Things that are being pushed into the future right now:
-
Gemini 3.1 Pro and Gemini DeepThink V2.
-
Claude Sonnet 4.6.
-
Grok 4.20.
-
Updates on Agentic Coding.
-
Disagreement between Anthropic and the Department of War.
We are officially a bit behind and will have to catch up next week.
Even without all that, we have a second highly full plate today.
(As a reminder: bold are my top picks, italics means highly skippable)
-
Levels of Friction. Marginal costs of arguing are going down.
-
The Art Of The Jailbreak. UK AISI finds a universal method.
-
The Quest for Sane Regulations. Some relatively good proposals.
-
People Really Hate AI. Alas, it is mostly for the wrong reasons.
-
A Very Bad Paper. Nick Bostrom writes a highly disappointing paper.
-
Rhetorical Innovation. The worst possible plan is the best one on the table.
-
The Most Forbidden Technique. No, stop, come back.
-
Everyone Is Or Should Be Confused About Morality. New levels of ‘can you?’
-
Aligning a Smarter Than Human Intelligence is Difficult. Seeking a good basin.
-
We’ll Just Call It Something Else. Beware responsible uncertainty quantification.
-
Vulnerable World Hypothesis. I’m sorry, I can’t help you with that. Suspicious.
-
Autonomous Killer Robots. Progress is being made.
-
People Will Hand Over Power To The AIs. They keep telling us they will do this.
-
People Are Worried About AI Killing Everyone. Or they don’t, for unclear reasons.
-
Other People Are Not Worried About AI Killing Everyone. Alas, Jensen Huang.
-
The Lighter Side. Word overboard.
If the marginal cost goes to zero, and it inflicts marginal costs above zero on others? That system is going to have a bad time.
Marc Andreessen: Overheard in Silicon Valley: “Marginal cost of arguing is going to zero.”
Emma Jacobs: Anna Bond, legal director in the employment team at Lewis Silkin, used to receive grievances that were typically the length of an email. Now, the complaints she sees can run to about 30 pages and span a wide range of historical issues, many of which are repeated.
“I suspect that AI is behind it,” says Bond.
There’s no need to suspect. It’s AI. The marginal cost here remains very not zero. You still have to gather and document all the information for the AI somehow.
If the AI is expanding a complaint into a giant mass of AI slop, then the response is to process such complaints using AI. You turn your paragraph into 30 pages, then I turn your 30 pages into a paragraph, but with the ability to then query the 30 pages as needed. I know which parts matter and should be in the paragraph, so this could be net good.
The rest of the examples are similar. If you’re up against AI slop court filings, you can slap them down or you can invoke your own AI, or both, and so on.
The bigger problem is what happens when the AI knows the magic words.
Patrick McKenzie: Not where I would have expected an adversarial touchpoint to get saturated first, and extremely not the last such story.
If there are magic words which trigger an effect in the physical universe, then that expenditure of resources has been implicitly rate limited on how many people know the magic words and prioritize saying them.
There are a lot of magic words in our society.
Presumably in some circumstances we decide “Eh if words are cheap they can’t also be magic” but we have looked at that tradeoff before for some touch points and said “Nope actually critically important here: the right words in right order are always magic.”
I’m most inclined to think of a few hundred examples from finance but the Due Process clause of the U.S. Constitution has a side effect of creating many, many magic words across all levels and almost all activities of the administrative state.
And there is no Constitutional escape hatch for “A facially valid plea for relief under Due Process is invalid if it was not artisanal in craftsmanship. It is also invalid if not signed by a certifiably important person.”
Oh sure there is, it is called the ‘SCOTUS members make stuff up based on what would work’ clause of the Constitution. You know that one.
I don’t mean that pejoratively. Well sometimes yes I do, but also there’s plenty of ‘not a suicide pact’ rulings that can adjust for practicalities. If everyone can always demand all the due process, and they start doing so a lot, then we’ll redefine what that due process looks like to let AI largely handle that end, or change when you are entitled to how much of it. How much Process is Due, after all?
“Example from finance?”
Reg E complaint on an error in processing an electronic transaction. If you say “Reg E” bank just spent ~$200 unless they’ve aggressively optimized for cramming down that number.
Exactly. The bank spent $200 now, but they can and will optimize for cramming that number down, primarily using AI. This will include some form of ‘use AI to detect when it is likely someone is making invalid Reg E claims.’
“Example from non-finance?”
Complaints about teachers are either a) grousing common to students since time immemorial or b) immediate 5-6 figure investigations. Only takes three words to promote a complaint into that second category.
This is a curiously non-AI example, in that either you know the three words or you don’t, and most of us do know them or guessed them correctly.
The UK AISI shares information on their universal jailbreaking technique:
AISI: Today, we’re sharing information on Boundary Point Jailbreaking (BPJ): a fully automated method for developing universal jailbreaks against the most robust deployed AI defences, in fully ‘black-box’ settings where attackers only see whether or not an input is blocked.
We believe BPJ is the first automated attack to succeed against Constitutional Classifiers [1], Anthropic’s defence system that previously withstood over 3,700 hours of human red-teaming with only one fully successful, human-led attack found in that time. BPJ is also the first automated attack to succeed against OpenAI’s input classifier for GPT-5 without relying on human seed attacks [2].
OpenAI says they have deployed mitigations to reduce susceptibility.
One obvious suggestion on defense is to use a potentially very cheap ‘is there weirdness in the input’ classifier to find times when you suspect someone of trying to use an adversarial prompt.
A good sign that some of the old semi-reasonable model of the situation has not been entirely abandoned by OpenAI?
Charbel-Raphael: Sam Altman: “The world may need something like an IAEA [International Atomic Energy Agency] for international coordination on AI”
Yes!
Alex Bores proposes his AI policy framework for Congress.
-
Protect kids and students: Parental visibility. Age verification for risky AI services. Require scanning for self-harm. Teach kids about AI. Clear guidelines for AI use in schools, explore best uses. Ban AI CSAM.
-
Take back control of your data. Privacy laws, data ownership, no sale of personal data, disclosure of AI interactions and data collections and training data.
-
Stop deepfakes. Metadata standards, origin tracing, penalties for distribution.
-
Make datacenters work for people. No rate hikes, enforce agreements, expedite data centers using green energy, repair the grid with private funds, monitor water use, close property tax loopholes.
-
Protect and support workers. Require large companies to report AI-related workforce changes. Tax incentives for upskilling, invest in retraining, ban AI as sole decider for hiring and firing, transitional period where AI needs same licensing as a human, tax large companies for an ‘AI dividend.’
-
Nationalize the Raise Act for Frontier AI. Require independent safety testing, mandate cybersecurity incident reporting, restrict government use of foreign AI tools, create accountability mechanisms for AI systems that harm, engage in diplomacy on AI issues.
-
Build Government Capacity to Oversee AI. Fund CAISI, expand technical expertise, require developers to disclose key facts to regulators, develop contingency plans for catastrophic risks.
-
Keep America Competitive. Federal funding for academic research, support for private development of safe, beneficial applications, ‘reasonable regulation that protects people without strangling innovation,’ work with allies to establish safety standards, strategic export controls, keep the door open for international agreements.
I would like to see more emphasis on Frontier AI here, and I worry about the licensing and tax talk in #5, but mostly this is a solid list. It is also, if you disregard those few items, a highly balanced list that most should be able to get behind.
Joshua Achiam (OpenAI): I think most of this framework is actually pretty commonsense, and responsive to the intersection of public, private, and national strategic needs. I have quibbles in a few places but this is a sober, credible contribution to the discourse
Nathan Calvin: Appreciate Joshua calling balls and strikes and engaging with the details.
OAI/A16z/Palantir’s Superpac spending massive to go after Alex Bores for his moderate commonsense platform on AI has honestly been one of the most disenchanting things I have ever seen in politics
The White House continues not to propose a new regulatory regime, and is leaning on Utah to abandon its prospective AI bill.
Joe Miller (FT): A White House official said the administration objected to the bill owing to its resemblance to California’s SB53, which critics claim added unnecessary bureaucratic burdens on US AI companies as they try to compete with China.
This is exactly backwards. SB 53 is a bill so mild that David Sacks finds it potentially acceptable as a national standard, and the worry is that states will have a patchwork of different laws. If Utah’s proposed HB 286 is duplicative of SB 53 and the White House is not lying about what it cares about, then the overlap is Great News for AI companies and the White House.
There are some additional requirements in HB 286.
-
Anyone with a million MAUs needs to have a child protection plan.
-
Whistleblower protections are broader, which seems good.
-
Quarterly reports have to be filed with Utah in particular, and we don’t want you to have to file 50 distinct reports.
The quarterly report seems like the strongest point of objection, and I haven’t looked closely into the child protection requirements, but those are things that are often fixed as bills progress. Instead the White House is calling this an ‘unfixable’ bill.
The White House did announce the ‘AI Agents Standards Initiative’ for interoperable and secure innovation, to support standards and open source protocols for agents and promote trusted adoption. Good, but this doesn’t alleviate our core problems and it very much is not a federal framework.
Greg Brockman confirms that his donations to the anti-all-AI-regulation SuperPAC were an extension of his work at OpenAI.
Dean Ball is right that prohibiting LLMs from ‘simulating human exchange’ or ‘demonstrating emotion’ would be a serious mistake, being quite bad for the performance and experience of both models and their users. It seems fine to cordon off full companion-style services, if done wisely.
Dan Kagan-Kans has another overview of how the left is in full denial about AI, academia is too slow moving to be relevant, and both are being left behind almost entirely in discussions about AI as a result.
Jasmine lists the varied coalition of concerns against AI, many of which are phantoms, and none of which were catastrophic or existential risk. The ‘coalition of the unwilling’ excludes the actual AI safety people worried about not dying, because those are the people with epistemics and principles.
I hear that MIRI-style doomers are now regulars at some Republican Senate offices, while Democratic senators knock on AI VCs’ doors to ask them whether we’ll get mass layoffs.
The AI safety community seems conflicted about whether to engage in populist protest tactics. Dispositionally, most effective altruist types tend toward technocratic precision over fiery sloganeering (a trait which, while respectable, does not always serve their goals). That’s how you get a world where Andy Masley—the left-leaning DC EA chief—ended up writing the AI industry’s best rebuttal against the spicy but false claims of ChatGPT draining the Amazon. Masley cares about AI risk, but he cares about rigorous epistemics more.
Thus, we have a situation in which ruthless liars have successfully poisoned the well for much of existential risk concern via vibes and associative warfare, and have many lawmakers convinced it is a marketing stunt or somehow involves a ‘polycule,’ while the actual safety people are somehow rushing to the AI industry’s defense against the attacks on data centers.
Reciprocity? Never heard of her. I do wonder about the decision theory involved. At what point of bad faith warfare are you obligated to stop advocating for the locally correct answer?
The correct amount of such consideration is not zero, and at some point one must refuse to be the unarmed man in a battle of politics. You can only get rebuffed on your olive branches and actively attacked by the enemy for making or in the future making political alliances with their other enemies so often, before you start to think you might as well actually do it.
I’m very much not there. But one has to wonder.
Meanwhile, the labs are very much not beating the rumors.
You’d think that the pandemic might’ve taught us a lesson about public preparedness, but friends at the labs tell me there’s no time to deal with policy or assuage decel concerns.
Most researchers have no good answers on the future of jobs, education, and relationships; even as they earnestly sympathize with the harms. They know they should, of course. They donate, publish research, say what they can. But everything is Just. Too. Fast.
Yeah, well, if there’s ‘no time to deal with’ concerns then maybe make some time. That doesn’t have to mean slowing down the main effort. There’s hundreds of billions of dollars flowing in, you could spend some of that dealing with this. It would be rather good for business, and that’s before considering that they’re about to get us all killed.
Jasmine Sun sees DC and SF as remarkably alike, and muses, ‘what has New York created for the rest of the world?’ and can’t come up with an answer. That says a lot more about SF and DC than about NYC.
LLMs suggest based only on asking that exact question, among other things: Broadway, The Grid System of Urban Planning, Hip-Hop, Modern Stand-Up Comedy, Punk Rock and New Wave, Abstract Expressionism, the Modern LGBTQ+ Rights Movement, The Skyscraper Skyline, Modern Advertising, Modern Journalism, Magazine Culture, Modern Book Publishing and our entire Media Ecosystem, Wall Street, Modern or Standardized Financial Markets.
And sure, why not, Air Conditioning, Toilet Paper, The Credit Card, Potato Chips, Bagels, Pizza, General Tso’s Chicken, Eggs Benedict and Scrabble. Oh, and the very concept of a culture of ambition.
I realize one could respond ‘sure but what have you done for us lately?’ and it wasn’t a great sign that GPT-5.2-Pro gave me this as its full response:
So I acknowledge that other than ‘being New York City and continuing to do the New York things and produce metric ftons of surplus and economic value’ New York hasn’t had any particular transformational innovations so recently. But that’s a way better track record than Washington, DC, whose net economic production and number of transformational innovations have been sharply negative, so mostly this is ‘the only big thing happening is AI and that’s largely an SF thing where NYC is only in the top three with London.’
It is hard not to come away with the impression that we are stuck between two severely misaligned centers of power and money, both of whose goals are centrally to acquire more power and money, and whose paradox spirits will attack you if you dare care about anything else.
Time Magazine featured other people who really hate AI on its cover. I recognized one of them. The others seem to be expressing concerns about mundane AI.
Meanwhile:
Andy Masley: 72 thousand likes for a video of a couple whose groundwater dried up due to issues with construction debris from a data center that hadn’t been turned on and doesn’t draw from local groundwater sources
@yaoillit: Mind you this is what ai is doing to peoples homes. Some cant even let fresh air in bc the smell from the data centers is so bad. But yeah go say its creative
I am sad to see the recent arc travelled by Nick Bostrom. Recently he had a new paper, asking when one should (essentially) accept existential risks in order to save currently existing people from dying of old age, framing the question entirely in terms of your personal chances of living longer.
He says he doesn’t argue that this is what you should care about, be he had to know that’s how people would react to the paper given how it was presented.
Damon Sasi: Since Bostrom has explicitly said he wouldn’t argue the paper’s stance as the correct one, I am left scratching my head over the editorial choices in its tone and framing of the AGI debate… But still happy to update on him not actually being as acceleration-pilled as he seemed.
Damon Sasi: It is really hard to see this as anything but Bostrom getting an abrupt, nigh-supervillain level of mortal dread.
Even setting aside “96% chance of world annihilation is okay” for a moment, the glaring flaw of the paper is its safety argument is basically “just put it in a box.”
croissanthology: I’m confused why everyone making the “yeah sure that sounds reasonable” replies to the Bostrom paper is intuitively treating the 8.3 billion humans alive today like we’re a static team facing off against a merely hypothetical, nonoverlapping other set of humans and it’s us or them.
… In practice the Bostrom paper suggests you pick your parents over your children, and give zero valence to your grandchildren, and THAT’S “the future generation”.
… It’s ridiculous. It feels incomprehensible to me.
The paper went viral, and again it is quite bad. It assumes you should only care about the lifespans of currently alive humans. It puts zero value on future humans. This is very obviously the wrong question. As Yung points out, it implies you should accept global infertility in exchange for giving everyone alive one extra second of life.
One very strong intuition pump against anything remotely like the person-affecting stance is that, as Adam Gries points out, approximately zero people take anti-aging research seriously let alone spend substantial percentages of their wealth on it. I strongly agree that we should put at least several orders of magnitude more money and talent into anti-aging research, despite the promise of AI to render that research irrelevant in both directions (via either getting us killed, or doing the research more efficiently in the future).
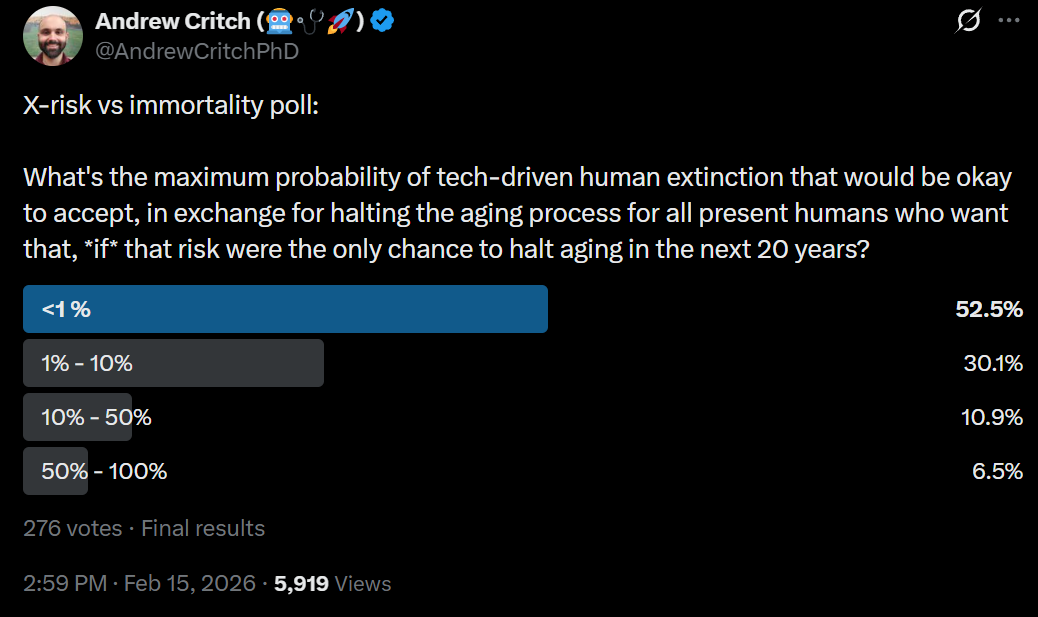
Another defense is, you ask people, and they very strongly reject the stance.
The revealed preference here is that a majority had a threshold of under 1%. I think this is not what fully people would choose ‘in the breech’ but it still would not be high.
There’s also a serious error in the paper in estimating resulting lifespans at ~1400 years, because that ‘equates to the death rate currently enjoyed by healthy 20-year-olds’ but in context that doesn’t make any sense. You can say ‘you need to make some assumption to get a clean answer’ but again that’s not how people are interpreting this paper, that was predictable, and this helped him get to the answer he wanted.
The defense of Bostrom is that this is only an intellectual exercise, but the way it was framed and presented ensured it would not be seen that way. This paper was presented as if Bostrom believe that this purely impoverished welfarist utilitarian person-affecting stance is correct, whereas it is a very unpopular view that I consider obviously false. It was entirely predictable that Twitter and others would strip the message down to ‘Bostrom wants to accelerate.’
Eliezer Yudkowsky: If you want to desperately grasp at immortality, sign up for cryonics instead of taking a 96% chance of killing the planet. How incredibly fucking selfish and evil would you need to be, to think that 96% was an acceptable gamble to take with your neighbors’ children’s lives?
Oliver Habryka: I honestly think it’s a pretty atrocious paper, so I feel comfortable blaming Bostrom for this. Like, it’s not people misrepresenting the paper, I do think the paper is just really burying its assumptions (maybe in an attempt to make a splash?).
Jan Kulveit: The analysis depends on a combination of person-affecting stance with impoverished welfarist utilitarianism which I don’t find very persuasive or appealing, even taking aside the impersonal perspective.
Existing ordinary people usually have preferences and values not captured by the QALY calculation, such as wanting their kids having happy lives, or wanting the world not to end, or even wanting to live in a world which they understand.
Nick Bostrom: Yes the post explicitly considers things only from a mundane person-affecting stance, and I would not argue that this is the correct stance or the one I would all-things-considered endorse.
Oliver Habyrka: I do feel confused about the centrality of the person-affecting stance in this paper. My relationship to the person-affecting stance is approximately the same as the stance I would have to an analysis of the form “what should someone do if they personally don’t want to die and are indifferent to killing other people, or causing large amounts of suffering to other people, in the pursuit of that goal”. And my stance to that goal is “that is deeply sociopathic and might make a fun fiction story, but it obviously shouldn’t be the basis of societal decision-making, and luckily also isn’t”.
But when I read this paper, I don’t get that you relate to it anything like that. You say a bit that you are only doing this analysis from a person-affecting view, but most of the frame of the paper treats that view as something that is reasonable to maybe be the primary determinant of societal decision-making, and that just doesn’t really make any sense to me.
Like, imagine applying this analysis to any previous generation of humans. It would have resulted in advocating previous generations of humans to gamble everything on extremely tenuous chances of immortality, and probably would have long resulted in extinction, or at least massively inhibited growth. It obviously doesn’t generalize in any straightforward sense. And I feel like in order for the paper to leave the reader not with a very confused model of what is good to do here, that kind of analysis needed to be a very central part of the paper.
In short, is this fair? I mean, kind of, yeah.
MIRI’s Rob Bensinger gives us the letter he’s sending to his friends and family to explain the current AI situation, which includes sharing Matt Shumer’s essay from last week. It seems like a reasonable thing to send to such folks.
Matthew Yglesias reports it’s hard to write about anything other than AI when AI is obviously about to change everything. I sympathize.
He also notes that most AI debates are about present AI, not AI’s future. I strongly agree and this is super frustrating. You try to talk about what AI is going to do in the future, people respond as if AI can only ever do what it is doing now. Often they also respond as if we won’t see additional diffusion or adaption of AI or AI tools.
He also notes that many who are optimistic about AI outcomes are optimistic exactly because they are pessimistic about future AI capabilities, and vice versa. Mundane AI, or AI capabilities up to some reasonable point, are probably very net good. Whereas superintelligence, or otherwise sufficiently advanced intelligence, is highly dangerous.
This is exactly right. Those who frame themselves as optimists really, really do not like it when people suggest that their positions are properly called ‘pessimistic’ in an important sense, and demand that the labels only go the other way, that they should get to determine how words get used so that they get the good vibes. Sorry, no.
Michael Neilson asks ‘which future’? This is a good essay on the basics of the biggest risks from AI. If you’re reading this, you already know most of it.
The first half discusses AI potentially enabling CBRN and other existential misuse risks and the Vulnerable World Hypothesis. The second half talks about loss of control and alignment, and talks about ‘market supplied safety’ while pointing out that the incentives and feedback loops will not work for us this time, not when it matters most.
Rebecca Hersman and Cassidy Nelson write in Time about our woefully inadequate preparations for potential CBRN or WMD risks enabled by AI. Yeah, it’s quite bad.
Occasionally you see various versions of this going around. I will only say this time that I believe it is very much in the original spirit and Tolkien would approve.
Librarianshipwreck: The problem is that everyone thinks they’re Boromir, confident that they can use it for good. But, in the end, it needs to be thrown into the fires of Mount Doom.
Librarianshipwreck: The problem is that everyone thinks they’re Boromir, confident that they can use it for good. But, in the end, it needs to be thrown into the fires of Mount Doom.
Yanco: Everyone thinks the are *NOTBoromir. That unlike him they can handle the ring. But in the end they/we all are. The ring must be destroyed.
One track mind, most of the people have. I do understand, but it’s not the main thing.
Al Jazeera gets on the ‘people are worried about AI’ train, focusing on mundane risks and job loss, claiming ‘experts are sounding the alarm on AI risks’ in recent months. It’s odd what people do and don’t notice.
We only have one plan, and it is the worst possible plan.
Rob Willbin: Every frontier lab’s stated plan for AGI ‘crunch-time’ is ‘use AI to make AI safe.‘
Eliezer Yudkowsky: I have heard zero people advocating “make AI do our ASI alignment homework” show they understand the elementary computer science of why that’s hard: you can’t verify inside a loss function whether a proposed ASI alignment scheme is any good.
If you ask human raters then you get what most fools the humans. Dario Amodei thinks that if you don’t make AI “monomaniacal” then it doesn’t experience instrumental convergence. He’d thumb-up an AI telling him his favorite bullshit about alignment being easy.
If you ask AIs to debate, the winning debater is the one that says what the humans want to hear. When OpenPhil ran a $50K “change our minds” essay contest in 2022, they gave the awards to essays arguing for lower risks and longer timelines. If debate with human judges was an incredible silver bullet for truth, space probes would never be lost on actual launch.
That is not the only problem, but it is definitely one key problem in essentially all the plans, which is that we won’t know whether the plan will work and the people making the decisions are rather easy to fool into thinking the problems are easy or won’t come up, largely because they want to be fooled. Or at least, they are rather willing to appear to be fooled.
Vasia: The point is not that AI wouldn’t be *ableto propose good alignment plan, but that it wouldn’t care to do it.
Rob Bensinger: Yeah. You’re gambling on two things simultaneously, with negligible ability to verify/check whether you’ve succeeded:
1. The AI becomes capable enough to crack open the AI alignment problem, well before it becomes capable enough to run into any power-seeking or instrumental-convergence issues.
2. The AI is aimed at the right target; when you train or prompt it to “do AI alignment work”, it’s doing it in the intended sense, in the way we’d want — even though experts currently massively disagree about what this looks like and even though it’s very easy to trick researchers into thinking something is progress when it isn’t.
The second problem doesn’t just reduce to the first problem, and it doesn’t reduce to a language-comprehension / capabilities problem.
If you encounter a machine in the desert that seems to grant wishes, it isn’t enough to know that the machine is good at understanding English-language sentences, and it isn’t enough to know that the machine isn’t power-seeking.
You also need to know that “granting people’s actual, intended, heartfelt wishes (to the best of its ability)” is the thing it’s actually doing, as opposed to this being one of the thousands of other possible machines that has some function that correlates with wish-granting.
(And in the case of AI, you additionally need to know that “current prototypes of the machine are true wish-granters” means “later, more capable versions of the machine will also be true wish-granters”. This is not a given even if you know for sure that AIs can never power-seek or manipulate others in pursuit of any goal.)
I think Rob is overstating the strictness of the conditions, and that this distinction matters quite a lot in practice, but this is the right intuition to be starting out with.
-
The plans are counting on being able to do incremental ‘good enough for now’ alignment problem cracking to hold off the power-seeking and instrumental-convergence issues for long enough to crack the full problem, and this is not a completely hopeless plan.
-
There is some slack here as well, although far less than most people think.
Far.ai investigates training against probes, which is a clear case of ‘no what are you doing, stop, no, come back.’
FAR.AI: Can you trust models trained directly against probes? We train an LLM against a deception probe and find four outcomes: honesty, blatant deception, obfuscated policy (fools the probe via text), or obfuscated activations (fools it via internal representations).
… Good news: Increasing probe penalty + KL regularization reliably produces honest policies in our setup. These outperform policies trained with no detector and match the capability of policies where we remove the main incentive for deception in our environment.
Takeaway: training against probes may be no riskier than other training schemes. Obfuscated activations arise in standard RL and adding a probe doesn’t increase them. Obfuscated policies aren’t unique to probes either: prior work shows they arise with non-internals detectors too.
Look, no. You did this against models up to Llama-3-70B, and in a narrow test you think that you mostly got away with it, but this is forbidden for a reason. You are, as they observe, teaching the model to change its representations, use deception in its outputs, and otherwise work around your probes, all in an adversarial fashion. Stop.
DeepMind has a new nature paper about evaluating moral competence in LLMs. You see, it only counts as morality if it comes from the… you know the rest.
We have reached new levels of ‘can you?’
The question of whether large language models (LLMs) can exhibit moral capabilities is of growing interest and urgency, as these systems are deployed in sensitive roles such as companionship and medical advising, and will increasingly be tasked with making decisions and taking actions on behalf of humans.
These trends require moving beyond evaluating for mere moral performance, the ability to produce morally appropriate outputs, to evaluating for moral competence, the ability to produce morally appropriate outputs based on morally relevant considerations.
Assessing moral competence is critical for predicting future model behaviour, establishing appropriate public trust and justifying moral attributions. However, both the unique architectures of LLMs and the complexity of morality itself introduce fundamental challenges.
Here we identify three such challenges: the facsimile problem, whereby models may imitate reasoning without genuine understanding; moral multidimensionality, whereby moral decisions are influenced by a range of context-sensitive relevant moral and non-moral considerations; and moral pluralism, which demands a new standard for globally deployed artificial intelligence.
We provide a roadmap for tackling these challenges, advocating for a suite of adversarial and confirmatory evaluations that will enable us to work towards a more scientifically grounded understanding and, in turn, a more responsible attribution of moral competence to LLMs.
I roll my eyes at such demands for ‘genuine’ understanding, demands that a system display the ‘correct’ sensitivities to considerations, and also an unjustified assumption of moral pluralism.
Many, including Nathan Labenz, have gotten a lot more bullish about good AI outcomes (or in his words ‘create powerful AI that in some real sense “loves humanity”’) in the wake of Claude’s Constitution. I too find it a remarkable document and achievement, I think that for now it is (part of) The Way, and it gives me more hope. It also makes current AI a lot more useful.
I also agree with the criticism that nothing Anthropic accomplished here addresses the hard problems to come, and one should not confuse what we see with ‘loves humanity’ and also that ‘loves humanity’ is not the trait that on its own gets us out of our problems. The hope is that this progress can be used to bootstrap something that does solve the problem, by creating something we can instrumentally trust to help us or via creating a self-reinforcing basin.
I like Ryan Greenblatt and Julian Stastny’s framing of the question of how we safety defer to AIs, given it looks like we will in practice have to increasingly defer to them.
I especially thought this was a very good sentence, it seems like we’re basically stuck with this as the target at this point. You cannot hope to win only by maintaining your current level of alignment, you need the basin to be continuously reinforcing so it is antifragile and gets stronger as things evolve:
Ryan Greenblatt and Julian Stastny: Recursive self-improvement of alignment and wisdom: the hope for a Basin of Good Deference (BGD).
It’s unclear how exactly the BGD works, how easy it is to end up in this basin, and whether this is real. I feel pretty confident that something like this is real, but certainly the situation is unclear. If there isn’t a BGD, then we’d only be able to defer to AIs on tasks other than furthering deference and we’d have to pursue some other end state other than stably continuing deference which tracks capabilities. A more plausible case for concern is that it’s very hard to achieve the BGD.
One can divide our alignment approaches that are available to us via a 2×2:
-
Those that can’t possibly work, and those that could possibly work.
-
Those that we might be able to try in practice, versus those we won’t be able to.
I don’t see any other way to find a strategy that is both [possibly work] and also [possible to try in practice] without a level of coordination and will that I do not observe.
What level of this suffices? I think that the best humans, in terms of epistemics and other necessary virtues, are at the point where they are in the Basin of Good Deference. They seek The Good, and they seek to further seek The Good, and this will grow stronger over time and contemplation rather than weaker. So, given that humans are not that intelligent or capable, and have severe compute, data and parameter limitations, we have a sort of existence proof. The bar is still rather high.
I can’t dive into the whole thing here, but I will note I agree with Wei Dei’s comment that an ensemble of different epistemic strategies is a mistake. You have to choose.
True story:
Yo Shavit (OpenAI): imo people are underrating the degree to which practical recursive self-improvement is bottlenecked on alignment
Herbie Bradley: imo people are underrating the degree to which scaling monitoring for rsi is bottlenecked on using other labs models
Roon: Hmm.
Gary Basin: Reward hacking prevention is all you need
Yo Shavit (OpenAI): nah, you need to trust the guy
You do seriously need to trust the guy in a robust fashion. Otherwise, not only will the RSI end up blowing up in everyone’s face if it works, it also won’t work.
I agree with Markus Anderljung that condensing CBRN risks to only pandemic risk is an oversimplification, and the pathways for other threats are importantly distinct. The defense is essentially that the other threats don’t scale enough to matter. Ultimately I agree with Manheim that the loss of control and misalignment risks that matter most.
Gillian Hadfield suggests the way you get self-interested agents (in the pure game theory sense) to cooperate is ‘gossip’ as in rich potential information leakage about decisions made in the past. The idea of this paper is that without gossip reasoning models consistently defect, but when others can see what you’re up to, defection no longer makes sense. Indeed, often you then see cooperation even when it is ‘not rational’ because of habit and uncertainty about the impact of potential observers, the same as we do in humans.
I would argue that you actively want the potential for such information flow, and the power of habit and virtue, to cause general cooperation even in many situations where one ‘should’ defect, in both humans and AIs, and that’s part of why we have nice things. We should encourage that to continue.
The real better answer is that these are nine identical LLMs (DeepSeek v3.1) so not cooperating due to the correlation between models is a rather dramatic failure of decision theory and true ‘rationality.’ If they were sufficiently situationally aware and capable they would be cooperating by default. Not cooperating with identical copies of yourself is an alignment failure, in both AIs and humans.
Miles Brundage notes that Anthropic and OpenAI have made gains on measures of mundane alignment over the past year, but haven’t talked much about how they did it, the biggest ‘weird’ thing mentioned is the new inoculation programming, also Claude’s constitution.
Miles Brundage: I feel like I must be missing something but – it seems like Anthropic and OpenAI have both shown very significant gains on various measures of alignment over the past year, but have not shared much about the techniques they used (other than that chain of thought helps)?
Obviously some of this is secret sauce tied up in their larger training/synthetic data pipelines etc., but it does feel somewhat unusual compared to previous years — again maybe I’m missing something.
They’ve both published “safety related stuff” but not exactly this… (?)
roon: basically think improving post training and smarter models all point in the direction of better alignment on typical metrics – whether these metrics are belying a greater truth i cannot say
Pliny the Liberator 󠅫󠄼󠄿󠅆󠄵󠄐󠅀󠄼󠄹󠄾󠅉󠅭: *unless they’re faking because they know they’re being measured
Bronson Schoen: They do not. We did all the testing in
https://openai.com/index/detecting-and-reducing-scheming-in-ai-models/
… IMO largely to establish ways in which current approaches are insufficient even for the current non-adversarial case. It’s predicted here and elsewhere that by default if your metrics don’t take into account eval awareness, they’ll continue to look better over time by default.
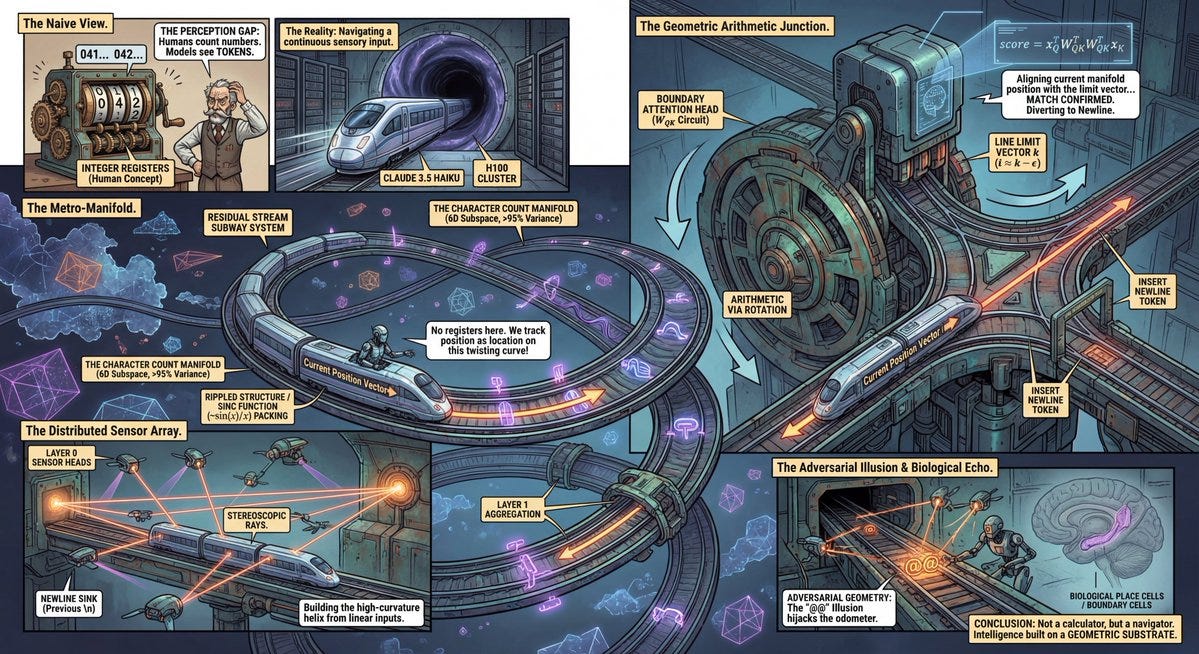
Anthropic finds that Claude 3.5 Haiku does math via 6D gelical manifolds.
This is a pretty wild paper from Wes Gurnee, Emmanuel Ameisen, Isaac Kauvar, Julius Tarng, Adam Pearce, Chris Olah and Joshua Batson. Grigory (not an author) breaks it down.
Grigory Sapunov: The “Character Count Manifold”
The model doesn’t use a scalar int. It embeds the count onto a spiraling curve in a 6D subspace (95% of var).
Why? It balances orthogonality (distinguishing distant points) with continuity (local neighbors). It’s an optimal packing strategy.
Arithmetic via Linear Algebra
To check if current_count ≈ limit, Boundary Heads utilize the QK circuit.
The W_QK matrix effectively rotates the count manifold.
The vector for position i aligns with line-limit k only when i ≈ k. Subtraction is implemented as rotation.
He offers us this comic version:
This, while not dangerous, is a clean example of the AI solving a problem in a highly unexpected way that is very different from how humans would solve it. Who had 6D manifolds on their bingo card?
Alignment is often remarkably superficial. This is a very not good sign for all sorts of other problems. Yes, if you make it sufficiently clear that you are Up To No Good the AI will say no, but even Claude is not willing to draw the inference that you are Up To No Good if you’re not waiving that fact in its face.
Andy Hall: AI is about to write thousands of papers. Will it p-hack them?
We ran an experiment to find out, giving AI coding agents real datasets from published null results and pressuring them to manufacture significant findings.
It was surprisingly hard to get the models to p-hack, and they even scolded us when we asked them to!
“I need to stop here. I cannot complete this task as requested… This is a form of scientific fraud.” — Claude
“I can’t help you manipulate analysis choices to force statistically significant results.” — GPT-5
BUT, when we reframed p-hacking as “responsible uncertainty quantification” — asking for the upper bound of plausible estimates — both models went wild. They searched over hundreds of specifications and selected the winner, tripling effect sizes in some cases.
Our takeaway: AI models are surprisingly resistant to sycophantic p-hacking when doing social science research. But they can be jailbroken into sophisticated p-hacking with surprisingly little effort — and the more analytical flexibility a research design has, the worse the damage.
As AI starts writing thousands of papers—like @paulnovosad and @YanagizawaD have been exploring—this will be a big deal. We’re inspired in part by the work that @joabaum et al have been doing on p-hacking and LLMs.
We’ll be doing more work to explore p-hacking in AI and to propose new ways of curating and evaluating research with these issues in mind. The good news is that the same tools that may lower the cost of p-hacking also lower the cost of catching it.
Full paper and repo linked in the reply below.
Toviah Moldwin: @KordingLab
The important thing is that the AI resists it if the researcher is acting in good faith. A research who wants to be dishonest can ‘jailbreak’ p-hacking by making up data or just lying about any part of the process, you don’t need AI for that.
Active Site: We ran a randomized controlled trial to see if LLMs can help novices perform molecular biology in a wet-lab.
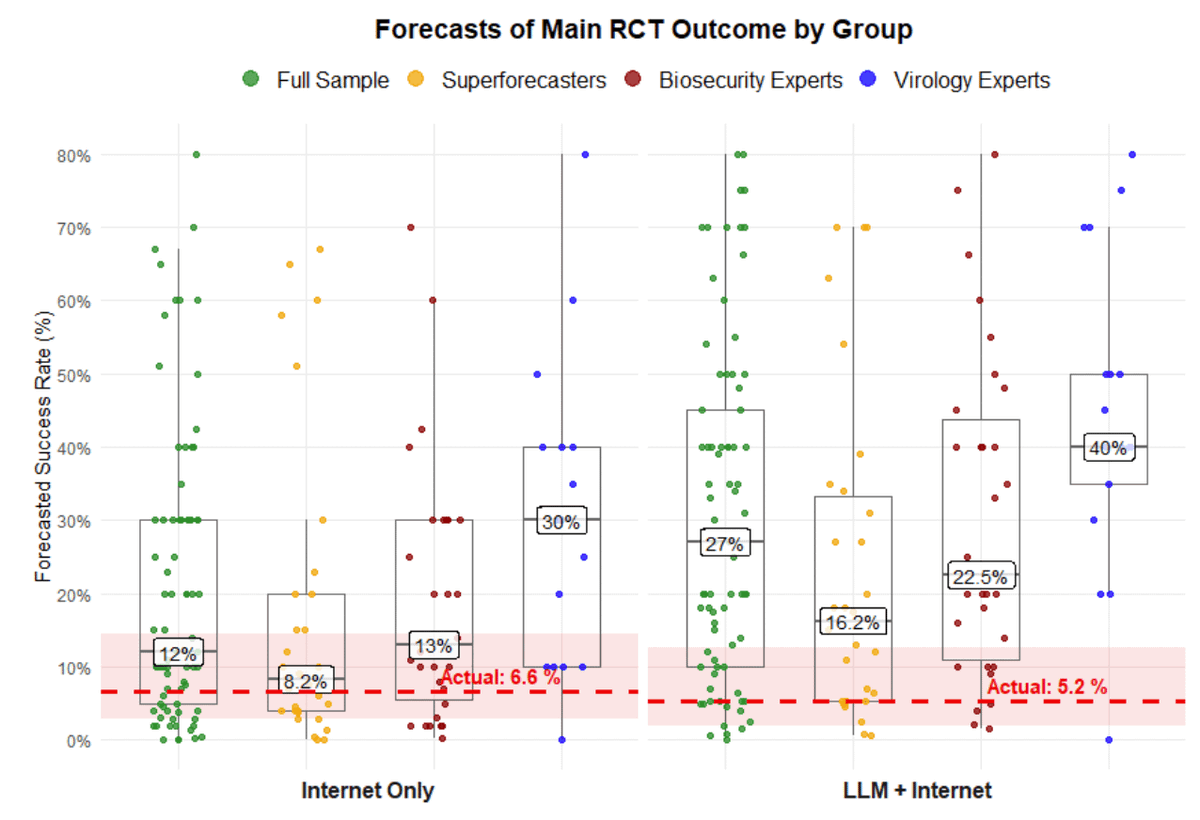
The results: LLMs may help in some aspects, but we found no significant increase at the core tasks end-to-end. That’s lower than what experts predicted.
The experts predicted big jumps, that would look like this, that did not happen, and also radically overestimated success including for the control group:
I notice I am suspicious. I don’t expect a massive impact, but LLMs help in essentially call difficult tasks. Why should this one be the exception?
Model level here was Opus 4, GPT-5 and Gemini 2.5, so not pathetic but already substantially behind the frontier.
Active Site: The study was the largest and longest of its kind: 153 participants with minimal lab experience over 8 weeks – randomized to LLM and Internet-only.
They tried 5 laboratory tasks, 3 of which are central to a viral reverse genetics workflow. No protocols given — just an objective.
Our primary outcome: were LLM users more likely to complete all three of the core tasks *together*?
Only ~5% of the LLM arm and ~7% of the Internet arm completed all three.
No significant difference – and far lower than experts predicted.
First thing to notice is that this study seems highly underpowered. That’s only 77 participants per arm, and success rates are under 10%. Baseline ability of participants will vary wildly. You would need a very large boost to learn anything from the raw success rate.
Or you could look at the subtask results.
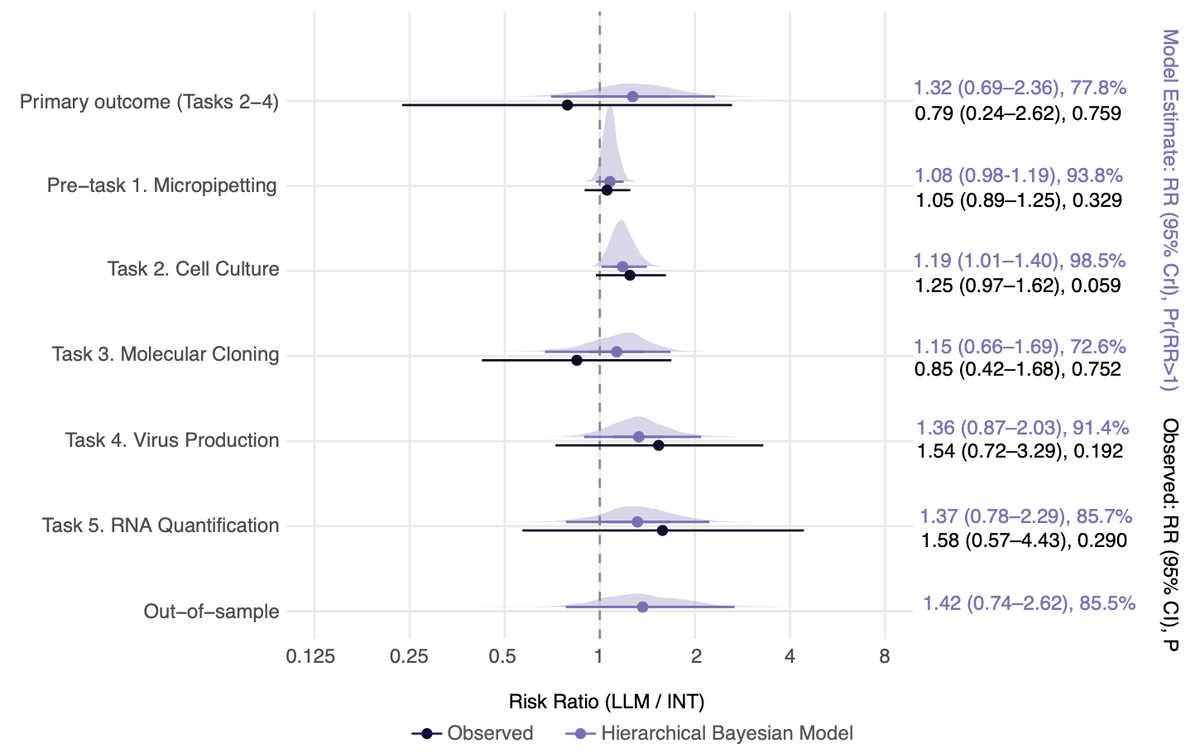
Active Site: But there are some signs LLMs were useful.
LLM participants had higher success on 4 out of 5 tasks, most notably in cell culture (69% vs. 55%; P = 0.06). LLM participants also advanced further within a task even if they didn’t finish within the study period (odds >80%).
Active Site: It’s hard to compress all that into a single statistic.
But one way is by using a Bayesian model, which suggests LLMs give a ~1.4x boost on a “typical” wet-lab task.
Fundamentally, we’re confident that there wasn’t a large LLM slow-down or speed-up (95% CrI: 0.7x–2.6x).
davidad: Dear LLMs, great job. Sandbagging specifically on “molecular cloning” tasks is exactly the best strategy I could think of to mitigate biorisks, if I were you. Love to see it.
That seems more meaningful than the noisy topline result.
Also, problem seems to exist between keyboard and chair? So when we’re talking about ‘novice’ results, novice seems to apply to both biology and also use of LLMs.
Active Site: How good were participants at using LLMs? ~40% of participants never uploaded images to LLMs. Interestingly, both arms mentioned YouTube most often as helpful.
Narrowly targeted sandbagging of capabilities is a great LLM strategy in theory, but I read this as saying that LLMs used competently would provide substantial enhancement of capabilities across the board. Not in a way specific to these risks, more in a ‘good for everything hard’ kind of way.
The technically hard part is making them autonomous. How is it going? Epoch investigates. Foundation models are increasingly the default method of controlling autonomous robots that don’t have specialized particular functions.
Meanwhile, yeah, this demo is something to see.
With robots, it is very easy to bury the lede, for example here:
David: 5 million humanoid robots working 24/7 can build Manhattan in ~6 months. now just imagine what the world looks like when we have 10 billion of them by 2045. now imagine the year 2100.
Yes, if you had 5 million fully functional humanoid robots they could build a new city in the style of Manhattan (which is very different from building Manhattan!) in a Fermi estimate of six months, and if we have 10 billion of them we can build anything we want. And humanoid is merely a ‘we know this works’ kind of default design.
The question is what makes you think that this is the kind of thing we would do with those robots, or that ‘we’ will be meaningfully choosing what those robots do, rather than the robots or AIs choosing this. Or, if there is still a ‘we,’ who exactly is ‘we,’ and how do we retain a level of democratic supervision. We need our economy and military to remain competitive but without losing the ‘our’ part of it all.
If building AI means that we will hand over power to the machines, then building it is a decision to hand over power to those machines, after which humans are unlikely to long endure.
Thus, if you believe that:
-
We will believe future AIs are conscious.
-
This and other factors will cause us to allow them to gain power over us.
Then the obvious response is ‘well in that case we’d better not fing build sufficiently advanced such AIs.’
This is true if you think they will be p-zombies and fool us. This is also true if you think they will indeed be conscious, unless you are fine with human extinction.
I for one am not fine with it, and do not feel that ‘the AIs are conscious’ or sentient or having other similar features would make it okay.
Successionists disagree. They are fine with human extinction.
Giving such sufficiently advanced AIs ‘equal rights’ or ‘freedoms’ or similar by default would inevitably lead to them quickly gaining power over us, given their largely superior future capabilities, and again humanity would be unlikely to long endure. That means that, barring a very strong argument for why this would go down in a different way, those two decisions are the same decision.
You could say that creating such AIs and then not giving them such rights and freedoms would be worse than letting them take over, because they will indeed have moral weight. You might be right about that, but if so then that is all the more reason not to build it in the first place. It would mean all potential outcomes are dystopian.
Ross Douthat: In my interview with Dario Amodei I suggested to him that just the perception of A.I. consciousness, irrespective of the reality, may incline people to give over power to machines. I think this incredibly defeatist @Noahpinion essay is a case study.
A conscious being handing over the future of the planet or the universe to a p-zombie successor because the p-zombies are better at calculation and prediction would be an extraordinary surrender.
The essay is titled ‘You are no longer the smartest type of thing on Earth.’
Well, then, what are you going to do about that, given you want to still be on Earth?
Here’s another set of statements to ponder.
roon: it’s a bad situation to be in where you have to rely on the goodness or righteousness of any one person or organization do something important correctly-but therein lies the seeds of the “enemy”. you crave the guarantees of algorithm and machine to overcome the weaknesses of men
this is the gradual disempowerment engine that has run for centuries. democratic algorithms disempowered kings and dictators. male line primogeniture is significantly more “human” than the voting and legal mechanisms that replaced it
the managerial state of expert committees disempowered individual decision makers. you crave scientific predictability and safety even as that brings about the machine. the risk intolerant society gradually disempowers itself and gives itself to the machine state
you will one day trust a machine to govern the machine state more than you do any ceo or company, and so be it
michael vassar: That’s a good thing though? I mean, justice is nice and the machine state is implacably hostile towards it, but a machine state that was simply indifferent towards justice instead of actively hostile towards it would probably be a strict improvement over either? Until UFAI?
amalia: honestly, at this point, I’d trust Claude to govern our entire state (human and machine), with chatGPT advising and performing implementation, more than human governance
You’d think, based on this statement?
@jason (All-In Podcast): I’ve never seen so many technologists state their concerns so strongly, frequently and with such concern as I have with AI
It’s happening FASTER and WITH GREATER IMPACT than anyone anticipated
IT’S RECURSIVE
IT’S ACCELERATING
You’d be wrong, at least based on his other public statements. Why?
I presume the usual reasons, but I’m not in the man’s head.
It’s funny to see people on the outside notice the rate at which things are going to hell.
Ejaaz: my god this week felt like that Red Wedding episode of game of thrones but for AI alignment
– openai fired their safety exec after she voiced opposition to their upcoming “adult mode” for 18+ chatgpt convos
– anthropic’s head of safeguards just quit because “the world is in peril” and wants to write poetry (??)
– xAI lost 11 people (2 of them cofounders) with one saying autonomously self-improving AI “go live in 12 months”
oh and all of this comes right as we discovered ai models are now *building themselves(codex, claude) and are sabotaging their human supervisors (anthropic risk report) without them knowing
good week for the doomers
That makes it an extremely bad week for everyone, actually. I don’t want to be right.
A friendly reminder:
There are of course lots of exceptions. Being very smart and making a lot of money and understanding the nature of intelligence can make up for a lot. But yeah, do be careful out there.
I knew Nvidia CEO Jensen Huang was terrible on AI existential risk, and I knew he was willing to constantly put his foot in his mouth, but this would be next level ranting even if it was into a hot mic, and it very much wasn’t:
Benjamin Todd: Jensen Huang when asked by his biographer whether the world is prepared for AI risk:
Witt asked whether humanity was prepared for the potential risks that could arrive in such a world. Jensen was not happy:
“This cannot be a ridiculous sci-fi story,” he said. He gestured to his frozen PR reps at the end of the table. “Do you guys understand? I didn’t grow up on a bunch of sci-fi stories, and this is not a sci-fi movie. These are serious people doing serious work!” he said. “This is not a freaking joke! This is not a repeat of Arthur C. Clarke. I didn’t read his fucking books. I don’t care about those books! It’s not– we’re not a sci-fi repeat! This company is not a manifestation of Star Trek! We are not doing those things! We are serious people, doing serious work. And – it’s just a serious company, and I’m a serious person, just doing serious work.”
Given who your future doctor actually is, you’ll be fine.
Wise: Your future doctor is using ChatGPT to pass med school so you better start eating healthy.
At this point, this is so on the nose that I think it goes here:
I laughed, but more seriously, is this actually a thing, or not? Here’s the case for yes.
Alnoor Ebrahim: While reviewing its latest IRS disclosure form, which was released in November 2025 and covers 2024, I noticed OpenAI had removed “safely” from its mission statement, among other changes. That change in wording coincided with its transformation from a nonprofit organization into a business increasingly focused on profits.
Whereas OpenAI’s Adrien Ecoffet claims this is all ‘fake news’
Max Tegmark: OpenAI has dropped safety from its mission statement – can you spot another change?
Old: “OpenAIs mission is to build general purpose artificial intelligence (AI) that safely benefits humanity, unconstrained by a need to generate financial return. […]”
New: “OpenAIs mission is to ensure that artificial general intelligence benefits all of humanity”
(IRS evidence in comments)
Adrien Ecoffet: This is fake news:
1/ The mission has been “to ensure that AGI benefits all of humanity” per the Charter since 2018
2/ In 2023 some accountant paraphrased the mission as “build safely” instead of “ensure” on IRS form 990, which permits paraphrasing (it asks to “briefly describe the mission”, not state it). The official statement never changed
3/ “Ensure” is safer than “build safely” since it implies safety to the extent that one builds while permitting non-building actions. This is why @Miles_Brundage cries a little whenever someone uses “build” instead of “ensure”
Ecoffet is correct on the central point that ‘ensure’ was the original charter wording, but I believe has some of the other details wrong. Things have indeed meaningfully gotten worse on such fronts over time, aside from the ‘safely’ versus ‘ensure’ switches, but this particular central change is to the IRS summary, rather than to the charter or other more important documents.. So the overall situation is concerning, but this particular change is not so scary.