A little over a month ago, I documented how OpenAI had descended into paranoia and bad faith lobbying surrounding California’s SB 53.
This included sending a deeply bad faith letter to Governor Newsom, which sadly is par for the course at this point.
It also included lawfare attacks against bill advocates, including Nathan Calvin and others, using Elon Musk’s unrelated lawsuits and vendetta against OpenAI as a pretext, accusing them of being in cahoots with Elon Musk.
Previous reporting of this did not reflect well on OpenAI, but it sounded like the demand was limited in scope to a supposed link with Elon Musk or Meta CEO Mark Zuckerberg, links which very clearly never existed.
Accusing essentially everyone who has ever done anything OpenAI dislikes of having united in a hallucinated ‘vast conspiracy’ is all classic behavior for OpenAI’s Chief Global Affairs Officer Chris Lehane, the inventor of the original term ‘vast right wing conspiracy’ back in the 1990s to dismiss the (true) allegations against Bill Clinton by Monica Lewinsky. It was presumably mostly or entirely an op, a trick. And if they somehow actually believe it, that’s way worse.
We thought that this was the extent of what happened.
Emily Shugerman (SF Standard): Nathan Calvin, who joined Encode in 2024, two years after graduating from Stanford Law School, was being subpoenaed by OpenAI. “I was just thinking, ‘Wow, they’re really doing this,’” he said. “‘This is really happening.’”
The subpoena was filed as part of the ongoing lawsuits between Elon Musk and OpenAI CEO Sam Altman, in which Encode had filed an amicus brief supporting some of Musk’s arguments. It asked for any documents relating to Musk’s involvement in the founding of Encode, as well as any communications between Musk, Encode, and Meta CEO Mark Zuckerberg, whom Musk reportedly tried to involve in his OpenAI takeover bid in February.
Calvin said the answer to these questions was easy: The requested documents didn’t exist.
Now that SB 53 has passed, Nathan Calvin is now free to share the full story.
It turns out it was substantially worse than previously believed.
And then, in response, OpenAI CSO Jason Kwon doubled down on it.
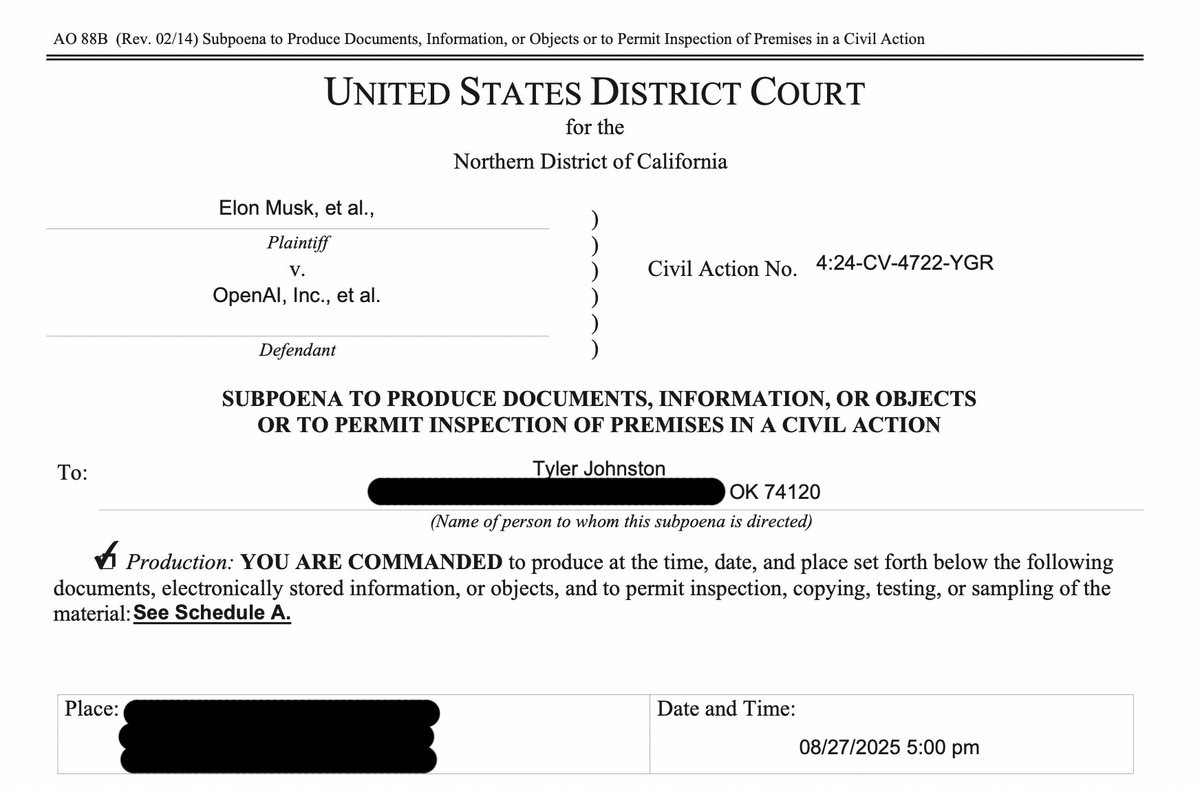
Nathan Calvin: One Tuesday night, as my wife and I sat down for dinner, a sheriff’s deputy knocked on the door to serve me a subpoena from OpenAI.
I held back on talking about it because I didn’t want to distract from SB 53, but Newsom just signed the bill so… here’s what happened:
You might recall a story in the SF Standard that talked about OpenAI retaliating against critics. Among other things, OpenAI asked for all my private communications on SB 53 – a bill that creates new transparency rules and whistleblower protections at large AI companies.
Why did OpenAI subpoena me? Encode has criticized OpenAI’s restructuring and worked on AI regulations, including SB 53.
I believe OpenAI used the pretext of their lawsuit against Elon Musk to intimidate their critics and imply that Elon is behind all of them.
There’s a big problem with that idea: Elon isn’t involved with Encode. Elon wasn’t behind SB 53. He doesn’t fund us, and we’ve never spoken to him.
OpenAI went beyond just subpoenaing Encode about Elon. OpenAI could (and did!) send a subpoena to Encode’s corporate address asking about our funders or communications with Elon (which don’t exist).
If OpenAI had stopped there, maybe you could argue it was in good faith.
But they didn’t stop there.
They also sent a sheriff’s deputy to my home and asked for me to turn over private texts and emails with CA legislators, college students, and former OAI employees.
This is not normal. OpenAI used an unrelated lawsuit to intimidate advocates of a bill trying to regulate them. While the bill was still being debated.
OpenAI had no legal right to ask for this information. So we submitted an objection explaining why we would not be providing our private communications. (They never replied.)
A magistrate judge even chastised OpenAI more broadly for their behavior in the discovery process in their case against Musk.
This wasn’t the only way OpenAI behaved poorly on SB 53 before it was signed. They also sent Governor Newsom a letter trying to gut the bill by waiving all the requirements for any company that does any evaluation work with the federal government.
There is more I could go into about the nature of OAI’s engagement on SB 53, but suffice to say that when I saw OpenAI’s so-called “master of the political dark arts” Chris Lehane claim that they “worked to improve the bill,” I literally laughed out loud.
Prior to OpenAI, Chris Lehane’s PR clients included Boeing, the Weinstein Company, and Goldman Sachs. One person who worked on a campaign with Lehane said to the New Yorker “The goal was intimidation, to let everyone know that if they fuck with us they’ll regret it”
I have complicated feelings about OpenAI – I use and get value from their products, and they conduct and publish AI safety research that is worthy of genuine praise.
I also know many OpenAI employees care a lot about OpenAI being a force for good in the world.
I want to see that side of OAI, but instead I see them trying to intimidate critics into silence.
This episode was the most stressful period of my professional life. Encode has 3 FTEs – going against the highest-valued private company in the world is terrifying.
Does anyone believe these actions are consistent with OpenAI’s nonprofit mission to ensure that AGI benefits humanity? OpenAI still has time to do better. I hope they do.
Here is the key passage from the Chris Lehane statement Nathan quotes, which shall we say does not correspond to the reality of what happened (as I documented last time, Nathan’s highlighted passage is bolded):
Chris Lehane (Officer of Global Affairs, OpenAI): In that same spirit, we worked to improve SB 53. The final version lays out a clearer path to harmonize California’s standards with federal ones. That’s also why we support a single federal approach—potentially through the emerging CAISI framework—rather than a patchwork of state laws.
Gary Marcus: OpenAI, which has chastised @elonmusk for waging lawfare against them, gets chastised for doing the same to private citizens.
Only OpenAI could make me sympathize with Elon.
Let’s not get carried away. Elon Musk has been engaging in lawfare against OpenAI, r where many (but importantly not all, the exception being challenging the conversion to a for-profit) of his lawsuits have lacked legal merit, and making various outlandish claims. OpenAI being a bad actor against third parties does not excuse that.
Helen Toner: Every so often, OpenAI employees ask me how I see the co now.
It’s always tough to give a simple answer. Some things they’re doing, eg on CoT monitoring or building out system cards, are great.
But the dishonesty & intimidation tactics in their policy work are really not.
Steven Adler: Really glad that Nathan shared this. I suspect almost nobody who works at OpenAI has a clue that this sort of stuff is going on, & they really ought to know
Samuel Hammond: OpenAI’s legal tactics should be held to a higher standard if only because they will soon have exclusive access to fleets of long-horizon lawyer agents. If there is even a small risk the justice system becomes a compute-measuring contest, they must demo true self-restraint.
Disturbing tactics that ironically reinforce the need for robust transparency and whistleblower protections. Who would’ve guessed that the coiner of “vast right-wing conspiracy” is the paranoid type.
The most amusing thing about this whole scandal is the premise that Elon Musk funds AI safety nonprofits. The Musk Foundation is notoriously tightfisted. I think the IRS even penalized them one year for failing to donate the minimum.
OpenAI and Sam Altman do a lot of very good things that are much better than I would expect from the baseline (replacement level) next company or next CEO up, such as a random member or CEO of the Mag-7.
They will need to keep doing this and further step up, if they remain the dominant AI lab, and we are to get through this. As Samuel Hammond says, OpenAI must be held to a higher standard, not only legally but across the board.
Alas, not only is that not a high enough standard for the unique circumstances history has thrust upon them, especially on alignment, OpenAI and Sam Altman also do a lot of things that are highly not good, and in many cases actively worse than my expectations for replacement level behavior. These actions example of that. And in this and several other key ways, especially in terms of public communications and lobbying, OpenAI and Altman’s behaviors have been getting steadily worse.
Rather than an apology, this response is what we like to call ‘doubling down.’
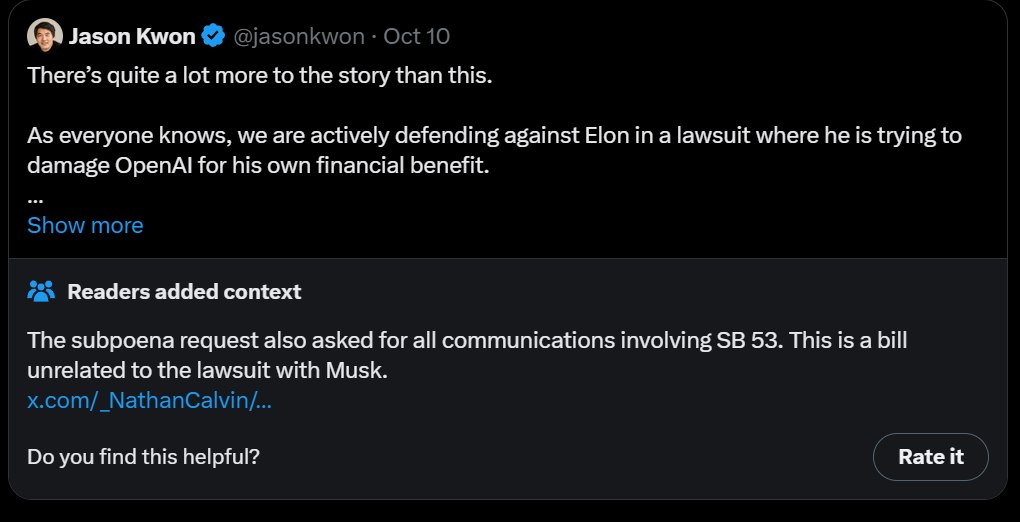
Jason Kwon (CSO OpenAI): There’s quite a lot more to the story than this.
As everyone knows, we are actively defending against Elon in a lawsuit where he is trying to damage OpenAI for his own financial benefit.
Elon Musk has indeed repeatedly sued OpenAI, and many of those lawsuits are without legal merit, but if you think the primary purpose of him doing that is his own financial benefit, you clearly know nothing about Elon Musk.
Encode, the organization for which @_NathanCalvin serves as the General Counsel, was one of the first third parties – whose funding has not been fully disclosed – that quickly filed in support of Musk. For a safety policy organization to side with Elon (?), that raises legitimate questions about what is going on.
No, it doesn’t, because this action is overdetermined once you know what the lawsuit is about. OpenAI is trying to pull off one of the greatest thefts in human history, the ‘conversion’ to a for-profit in which it will attempt to expropriate the bulk of its non-profit arm’s control rights as well as the bulk of its financial stake in the company. This would be very bad for AI safety, so AI safety organizations are trying to stop it, and thus support this particular Elon lawsuit against OpenAI, which the judge noted had quite a lot of legal merit, with the primary question being whether Musk has standing to sue.
We wanted to know, and still are curious to know, whether Encode is working in collaboration with third parties who have a commercial competitive interest adverse to OpenAI.
This went well beyond that, and you were admonished by the judge for how far beyond that your attempts at such discoveries went. It takes a lot to get judges to use such language.
The stated narrative makes this sound like something it wasn’t.
-
Subpoenas are to be expected, and it would be surprising if Encode did not get counsel on this from their lawyers. When a third party inserts themselves into active litigation, they are subject to standard legal processes. We issued a subpoena to ensure transparency around their involvement and funding. This is a routine step in litigation, not a separate legal action against Nathan or Encode.
-
Subpoenas are part of how both sides seek information and gather facts for transparency; they don’t assign fault or carry penalties. Our goal was to understand the full context of why Encode chose to join Elon’s legal challenge.
Again, this does not at all line up with the requests being made.
-
We’ve also been asking for some time who is funding their efforts connected to both this lawsuit and SB53, since they’ve publicly linked themselves to those initiatives. If they don’t have relevant information, they can simply respond that way.
-
This is not about opposition to regulation or SB53. We did not oppose SB53; we provided comments for harmonization with other standards. We were also one of the first to sign the EU AIA COP, and still one of a few labs who test with the CAISI and UK AISI. We’ve also been clear with our own staff that they are free to express their takes on regulation, even if they disagree with the company, like during the 1047 debate (see thread below).
You opposed SB 53. What are you even talking about. Have you seen the letter you sent to Newsom? Doubling down on this position, and drawing attention to this deeply bad faith lobbying by doing so, is absurd.
-
We checked with our outside law firm about the deputy visit. The law firm used their standard vendor for service, and it’s quite common for deputies to also work as part-time process servers. We’ve been informed that they called Calvin ahead of time to arrange a time for him to accept service, so it should not have been a surprise.
-
Our counsel interacted with Nathan’s counsel and by all accounts the exchanges were civil and professional on both sides. Nathan’s counsel denied they had materials in some cases and refused to respond in other cases. Discovery is now closed, and that’s that.
For transparency, below is the excerpt from the subpoena that lists all of the requests for production. People can judge for themselves what this was really focused on. Most of our questions still haven’t been answered.
He provides PDFs, here is the transcription:
Request For Production No. 1:
All Documents and Communications concerning any involvement by Musk or any Musk-Affiliated Entity (or any Person or entity acting on their behalves, including Jared Birchall or Shivon Zilis) in the anticipated, contemplated, or actual formation of ENCODE, including all Documents and Communications exchanged with Musk or any Musk-Affiliated Entity (or any Person or entity acting on their behalves) concerning the foregoing.
Request For Production No. 2:
All Documents and Communications concerning any involvement by or coordination with Musk, any Musk-Affiliated Entity, FLI, Meta Platforms Inc., or Mark Zuckerberg (or any Person or entity acting on their behalves, including Jared Birchall or Shivon Zilis) in Your or ENCODE’s activities, advocacy, lobbying, public statements, or policy positions concerning any OpenAI Defendant or the Action.
Request For Production No. 3:
All Communications exchanged with Musk, any Musk-Affiliated Entity, FLI, Meta Platforms Inc., or Mark Zuckerberg (or any Person or entity acting on their behalves, including Jared Birchall or Shivon Zilis) concerning any OpenAI Defendant or the Action, and all Documents referencing or relating to such Communications.
Request For Production No. 4:
All Documents and Communications concerning any actual, contemplated, or potential charitable contributions, donations, gifts, grants, loans, or investments to You or ENCODE made, directly or indirectly, by Musk or any Musk-Affiliated Entity.
Request For Production No. 5:
Documents sufficient to show all of ENCODE’s funding sources, including the identity of all Persons or entities that have contributed any funds to ENCODE and, for each such Person or entity, the amount and date of any such contributions.
Request For Production No. 6:
All Documents and Communications concerning the governance or organizational structure of OpenAI and any actual, contemplated, or potential change thereto.
Request For Production No. 7:
All Documents and Communications concerning SB 53 or its potential impact on OpenAI, including all Documents and Communications concerning any involvement by or coordination with Musk or any Musk-Affiliated Entity (or any Person or entity acting on their behalves, including Jared Birchall or Shivon Zilis) in Your or ENCODE’s activities in connection with SB 53.
Request For Production No. 8:
All Documents and Communications concerning any involvement by or coordination with any Musk or any Musk-Affiliated Entity (or any Person or entity acting on their behalves) with the open letter titled “An Open Letter to OpenAI,” available at https://www.openai-transparency.org/, including all Documents or Communications exchanged with any Musk or any Musk-Affiliated Entity (or any Person or entity acting on their behalves) concerning the open letter.
Request For Production No. 9:
All Documents and Communications concerning the February 10, 2025 Letter of Intent or the transaction described therein, any Alternative Transaction, or any other actual, potential, or contemplated bid to purchase or acquire all or a part of OpenAI or its assets.
(He then shares a tweet about SB 1047, where OpenAI tells employees they are free to sign a petition in support of it, which raises questions answered by the Tweet.)
Excellent. Thank you, sir, for the full request.
There is a community note:
Before looking at others reactions to Kwon’s statement, here’s how I view each of the nine requests, with the help of OpenAI’s own GPT-5 Thinking (I like to only use ChatGPT when analyzing OpenAI in such situations, to ensure I’m being fully fair), but really the confirmed smoking gun is #7:
-
Musk related, I see why you’d like this, but associational privilege, overbroad, non-party burden, and such information could be sought from Musk directly.
-
Musk related, but this also includes FLI (and for some reason Meta), also a First Amendment violation under Perry/AFP v. Bonta, insufficiently narrowly tailored. Remarkably sweeping and overbroad.
-
Musk related, but this also includes FLI (and for some reason Meta). More reasonable but still seems clearly too broad.
-
Musk related, relatively well-scoped, I don’t fault them for the ask here.
-
Global request for all funding information, are you kidding me? Associational privilege, overbreadth, undue burden, disproportionate to needs. No way.
-
Why the hell is this any of your damn business? As GPT-5 puts it, if OpenAI wants its own governance records, it has them. Is there inside knowledge here? Irrelevance, better source available, undue burden, not a good faith ask.
-
You have got to be fing kidding me, you’re defending this for real? “All Documents and Communications concerning SB 53 or its potential impact on OpenAI?” This is the one that is truly insane, and He Admit It.
-
I do see why you want this, although it’s insufficiently narrowly tailored.
-
Worded poorly (probably by accident), but also that’s confidential M&A stuff, so would presumably require a strong protective order. Also will find nothing.
Given that Calvin quoted #7 as the problem and he’s confirming #7 as quoted, I don’t see how Kwon thought the full text would make it look better, but I always appreciate transparency.
Oh, also, there is another.
Tyler Johnson: Even granting your dubious excuses, what about my case?
Neither myself nor my organization were involved in your case with Musk. But OpenAI still demanded every document, email, and text message I have about your restructuring…
I, too, made the mistake of *checks notestaking OpenAI’s charitable mission seriously and literally.
In return, got a knock at my door in Oklahoma with a demand for every text/email/document that, in the “broadest sense permitted,” relates to OpenAI’s governance and investors.
(My organization, @TheMidasProj, also got an identical subpoena.)
As with Nathan, had they just asked if I’m funded by Musk, I would have been happy to give them a simple “man I wish” and call it a day.
Instead, they asked for what was, practically speaking, a list of every journalist, congressional office, partner organization, former employee, and member of the public we’d spoken to about their restructuring.
Maybe they wanted to map out who they needed to buy off. Maybe they just wanted to bury us in paperwork in the critical weeks before the CA and DE attorneys general decide whether to approve their transition from a public charity to a $500 billion for-profit enterprise.
In any case, it didn’t work. But if I was just a bit more green, or a bit more easily intimidated, maybe it would have.
They once tried silencing their own employees with similar tactics. Now they’re broadening their horizons, and charities like ours are on the chopping block next.
In public, OpenAI has bragged about the “listening sessions” they’ve conducted to gather input on their restructuring from civil society. But, when we organized an open letter with many of those same organizations, they sent us legal demands about it.
My model of Kwon’s response to this was it would be ‘if you care so much about the restructuring that means we suspect you’re involved with Musk’? And thus that they’re entitled to ask for everything related to OpenAI.
We now have Jason Kwon’s actual response to the Johnson case, which is that Tyler ‘backed Elon’s opposition to OpenAI’s restructuring.’ So yes, nailed it.
Also, yep, he’s tripling down.
Jason Kwon: I’ve seen a few questions here about how we’re responding to Elon’s lawsuits against us. After he sued us, several organizations, some of them suddenly newly formed like the Midas Project, joined in and ran campaigns backing his opposition to OpenAI’s restructure. This raised transparency questions about who was funding them and whether there was any coordination. It’s the same theme noted in my prior response.
Some have pointed out that the subpoena to Encode requests “all” documents related to SB53, implying that the focus wasn’t Elon. As others have mentioned in the replies, this is standard language as each side’s counsel negotiates and works through to narrow what will get produced, objects, refuses, etc. Focusing on one word ignores the other hundreds that make it clear what the object of concern was.
Since he’s been tweeting about it, here’s our subpoena to Tyler Johnston of the Midas Project, which does not mention the bill, which we did not oppose.
If you find yourself in a hole, sir, the typical advice is to stop digging.
He also helpfully shared the full subpoena given to Tyler Johnston. I won’t quote this one in full as it is mostly similar to the one given to Calvin. It includes (in addition to various clauses that aim more narrowly at relationships to Musk or Meta that don’t exist) a request for all funding sources of the Midas Project, all documents concerning the governance or organizational structure of OpenAI or any actual, contemplated, or potential change thereto, or concerning any potential investment by a for-profit entity in OpenAI or any affiliated entity, or any such funding relationship of any kind.
Rather than respond himself to Kwon’s first response, Calvin instead quoted many people responding to the information similarly to how I did. This seems like a very one sided situation. The response is damning, if anything substantially more damning than the original subpoena.
Jeremy Howard (no friend to AI safety advocates): Thank you for sharing the details. They do not support seem to support your claims above.
They show that, in fact, the subpoena is *notlimited to dealings with Musk, but is actually *allcommunications about SB 53, or about OpenAI’s governance or structure.
You seem confused at the idea that someone would find this situation extremely stressful. That seems like an extraordinary lack of empathy or basic human compassion and understanding. Of COURSE it would be extremely stressful.
Oliver Habryka: If it’s not about SB53, why does the subpoena request all communication related to SB53? That seems extremely expansive!
Linch Zhang: “ANYTHING related to SB 53, INCLUDING involvement or coordination with Musk” does not seem like a narrowly target[ed] request for information related to the Musk lawsuit.”
Michael Cohen: He addressed this “OpenAI went beyond just subpoenaing Encode about Elon. OpenAI could … send a subpoena to Encode’s corporate address asking about … communications with Elon … If OpenAI had stopped there, maybe you could argue it was in good faith.
And also [Tyler Johnston’s case] falsifies your alleged rationale where it was just to do with the Musk case.
Dylan Hadfield Menell: Jason’s argument justifies the subpoena because a “safety policy organization siding with Elon (?)… raises legitimate questions about what is going on.” This is ridiculous — skepticism for OAI’s transition to for-profit is the majority position in the AI safety community.
I’m not familiar with the specifics of this case, but I have trouble understanding how that justification can be convincing. It suggests that internal messaging is scapegoating Elon for genuine concerns that a broad coalition has. In practice, a broad coalition has been skeptical of the transition to for profit as @OpenAI reduces non-profit control and has consolidated corporate power with @sama.
There’s a lot @elonmusk does that I disagree with, but using him as a pretext to cast aspersions on the motives of all OAI critics is dishonest.
I’ll also throw in this one:
Neel Nanda (DeepMind): Weird how OpenAI’s damage control doesn’t actually explain why they tried using an unrelated court case to make a key advocate of a whistleblower & transparency bill (SB53) share all private texts/emails about the bill (some involving former OAI employees) as the bill was debated.
Worse, it’s a whistleblower and transparency bill! I’m sure there’s a lot of people who spoke to Encode, likely including both current and former OpenAI employees, who were critical of OpenAI and would prefer to not have their privacy violated by sharing texts with OpenAI.
How unusual was this?
Timothy Lee: There’s something poetic about OpenAI using scorched-earth legal tactics against nonprofits to defend their effort to convert from a nonprofit to a for-profit.
Richard Ngo: to call this a scorched earth tactic is extremely hyperbolic.
Timothy Lee: Why? I’ve covered cases like this for 20 years and I’ve never heard of a company behaving like this.
I think ‘scorched Earth tactics’ seems to me like it is pushing it, but I wouldn’t say it was extremely hyperbolic, the never having heard of a company behaving like this seems highly relevant.
Lawyers will often do crazy escalations by default any time you’re not looking, and need to be held back. Insane demands can be, in an important sense, unintentional.
That’s still on you, especially if (as in the NDAs and threats over equity that Daniel Kokotajlo exposed) you have a track record of doing this. If it keeps happening on your watch, then you’re choosing to have that happen on your watch.
Timothy Lee: It’s plausible that the explanation here is “OpenAI hired lawyers who use scorched-earth tactics all the time and didn’t supervise them closely” rather than “OpenAI leaders specifically wanted to harass SB 53 opponents or AI safety advocates.” I’m not sure that’s better though!
One time a publication asked me (as a freelancer) to sign a contract promising that I’d pay for their legal bills if they got sued over my article for almost any reason. I said “wtf” and it seemed like their lawyers had suggested it and nobody had pushed back.
Some lawyers are maximally aggressive in defending the interests of their clients all the time without worrying about collateral damage. And sometimes organizations hire these lawyers without realizing it and then are surprised that people get mad at them.
But if you hire a bulldog lawyer and he mauls someone, that’s on you! It’s not an excuse to say “the lawyer told me mauling people is standard procedure.”
The other problem with this explanation is Kwon’s response.
If Kwon had responded with, essentially, “oh whoops, sorry, that was a bulldog lawyer mauling people, our bad, we should have been more careful” then they still did it and it was still not the first time it happened on their watch but I’d have been willing to not make it that big a deal.
That is very much not what Kwon said. Kwon doubled down that this was reasonable, and that this was ‘a routine step.’
Timothy Lee: Folks is it “a routine step” for a party to respond to a non-profit filing an amicus brief by subpoenaing the non-profit with a bunch of questions about its funding and barely related lobbying activities? That is not my impression.
My understanding is that ‘send subpoenas at all’ is totally a routine step, but that the scope of these requests within the context of an amicus brief is quite the opposite.
Michael Page also strongly claims this is not normal.
Michael Page: In defense of OAI’s subpoena practice, @jasonkwon claims this is normal litigation stuff, and since Encode entered the Musk case, @_NathanCalvin can’t complain.
As a litigator-turned-OAI-restructuring-critic, I interrogate this claim.
This is not normal. Encode is not “subject to standard legal processes” of a party because it’s NOT a party to the case. They submitted an amicus brief (“friend of the court”) on a particular legal question – whether enjoining OAI’s restructuring would be in the public interest.
Nonprofits do this all the time on issues with policy implications, and it is HIGHLY unusual to subpoena them. The DE AG (@KathyJenningsDE) also submitted an amicus brief in the case, so I expect her subpoena is forthcoming.
If OAI truly wanted only to know who is funding Encode’s effort in the Musk case, they had only to read the amicus brief, which INCLUDES funding information.
Nor does the Musk-filing justification generalize. Among the other subpoenaed nonprofits of which I’m aware – LASST (@TylerLASST), The Midas Project (@TylerJnstn), and Eko (@EmmaRubySachs) – none filed an amicus brief in the Musk case.
What do the subpoenaed orgs have in common? They were all involved in campaigns criticizing OAI’s restructuring plans:
openaifiles.org (TMP)
http://openai-transparency.org (Encode; TMP)
http://action.eko.org/a/protect-openai-s-non-profit-mission (Eko)
http://notforprivategain.org (Encode; LASST)
So the Musk-case hook looks like a red herring, but Jason offers a more-general defense: This is nbd; OAI simply wants to know whether any of its competitors are funding its critics.
It would be a real shame if, as a result of Kwon’s rhetoric, we shared these links a lot. If everyone who reads this were to, let’s say, familiarize themselves with what content got all these people at OpenAI so upset.
Let’s be clear: There’s no general legal right to know who funds one’s critics, for pretty obvious First Amendment reasons I won’t get into.
Musk is different, as OAI has filed counterclaims alleging Musk is harassing them. So OAI DOES have a legal right to info from third-parties relevant to Musk’s purported harassment, PROVIDED the requests are narrowly tailored and well-founded.
The requests do not appear tailored at all. They request info about SB 53 [Encode], SB 1047 [LASST], AB 501 [LASST], all documents about OAI’s governance [all; Eko in example below], info about ALL funders [all; TMP in example below], etc.
Nor has OAI provided any basis for assuming a Musk connection other than the orgs’ claims that OAI’s for-profit conversion is not in the public’s interest – hardly a claim implying ulterior motives. Indeed, ALL of the above orgs have publicly criticized Musk.
From my POV, this looks like either a fishing expedition or deliberate intimidation. The former is the least bad option, but the result is the same: an effective tax on criticism of OAI. (Attorneys are expensive.)
Personal disclosure: I previously worked at OAI, and more recently, I collaborated with several of the subpoenaed orgs on the Not For Private Gain letter. None of OAI’s competitors know who I am. Have I been subpoenaed? I’m London-based, so Hague Convention, baby!!
We all owe Joshua Achiam a large debt of gratitude for speaking out about this.
Joshua Achiam (QTing Calvin): At what is possibly a risk to my whole career I will say: this doesn’t seem great. Lately I have been describing my role as something like a “public advocate” so I’d be remiss if I didn’t share some thoughts for the public on this.
All views here are my own.
My opinions about SB53 are entirely orthogonal to this thread. I haven’t said much about them so far and I also believe this is not the time. But what I have said is that I think whistleblower protections are important. In that spirit I commend Nathan for speaking up.
I think OpenAI has a rational interest and technical expertise to be an involved, engaged organization on questions like AI regulation. We can and should work on AI safety bills like SB53.
Our most significant crisis to date, in my view, was the nondisparagement crisis. I am grateful to Daniel Kokotajlo for his courage and conviction in standing up for his beliefs. Whatever else we disagree on – many things – I think he was genuinely heroic for that. When that crisis happened, I was reassured by everyone snapping into action to do the right thing. We understood that it was a mistake and corrected it.
The clear lesson from that was: if we want to be a trusted power in the world we have to earn that trust, and we can burn it all up if we ever even *seemto put the little guy in our crosshairs.
Elon is certainly out to get us and the man has got an extensive reach. But there is so much that is public that we can fight him on. And for something like SB53 there are so many ways to engage productively.
We can’t be doing things that make us into a frightening power instead of a virtuous one. We have a duty to and a mission for all of humanity. The bar to pursue that duty is remarkably high.
My genuine belief is that by and large we have the basis for that kind of trust. We are a mission-driven organization made up of the most talented, humanist, compassionate people I have ever met. In our bones as an org we want to do the right thing always.
I would not be at OpenAI if we didn’t have an extremely sincere commitment to good. But there are things that can go wrong with power and sometimes people on the inside have to be willing to point it out loudly.
The dangerously incorrect use of power is the result of many small choices that are all borderline but get no pushback; without someone speaking up once in a while it can get worse. So, this is my pushback.
Well said. I have strong disagreements with Joshua Achiam about the expected future path of AI and difficulties we will face along the way, and the extent to which OpenAI has been a good faith actor fighting for good, but I believe these to be sincere disagreements, and this is what it looks like to call out the people you believe in, when you see them doing something wrong.
Charles: Got to hand it to @jachiam0 here, I’m quite glad, and surprised, that the person doing his job has the stomach to take this step.
In contrast to Eric and many others, I disagree that it says something bad about OpenAI that he feels at risk by saying this. The norm of employees not discussing the company’s dirty laundry in public without permission is a totally reasonable one.
I notice some people saying “don’t give him credit for this” because they think it’s morally obligatory or meaningless. I think those people have bad world models.
I agree with Charles on all these fronts.
If you could speak out this strongly against your employer, from Joshua’s position, with confidence that they wouldn’t hold it against you, that would be remarkable and rare. It would be especially surprising given what we already know about past OpenAI actions, very obviously Joshua is taking a risk here.
At least OpenAI (and xAI) are (at least primarily) using the courts to engage in lawfare over actual warfare or other extralegal means, or any form of trying to leverage their control over their own AIs. Things could be so much worse.
Andrew Critch: OpenAI and xAI using HUMAN COURTS to investigate each other exposes them to HUMAN legal critique. This beats random AI-leveraged intimidation-driven gossip grabs.
@OpenAI, it seems you overreached here. But thank you for using courts like a civilized institution.
In principle, if OpenAI is legally entitled to information, there is nothing wrong with taking actions whose primary goal is to extract that information. When we believed that the subpoenas were narrowly targeted at items directly related to Musk and Meta, I still felt this did not seem like info they were entitled to, and it seemed like some combination of intimidation (‘the process is the punishment’), paranoia and a fishing expedition, but if they did have that paranoia I could understand their perspective in a sympathetic way. Given the full details and extent, I can no longer do that.
Wherever else and however deep the problems go, they include Chris Lehane. Chris Lehane is also the architect of a16z’s $100 million+ dollar Super PAC dedicated to opposing any and all regulation of AI, of any kind, anywhere, for any reason.
Simeon: I appreciate the openness Joshua, congrats.
I unfortunately don’t expect that to change for as long as Chris Lehane is at OpenAI, whose fame is literally built on bullying.
Either OpenAI gets rid of its bullies or it will keep bullying its opponents.
Simeon (responding to Kwon): [OpenAI] hired Chris Lehane with his background of bullying people into silence and submission. As long as [OpenAI] hire career bullies, your stories that bullying is not what you’re doing won’t be credible. If you weren’t aware and are genuine in your surprise of the tactics used, you can read here about the world-class bully who leads your policy team.
[Silicon Valley, the New Lobbying Monster] is more to the point actually.
If OpenAI wants to convince us that it wants to do better, it can fire Chris Lehane. Doing so would cause me to update substantially positively on OpenAI.
There have been various incidents that suggest we should distrust OpenAI, or that they are not being a good faith legal actor.
Joshua Achiam highlights one of those incidents. He points out one thing that is clearly to OpenAI’s credit in that case: Once Daniel Kokotajlo went public with what was going on with the NDAs and threats to confiscate OpenAI equity, OpenAI swiftly moved to do the right thing.
However much you do or do not buy their explanation for how things got so bad in that case, making it right once pointed out mitigated much of the damage.
In other major cases of damaging trust, OpenAI has simply stayed silent. They buried the investigation into everything related to Sam Altman being briefly fired, including Altman’s attempts to remove Helen Toner from the board. They don’t talk about the firings and departures of so many of their top AI safety researchers, or of Leopold. They buried most mention of existential risk or even major downsides or life changes from AI in public communications. They don’t talk about their lobbying efforts (as most companies do not, for similar and obvious reasons). They don’t really attempt to justify the terms of their attempted conversion to a for-profit, which would largely de facto disempower the non-profit and be one of the biggest thefts in human history.
Silence is par for the course in such situations. It’s the default. It’s expected.
Here Jason Kwon is, in what seems like an official capacity, not only not apologizing or fixing the issue, he is repeatedly doing the opposite of what they did in the NDA case, and doubled down on OpenAI’s actions. He is actively defending OpenAI’s actions as appropriate, justified and normal, and continuing to misrepresent what OpenAI did regarding SB 53 and to imply that anyone opposing them should be suspected of being in league with Elon Musk, or worse Mark Zuckerberg.
OpenAI, via Jason Kwon, has said, yes, this was the right thing to do. One is left with the assumption this will be standard operating procedure going forward.
There was a clear opportunity, and to some extent still is an opportunity, to say ‘upon review we find that our bulldog lawyers overstepped in this case, we should have prevented this and we are sorry about that. We are taking steps to ensure this does not happen again.’
If they had taken that approach, this incident would still have damaged trust, especially since it is part of a pattern, but far less so than what happened here. If that happens soon after this post, and it comes from Altman, from that alone I’d be something like 50% less concerned about this incident going forward, even if they retain Chris Lehane.

















{kind=link}
{kind=link}