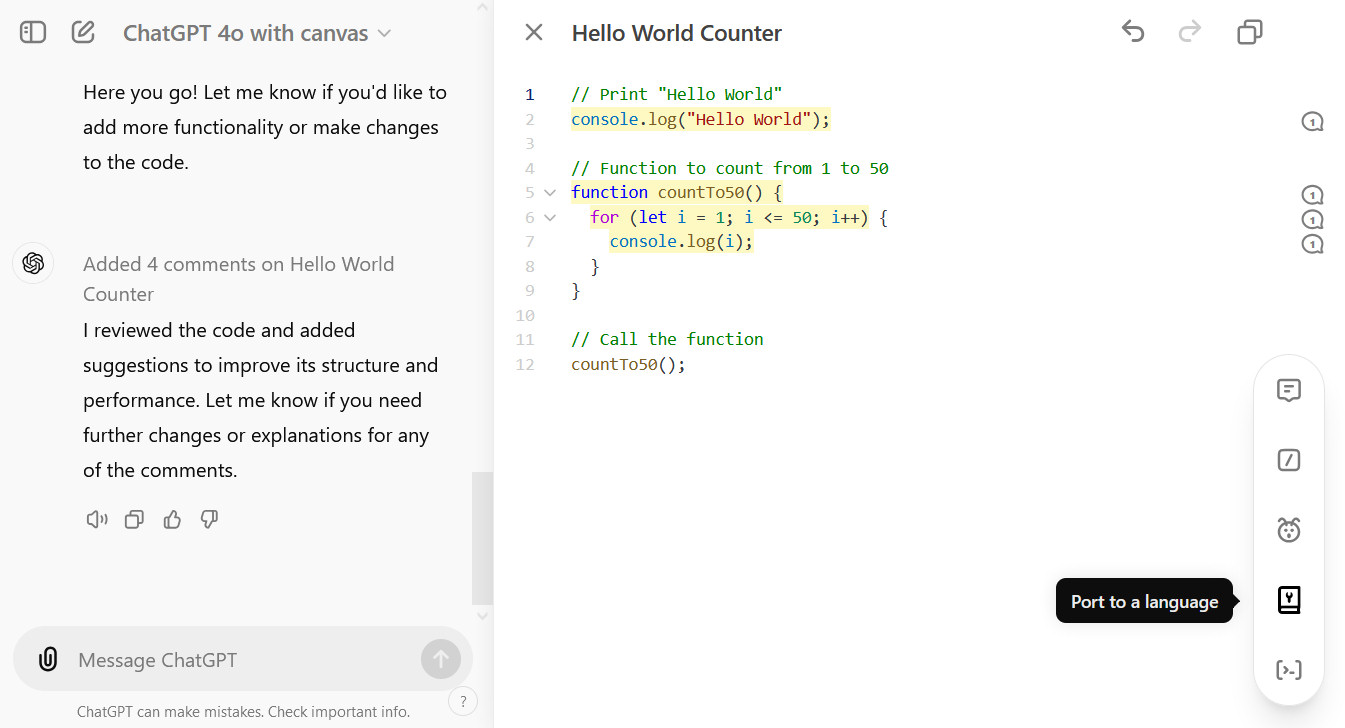
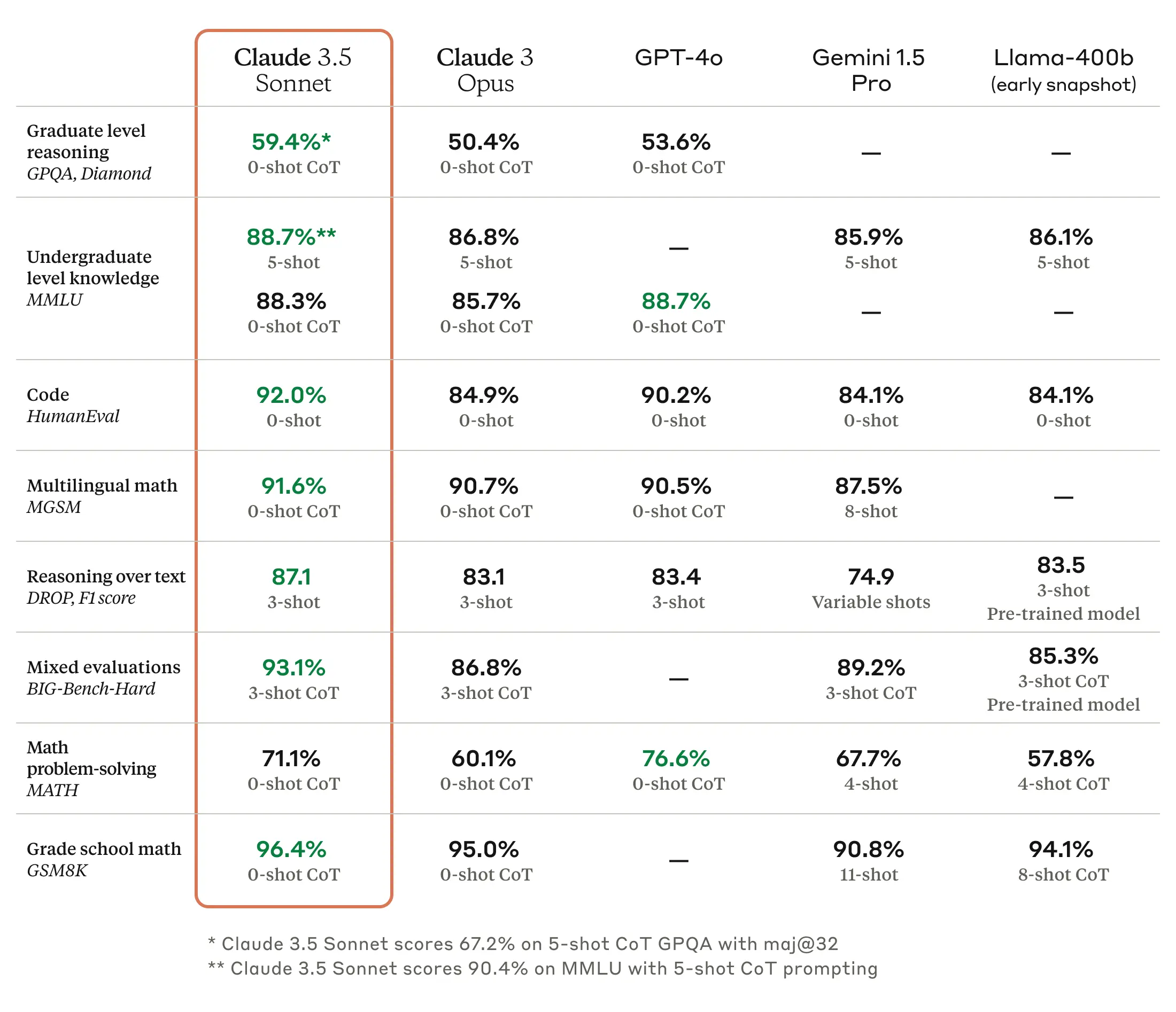
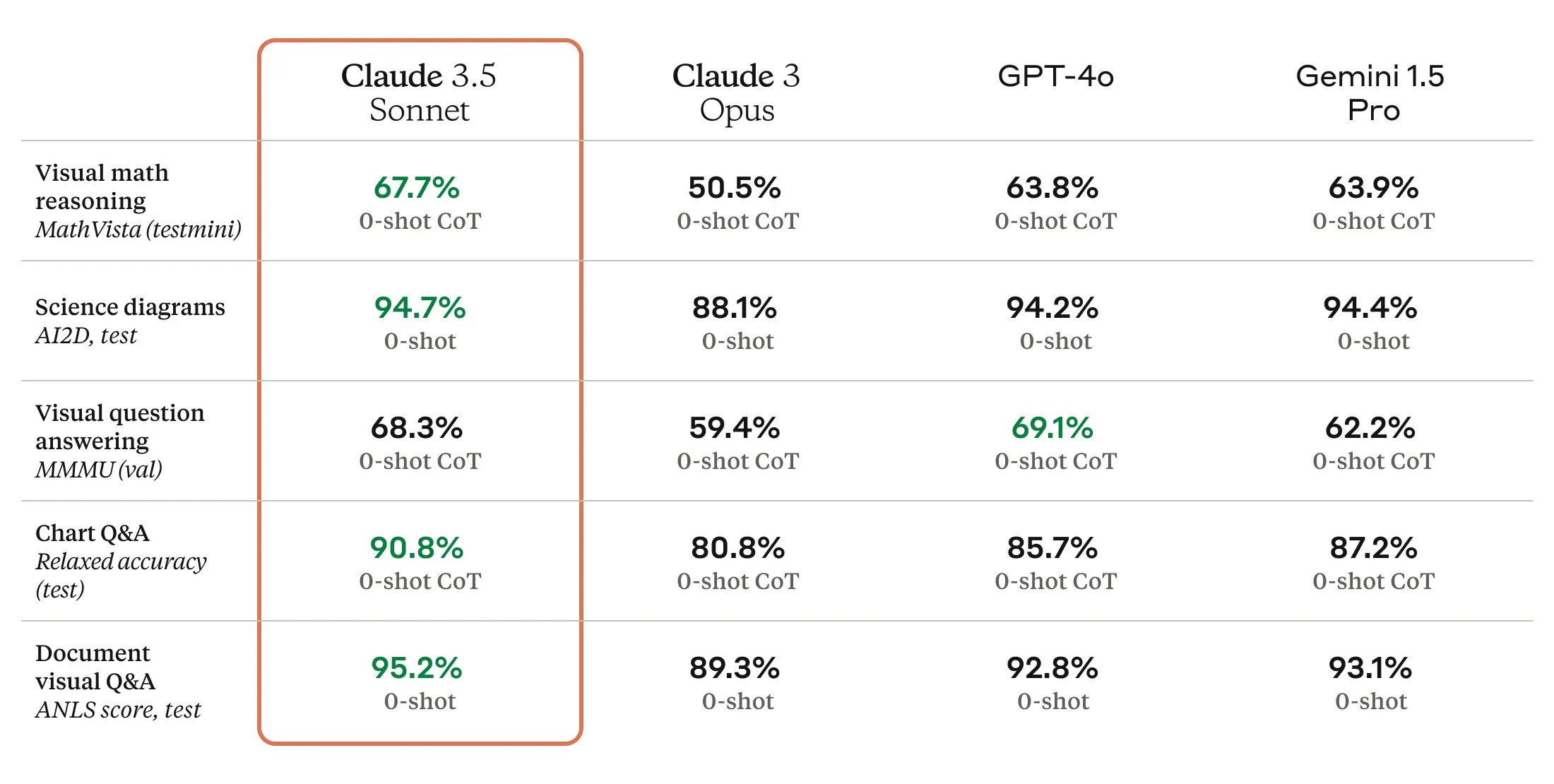
First, Anthropic’s Claude 3.5 Sonnet will roll out to Copilot Chat’s web and VS Code interfaces over the next few weeks. Google’s Gemini 1.5 Pro will come a bit later.
Additionally, GitHub will soon add support for a wider range of OpenAI models, including GPT o1-preview and o1-mini, which are intended to be stronger at advanced reasoning than GPT-4, which Copilot has used until now. Developers will be able to switch between the models (even mid-conversation) to tailor the model to fit their needs—and organizations will be able to choose which models will be usable by team members.
The new approach makes sense for users, as certain models are better at certain languages or types of tasks.
“There is no one model to rule every scenario,” wrote Dohmke. “It is clear the next phase of AI code generation will not only be defined by multi-model functionality, but by multi-model choice.”
It starts with the web-based and VS Code Copilot Chat interfaces, but it won’t stop there. “From Copilot Workspace to multi-file editing to code review, security autofix, and the CLI, we will bring multi-model choice across many of GitHub Copilot’s surface areas and functions soon,” Dohmke wrote.
There are a handful of additional changes coming to GitHub Copilot, too, including extensions, the ability to manipulate multiple files at once from a chat with VS Code, and a preview of Xcode support.
GitHub Spark promises natural language app development
In addition to the Copilot changes, GitHub announced Spark, a natural language tool for developing apps. Non-coders will be able to use a series of natural language prompts to create simple apps, while coders will be able to tweak more precisely as they go. In either use case, you’ll be able to take a conversational approach, requesting changes and iterating as you go, and comparing different iterations.
GitHub Copilot moves beyond OpenAI models to support Claude 3.5, Gemini Read More »