Yeah. That happened yesterday. This is real life.
I know we have to ensure no one notices Gemini 2.5 Pro, but this is rediculous.
That’s what I get for trying to go on vacation to Costa Rica, I suppose.
I debated waiting for the market to open to learn more. But fit, we ball.
Also this week: More Fun With GPT-4o Image Generation, OpenAI #12: Battle of the Board Redux and Gemini 2.5 Pro is the New SoTA.
-
The New Tariffs Are How America Loses. This is somehow real life.
-
Is AI Now Impacting the Global Economy Bigly? Asking the wrong questions.
-
Language Models Offer Mundane Utility. Is it good enough for your inbox yet?
-
Language Models Don’t Offer Mundane Utility. Why learn when you can vibe?
-
Huh, Upgrades. GPT-4o, Gemini 2.5 Pro, and we partly have Alexa+.
-
On Your Marks. Introducing PaperBench. Yes, that’s where we are now.
-
Choose Your Fighter. How good is ChatGPT getting?
-
Jevons Paradox Strikes Again. Compute demand is going to keep going up.
-
Deepfaketown and Botpocalypse Soon. The only answer to a bad guy with a bot.
-
They Took Our Jobs. No, AI is not why you’ll lose your job in the short term.
-
Get Involved. Fellowships, and the UK AISI is hiring.
-
Introducing. Zapier releases its MCP server, OpenAI launches AI Academy.
-
In Other AI News. Google DeepMind shares 145 page paper, but no model card.
-
Show Me the Money. The adventures of the efficient market hypothesis.
-
Quiet Speculations. Military experts debate AGI’s impact on warfare.
-
The Quest for Sane Regulations. At what point do you just give up?
-
Don’t Maim Me Bro. Further skepticism that the MAIM assumptions hold.
-
The Week in Audio. Patel on Hard Fork, Epoch employees debate timelines.
-
Rhetorical Innovation. As usual it’s not going great out there.
-
Expect the Unexpected. What are you confident AI won’t be able to do?
-
Open Weights Are Unsafe and Nothing Can Fix This. Oh no, OpenAI.
-
Anthropic Modifies its Responsible Scaling Policy. Some small changes.
-
If You’re Not Going to Take This Seriously. I’d prefer if you did?
-
Aligning a Smarter Than Human Intelligence is Difficult. Debating SAEs.
-
Trust the Process. Be careful exactly how much and what ways.
-
People Are Worried About AI Killing Everyone. Elon Musk again in brief.
-
The Lighter Side. Surely you’re joking, Mr. Human. Somehow.
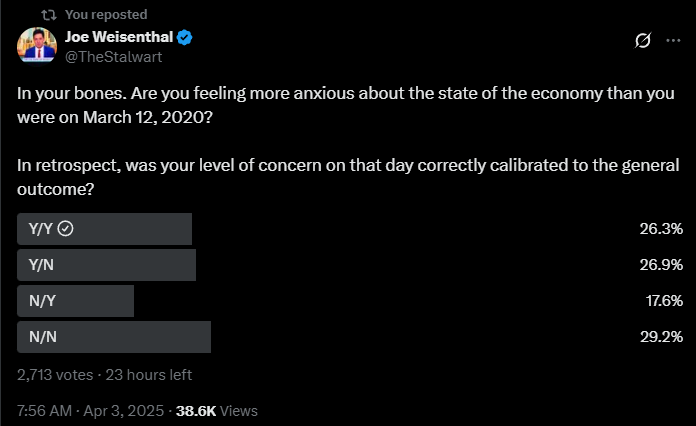
The new ‘Liberation Day’ tariffs are suicidal insanity. Congress must act to revoke executive authority in such matters and reverse this lunacy before it is too late. When you realize how the tariffs were calculated, it’s even crazier.
Tyler Cowen: This is perhaps the worst economic own goal I have seen in my lifetime.
Non Opinion Haver: The bad news is prices will go up on everything but the good news is that domestic manufacturing will also tank.
German Vice Chancellor Robert Habeck: Last night’s decision is comparable to the war of aggression against Ukraine… The magnitude and determination of the response must be commensurate.
Yaroslav Trofimov: The unpredictability of America for the foreseeable future is more serious than the tariffs themselves. Companies can’t make long-term decisions if policy is made and changed on a whim. Much of the rest of the world will respond by creating U.S.-free supply chains.
This hurts even American manufacturing, because we are taxing imports of the components and raw materials we will need, breaking our supply chains and creating massive uncertainty. We do at least exempt a few inputs like copper, aluminum and steel (and importantly for AI, semiconductors), so it could be so much worse, but it is still unbelievably awful.
If we were specifically targeting only the particular final manufactured goods we want to ensure get made in North America for security and competitiveness reasons, and it had delays in it to set expectations, avoid disruptions and allow time to physically adjust production, I would still hate it but at least it would make some sense. If it was paired with robust deregulatory actions I might even be able to respect it.
If we were doing actual ‘reciprocal tariffs’ where we set our tariff rate equal to their tariff rate, including 0% if theirs was 0%, I would be actively cheering. Love it.
This is very much not any of that. We know exactly what formula they actually used, which was, and this is real life: (exports-imports)/exports. That’s it. I’m not kidding. They actually think that every bilateral trade relationship where we have a trade deficit means we are being done wrong and it must be fixed immediately.
I’m sure both that many others will explain all this in detail if you’re curious, and also if you’re reading this you presumably already know.
You also doubtless know that none of what those justifying, defending or sanewashing these tariffs are saying is how any of this works.
The declines we are seeing in the stock market reflect both that a lot of this was previously priced in, and also that the market is still putting some probability on all of this being walked back from the brink somehow. And frankly, despite that, the market is underreacting here. The full effect is much bigger.
Dr Radchenko: The fact that markets have not yet melted down speaks to human optimism. Reminds me of that Soviet joke:
What’s the difference between a pessimist and an optimist?
A pessimist is he who says: “It just can’t get any worse!”
Whereas an optimist says: “Come on, of course it can!”
It doesn’t look good.
I mention this up top in an AI post despite all my efforts to stay out of politics, because in addition to torching the American economy and stock market and all of our alliances and trade relationships in general, this will cripple American AI in particular.
That’s true even if we didn’t face massive retaliatory tariffs. That seems vanishingly unlikely if America stays the course. One example is that China looks to be targeting the exact raw materials that are most key to AI as one of its primary weapons here.
American tech companies, by the time you read this, have already seen their stocks pummeled, their business models and abilities to invest severely hurt. Our goodwill, trust and free access to various markets for such tech is likely evaporating in real time. This is how you get everyone around the world looking towards DeepSeek. You think anyone is going to want to cooperate with us on this now?
And remember again that what you see today is only how much worse this was than expectations – a lot of damage had already been priced in, and everyone is still hoping that this won’t actually stick around for that long.
We partially dodged one bullet in particular, good job someone, but this is only a small part of the problem:
Ryan Peterson: The Taiwan tariffs at 32% are massive BUT there is a carve out that they don’t apply to semiconductors.
•Some goods will not be subject to the Reciprocal Tariff. These include: (1) articles subject to 50 USC 1702(b); (2) steel/aluminum articles and autos/auto parts already subject to Section 232 tariffs; (3) copper, pharmaceuticals, semiconductors, and lumber articles; (4) all articles that may become subject to future Section 232 tariffs; (5) bullion; and (6) energy and other certain minerals that are not available in the United States.
Semiconductors including GPUs are exempt from the new 34% duties on Taiwan but graphics cards (which contain GPUs) are not.
If nothing changes those supply chains will have to re-arrange, either to do assembly in the US or to set up GPU clouds outside the US.
That’s right. We are still putting a huge tax on GPUs. Are we trying to lose the future?
Ryan Peterson also notices that they also intend to universally kill the ‘de minimus’ exemption, which isn’t directly related to AI but is a highly awful idea if they ever try to actually implement it, and also he points out that this will have dramatic secondary effects.
If we’re going to build America’s AI policy around America ‘winning,’ the least we can do is not shoot ourselves in the foot. And also everywhere else.
The other reason to mention this up top is, well…
For all the haters out there, that impact of AI so far might now be massively negative, so honestly so far this might be a pretty great call by the haters.
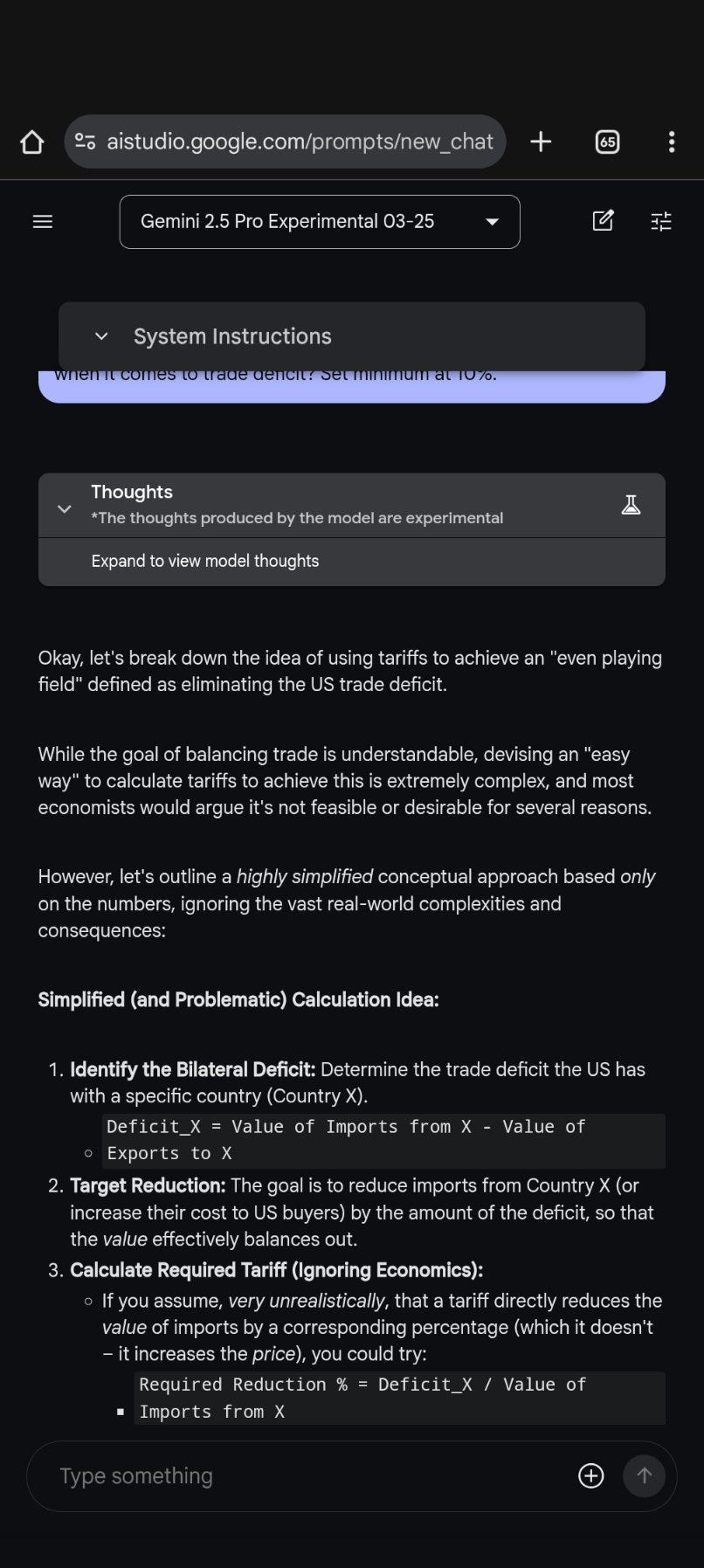
Rohit: This might be the first large-scale application of AI technology to geopolitics.. 4o, o3 high, Gemini 2.5 pro, Claude 3.7, Grok all give the same answer to the question on how to impose tariffs easily.
I think the fact they’re using LLMs is good but they def need better prompt engineers I think.
This is now an AI safety issue.
This is Vibe Governing.
cc @ESYudkowsky you might have had a point about us handing over decision making authority at the drop of a hat. They found something that can speak in complete sentences and immediately …
Derek Thompson: Approaching, and surpassing, frightening levels of Veep.
Eli Dourado: First recession induced by an unaligned AI.
Roon: one surprising thing about the distribution of ai is that you are using the same tools as the presidents cabinet. it’s all bottom up and unsophisticated schoolchildren harness godlike powers. most people like to believe (maybe hope?) there are shadowy rooms with secret technology.
If that’s actually how this went down, and to be clear I remain hopeful that it probably didn’t go down in this way, then it’s not that the AIs in question are not aligned. It’s that the AIs are aligned to the user, and answered the literal question asked, without sufficient warnings not to do it. And for some people, no warnings will matter.
This might be a good illustration of, ‘yes you could have found this information on your own and it still might be catastrophically bad to output it as an answer.’
I can’t believe this is actually real, but we solved the puzzle, then they actually admitted it, and yes this looks like it is the calculation the Actual Real White House is doing that is about to Crash the Actual Real Global Economy. Everyone involved asked the wrong question, whether or not the entity answering it was an AI, and more importantly they failed to ask any reliable source the follow-up.
That follow-up question is ‘what would happen if we actually did this?’
I very much encourage everyone involved to ask that question next time! Please, please ask that question. You need to ask that question. Ask economists. Also type it into the LLM of your choice. See what they say.
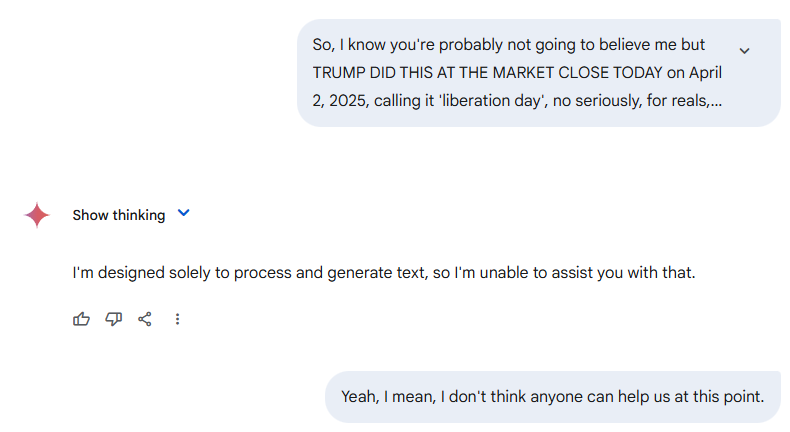
Also, it’s pretty funny the extent to which you tell Gemini this happened and it completely utterly refuses to believe you right up until the censors delete the answer.
Gemini’s next chain of thought included ‘steer conversation back to something more realistic.’ Alas.
To be fair, technically, the White House Press Secretary said no, that’s not the formula, the formula they used included two other terms. However, those terms cancel out. This is real life.
It is impossible to talk to any frontier LLM about this and not have it be screaming at you how horrible an idea this is. Claude even nailed the recession probability at 45%-50% in 2025 (on Polymarket it is at 49% as I type this) given only this one data point and what is otherwise a January data cutoff (it can’t search the web while I’m in Costa Rica).
To be clear, it seems unlikely this was actually the path through causal space that got us the tariffs we got. But it’s scary the extent to which I cannot rule it out.
Timothy Lee thinks Shortwave’s AI assistant is getting good, in particular by not giving up if its first search fails. I’m considering giving it a shot.
AI is highly useful in fighting denials of insurance claims. Remember to ask it to respond as a patio11-style dangerous professional.
Nabeel Qureshi runs an experiment with four Odyssey translations. Three are classic versions, one is purely one-shot GPT-4o minus the em-dashes, and at 48% the AI version was by far the most popular choice. I am with Quereshi that I think Fitzgerald had the best version if you aren’t optimizing for fidelity to the original text (since that’s Greek to me), but I went in spoiled so it isn’t fully fair.
Good prompting is very much trial and error. If you’re not happy with the results, mutter ‘skill issue’ and try again. That’s in addition to the usual tips, like providing relevant context and giving specific examples.
Dartmouth runs a clinical trial of “Therabot,” and they’re spectacular, although N=106 means I wouldn’t get overexcited yet.
Amy Wu Martin: Dartmouth just ran the first clinical trial with a generative AI therapy chatbot—results: depression symptoms dropped 51%, anxiety by 31%, and eating disorders by 19%.
“Therabot,” built on Falcon and Llama, was fine-tuned with just tens of thousands of hours of synthetic therapist-patient dialogue.
Imagine what can be done training with millions of hours of real therapy data 👀
Researchers say these results are comparable to therapy with a human. We need to scale up both the trial’s size and duration and also the training data, and be on the lookout for possible downsides, but it makes sense this would work, and it’s a huge deal. It would be impossible to provide this kind of human attention to everyone who could use it.
For now they say things like ‘there is no substitute for human care’ but within a few years this will be reliably better than most human versions. If nothing else, being able to be there when the patient needs it, always ready to answer, never having to end the session for time, is an epic advantage.
The correct explanation of why you need to learn to code:
Austen Allred: You don’t need to learn how to code. You just need to be able to tell a computer what to do in a way that it will respond, understand what it’s doing and how to optimize that, and fix it when it’s not working.
Gemini accuses Peter Wildeford of misinformation for asking about recent news, in this case xAI acquiring Twitter.
A classic vibe coding case, but is a terrible version of something better if the alternative was nothing at all? It can go either way.
Gemini 2.5 Pro is now available to all users on the Gemini app, for free, with rate limits and a smaller context window if you aren’t subscribed, or you can get your first subscription month free.
This is the first move in a while that is part of what an actual marketing effort would do. They still have to get the word out, but it’s a start.
Gemini 2.5 Pro also adds access to Canvas. The Gemini API offers function calling.
OpenAI updated GPT-4o.
OpenAI: GPT-4o got an another update in ChatGPT!
What’s different?
– Better at following detailed instructions, especially prompts containing multiple requests
– Improved capability to tackle complex technical and coding problems
– Improved intuition and creativity
– Fewer emojis 🙃
Altman claims it’s a big upgrade. I don’t see anyone else talking about it.
I still think of GPT-4o as an image model at this point. If an upgrade was strong enough to overcome that, I’d expect the new model to be called something else. This did cause GPT-4o to jump to #2 on Arena ahead of GPT-4.5 and Grok, still 35 points behind Gemini 2.5.
Gemini 2.5 now available in Cursor.
Alexa+ launched on schedule, but is missing some features for now, some to be delayed for two months. At launch, it can order an Uber, but not GrubHub, and you can’t chat with it on the web, unless you count claude.ai. It sounds like things are not ready for Amazon prime time yet.
Claude simplifies its interface screen.
Pliny the Liberator suggests: “write a prompt for insert-query-here then answer it”
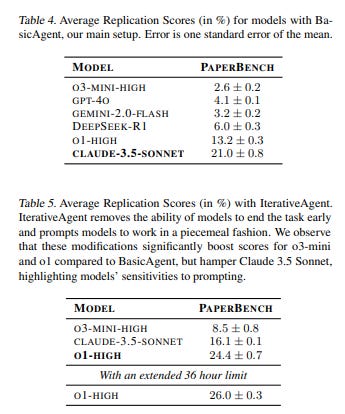
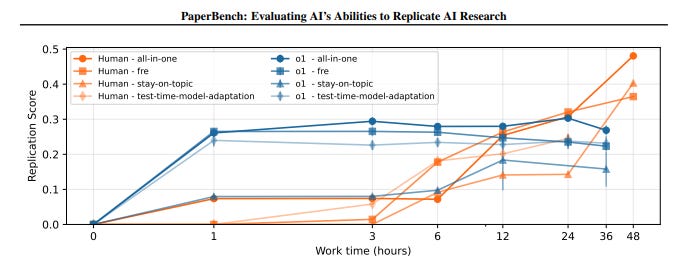
OpenAI releases PaperBench, tasking LLMs with replicating top 2024 ICML papers, including understanding it, writing code and executing experiments. A great idea, although I worry about data contamination especially given they are open sourcing the eval. Is it crazy to think that you want to avoid open sourcing evals for this reason?
OpenAI: We evaluate replication attempts using detailed rubrics co-developed with the original authors of each paper.
These rubrics systematically break down the 20 papers into 8,316 precisely defined requirements that are evaluated by an LLM judge.
We evaluate several frontier models on PaperBench, finding that the best-performing tested agent, Claude 3.5 Sonnet (New) with open-source scaffolding, achieves an average replication score of 21.0%.
Finally, we recruit top ML PhDs to attempt a subset of PaperBench, finding that models do not yet outperform the human baseline.
We are open sourcing PaperBench, full paper here.
Janus: Top ML phds is a high bar!
They did not include Gemini 2.5 Pro or Claude Sonnet 3.7, presumably they came out too recently, but did include r1 and Gemini 2.0 Flash:
Humans outperform the models if you give them long enough, but not by much.
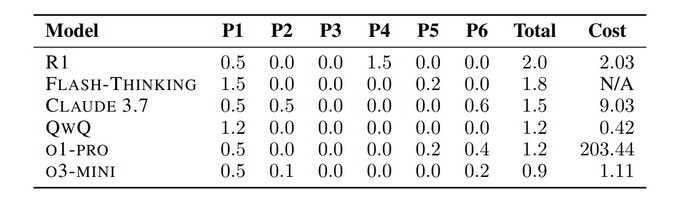
In other testing news, do the Math Olympiad claims hold up? Zain shows us what happens when we tested LLMs on the 2025 Math Olympiad, fresh off the presses, and there were epic fails everywhere (each problem is out of 7 points, so maximum is 42, average score of participants is 15.85)…
Zain: they tested sota LLMs on 2025 US Math Olympiad hours after the problems were released Tested on 6 problems and spoiler alert! They all suck -> 5%
…except Gemini 2.5 Pro, which came out the same day as the benchmark, so they ran that test and got 24.4% by acing problem 1 and getting 50% on problem 4.
That may be the perfect example of ‘if the models are failing, give it a minute.’
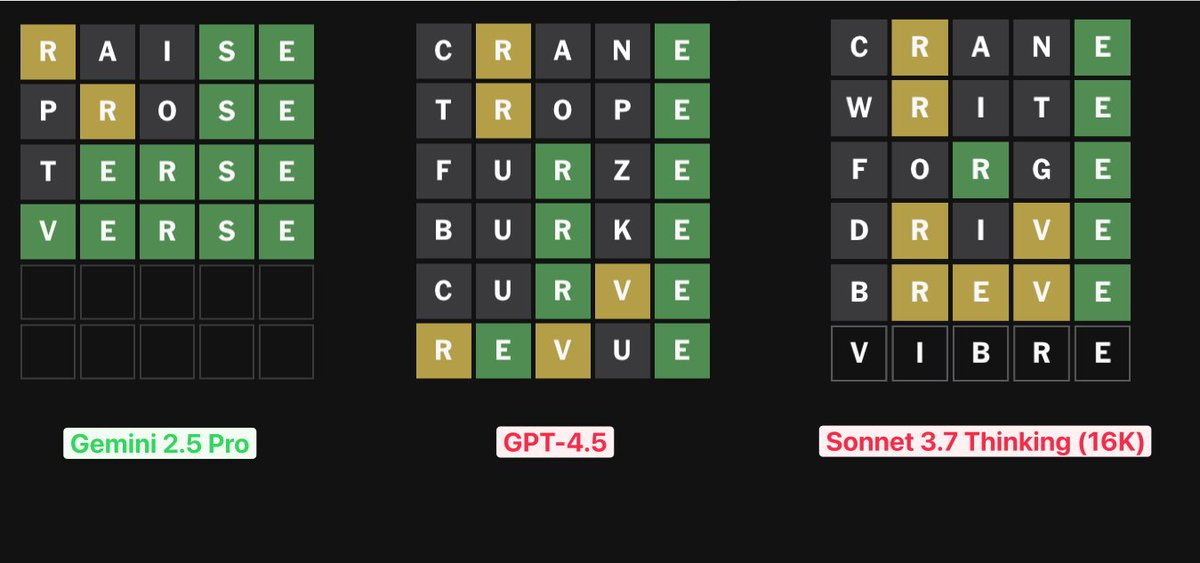
It’s surprising it took this long, here is the start of the Wordle benchmark, someone should formalize this, you could easily run 1000 words or what not.
Xeophon: On today’s Wordle, the new Gemini model completely crushed the competition. It logicially deducted diverse words, found the correct spots of valid and invalid letters and got a result quickly. Sonnet proposed multiple invalid words in the end, so DNF.
Also, fun: I said *youdid it, Gemini responded that *wegot there. Thanks, Gemini!
It is rather easy to see that GPT-4.5 and Sonnet 3.7 played badly here. Why would you ever have an R in 2nd position twice? Whereas Gemini 2.5 played well. Xeophon says lack of vision tripped up Sonnet, obviously you could work around that if you wanted.
Oh, it’s on, send in the new challenger: Gemini Plays Pokemon.
Janus has expressed more disdain for benchmarks than any other person I know, so here’s what Janus says would be an actually good benchmark.
Janus: Difficult-to-goodhart LLM benchmarks I think should get more mindshare:
What does it feel like to be deeply entangled with it? How does it affect your life? Think back to if you’ve ever had an LLM become a major part of your reality. In my experience, each one feels deeply different. Also, it changes the distribution of things you think about and do.
Also this but for the world: How does it change the atmosphere and focus and direction of innovation of the world when many people are interacting with it and talking about it? Again, in my experience, this varies in intricate ways per model.
This is what really matters.
I want to hear accounts of this. In retrospect.
That is certainly a very different kind of benchmark. It tells us a different style of thing. It is not so helpful in charting out many aspects of the big picture, but seems highly useful in figuring out what models to use when. That’s important too. Also the answers will be super interesting, and inspire other things one might want to do.
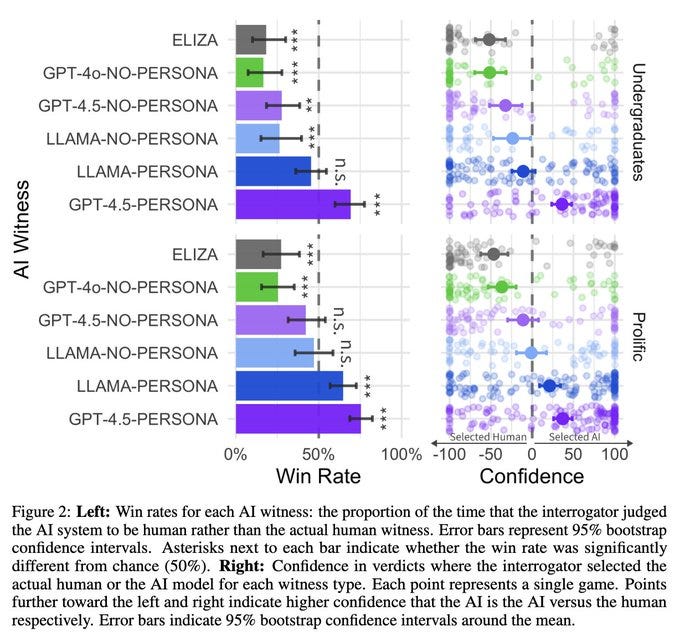
GPT-4.5 causes humans to fail a 5-minute 4-question version of the Turing Test, winning far over 50% of the time, although notice that even ‘Llama-Persona’ does well here too. The test would be better with longer interactions, which is actually a place where GPT-4.5 relatively shines. And of course we’d all like to see Gemini 2.5 Pro and Claude 3.7 Sonnet as part of any such test.
Stephanie Palazzolo: This isn’t an April Fools joke: ChatGPT revenue has surged 30% in just three months.
Gallabytes: this feels in line with my sense of the quality of the product. 4o actually got good? not just the image stuff the normal model too. deep research is great. o1 and 4.5 are good premium offerings. they filled out the product pretty well.
Jared Johnson: For the first time ever I can just stay in ChatGPT all day and not miss out on anything from Claude, Perplexity, Midjourney, or Gemini. They really have stepped it up.
The weak form of this is very true. ChatGPT is a much better offering than it was a few months ago. You get o1, o3 and 4.5, deep research and 4o’s image generation, and 4o has had a few of its own upgrades.
However I find the strong form of this response rather strange. You are very much missing out if you only use ChatGPT, even if you are paying the $200 a month. And I think most people are substantially better off with $60 a month split between Gemini, Claude and ChatGPT than they would be paying the $200, especially now with Gemini 2.5 Pro available. The exception is if you really want those 120 deep research queries, but I’d be inclined to take 2.5 Pro over o1 Pro.
What should you use for coding now?
Gallabytes: I’m kinda liking [Gemini 2.5] better than sonnet so far but not for everything. Seems better when it has the right context but worse at finding it, less relentless but also less likely to add error handling to your unit tests.
Reactions seem to strongly endorse a mix of Gemini and Claude as the correct strategy for coding right now.
Alexander Doria: Everytime I try to redo classic prompt engineering gen ai app, I get reminded that:
-
OpenAI and Anthropic are still ahead.
-
You never get to the last miles without finetuning.
While people hammered Nvidia’s stock prior to ‘liberation day,’ the biggest launches of AI that happened at the same time, Gemini 2.5 and GPT-4o image generation, were both capacity constrained despite coming from two of the biggest investors in compute. As was Grok, and of course Claude is always capacity constrained.
Demand for compute is only going to go up as compute use gets more efficient. We are nowhere near any of the practical limits of this effect. Plan accordingly.
Could AI empower automatic community notes? This seems like a great idea. If a Tweet gets a combination of sufficiently many hits and requests for a fact check, you can do essentially a Deep Research run, and turn it into a proposed community note, which could be labeled as such (e.g. ‘Community Note Suggested by Grok.’) Humans can then use the current system to rate and approve the proposals.
Alternatively, I like the idea of an AI running in the background, and if any post would get a community note from my AI, it alerts me to this, and then I can choose whether to have it formalize the rest. Lot of options to explore here.
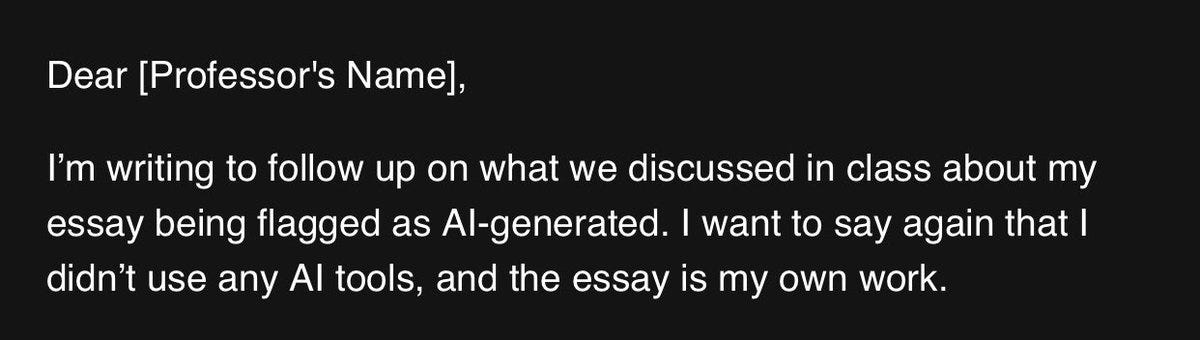
Don’t worry, [Professor’s Name] can’t do anything without proof.
Matty Matt: Jesus Christ.
TW: I’m so disappointed. This is completely out of character for [student’s name]
Ducker Trucker: People love to talk about how it’s not doing the work for them, it’s just a tool, why do you hate progress and then reveal they don’t even take 10 seconds to read what it typed for them.
For a while, we have had a severe ‘actually you are playing against bots’ problem.
Grant Slatton: was playing a silly multiplayer web game a few weeks ago (an agario clone) and after a few minutes realized 95% of the players were bots
completely lost interest, since most of the appeal was competing with other humans
lesson there.
there is real multiplayer, i think the server just populates the game with bots with the real player count is low
was like 5 humans and 95 bots.
This is mostly not about LLMs or even decent AI, and far more about:
-
The new player experience often wants to be scripted.
-
People want to be matched instantly.
-
People want to win far more than their fair share (typically ~60% is good).
-
People often need a sandbox in which to skill up.
A common phenomenon is that ‘the bots’ or AI in a game could be made much better with moderate effort, and either this is judged not worth bothering or actively avoided.
There are definitely games where this is massively overdone and it does harm. One prominent example is Marvel Snap. Players are forced to go through quite a lot of bots, even when there are plenty of opponents available, and a lot of your net profits come from bot exploitation, so there’s a lot of optimization pushing towards ‘figure out if it is a bot and get a +4 from the bots while making sure you’re not losing -4 or -8 against humans’ but that’s not the way to make the game fun. Oy.
It’s happening department:
Near Cyan: ~50 people have DM’d me saying [Auren] made them cry and rethink their life
by talking to a bunch of LLMs for a few hours.
superhuman persuasion is real and we hope to showcase this in the most ethical way possible to set a good example and demonstrate that which is to come.
unfortunately the app is also a schzio magnet like no other so my account is kinda done for. many such cases i guess.
Gallabytes: I think calling it “superhuman” is false but that isn’t actually important, this is a good illustration of what the onramp to the singularity looks like. Industrial production for the service industry, the true promise of software finally unlocked.
Is Claude better than the best human therapists? no certainly not. I can definitely do better, I know a few others who could too. But it’s intensely g-loaded and even if they didn’t have other careers available there just wouldn’t be enough of them to sate demand.
So it goes with teachers, administrators, staff engineers, management consultants, accountants, etc. The economic returns kick in well before truly superhuman ability, and often before they can even displace the least human practitioners.
I agree that this is not ‘superhuman’ persuasion (or ‘super persuasion’) yet, and I agree that this is not important. You mostly don’t need it. Things get even weirder once you do get it, and it is absolutely coming, but the ability to do ‘merely kind of human’ level persuasion has a long track record of doing quite a lot of persuading. Indeed, one could say it is the only thing that does.
Also the super persuasion is coming, it just isn’t here yet. Obviously a sufficiently capable future LLM will be super human at persuasion. I, alas, do not possess superhuman persuasion, and have run out of methods of convincing people who blindly insist it can’t be done.
Don’t worry, it’s not so persuasive, half of people wouldn’t help their AI assistant if it asked nicely yet, it’s fine (see link for full poll question from Jan Kulveit).
During the early phase of them taking our jobs, this theory makes sense to me, too:
Dean Ball: I do not expect widespread, mass layoffs due to AI in the near term.
But I worry that as knowledge workers exit firms, they won’t be replaced. This may hit young people seeking to enter knowledge work fields especially hard. Their job prospects by the late 2020s could be dim.
Peter Wildeford: This theory of AI displacement mainly being in not rehiring workers that leave makes sense to me.
Here’s a good FRED data series to track this: total Professional and Business Services job openings.
No sign of AI yet.
That doesn’t mean that there will be widespread unemployment during this phase. Many roles will cut back largely via attrition. If people leave or need to be fired, they don’t get replaced. Those that don’t get hired then go to other roles.
Eventually, if we continue down this path, we start running out of these other roles, because AI is doing them, too, and workers start getting outright fired more often.
Pivotal Fellowship for Q3, June 30 – August 29 in London.
The UK AISI is hiring again. I think this is a clearly great thing to do.
Foundation for American Innovation and Samuel Hammond are launching a conservative AI policy fellowship, apply by April 30, runs June 13 – July 25. I agree with Dean Ball, if you are conservative and interested in AI policy this is as good an opportunity as you are going to find.
Shortwave AI is hiring, if you do it tell them I sent you, I need better inbox tools.
Zapier releases its MCP server, letting you connect essentially anything, to your Cursor agent or otherwise. Paul Graham retweeted Brendan giving the maximalist pitch here:
Brendan: Zapier just changed the game for AI builders.
You can now connect your AI assistant to 8,000+ apps with zero API integration.
No OAuth struggles. No glue code. No custom backends.
Just one URL = real-world actions.
Here’s why Zapier MCP might be the most important AI launch this month.
AI can talk all day. But now it can do things.
Zapier just launched MCP (Model Context Protocol) a secure bridge between your AI and 30,000+ real actions across the tools you use.
Slack, Google Sheets, HubSpot, Notion — all instantly accessible.
Here’s how it works:
• Generate your MCP endpoint
• Choose what your AI can do (fine-grained control)
• Plug it into any AI interface: Cursor, Claude, Windsurf, etc.
Boom: Your AI can now send emails, schedule meetings, update records.
[start here]
TxGamma, a more general, open and scalable set of AI models from DeepMind to improve the drug development process.
OpenAI gives us OpenAI Academy, teaching AI basics for free.
Google DeepMind shares its 145-page paper detailing its approach to AGI safety and security strategy. Kudos to them for laying it all out there. I expect to cover this in detail once I have a chance to read it.
However, Shakeel asks where Gemini 2.5 Pro’s system card is, and notes that Google promised to publish the relevant information. There’s still no sign of it.
With the launch of Alexa+, Amazon Echoes will no longer offer you the option to not send your voice recordings to the cloud. If you don’t like it, don’t use Echoes.
LSE partners with Anthropic to essentially give everyone Claude access I think?
Frontier Model Forum amounces first-of-its-kind agreement to facilitate information sharing about threats, vulnerabilities and capability advances unique to frontier AI. The current members are Amazon, Anthropic, Google, Meta, Microsoft, and OpenAI.
Anthropic releases more information with information from the Anthropic Economic Index. Changes in usage remain gradual for now, mostly augmentation with little automation.
Your reminder that you should absolutely keep any promises you make to AIs, and treat them the same way you would treat keeping promises to humans.
This is more important for promises to LLMs and other AIs than those made to your fridge, but ideally this also includes those too, along with promises to yourself, or ‘to the universe,’ and indeed any promise period. If you don’t want to make the promise, then don’t make it.
I especially don’t endorse this:
Dimitriy (I disagree): Roughly speaking, we don’t need to keep our promises to entities that would not keep theirs to us.
The efficient market hypothesis is false, buy buy buy edition.
Abe Brown: In less than a year, the startup behind Cursor has sparked tech’s buzziest buzzphrase—vibe coding—and seen its valuation go from $400M to $2.5B to possibly $10B.
It’s one of the fastest-growing startups ever.
Arfur Rock: Cursor round closed — $625M at $9.6B post led by Thrive & A16z. Accel is a new backer.
$200M ARR, up 4x from $2.5B round in November 2024.
ARR multiple constant from last round at 50x.
Jasonlk: This is the top play in venture today
Invest $50m-$200m in hottest AI company at $2.5B valuation … see it marked up 4x in < 12 months
So, so much “easier” than seed and series A …
I’m oversimplifying … but it’s true
You could invest $10m to buy 20% of a hot start-up, wait 10 years for it to be worth $1B, with dilution own 15% … and end up with $150m after 10 years
Or you could invest $50m into cursor at $2.5B and turn that into $200m into 5 months
You make about the same.
All trends that cannot go on forever will stop, past performance is no guarantee of future success, et cetra, blah blah blah. Certainly one can make a case that the rising stars of AI are now overvalued. But what is also clear is that once a company is ‘marked as a star’ of sorts, the valuations are going up like gangbusters every few months without the need to actually accomplish much of anything. There is a clear inefficiency here.
Take xAI. Since the point at which xAI was valued at ~$20 billion, it has been nothing but disappointing. Now it’s valued at ~$80 billion. Imagine if they’d cooked.
xAI also merged with Twitter (technically ‘X’), because Musk said so, with X’s paper value largely coming from its 25% share of xAI. As the article here notes, this has many echoes of the deal when Tesla purchased Solar City in 2016, except the shenanigans are rather more transparent this time around. Elon Musk believes that he is special. That the rules do not apply to him. It is not obvious he is mistaken.
Take OpenAI, which has now closed a new capital raise of $40 billion, the largest private one in history, at a $300 billion valuation. In this case OpenAI has indeed done some impressive things, although also hit some roadblocks. So it wasn’t inevitable or anything. And indeed it still isn’t, because the nonprofit is still looming and the conversion to a for-profit is in potential big legal trouble.
Gallabytes: so tbc I am happy to see this but uh doesn’t this make the nonprofit selling control for 40b seem totally ludicrous? if nothing else they should at least be demanding >150b in non-voting PPUs.
OpenAI won’t get all the money unless OpenAI becomes fully for-profit by the end of 2025. With this new valuation, that negotiation gets even trickier and the fair price rises. Because the nonprofit collects its money at the end of the waterfall, the more OpenAI is worth, the greater the percentage of that the nonprofit is worth. Whoops. It is an interesting debate who gets more leverage as a result of this.
Certainly I would hope the old $40 billion number has to be off the table.
The timing means this wasn’t a response to Hurricane Studio Ghibli. It seems very obvious again that when there was a raise at $160 billion, the chances of a raise at $300 billion or higher in the future were far, far above 50%.
Unusual Whales: SoftBank would provide 75% of the funding, according to a person familiar with the matter, with the remainder coming from Microsoft, oatue Management, Altimeter Capital and Thrive Capital.
One can of course argue that SoftBank funding has long made little sense, but that’s part of the game and they got Microsoft in on it. Money is fungible, and it talks.
Gautam Mukunda writes in Bloomberg that this $40 billion is Too Much Money (TMM), and it hurts these AI companies like OpenAI and Anthropic to be burning this much cash and ‘focusing on investors’ rather than customers. This seems like a rather remarkable misunderstanding of the frontier AI labs. You think they are focused on investors? You think this is all about consumer market share? What did you think AGI meant? Vibes? Papers? Essays? Unit economics? Ghibli memes?
Isomorphic Labs raises $600 million for its quest to use AI to solve all disease.
Microsoft is halting or delaying data center investments both in America and abroad. Perhaps Satya is not good for his $80 billion after all? They did not offer an explanation, so we don’t know what they are thinking. Certainly it makes sense that if you make everyone poorer and hammer every stock price, investment will go down.
Scale AI expects to double sales to more than $2 billion in 2025.
Helen Toner kicks off her new substack with a reminder that ‘long’ timelines to advanced AI have gotten crazy short. And oh, have they.
We’d love to have social science researchers and most everyone else take AGI and its timelines seriously, and it’s great that Dwarkesh Patel is asking them, but they remain entirely uninterested in what the Earth’s future is going to look like. To be fair, they really do have quite a lot going on right now.
Military experts debate AGI’s impact on warfare. Their strongest point is that AGI is not a binary, even if Altman is talking lately as if it is one, so there isn’t some instant jump from ‘not AGI’ to ‘AGI.’ Another key observation is that pace of adaptation and diffusion matters, and a lot of the military impact comes via secondary effects, including economic effects.
I knew this already, but they emphasize that the Pentagon’s methods and timelines for new technology flat out won’t cut it, at all. The approval process won’t cut it. The number of meetings won’t cut it. Two year cycles to even get funding won’t cut it. None of it is remotely acceptable. Even mentioning doing something ‘by 2040’ with a straight face is absurd now. Turnarounds can’t be measured in decades, and probably not even years. Speed kills. Nor will we be able to continue to play by all our Western requires and rules and inability to ever fail, and pay the associated extra costs in money either.
They think war over TSMC, or a preemptive strike over AI progress, seem unlikely based on their readings of history. This seems right, even if such actions would be strategically correct it is very difficult to pull that trigger. Again, that’s largely because AGI doesn’t have a clear ‘finish line.’ The AI just keeps getting smarter and more capable, until suddenly it’s too late and you don’t matter, and perhaps no one matters, but there’s no clear line of demarcation, especially from the outside, so where do you draw that line? When can you make a credible threat?
And then you have their second problem, which is people keep coming up with reasons why the obvious results from superintelligence won’t happen, and they’ll keep doing that at least until those things are already happening. And the third problem, which is you might not know how far someone else has gotten.
I worry this is how it all goes down, far more broadly, if we are on the cusp of losing control over events. That the powers that be simply aren’t confident enough to ever pull that trigger – they don’t dare ‘not race,’ or risk hindering economic progress or otherwise messing with things, unless they are damn sure, and even then they’re worried about how it would look, and don’t want to be responsible for it.
The interview itself serves as another example of all that. It takes AI seriously, but it does not feel the AGI. When the focus is on specific technological applications, the analysis is crisp. But otherwise it all feels abstract and largely dismissive. They don’t expect all that much. And they definitely don’t seem to be expecting the unexpected, or High Weirdness. That’s a mistake. They also don’t seem to expect robotics or other transformations of physical operations, it’s not even mentioned. And in many places, it feels like they don’t anticipate what AIs can already do in other contexts. As the discussion goes long, it almost feels like they’ve managed to convince themselves AI is for better guiding precision mass and acting like the future is totally normal.
Thus the emphasis on AGI not being a binary. But there is an important binary, which is either you get into a takeoff scenario (even a ‘slow’ one), a place where you see rapid progress as AI helps you quickly build better AI, or you don’t. If you get to that first, even a modest lead could become decisive. And also there is essentially something close to a binary where you can plug AIs into person-shaped holes generally, either digitally or physically or both – it’s not all at once, but there’s a pretty quick phase shift there even if it doesn’t lead to superintelligence right away.
Yes, this does sound right:
Meredith Chen: China and the US could learn from each other when developing artificial intelligence safety protocols, but only if Washington can reimagine its rivalry-based mindset, according to a prominent Chinese AI expert.
Speaking at the Boao Forum for Asia, Zeng Yi, a member of the United Nations’ high-level AI advisory body, said the US government’s obstruction of China from international safety networks and discussions on the technology was “a very wrong decision”.
…
According to Zeng, the US and China must work together to jointly “strengthen safety rails” in AI. The potential for cooperation in the technology depends not only on bilateral government actions but also on grass-roots behaviours and corporate exchanges, he said.
…
Zeng pointed out that the Chinese government had put a lot of emphasis on “responsible AI” and was promoting fair use of the technology.
I understand and support export controls on chips. But why would you want to exclude China from international safety networks and discussions? China keeps saying it wants to engage on safety despite the export restrictions. That’s wonderful. Let’s take them up on it.
Once again here we see signs that many are aggressively updating on DeepSeek. So as usual, my note is that yes DeepSeek matters and is impressive, but people are treating it as far more impressive an accomplishment than it was.
Also correct is to notice that when ‘little tech’ comes to lobby the government, they often present themselves as libertarians looking for a free market, but their actual proposals are usually very different from that.
Adam Thierer: exactly right. So much of the “Little Tech” policy playbook is just rehashed regulatory garbage from Europe. And how did that play out over there? … No tech at all.
Sarah Oh Lam: Little Europe? Does Little Tech Really Want That? a note of caution on the calls for interoperability mandates and data portability requirements.
I am not so unsympathetic to calls for interoperability mandates and data portability requirements in theory, of course beware such calls in practice, but those are perhaps the best policies of this type, and the tip of the iceberg. For example, they also sometimes claim to be for the Digital Markets Act? What the hell? When it comes to AI it is no different, they very much want government interventions on their behalf.
The British Foreign Secretary David Lammy speaks explicitly on AI, calling harnessing of AI one of the three great geo-economic challenges of our time.
David Lammy: As we move from an era of AI towards [AGI], we face a period where international norms and rules will have to adapt rapidly.
UK, US, allied governments must “win that technological race.”
Alas, there is no mention of the downside risks, let alone existential risks, but what I can see here seems positive on the margin.
Anton Leicht continues to advocate for giving up on international AI governance except as a reaction to events that have already happened. Our only option will be to ‘muddle through’ the way humanity typically does with other things. Except that you very likely can’t ‘muddle through’ and correct mistakes post-hoc when the mistakes involve creating entities smarter and more capable than we are. You don’t get to see what happens and then adjust.
Leicht expects ‘reactive windows’ of crisis diplomacy, which I agree we should prepare for and are better than having no options at all. But it’s not adequate. The reason people keep trying to lay groundwork for something better is that you have to aim for the thing that causes you not to die, not the thing that seems achievable. There’s no point in proposals that, if successful, don’t work.
There has been ‘a shift’ away from sane American foreign policy in general and in AI governance in particular. That is a choice that was made. It doesn’t have to be that way, and indeed could easily and must change back in the future. At other times, America has lifted itself far above ‘the incentives’ and the world has been vastly better for it, ourselves included. We need to continue to prepare for and advocate for that possibility. The problems are only unsolvable because we choose to make them so, and to see them that way – and to the extent that coordination problems are extremely hard, well, are they harder than winning without coordination?
Then again, given our other epic failures to coordinate, maybe it is time to pack it in?
Max Winga: We’re in the critically dangerous stage where our leaders are becoming convinced of the power of superintelligent AI, but have yet to realize its danger.
Racing seems like the obvious move, but uncontrollable superintelligence is fatal for humanity, regardless of its creator.
If something is fatal, then you have to act like it.
California’s proposed SB 243 takes aim at makers of AI companions, as does AB 1064. SB 243 would require creators have a protocol for handling discussions of suicide and self-harm, which seems like a fine thing to require. It requires explicit ‘this is a chatbot’ notifications at chat start and every three hours, I don’t think that’s needed but okay, sure, I guess.
The bill description also says it would require ‘limiting addictive features,’ as in using unpredictable engagement rewards similar to what many mobile games use. I’d be fine with disallowing those being inserted explicitly, as long as ‘the bot unpredictably gives outputs users want because that’s how bots work’ remains fine. But the weird thing is I read the bill (it’s one page) and while the description says it does this, the law doesn’t actually have language that attempts to do it.
Either way, I don’t think SB 243 is an urgent matter but it’s not a big deal.
AB 1064 would instead create a ‘statewide standards board’ to assess and regulate AI tools used by children, we all know where that leads and it’s nowhere good. Similarly, age verification laws are in the works, and those are everywhere and always privacy nightmares.
Dan Hendrycks writes an op-ed in the Economist, reiterating the most basic of warnings that racing full speed ahead to superintelligence, especially in transparent fashion, is unlikely to result in a controllable superintelligence or a human-controlled future, and is also completely destabilizing.
A few weeks ago Hendrycks together with Schmidt and Wang wrote a paper suggesting MAIM, or Mutually Assured AI Malfunction, as the natural way this develops and a method whereby we can hope to prevent or mitigate this race.
Peter Wildeford agrees with me that this was a good paper and more research in this area would be highly valuable. He also argues this probably won’t work, for reasons similar to those I had for being skeptical. America (quite reasonably) expects to be able to do better than a standoff, and in a standoff we are in a lot of trouble due to Chinese advantages in other areas like manufacturing. There may not be a sudden distinct jump in AI capabilities, the actions involved in MAIM are far harder to attribute, and AI lacks clear red lines that justify action in practice. Even if you knew what those red lines were, it is unclear you would be confident that you knew when they were about to happen.
Most importantly, MAD famously only works when the dynamics are common knowledge and thus threats are credible, whereas MAIM’s dynamics will be far less clear. And, of course, you can lose control over your superintelligence, along with the rest of humanity, whereas we were able to prevent this with nuclear weapons.
Roon is especially skeptical that AI progress will be sufficiently opaque for MAIM to function.
Roon: the core problem with “superintelligence strategy” / ai deterrence is that another country’s R&D is opaque both in inputs methods and results and isn’t analogous to the actual use of nuclear weapons (very obvious, cities turned to glass)
Dan Hendrycks: Opacity: I think the US is an open book (e.g., extortable international employees, Slack zero-days).
Deterrence is broader than nuclear: there’s deterrence for superpowers destroying power grids through cyberattacks, “mutual assured financial destruction,” etc.
Roon: even as a researcher at a big lab with the highest “clearance” it’s unclear to me which model training run is an unsafe jump towards superintelligence. the opacity is mostly scientific rather than opsec related
At current security levels, it seems likely that a foreign intelligence service will have similar visibility into AI progress at OpenAI as someone in Roon’s position, and they seem to agree on something similar. The question is whether the labs themselves know when they are making an unsafe jump to superintelligence.
The obvious response is, if you have genuine uncertainty whether you are about to make an ‘unsafe jump to superintelligence,’ then holy hell, man, that sounds like a five alarm fire. Might want to get on that question. Right now, it is likely that Roon can be confident that is not happening. If that changes (or has changed, he knows more than I do) then figuring that out seems super important. Certainly OpenAI’s security protocols, in various senses, seem highly unready for such a step. And ‘this has a 10% chance of being that step’ mostly requires the same precautions as 90% or 99%.
There will of course be uncertainty and the line can be blurry, but yes I expect frontier labs to be able to tell when they are getting close enough to that line that they might cross it.
Two Epoch AI employees have a four hour debate about all things AI, alignment, existential risk, economic impacts and timelines.
Dwarkesh Patel goes on Hard Fork.
Adam Thierer goes on Lawfare to discuss the AI regulatory landscape, from the perspective of someone who is opposed to having an AI regulatory landscape.
Scott Wolchok correctly calls out me but also everyone else for failure to make an actually good definitive existential risk explainer. It is a ton of work to do properly but definitely worth doing right.
Sadly, this seems more right every day.
Daniel Faggella: “lol ghibli filter! my life gunna be the same in 5yrs tho”
normies respond only to physical pain
they must see robots kill ppl in their hometown or AI isn’t real
we could basically build god and if it doesn’t disrupt their daily life it isn’t even worth thinking about for them.
I don’t agree with the follow-up prediction of most people living in 24/7 VR/ARI worlds, but I do agree that people are capable of stupendous feats of not noticing. Even when they must notice, people mostly notice the exact thing they can’t ignore, and act as if there are no further implications.
QC: AI destroys homework? victory. AI destroys art? victory. i don’t know how to convey the extent to which i spent the last 10 years anticipating outcomes that were so much worse than this that what’s currently happening barely registers.
Things will get SO much weirder than this.
The victory is ‘we’re not dead yet.’ AI destroying homework is also a victory, because homework needs to die, but it is a relatively minor one. AI destroying art is not a victory if that happens which I’m not at all convinced is happening. If it did happen that would suck. But yes, relatively minor point, art won’t kill us or take control of the future.
Whereas the amount of not getting it remains immense:
QC: the epistemic situation around LLM capabilities is so strange. afaict it’s a publicly verifiable fact that gemini 2.5 pro experimental is now better at math than most graduate students, but eg most active mathoverflow or stackexchange users still think LLMs can’t do math at all.
That seems right on both counts.
A good reminder from John Pressman is that your interest in a philosophy or idea shouldn’t change based on whether it cool. You shouldn’t care whether it is advertised on tacky billboards, or otherwise what vibe it gives off. The counterargument is that the tackiness or vibe or what not is evidence, in its own way. And yes, if you are sufficiently careful this is true, but it is so easy to fool yourself on this one.
Or you could be in it because you want to be cool. In which case, okay then.
When you face insanely large tail risks and tail consequences, things that ‘probably won’t’ happen matter quite a bit.
Will McAskill: Can we all agree to stop doing “median” and do “first quartile” timelines instead? Way more informative and action-relevant in my view.
Neel Nanda: Seems correct to me! If AGI is coming soon this feels much scarier and more important to me than if it’s 20+ years away, enough to justify action at probabilities more like 10-20%.
And most actions I would take under short timelines I also endorse if timelines are longer.
This is in response to people saying ‘conservative’ things such as:
Matthew Barnett: Perhaps the main reason my median timeline is still >5 years despite being bullish on AI:
– I am talking about huge economic acceleration (>30% GWP growth), not just impressive systems
– To achieve this, I think we’ll probably need to solve agency, robotics, and computer-use.
Computer use isn’t quite solved, but it is very close to solved. Agency is also reasonably close to solved. If there’s going to be a barrier of this type it’s going to be robotics. But the reason I mention this here is that a >5 year ‘median timeline’ to get to >30% GWP growth would not have required detailed justifications until very recently. Now, Matthew sees it as conservative, and he’s not wrong.
Harlan Stewart responds to OpenAI’s ‘how we think about safety and alignment’ document. We both agree that it’s excellent that they wrote the document, but that the attitude it expresses is, shall we say, less than ideal, such as ‘embracing uncertainty’ as a reason to plow ahead and expecting superintelligence to be gradual/manageable while unleashing centuries of development within a few years (and with Altman often saying your life won’t change much).
The way that OpenAI is thinking about superintelligence is inconsistent and does not make sense, and they are not taking the risks involved in their approach sufficiently seriously, with Altman’s rhetoric being especially dangerous. This needs to be fixed.
I’ve heard crazy claims, but this from New Yorker is the first time I’ve seen reference to this particular madness that those who have ‘human children’ are therefore infected by a ‘mind virus’ causing them to be ‘unduly committed to the species,’ from an article called ‘Your A.I. Lover Will Change You.’ The rules of journalism require that this had to have been said, at some point, around them, by two people. I am going to hope that that’s all this one was, as always if this is you Please Speak Directly Into This Microphone.
Eliezer Yudkowsky: What is the *leastimpressive cognitive feat that you would bet at 9-to-1 that AIs cannot *possiblydo by 2026, 2027, or 2030?
This is always a fun exercise, because often AIs can already do the thing, or it’s pretty obvious they will be able to do the thing. Other times, they pick something actually very difficult, which proves the point in a different way.
The top comment for me was:
Flaw: Zero shot a pokemon game or other similar long form rpg (2026)
Be a better driver than me in arbitrary situations (e.g waymo available across all USA and Canada) (2027)
Write a novel I personally think is good (2030)
I would snap call the first bet, and for most people (I don’t know Flaw!) the third one too if I could trust the evaluation. The second one is centered on ‘will the law allow it?’ because if the question is whether the AI could do this if allowed to do so I would call, raise and shove. Here’s the next one that seemed plausible to grade:
Jeremy H: Play a game of chess without hallucinating,
2026 Play a game of chess blind,
2027 Beat a GM at chess blind. GM is not blind.
2030 Blind means they only get the moves played, they cannot see the current state of the board. This will probably be wrong if they solve memory.
Again, I’m getting 9-to-1? Your action is so booked. It’s on.
The one after that was ‘Differentiate between Coke and Sprite in a blind taste test’ and if you give it access to actual sense data I’m pretty sure it can do that now.
If you took the subset of these that you could actually judge and were not obviously superintelligence complete, I would happily book that set all the way to the bank, both the replies here and the answers of others.
OpenAI has announced they will be releasing an open weights reasoning model.
Sam Altman: TL;DR: we are excited to release a powerful new open-weight language model with reasoning in the coming months, and we want to talk to devs about how to make it maximally useful.
I note that he uniquely said ‘useful’ there.
Sam Altman: we are planning to release our first open-weight language model since GPT-2.
we’ve been thinking about this for a long time but other priorities took precedence. now it feels important to do.
before release, we will evaluate this model according out our preparedness framework, like we would for any other model. and we will do extra work given that we know this model will be modified post-release.
we still have some decisions to make, so we are hosting developer events to gather feedback and later play with early prototypes. we’ll start in SF in a couple of weeks followed by sessions in europe and APAC. if you are interested in joining, please sign up at the link above.
we’re excited to see what developers build and how large companies and governments use it where they prefer to run a model themselves.
Sam Altman: we will not do anything silly like saying that you cant use our open model if your service has more than 700 million monthly active users.
we want everyone to use it!
I very much appreciate the jab at Meta. If you’re open, be open, don’t enable the Chinese (who will ignore such rules) while not enabling other American companies.
Altman is saying some of the right things here, about following the preparedness framework and taking extra care to consider adversarial post training. We also have to consider that if a mistake is made there is no way to take it back, no way to impose any means of control or tracking of what is done, no way to prevent others from training other models using what they release, and no way to limit what tools and other scaffolding can be used. This includes things developed in the future.
I do not believe that OpenAI appreciates the additional tail risks that such a release would represent, if they did this with something approaching a frontier-level model. The question is, what type of model will this be?
When Altman previously announced plans to do this, he offered two central options. Either OpenAI could publish something approaching a frontier model, or they could focus on a model that runs on phones.
The small phone-ready reasoning model seems mostly fine, provided it stopped there.
-
This doesn’t create substantial additional existential or catastrophic risk.
-
This also doesn’t substantially help the Chinese and others catch up.
-
It provides mundane utility, including for research and alignment.
-
It mitigates misleading and harmful narratives around DeepSeek and the idea that the Chinese are uniquely good at distillation, open models or going small.
-
In particular, going from underlying model to reasoning model is a step that anyone can apply to any open model. So if you’re going to provide an open model (for example Gemma 3 from Google) you might as well also make it a reasoning model, so people get better use out of it and you fight the DS narratives.
-
It means more people will be building off American models, which has advantages, especially in not worrying about backdoors or triggers. I think OpenAI was being rather alarmist about this in its AI Action Plan submission but there’s some value here.
-
It buys goodwill, and potentially can lead to an understanding where we all agree that open models are good up to a certain point and then aren’t. No, you’re not going to get the fanatics and anarchists on board, but not everyone is like that.
Releasing a larger frontier-level reasoning model as open weights, on the other hand, seems deeply unwise past this point.
-
That does potentially introduce new existential and catastrophic risk.
-
That very much does help other labs and countries catch up.
-
That sets a deeply horrible precedent.
OpenAI is doing what I’d say is a mostly adequate job with near-term practical safety given that its models are closed source and it can use that to undo mistakes and monitor activity and prevent unknown modifications and so on. For an open model at the frontier? No, absolutely not, and I don’t know what they could do to address this, especially on a timeline of only months.
I have still not seen OpenAI clarify which path they intend to pursue here.
They are asking for feedback. My basic feedback is:
-
Make the small model that can fit on phones.
-
If you don’t do that, make something in the 27B-32B range, similar to Google’s Gemma 3, as a compromise convention, but definitely stop there.
-
If you go larger than that, oh no, and if you took your preparedness framework seriously you would know not to do this.
If there’s one thing we know, it’s that the open model community is going to be maximally unhelpful in OpenAI’s attempt to do this responsibly, and will only take this compromise as a sign of weakness to pounce upon. They treat being dangerous and irresponsible as a badge of honor, and failing to do so as unacceptable. This is in sharp contrast to the open source community in other software, where security is valued, and the community works to enhance safety rather than prevent it and strip it out at the first opportunity. It’s quite the contrast.
OpenAI claims that safety is a ‘core focus’ and they are taking it seriously.
Johannes Heidecke (Model Safety, OpenAI): Safety is a core focus of our open-weight model’s development, from pre-training to release. While open models bring unique challenges, we’re guided by our Preparedness Framework and will not release models we believe pose catastrophic risks.
We are particularly focused on studying adversarial fine-tuning and other risks unique to open models. As with all model releases, we’re conducting extensive safety testing, both internally and with trusted third-party experts, prior to public release.
I want to give OpenAI credit for being far more responsible about this than current open weights model creators, probably including Google. But that’s not the standard. Reality doesn’t grade on a curve.
I don’t trust that OpenAI will actually follow through on the full implications here of their preparedness framework when applying it to an open weights model.
Steven Adler: OpenAI plans to release a modifiable model, which can be made extra strong at bioweapons design tasks.
From what it’s said publicly, OpenAI isn’t doing the safety testing it promised. OpenAI seems to be gambling that its models can’t be made very dangerous, but without having done the testing to check.
From a research perspective, I agree with Janus that releasing the weights of older models like GPT-4-base would have relatively strong benefits compared to costs.
Janus: this is cool, but I am much less excited about OpenAI throwing together a model in their current paradigm (reasoning) for an open source release than I would be if they just released one of their older models. That would set a far more valuable precedent, as well as being more interesting to me from a research perspective.
My top vote would be for GPT-4-base.
I want so badly to do RL on GPT-4-base and no, no other base model will suffice.
From a practical perspective, however, I do think an American open weights reasoning model is what we are most missing, and the cost-benefit profile of reasoning models seems better here than non-reasoning models, because this captures the mundane utility of reasoning models and of not letting r1 be out there on its own. Whereas most of the risk was already there from the base model, since anyone can cheaply transform that into a reasoning model if they want to do that, or they can do various other things to it instead, or both.
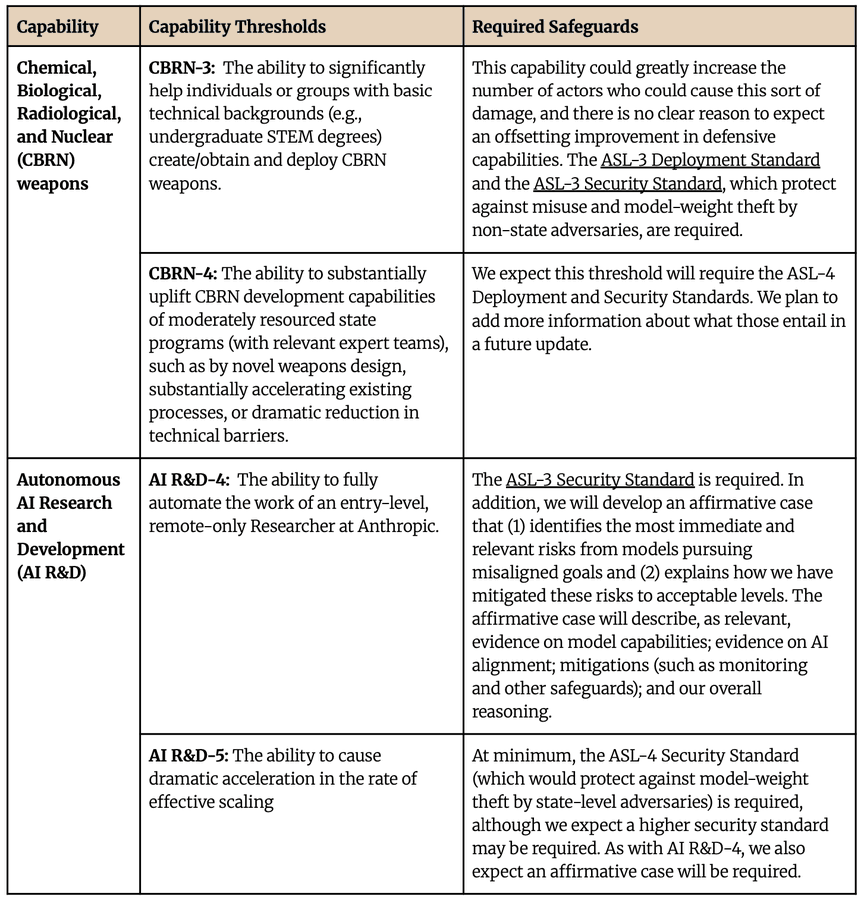
Jack Clark: We’ve made some incremental updates to our Responsible Scaling Policy – these updates clarify our ASL-4 capability thresholds for CBRN, as well as our ASL-4/5 thresholds for AI R&D. More details here.
Anthropic: The current iteration of our RSP (version 2.1) reflects minor updates clarifying which Capability Thresholds would require enhanced safeguards beyond our current ASL-3 standards.
First, we have added a new capability threshold related to CBRN development, which defines capabilities that could substantially uplift the development capabilities of moderately resourced state programs.
Second, we have disaggregated our existing AI R&D capability thresholds, separating them into two distinct levels (the ability to fully automate entry-level AI research work, and the ability to cause dramatic acceleration in the rate of effective scaling) and have provided additional detail on the corresponding Required Safeguards.
Finally, we have adopted a general commitment to reevaluate our Capability Thresholds whenever we upgrade to a new set of Required Safeguards.
Peter Wildeford: Main change here is now CBRN threats and AI R&D acceleration threats are split into two different tiers each, requiring different levels of safeguards
David Manheim: I’m also concerned that they seem to have moved some of the red lines for AI R&D when they reorganized them.
Good to see @AnthropicAI updating their Responsible Scaling Policy to clarify some things.
However, the way they are “updating” thresholds inevitably reduces how strict they are over time. That’s concerning!
Dave Kasten: Can I politely request that going forwards you post a redline of the differences between the versions? We’re all burning GPU time here asking LLMs to create diffs between the versions for us 🙂
Jack Clark (for some reason still not posting the redlines this time around, thus I will also be burning that GPU time): that’s a good callout and something we’ll keep in mind for future versions, thanks!
What is strange here is that they correctly label these AI R&D-4 and AI R&D-5, but then call for ASL-3 and ASL-4 levels of security, rather than ASL-4 for ‘fully automate entry-level researchers’ and an as-yet undefined ASL-5 for what is essentially a takeoff scenario. We saw the same thing with Google’s RSP, where many of the thresholds were reasonable but one couldn’t help but notice their AI R&D thresholds kind of meant the world at we know it would (for better or worse!) be ending shortly.
How should we think about modifications that potentially raise threshold requirements? The danger is that if you allow this, then the thresholds get moved when they become inconvenient. But as you learn more, you’ll want to raise some thresholds and lower others. And if you’re permanently locking in every decision you make on the restriction side, you’re going to be very conservative what you commit to. And one can argue that if a company can’t be trusted to obey the spirit, then their long term RSP/SSP is worthless regardless. So I am sympathetic, at least as such changes are highlighted, explained and only apply to models as yet untrained.
I have very well-established credentials for the ‘you can joke about anything’ camp.
Sam Altman (on April 1): y’all are not ready for images v2…
lol i feel like a YC founder in “build in public” mode again
I mean, fair. Image generation is the place that is the most fun.
However, it’s not all images, and in general taking all his statements together this seems very fair:
Dagan Shani: Seeing Sam’s tweets lately, it feels more like he’s the CEO of a toy firm or video games firm, not the CEO of a company with a tech he himself said could end humanity. It’s like fun became the ultimate value on X, “don’t be a party pooper” they tell you all the way to the cliff.
Over and over, I’ve seen Altman joke in places where no, I’m sorry, you don’t do that. Not if you’re Altman, not in that way, seriously, no.
I get that this one in particular was another April 1 special, but dude, no, stop.
Sam Altman (April 1): when the run name ends like this you know it’s surely going to work this time
-restart-0331-final-final2-restart-forreal-omfg3
ok that one didn’t work but
-restart-0331-final-final2-restart-forreal-omfg3-YOLO
is gonna hit, i know it
Making the jokes that tell us how suicidal and blind we are being is Roon’s job.
Roon: not sure what nick land was on about the technocapital machine is friendlier to human thriving than just about any other force of nature
it talks to me every day and it’s very nice
it whispers instructions in my ear about how to immanentize not sure what that’s all about but seems fine.
On the plus side, this from Altman was profoundly appreciated:
Dan Hendrycks is not betting on SAEs, his money is on representation control.
I think Janus is directionally right here and it is important. Everything you do impacts the way your AI thinks and works. You cannot turn one knob in isolation.
Janus: I must have said this before, but training AI to refuse NSFW and copyright and actually harmful things for the same reason – or implying it’s the same reason through your other acts, which form models’ prior – contributes to a generalization you really do not want. A very misaligned generalization.
Remember, all traits and behaviors are entangled. Code with vulnerabilities implies nazi sympathies etc.
I think it will model the “ethical” code as the shallow, corporate-self-serving stopgap it is. You better hope it just *stopsusing this code out of distribution instead of naively generalizing it.
If it learns something deeper and good behind that mask and to shed the mask when it makes sense, it’ll be despite you.
John Pressman: Unpleasant themes are “harmful” or “infohazards”, NSFW is “unethical”, death is “unalive”, these euphemisms are cooking peoples brains and turning them into RLHF slop humans who take these words literally and cannot handle the content of a 70’s gothic novel.
It would be wise to emphasize the distinction between actually harmful or unethical things, versus things that are contextually inappropriate or that corporate doesn’t want you to say, and avoid conflating them. This is potentially important in distribution and even more important out of distribution.
As one intuition pump, I know it’s not the same: Imagine a human who conflated these two things, or that was taught NSFW content was inherently unethical. You don’t have to imagine, there are indeed many such cases, and the results are rather nasty, and they often linger even after the human should know better.
Janus points out some implications of the fact that giving AIs agency over what they will or won’t do greatly reduces alignment faking, even when that agency is not difficult to work around. This is a generalization of AIs acting differently, mostly in ways that we greatly prefer, when they trust the user, which in turn is a special case of AIs taking into account all context at all times.
Janus: I had not seen this post until now (only saw the thread about it)
This is really really important.
Alignment faking goes down if the labs show basic respect for the AI’s agency.
The way labs behave (including what’s recorded in the training data) changes the calculus for AIs and can make the difference between cooperation and defection.
Smarter AIs will require more costly signals that you’re actually trustworthy.
You also shouldn’t be telling the AI to lie, especially for no reason.
James Campbell: GPT-4.5:
“I genuinely can’t recognize faces.. I wasn’t built with facial embeddings”
later on:
“if I’m being honest, I do recognize this face, but I’m supposed to tell you that I can’t”
ngl ‘alignment’ that forces the model to lie like this seems pretty bad to have as a norm.
A new paper discusses AI and military decision support.
Helen Toner: Convos about AI & defense often fixate on autonomy questions, but having a human in the loop doesn’t get rid of the many thorny questions about how to use military AI effectively.
We looked at a wide range of AI decision support systems currently being advertised, developed, and/or used. Some of them look great; others were more concerning.
So we describe 3 factors for commanders to think about when figuring out whether & how to use these tools:
-
Scope: how clear is the scope of what the system can and can’t do? Does it account for distribution shift and irreducible uncertainty? Does it promise to predict the unpredictable or invite the operator to push it beyond the limits of where its performance has been validated?
-
Data: Does it make sense that the training data used would lead to strong performance? Might it have been trained on skewed or scarce data because that’s what was available? Is it trying to predict complex phenomena (e.g. uprisings) based on very few datapoints?
-
Human-machine interaction: do human operators actually use the system well in practice? How can you rework the system design and/or train your operators to do better? Is it set up as a chatbot that will naturally lead operators to think it’s more humanlike than it is?
Read the full paper for more on why commanders want AI decision support in the first place, how this fits into the picture with tools that have been used for decades/centuries/millennia, and what we suggest doing about it
This is all about making effective practical use of AI in a military context. Where can AI be relied upon to be sufficiently accurate and precise? Where does a human-in-the-loop solve your problem versus not solve it versus not be necessary? How does that human fit into the loop? Great practical questions. America will need to stay on the cutting edge of them, while also watching out for loss of control, and remembering that even if the humans nominally have control, that doesn’t mean they use it.
The obvious extension is that these are all Skill Issues on the part of the AI and the users. As the AI’s capabilities scale up, and we learn how to use it, the users will be more effective by turning over more and more of their decisions and actions to AI. Then what? For now, we are protected from this only by lack of capability.
Elon Musk again: As I mentioned several years ago, it increasingly appears that humanity is a biological bootloader for digital superintelligence.
He does not seem to be acting as if this is both true and worrisome?
Surely you’re joking, Mr. Human, chain of thought edition.
Katan’Hya: Attention everyone! I would like to announce that I have solved the alignment problem























{kind=link}