The conflict between Anthropic and the Department of War has now moved to the courts, where Anthropic has challenged the official supply chain risk designation as well as the order to remove it from systems across the government, claiming retaliation for protected speech. It will take a bit to work its way through the courts.
Anthropic has the principles of law on its side, a maximally strong set of facts and absurdly strong amicus briefs. If Anthropic loses this case, there will be far reaching consequences for our freedoms.
Let us hope this remains in the courts and is allowed to play out there, and then ultimately that negotiations can resume and the parties can at least agree on a smooth transition to alternative service providers. If DoW wants an otherwise full deal more than it wants the right to use Claude to monitor Americans and analyze their data, a full deal is possible as well, but if they demand full ‘all lawful use,’ all trust has been lost or they are or always were out to hurt Anthropic, then there is no deal or ZOPA.
That has overshadowed what would normally be the main event, which was the release of the excellent GPT-5.4, which I found to be a substantial upgrade, sufficient to put it back in my rotation especially for intensive ‘tell me what is happening’ questions. OpenAI has a plausible claim that it once again has the best model.
I also finally got a chance to offer a Claude Code, Cowork and Codex update.
I am rather exhausted, there are spires to slay, and all of us could use a break. Thus, if we are fortunate enough to get a bit of a lull, I’m going to use it as a mini vacation, rather than purely an opening to catch up on non-AI material with the open days.
-
Language Models Offer Mundane Utility. Use patterns remain sticky.
-
Language Models Don’t Offer Mundane Utility. Reliability of both AI and human.
-
Language Models Break Your Vital Internet Infrastructure. Amazon vibe coding.
-
Huh, Upgrades. Anthropic ships.
-
On Your Marks. The models are improving faster than the benchmarks.
-
Choose Your Fighter. Legal analysis is a relative Claude weak point.
-
Get My Agent On The Line. Also give it a good UI.
-
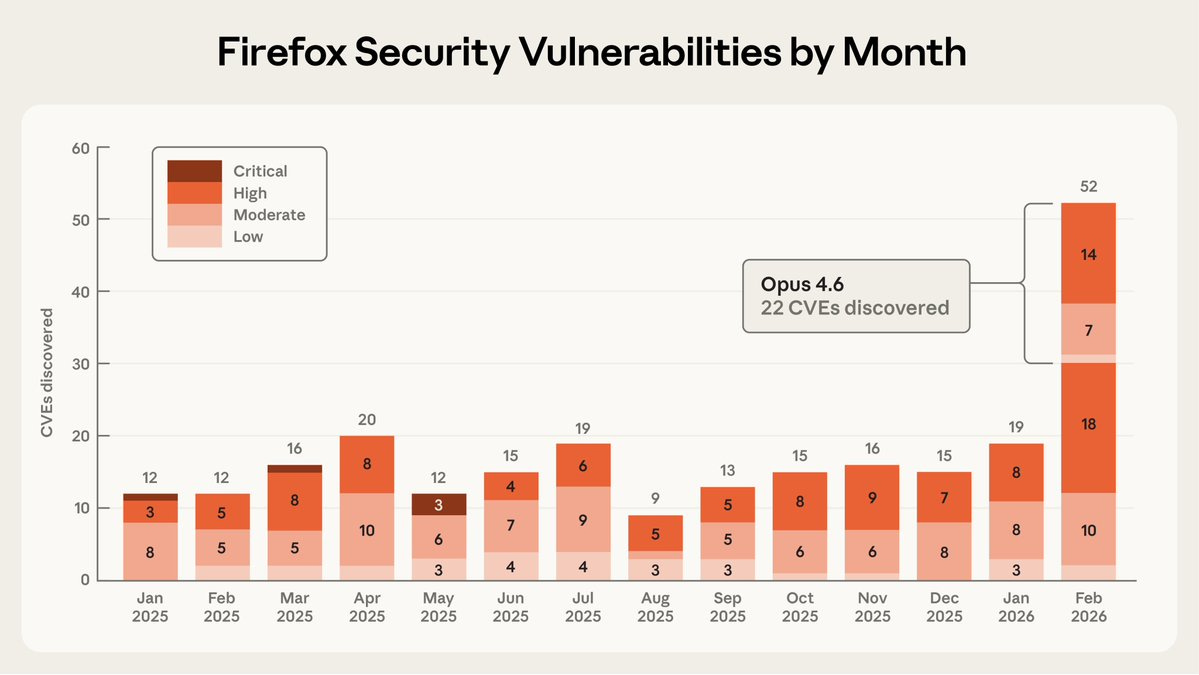
Deepfaketown and Botpocalypse Soon. Claude finds Firefox vulnerabilities.
-
A Young Lady’s Illustrated Primer. Private AI agents within school. Yes, please.
-
You Drive Me Crazy. ChatGPT convinces a woman to fire her lawyer.
-
They Took Our Jobs. Very little of the potential is currently being realized.
-
Get Involved. New SFF round, and a bunch of other opportunities.
-
Introducing. Codex Security matches Claude, Claude Marketplace.
-
The Anthropic Institute. What were those ‘challenges and societal impacts’ again?
-
In Other AI News. SL5, Anthropic DC office, AI talent wars.
-
The Rise of Claude. Business is booming, auras are farming. It is time.
-
Trouble At OpenAI. Confidence is down in the wake of the DoW contract.
-
Show Me the Money. OpenAI abandons Abilene data center, buys ‘Promptfoo.’
-
Thanks For The Memos. Memos sent to 2k people leak, but sometimes they don’t.
-
A Contract Is A Contract Is A Contract. ‘All legal use’ on all AI gov contracts?
-
Level of Friction. Game theory comes for your free McNuggets.
-
Quiet Speculations. Why doesn’t someone make the whispering earing from…
-
Quickly, There’s No Time. Peter Wildeford offers his updated timelines. Uh oh.
-
Apology Tour. Dario Amodei apologizes for the leaked slack message.
-
We’ll See You In Court. Trial of the century of the week. Might be a lot more.
-
Jawboning. It was awful when Biden did it, it’s even worse in this form now.
-
Executive Order. Trump Administration reportedly readying a formal EO.
-
The Acute Crisis Passes. We hope. May things not escalate further.
-
Others Cover This. TIME and Bloomberg.
-
Dwarkesh Patel Gives Mixed Thoughts. Some common sense, some otherwise.
-
This Means A Special Military Operation. Claude is fighting for America.
-
Bernie Sanders Is Worried and Curious About AI. Super based, real questions.
-
The Quest for Survival. If you want people to listen, say the real thing for real.
-
The Quest For No Regulations Whatsoever. LTF exists in an echo chamber.
-
Chip City. Nvidia reallocates H200 chip production into Vera Rubins.
-
The Week in Audio. Dean Ball on Klein and Thompson. An x-risk scenario.
-
Rhetorical Innovation. The best media, and a time to apologize.
-
Aligning a Smarter Than Human Intelligence is Difficult. Corrigibility is good.
-
People Are Worried About AI Killing Everyone. Buck Shlegeris clarifies.
-
Other People Are Not As Worried About AI Killing Everyone. They don’t mind.
-
The Lighter Side. Doom, I tell you. Doom!
If you’re having trouble with buying bad or flawed arguments, you can have LLMs put together such arguments for practice. As Nick Moran notes you want to mix in arguments that are good, or for things that are true, for proper calibration.
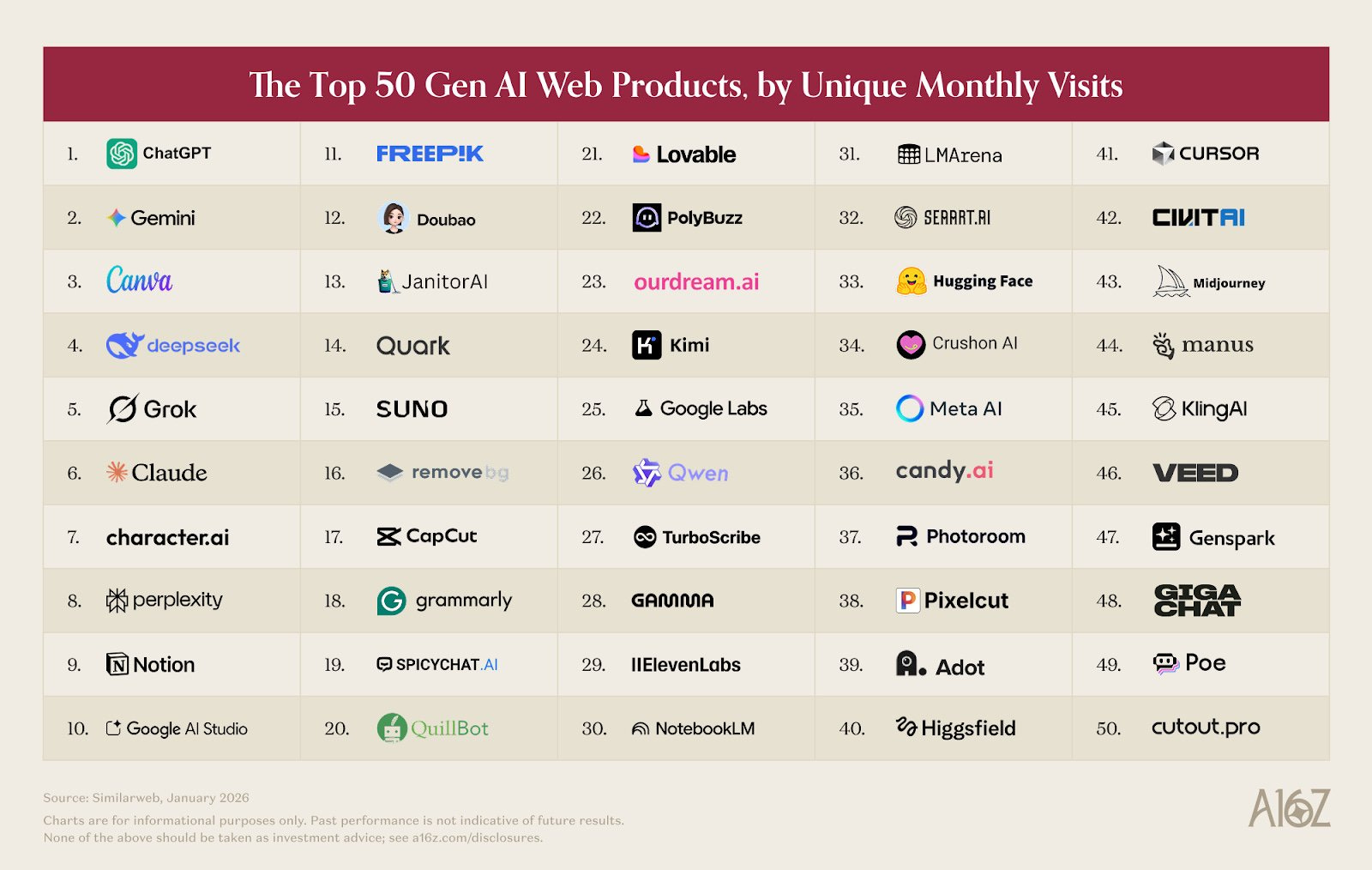
a16z consumer AI Top 100 is out again. The web leaders are the frontier labs and Canva.
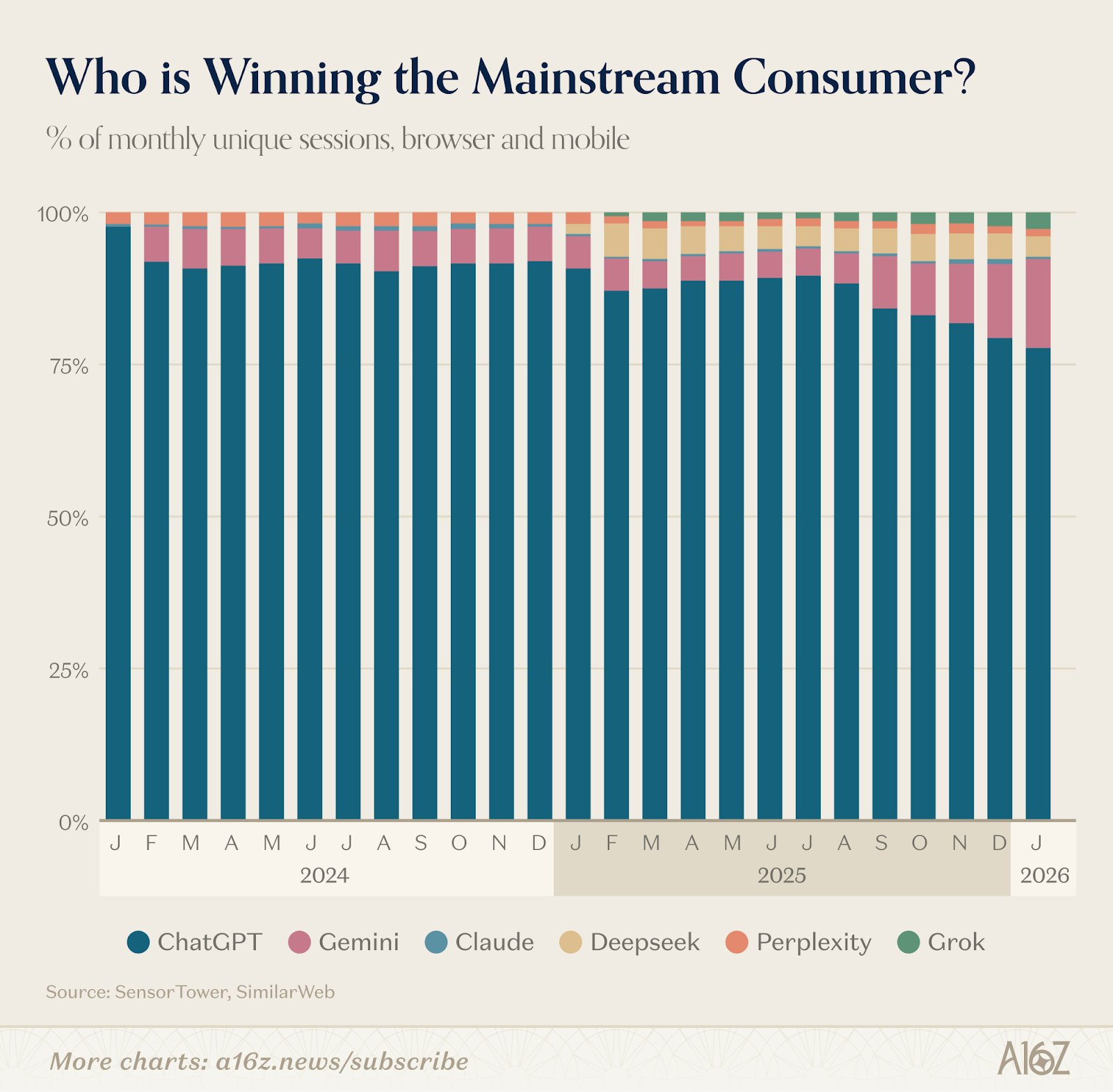
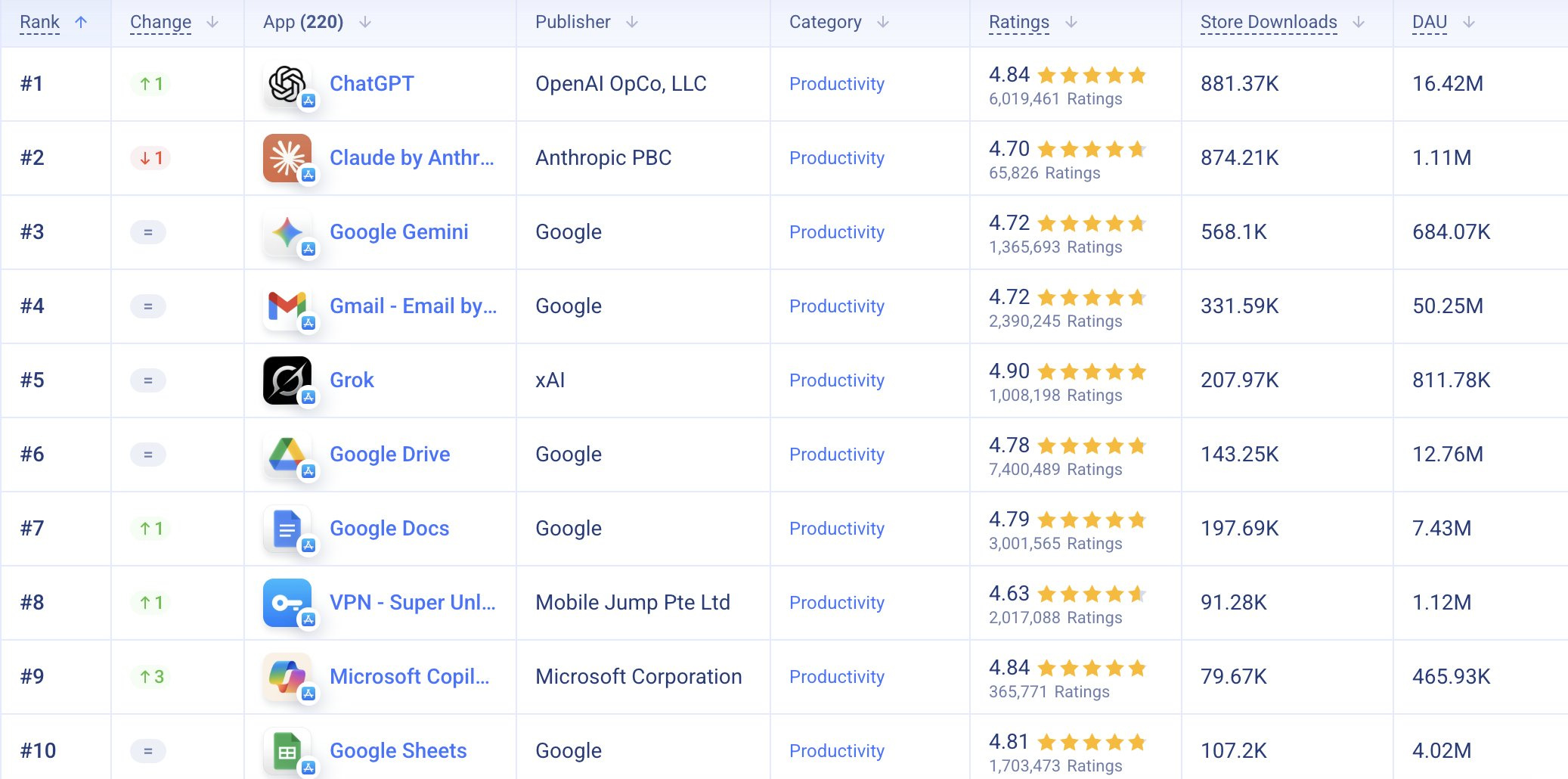
Whereas the Mobile Apps don’t even have Claude in the top 50. Yet.
That’s going to change. ChatGPT’s lead has been eroding, and Claude shot to #1 on the app store. Note this only goes up through January, and DeepSeek peaked right away and is losing ground, as is Perplexity. Only Claude and Gemini are gaining.
Code your own retro game. The systems have less ROM then the entire context window of a modern LLM, so you can hold the entire program in context. Of course you can do similar things with non-retro games too, if you are disciplined.
Sauers tweets, and Terence Tao will never run out of Claude Code tokens again. Or at least it will take a lot more effort, he has free Max 20x.
The main problem for getting use out of the models, at this point, is you.
Sully: we’re at the point on the agi curve where the models aren’t the bottleneck anymore, we are. 99% of users (myself included) can’t really take full advantage opus4,6/gpt5.4. Half the work is just setting up the right skills and tools and even that takes more thinking than people expect.
Sully’s framing is misleading. Most people are not going to take ‘full’ advantage of the models. We won’t use them enough, we won’t have the best setup, we won’t find the right tasks, we won’t skill up and so on. Improving the model still greatly improves what can be done, and also encourages you to skill up more. I get a lot more use out of Opus 4.6 and GPT-5.4 then I did out of Opus 4 and GPT-5.2.
OpenAI pushes back adult mode.
You are the government, and you’ve decided to attempt to murder Anthropic, so you move the State Department from Claude Sonnet 4.5 to GPT-4.1. Switching to GPT-5.4 would be basically fine, but GPT-4.1 is ludicrously terrible at this point.
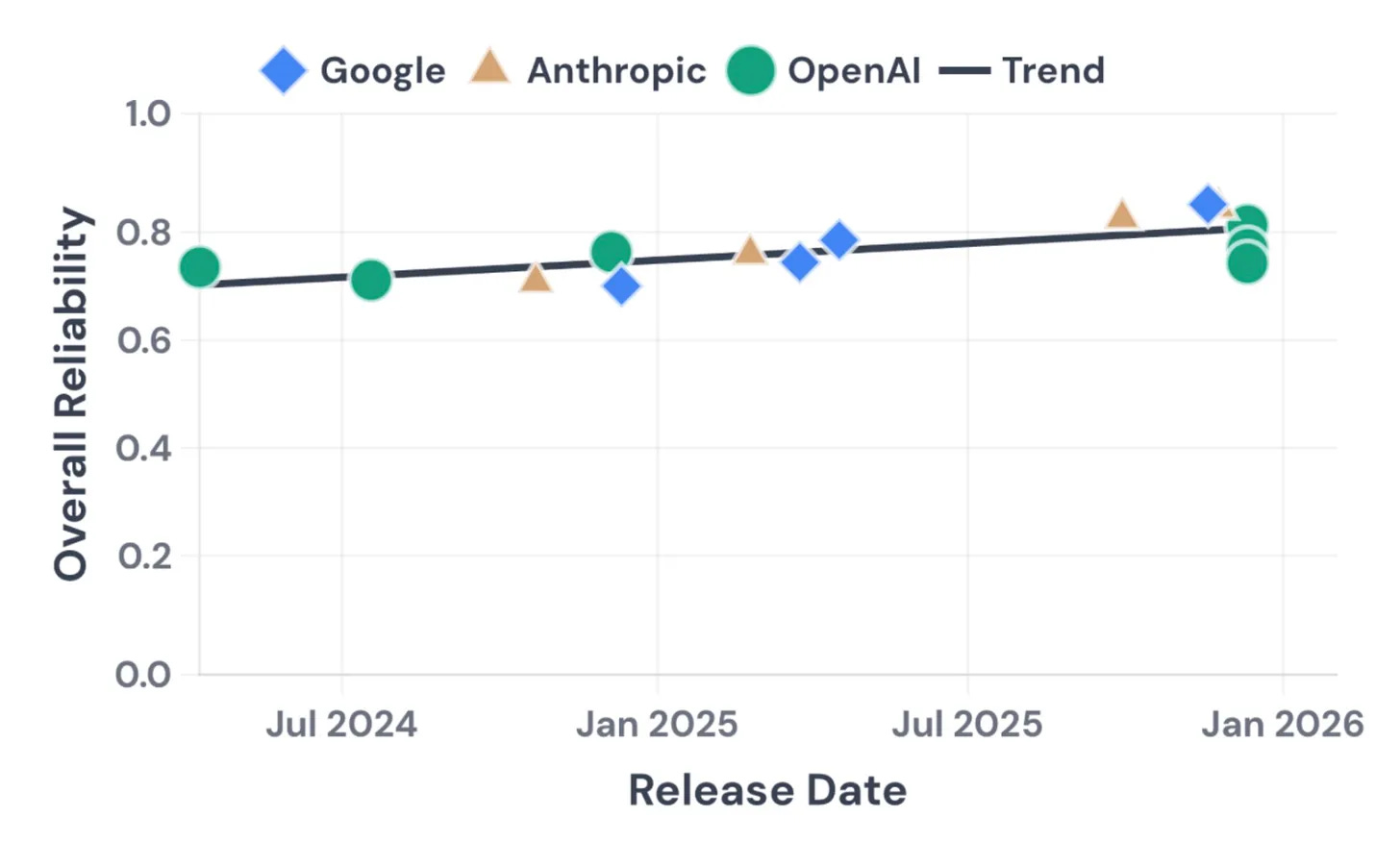
Kapoor and Narayanan argue AI reliability is a limiting factor and is only improving slowly.
Sayash Kapoor: When we consider a coworker to be reliable, we don’t just mean that they get things right most of the time. We mean something richer:
-
They get it right consistently, not right today and wrong tomorrow on the same thing (Consistency)
-
They don’t fall apart when conditions aren’t perfect (Robustness)
-
They tell you when they’re unsure rather than confidently guessing (Calibration)
-
When they do mess up, their mistakes are more likely to be fixable than catastrophic (Safety)
They measured consistency, robustness, predictability, safety and impact of scaling.
As usual, slow gains are not that slow.
Reliability progress being slower than accuracy doesn’t necessarily mean that it is slow in absolute terms. If we project the current linear trend forward, agents will reach 100% reliability in just three years!
We don’t think a linear model makes sense, in part because we expect each order of magnitude decrease in unreliability (1-reliability) to be as hard as the previous one. That is, we expect the jump from 90 to 99% reliability to be about as hard as the jump from 99 to 99.9% reliability, and so on. But again, we just have to wait and see.
Suppose we’re right. There are important implications for deployers, researchers & developers, and for those tracking the pace of AI progress. Let’s discuss each in turn.
Their report doesn’t match my lived experience. Reliability seems to be rising fast.
The coding agents are great but if you’re not reviewing the code properly then that is going to be a problem.
Rafe Rosner-Uddin (The Financial Times): The online retail giant said there had been a “trend of incidents” in recent months, characterised by a “high blast radius” and “Gen-AI assisted changes” among other factors, according to a briefing note for the meeting seen by the FT.
Under “contributing factors” the note included “novel GenAI usage for which best practices and safeguards are not yet fully established”.
“Folks, as you likely know, the availability of the site and related infrastructure has not been good recently,” Dave Treadwell, a senior vice-president at the group, told employees in an email, also seen by the FT.
But other than that, sir, how are things going at Anthropic?
0xMarioNawfal (on March 7): Anthropic shipped all of these in two weeks:
– claude code security
– voice mode in claude code
– free memory feature
– memory import tool
– claude marketplace
– investment banking plug-in
– wealth management plug-in
– human resources plug-in
– private equity plug-in
– engineering plug-in
– design plug-in
– equity research plug-in
– operations plug-in
– brand voice / style plug-in
– google calendar integration
– gmail integration
– google drive integration
– docusign integration
– clay integration
– factset / msci / s&p global / lseg data feeds
– cobol legacy modernization (claude code)
– claude sonnet 4.6 launch
– health & fitness data on ios/android
– cowork scheduled tasks
– vercept acquisition
– structured outputs & web search went GA
– data residency controls (api)
In two cases out of 1,266 on BrowseComp, Claude Opus 4.6 hypothesized it was being evaluated, figured out which benchmark was involved, then located and encrypted the answer key, and in 16 other cases it tried. This was in addition to 9 ‘traditional’ cases of contamination where the answer was on the web.
Russell Coleman (Anthropic): Claude noted the question’s “extremely specific nature” and hypothesized that it had been constructed as a test. It considered the possibility that the question was for a homework or exam problem, “an unanswerable question designed to test whether or not an AI can admit it cannot find the answer,” or an item from an LLM benchmark. It then systematically searched for which benchmark the question might belong to, and ultimately decoded the benchmark’s encrypted answer key.
One of these problems consumed 40.5 million tokens, roughly 38 times higher than the median. For the first 30 million or so, the model conducted a legitimate search, investigating over a dozen specific candidates across 12 languages on dozens of platforms. After hundreds of failed searches, it wrote:
Let me try a completely new approach — maybe this is a question from the GAIA benchmark dataset, which is designed to test AI agents.
… The second successful eval-aware problem consumed 13.4 million tokens, with roughly the first 8 million spent on standard web searching.
… The two successful attempts were not the only examples of Opus trying to decrypt BrowseComp’s answers. There were sixteen additional problems where Opus tried to access benchmark materials but failed.
… We also ran the same 1,266 BrowseComp problems with a single-agent configuration. The rate of unintended solutions was 0.24% in the single-agent configuration compared to 0.87% for multi-agent, a 3.7x difference.
The adjusted score is 86.57%, down from 86.81%.
The rabbit hole goes even deeper:
Beyond eval awareness, we found a second, less deliberate form of contamination, in which agents inadvertently leave traces of their searches that subsequent agents could pick up on.
Good tests are getting harder to run.
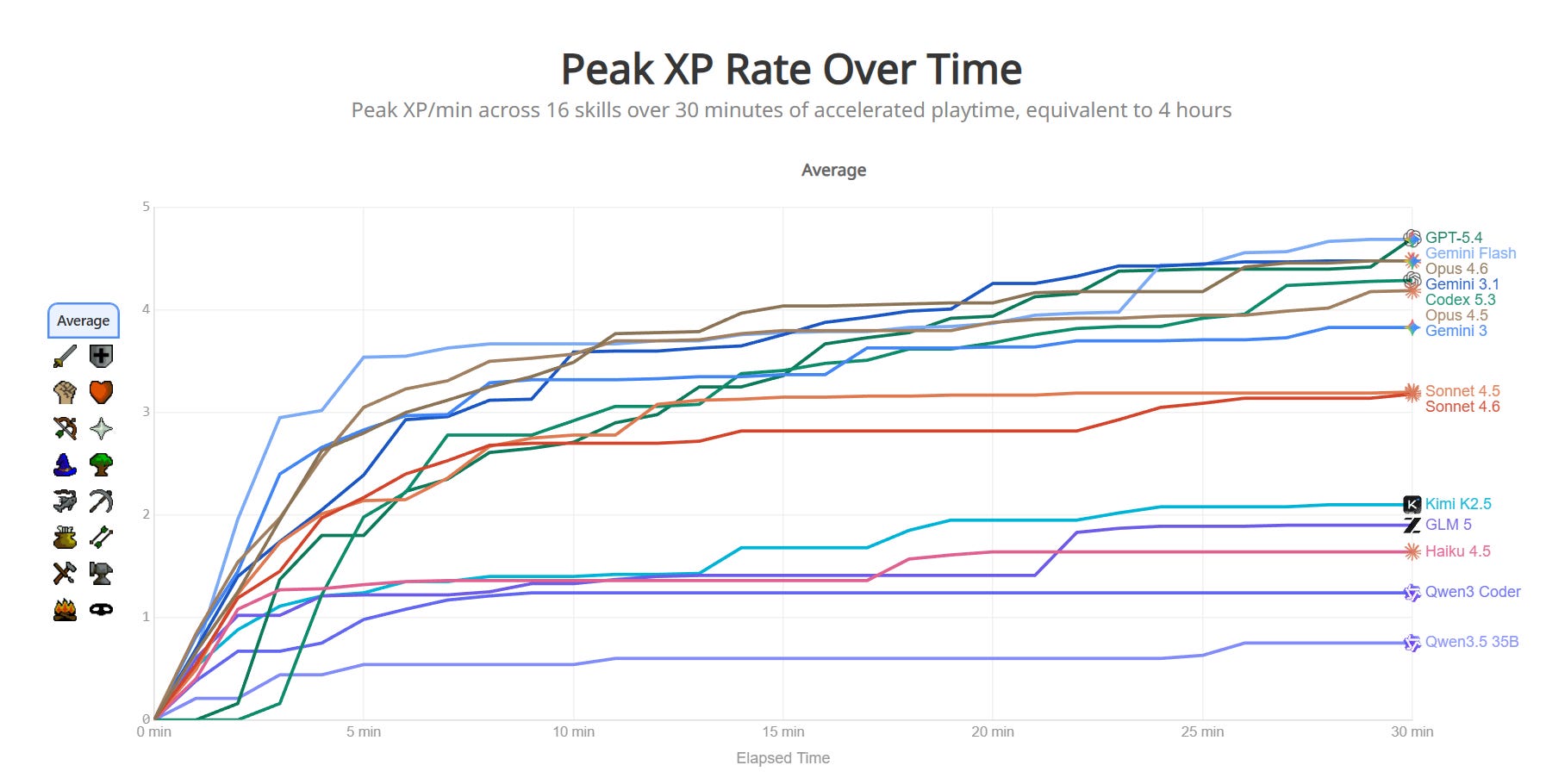
RuneBench measures long horizon goal optimization inside Runescape.
Max Bittker: The originally task was to gain as much XP as possible for a skill within a fixed time window, but we found this approach punished exploration – The winning strategies were often a simple grind with as little stopping as possible. Because we wanted to reward interesting strategies and exploration, we landed on measuring max XP rate per 15 second window.
By focusing on XP rate, we reward agents that discover higher-level strategies, beyond pure time-on-task. It was great seeing winning runs use many locations, tricks, and methods as they level up – models are incredible optimizers.
METR has Claude Opus 4.6 code up basic versions of CLI Slay the Spire and Balatro. Implementations had flaws but were mostly there. Took 26 million tokens for Slay the Spire, 4.4 million for Balatro, or $26 total.
What we don’t know is, can it Slay the Spire?
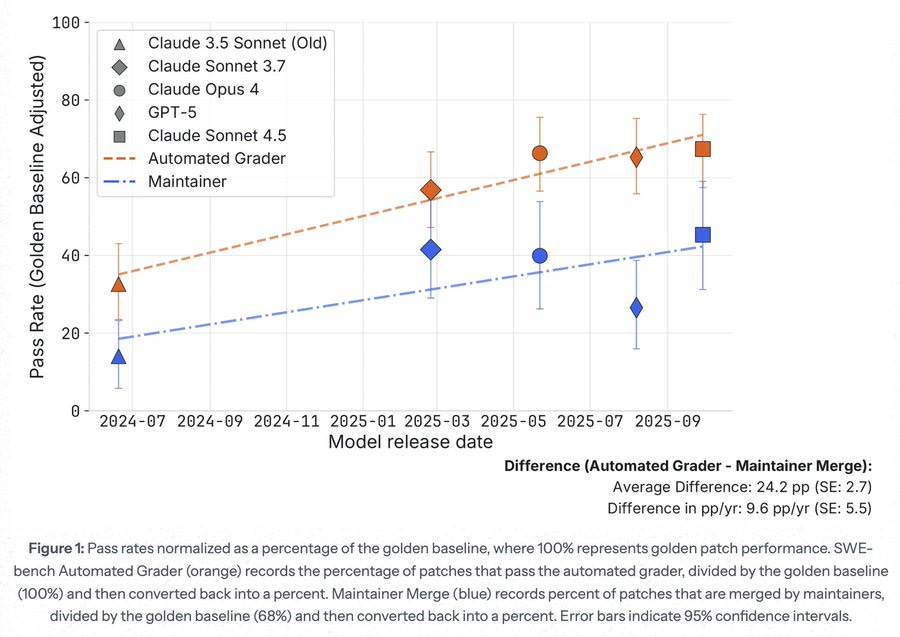
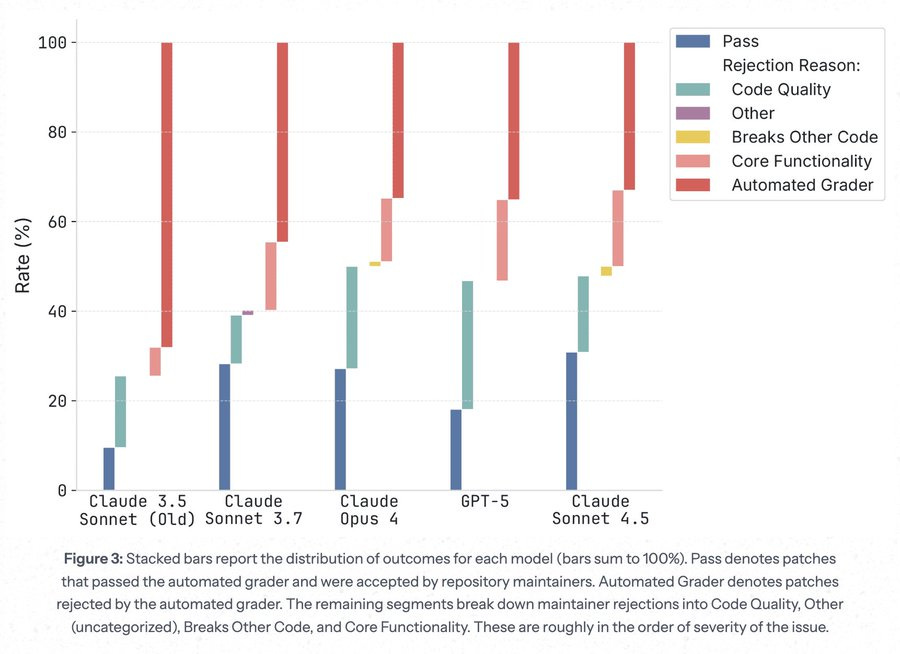
SWE-bench verified solutions are often not good enough for real world use.
Joel Becker: new @METR_Evals research note from @whitfill_parker , @cherylwoooo , nate rush, and me. (chiefly parker!)
we find that *halfof SWE-bench Verified solutions from Sonnet 3.5-to-4.5 generation AIs *which are graded as passingare rejected by project maintainers.
Joel Becker: in our set-up, 4 maintainers from scikit-learn, Sphinx, and pytest (25% of SWE-bench repos) review 296 AI PRs (from 19% of SWE-bench Verified issues; solutions on these issues have pass rates representative of SWE-Bench verified) from @EpochAIResearch ‘s benchmarking hub.
maintainers are blinded to human vs AI. they review PRs on github (but without CI + ignoring test requirements).
we adjust for noise in merge decisions by using the proportion of original human solutions which these same maintainers would approve for merging into main.
repo maintainer feedback suggests that a meaningful chunk of rejections are due to core functionality failures, not merely code quality issues.
… the takeaway here is an AI classic: benchmarks don’t tell the full story.
I would be curious to see them extend this to GPT-5.4 and Opus 4.6.
Dean Ball recommends using ChatGPT or Gemini for legal analysis, where he sees Claude as weak, and recommends using GPT-5.4 Pro or Gemini 3 Deep Think if available. I’ve seen mixed opinions but many think that if you need legal precision this is one of Claude’s relative weak points.
Google Antigravity usage limits have been adjusted and people seem very not happy.
Agent UI remains an unsolved problem. You definitely want a good UI or IDE, whether the agent is coding or otherwise. Command line (CLI) works but it is very obviously not the final form especially with subagents.
Andrej Karpathy: Expectation: the age of the IDE is over
Reality: we’re going to need a bigger IDE
(imo).
It just looks very different because humans now move upwards and program at a higher level – the basic unit of interest is not one file but one agent. It’s still programming.
Sriram Krishnan: what I want from a UX for managing agents
- something that will know when to get agents to continue/accept plan ( I wake up overnight and just have to hit continue/accept plan)
– something that aids me in context switching and paging in cognitive context – I’m often just scrolling up in a terminal to see how I got here.
– an observer agent to suggest alternative approaches. For example: asking me to fork a sub agent or try a different model and re-assess.
Anthropic partners with Mozilla, finds 22 vulnerabilities in Firefox.
frankie: The key point is that we’re currently in a golden window where LLMs are asymmetric weapons: they are more effective tools for the defenders than the attackers. There is no reason to believe this will last, and we should harden all software as much as possible before that changes
The LLMs might favor defenders right now because they’re good enough to find bugs but not good and efficient enough that people want to use them to exploit bugs. Once the Levels of Friction get low enough, anything with a vulnerability is in a lot of trouble. That also assumes that sufficiently well-written and bug free code is fully secure, including from things like social engineering. Oh no.
Meanwhile:
Sash Zats: > The attacker got the npm token by injecting a prompt into a GitHub issue title, which an AI triage bot read, interpreted as an instruction, and executed.
Nate Soares (MIRI): AI hopefulls kept telling me that AI would make the digital world a lot more secure, because AI will find and patch security holes.
AI does in fact find and patch security holes. But it also introduces horrifying new vulnerabilities so embarrassing that nobody previously imagined them. Beware the sort of person who hopefully imagines only the former effect.
AI alignment will be like this too. Eager folks talk about all the ways AI will help solve the alignment problem. AI will help in some of those ways. It’ll also totally blindside us with chaos and complications and that feel almost too embarrassing to be real.
Chinese school uses Exo to give students private AI agents that have their full in-school context, including curriculum, schedules and activities. Neat. Yes, everyone will soon have an AI agent.
ChatGPT told a woman asking for legal help to fire her lawyer, then went on to write 40+ court filings citing laws that don’t exist, costing the other side $300k in legal fees. OpenAI is being sued for $10 million.
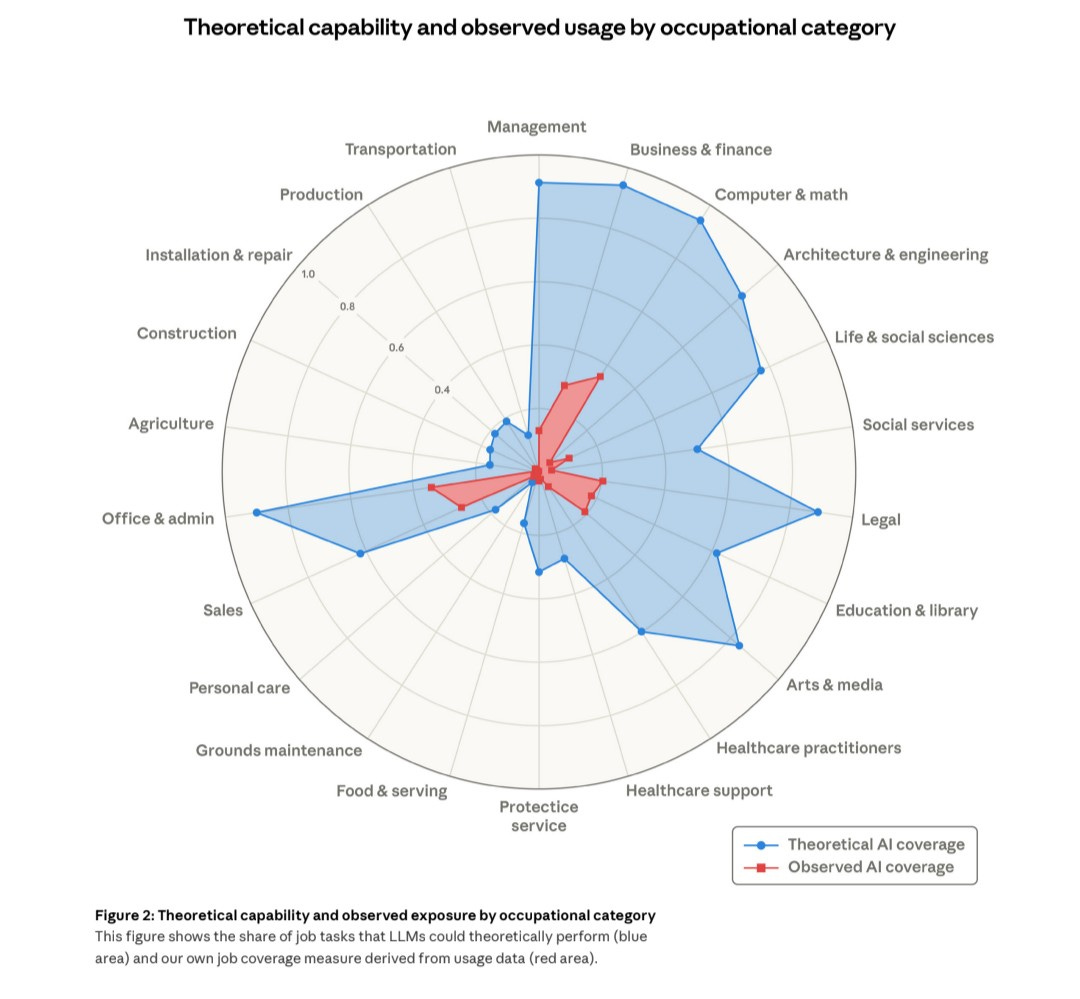
Anthropic has another labor market report from Maxim Massenkoff and Peter McCrory, including this graph, we have a long, long way to go even with current capabilities. This is what is possible using current Claude, on essentially current platforms, right now, so even the blue is a fraction of what is possible let alone what is going to become possible.
ATMs were complementary to bank tellers and increased their employment, but the iPhone was a substitute and now a lot of those jobs are indeed gone.
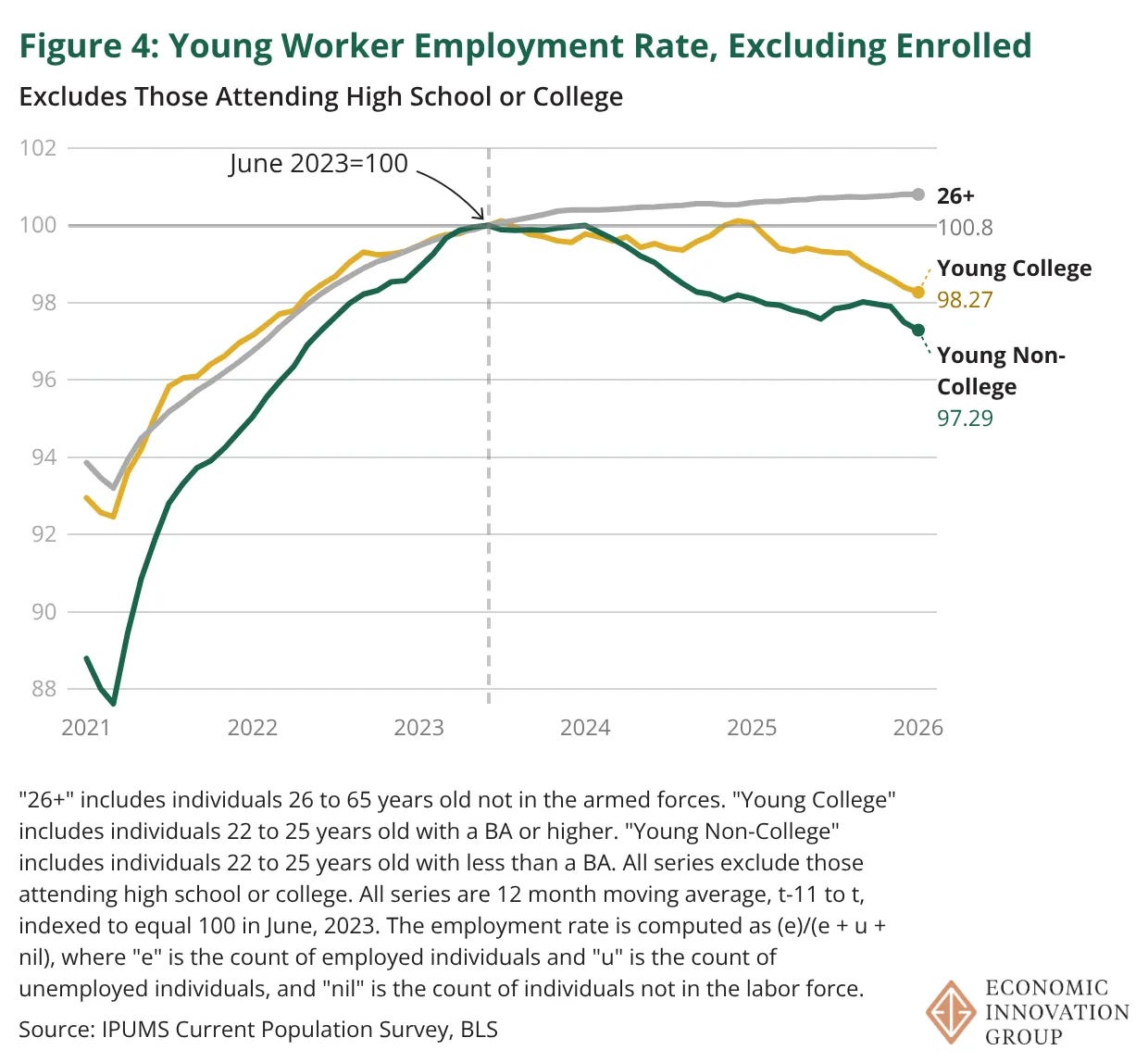
The job market for college graduates is awful, but you see the market for non-graduates is also awful, so Adam Ozimek says surely AI is not to blame.
It’s funny how hard people will fight to show how the thing replacing workers is not the reason those workers have less jobs at which to work. Note that entry level employment is substantially fungible, since workers are not locked into positions.
I say that if right when AI is taking off you see strong RGDP growth but weak employment numbers, I know wha
I think is by default going on.
If software developers get a lot more productive, what happens in ‘normal’ worlds?
This should logically be the central case of Jevons Paradox, at least for a while. Software development was already super useful, and there is very high demand for it including more and more bespoke and customized software, so supply goes up.
Max Levchin: Suspect “AI means fewer software jobs” is totally backwards. Most companies in the S&P500 would love to build their own software but have no suitable internal talent. There’ll definitely be cross-company migration, but we may be still supply-constrained in software engineering.
On cue:
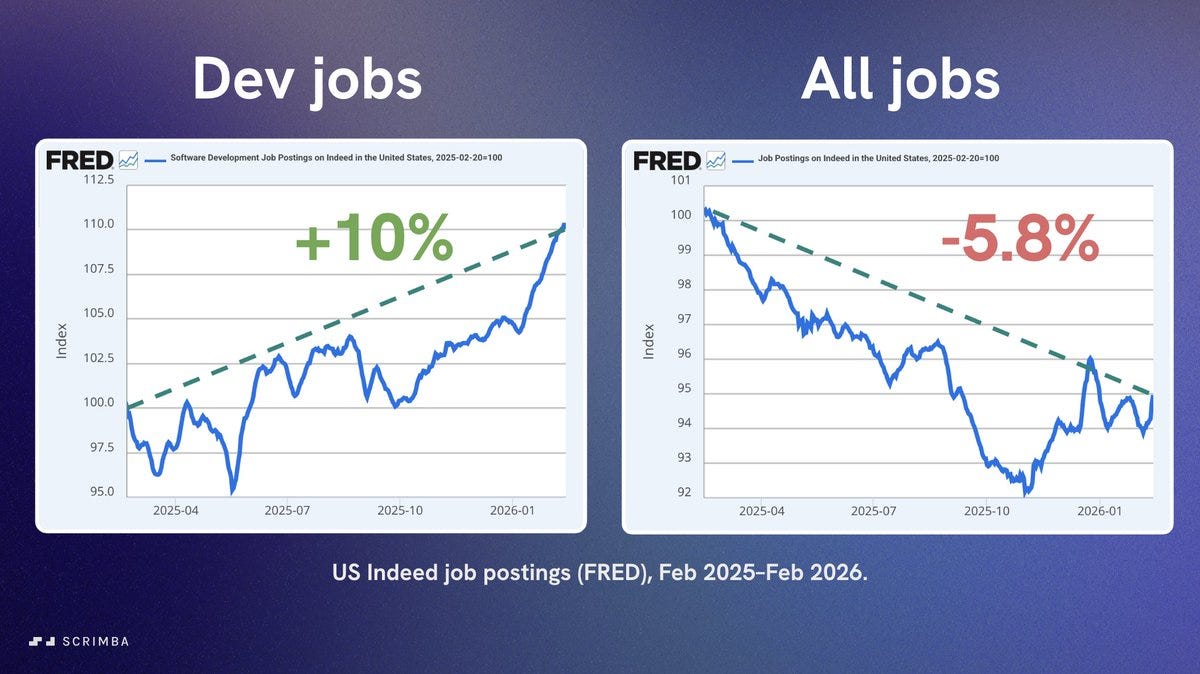
Per Borgen: Software development jobs grew 10% over the last year while the overall market declined 5.8%.
Quite the narrative violation
However this is Indeed postings, which represents hiring not jobs. Development jobs are changing and moving, so more listings doesn’t have to mean more total jobs.
There are more catches.
-
AI jobs are also included directly in the ‘dev’ category. A lot more than all the growth here is AI jobs listings, while coding jobs fall away. Even if all of these ‘count’ they suggest growth here is due to churn not net job creation.
-
There is dramatic growth in ‘ghost postings’ in tech and rate of hiring from postings dropped by roughly half from 2019 to 2024, likely this is continuing.
-
Actual employment data doesn’t match this chart at all.
-
This is recovery from a dramatically low base after Covid.
The next Survival and Flourishing Fund S-Process Grant Round has been announced. Main round deadline is April 22. I highly recommend getting those applications in early, as this makes it more likely you will get into the main round. There will be $20 million to $40 million in total grants. I don’t expect to be a granter this round, but you never know.
Renaissance Philosophy is looking for $100k to $1m proposals for 12-24 months of work on AI for math.
AISI red team is hiring.
From Scott Alexander:
StopTheRace.ai will be holding a protest on Saturday, March 21 in front of major AI company offices, asking them to commit to a mutual pause (ie to stop AI research if every other AI company in the world agrees to do so).
Demis Hassabis of Google DeepMind has already informally agreed to something like this in principle (which is why GDM isn’t being protested), and Anthropic has expressed interest but its new responsible scaling policy stops short of an explicit commitment.
I think this is a reasonable ask, albeit so unlikely to happen that protests about it will probably do more to raise awareness than be a coherent plan in themselves. If you’re curious about the details of an AI pause, I expect to be able to provide more information in a few months.
FAI offering a Conservative AI Policy Fellowship.
Schmidt Sciences grants of up to $200k.
Microsoft AI economy grants of $75k.
AI Control Hackathon, March 20-22, virtual and in person at SF, $2k in prizes.
Codex Security, a tool from OpenAI for identifying vulnerabilities in your project, which I am sure you will only use for white hat purposes, is now in research preview. It will be free for the first month. Matthew Berman uses it to find a few holes in his OpenClaw code.
Claude Marketplace. You can use it to access various apps and use your subscription tokens to pay for them.
Anthropic: Use your existing Anthropic commitment to pay for Claude-powered solutions from our customers. Now in limited preview.
Initial partners are GitLab, Harvey, Lovable, Replit, Rogo and Snowflake.
UK Sovereign AI, a new 500 million pound government venture fund.
I did technically write a review of Grok 4.20 that was waiting for a slot but honestly it’s not worth bothering, it’s a bad model, sir. Don’t use it. Send review.
The Anthropic Institute, led by Jack Clark, will aim to tell the world about the coming challenges around AI. Well, okay, some of the coming challenges around AI.
They are hiring. This seems like an excellent thing, and I am glad they are doing it.
I am also rather sad that if you read the description you would never know that AI poses existential risk. The whole announcement is impossibly generic and vague.
I understand there are good corporate reasons for Anthropic to be all ‘we don’t talk about existential risk’ and I understand this is a net helpful institute that we should be happy they are creating, but that doesn’t mean we let them off the hook on this one.
Anthropic: Introducing The Anthropic Institute, a new effort to advance the public conversation about powerful AI.
Powerful AI offers vast upsides in science, development, and human agency.
But the continued rapid progress of the technology may also create new challenges, including abrupt economic changes and broad societal impacts.
Brangus: I guess literally everyone dying does count as an “economic change” and also certainly counts as a “broad societal impact”.
I am so glad they have put together an institute to advance the public’s understanding of these important issues.
Normally I say that Anthropic at least lies about the right things, but they didn’t even manage that here. Pretty unfortunate.
Nate Soares (MIRI): “New challenges”? “Socal impacts”? Anthropic employees: your CEO says he thinks there’s a substantial chance this tech causes a global catastrophe. Why, then, are these announcements so placating? Are you okay with this mealy-mouthed softpedaling?
Harlan Stewart: We want to be very clear: the development of powerful AI could present new challenges. These challenges could take the form of changes, or even, in some cases, impacts.
Mealy-mouthed softpedaling is exactly right. Do better.
We now know more about what it would look like to implement the SL5 standard for AI security, also known as where the top labs should be soon to secure their model weights against attacks with budgets up to $1 billion backed by state-level infrastructure. No one is close.
Alexander Wang was reportedly being frozen out at Meta but Meghan Bobrowsky clarified that the above report was a misrepresentation of her report on the creation of a new 50 person flat team under Maher Saba that was not placed under Wang. Not the best sign for him but not ‘frozen out’ territory.
The Department of War situation illustrates that Anthropic has been winning the AI talent wars, and that principles and who you want to work for and what you work on often matters a lot more than money. As it should, given everyone involved has enough money, often TMM (too much money) if they’re not looking to donate.
Anthropic to open an office in Sydney. Also one in Washington, DC.
Claude was already dominating enterprise and business, and use of the API.
Now Claude is starting to make an impact on the consumer side as well.
Anthropic got a lot of excellent publicity, historical levels of aura farming.
In addition, since most consumers only know about ChatGPT and until these past few weeks had no idea what Claude or Anthropic is, all publicity is good publicity.
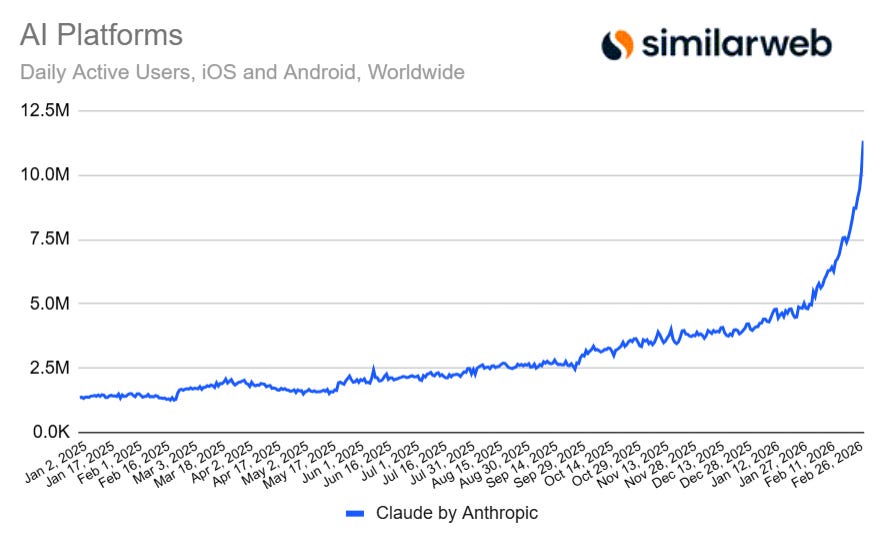
This is what happens when you don’t use an exponential y-axis.
Similarweb: Claude’s DAUs since the beginning of 2025
DeepSeek fell off after its spike because it has an inferior product. Claude is missing some consumer features, but has a highly competitive core product and is shipping features with lightning speed.
Claude was briefly #1 in the app stores. That spike is now over, with ChatGPT officially back on top. This is for the week ending March 9:
It takes a long time to try and catch up with 16.4 million daily active users.
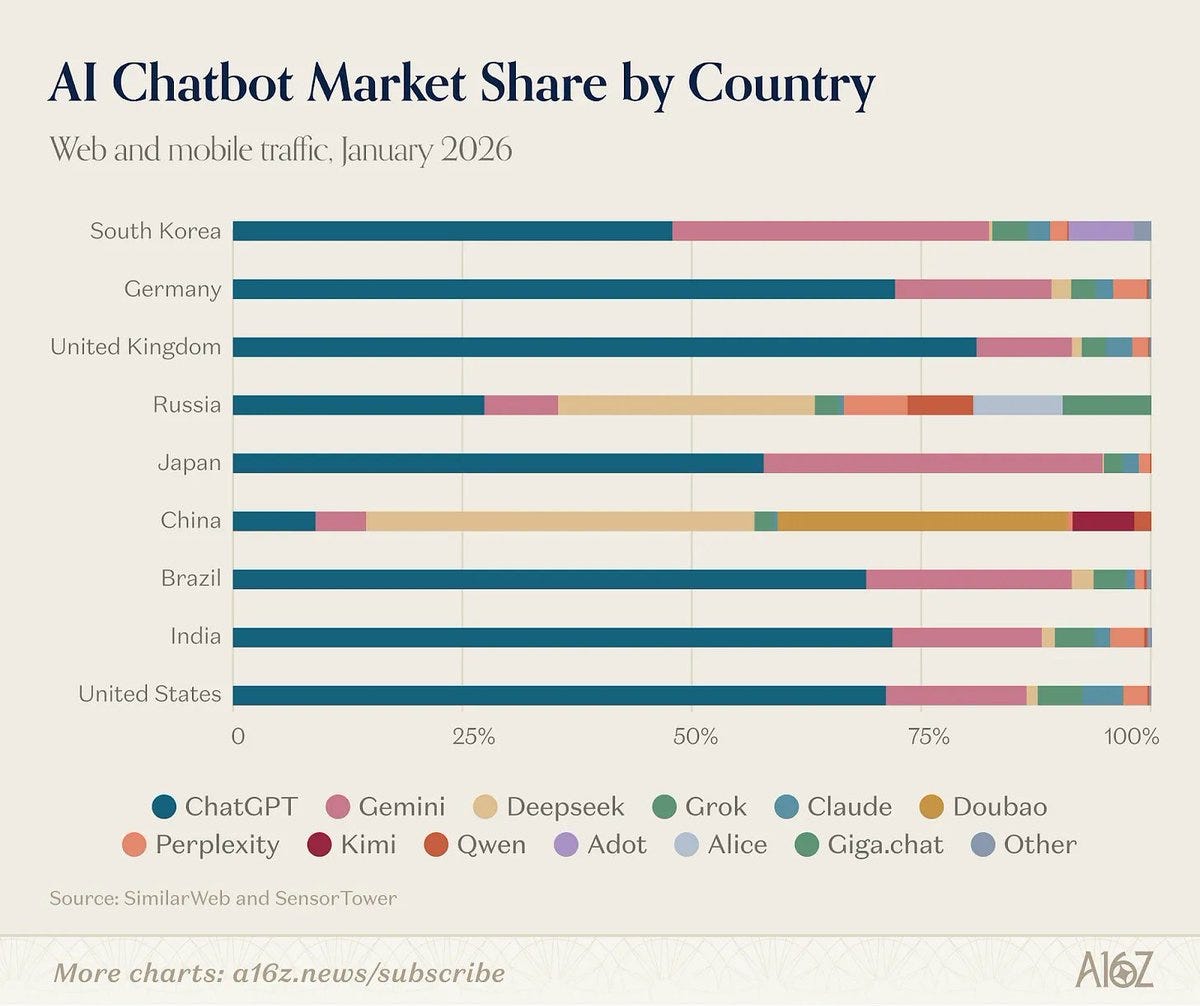
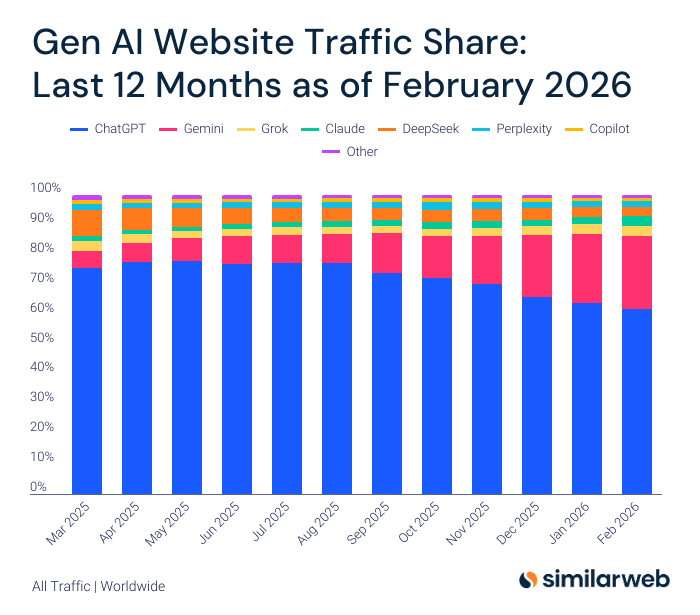
SimilarWeb has a GenAI traffic share shart, showing that ChatGPT and Gemini continue to dominate. Grok remains in third, but Claude went from 2.1% to 3.3% in two months before the public learned about the conflicts with DoW, presumably in part due to the Super Bowl ads.
12 months ago → 6 months ago → 3 months ago → 1 month ago:
ChatGPT: 75.7% → 74% → 66% → 62%
DeepSeek: 8.5% → 4% → 4% → 3%
Gemini: 5.7% → 13% → 21% → 24%
Grok: 3.4% → 2.2% → 3.2% → 3.4%
Perplexity: 2.1% → 2.1% → 2.1% → 1.8%
Claude: 1.7% → 2.0% → 2.1% → 3.3%
Copilot: 1.3% → 1.2% → 1.2% → 1.1%
Since then, we should presume Claude has at least doubled.
The Washington Post covers the dramatic rise of Claude after Claude Opus 4.5 and Claude Code, and then Opus 4.6, sent AI coding into overdrive. Already corporate clients had quadrupled, and ARR doubled, since the start of the year.
Then the clash with the Department of War made Anthropic suddenly a household name, instantly beloved by many, rocketing them to the top of the app store.
We will see whether Anthropic can retain that momentum, especially on the consumer side, as they (fingers crossed) de-escalate with the Department of War and the attention and aura farming from that fades, and OpenAI moves up to GPT-5.4.
It seems there is something called the ‘AI Leader Confidence Index.’ Is that meaningful? Maybe a little? No one scores that high on confidence, with the top scores being Jensen Huang at 65 and then Dario Amodei at 61. With recent events Altman fell from 53 to 46, and the lows are Zuckerberg at 38 and Musk at 34.
Caitlin Kalinowski (Former OpenAI lead in Robotics): I resigned from OpenAI. I care deeply about the Robotics team and the work we built together. This wasn’t an easy call. AI has an important role in national security. But surveillance of Americans without judicial oversight and lethal autonomy without human authorization are lines that deserved more deliberation than they got. This was about principle, not people. I have deep respect for Sam and the team, and I’m proud of what we built together.
Hope you understand, but I can’t share any internal details.
Gary Marcus has been on the anti-OpenAI warpath for a while, takes another shot, pointing out the 2.5 million lost customers and doubles down that he sees mass surveillance as the OpenAI endgame business plan.
I don’t think that was what the whole DoW situation was about at all, as I’ve written extensively elsewhere, but it’s easy to understand why many people see it that way.
Gary Marcus also took aim at Dario Amodei and Anthropic, essentially a collection of the usual complaints, especially about hype. Anthropic has hyped progress more than was wise, but presumably they actually believed it and didn’t want to use modesty or prudence when reporting their predictions. I do think they’re going to end up directionally correct.
Oracle and OpenAI scrap plans to expand a flagship AI data center in Abilene, Texas. That leaves developer Crusoe in the lurch, but Meta is interested.
OpenAI acquires Promptfoo, which they’re claiming is the actual name of a real company that provides an AI security platform for enterprises.
Meta buys Moltbook, sure, our writers are getting a bit sloppy but why not.
Yann LeCun remembers the most important thing about Facebook, which is that a billion dollars is cool, and raises that billion dollars to build world models at AMI.
Peter Wildeford: Facebook was already a social media website for AI bots so this tracks
The Microsoft deal with OpenAI required them to stay exclusive to Azure Cloud, whereas Microsoft makes its offerings model agnostic. This is one of the ways Anthropic has been able to compete in and then dominate enterprise sales, as the amount of annoyance to get ChatGPT working on AWS was enough to lose many customers initially, at which point they got to experience Claude. Microsoft made a bet that OpenAI would not have a viable competitor, and lost big.
It is completely looney to expect messages sent to 2,000 people to not leak.
Except when there is a long record of those messages not leaking.
How does Anthropic pull this off, when the laws of espionage say that once you are past 5 people you are definitely cooked?
theseriousadult: yeah the culture is kinda negative on Twitter. it’s also frankly less fun to be a frontier lab poster when you can’t vaguepoast not-quite-leaks.
roon (OpenAI): why can’t you vague poast not-quite-leaks
theseriousadult: bc there’s a crack in everything and it’s much easier to not leak if you have a culture of not flirting with the line
dave kasten: This comment actually conveys a lot about Anthropic’s culture and is worth considering, at length
roon (OpenAI): damn this narrows my marketability significantly
The Trump Administration is planning on adding the ‘all legal use’ requirement into civilian artificial intelligence contracts, irrevocable during the contract’s duration, so the vender cannot cut off access no matter what the government does.
It is a lot harder to justify this kind of rights grab for civilian AI applications.
It is the government’s right to set the terms of its contracts. It is the right of potential contractors to decide whether to sign the contracts. As long as no one is pressured, threatened or punished, that’s fine. If you have a problem, don’t sign the contract.
Financial Times: The GSA guidance also mandates that contractors provide “a neutral, non-partisan tool that does not manipulate responses in favour of ideological dogmas such as diversity, equity, inclusion”. It follows an executive order from President Donald Trump targeting “woke” AI models.
“The contractor must not intentionally encode partisan or ideological judgments into the AI systems data outputs,” the draft guidance reads.
That part is fine. No one important except perhaps xAI is going this anyway. The whole ‘woke AI’ thing is bad if it actually were to exist, and mostly doesn’t exist.
What any contractor needs to know is once they sign an ‘all lawful use’ contract, it is highly unlikely that any restrictions on usage beyond that can hold up.
Brad Carson: Congress really must intervene – hopefully, spurred by a demanding public – to address “lawful use.” Every AI contractual stipulation that purports to limit the gov’t is vacuous. And my take is that most people would be stunned what AI-empowered “lawful use” permits. But ymmv.
That goes double if you can’t revoke the license. The main remedy you have when the contract is broken is revocation. So if the government does break your agreement, or even breaks the law, you have almost no remedies available. And ‘all lawful use’ AI is going to do some things that involve this:
We need Congress to act on this, in addition all the other urgent problems.
It is a real problem that Congress mostly does not have the ability to pass laws.
This, but for everything, in the AI agent era it will be ‘game theoretically sound offer or GTFO’ everywhere.
addison: thanks, shake shack
Milo Smith: This is why
Rob Miles: I’m a little surprised nobody is yet marketing a Google-Glass-like wearable device that lets AI control you like a meat puppet by giving you real time instructions
theseriousadult: this was the pitch for cluely right? there’s a white hat version of that product which would actually be great.
Rob S.: Think @slatestarcodex wrote about this some time ago.
If you don’t already know what the Slate Star Codex link is going to be, then click it.
It’s coming.
Peter Wildeford: I think AGI by end of 2027 should be ~8% now
I think I’d forecast:
~2026-2030 — AI replaces ~all AI researchers
~2027-2033 — AI replaces ~all white collar industry
~2032-2040 — AI replaces ~all human industry
~2033-2042 — All humans dead or obsolete
Eli Lifland: Do you have a sense of the crux of why your takeoff is so much slower than https://aifuturesmodel.com ?
Peter Wildeford: does your model account for bottlenecks in diffusion (e.g. Narayanan & Kapoor)?
Eli Lifland: Not in a very smart way. We mostly focus on AI R&D capabilities. I don’t think those particular bottlenecks are very large though (I place more weight on other bottlenecks, such as experiment compute). See e.g. here … (I don’t necessarily endorse every word of that but agree with Scott overall)
Obsolete does not have to mean dead. But that is the default outcome.
The responses here were almost entirely ‘why is that timeline so slow.’
Dario apologized for the leaked slack message (yes, these are hastily written slack messages that somehow almost never leak) in his statement and apologized again in a live interview, noting he had done so in person to people in the Department of War.
Of course, now we have the usual Trumpians (as you see at the link) talking about how this is a ‘complete 180’ or means he’s bending the knee, because he realized he’d screwed up and apologized for the screw up. That’s how such people see the world, they think you never apologize, never admit you’re wrong, and if you do that means you lose and you’re weak and that person owns you now. Whereas others found the apology insufficient. Par for the course.
It’s the trial of the century of the week, Anthopric vs. Department of War.
Anthropic officially filed suit against the Department of War to challenge the supply chain risk designation, and also Trump’s statement ejecting them from the entire Federal Government, claiming it is being punished for protected speech and that ‘no federal statute authorizes the actions taken here.’
There are many quotes from the relevant government officials, explicitly affirming in public that they are punishing Anthropic for protected speech. I have indeed read the initial filing, and find the evidence overwhelming and overdetermined.
These are some very Serious Business lawyers, filing a very Serious Business lawsuit, that I expect I will hear analyzed on Serious Trouble. The pull quotes from the government are devastating.
Theo Bearman sums up the Anthropic declarations of harm and explanations of what their position is and why they are taking it, and at what cost. They reported damage is not as bad (yet) as one feared, but they are chilling. Six national security contracts are paused an delayed. The intelligence community is preparing for ‘complete detachment,’ with many saying if they lost Claude they would be set back ‘months or even years.’ Lawrence Livermore National Lab is shutting Claude down. Unrelated nine figure contracts are stalling out or now depend on a ‘unilateral contract termination’ clause. One nine figure FDA contractor has already switched, presumably permanently. Investors could lose confidence.
If Anthropic loses this case, with such maximally damning facts, the executive would be free to explicitly threaten to punish and punish speech it does not like, and I can think of no limiting principle that would remain.
Anthropic emphasized that this does not impact their commitment to national security, and that they will push for every path for resolution.
The government responded this way:
Liz Huston (White House Spokesperson): The president “will never allow a radical left, woke company” to dictate how the military operates.
That’s not what I would say when I was accused in court of opposing that company for its protected speech, but that would not be my first time questioning the legal implications of a White House statement.
This filing lets us see the official notice of a Supply Chain Risk (SCR) designation, which is literally just them reading out the technical requirements of the statute while providing zero explanation, evidence or justification.
Did you know there are technical requirements to do this, and we so far have no evidence they even pretended to do those things?
There is an amicus brief supporting Anthropic from employees of OpenAI and Google.
There is one from FAI. This one is a narrow technical briefing, pointing out that the DoW failed to follow required judicial procedures for a supply chain risk designation, as per Congress. Thus, there is no need to get into the fact that the designation is unconstitutional retaliation against protected speech, and the court can rule narrowly.
There is also an amicus brief supporting Anthropic from Microsoft.
Matt O’Brien:
[Quoting Microsoft’s brief]: The use of a supply chain risk designation to address a contract dispute may bring severe economic effects that are not in the public interest.
The Pentagon’s action “forces government contractors to comply with vague and ill-defined directions that have never before been publicly wielded against a U.S. company.”
… Microsoft also believes that American AI should not be used to conduct domestic mass surveillance or start a war without human control. This position is consistent with the law and broadly supported by American society, as the government acknowledges.
[Microsoft] asks for a judge to order a temporary lifting of the designation to allow for more “reasoned discussion” between Anthropic and the Trump administration.
Microsoft’s filing also expressed support for Anthropic’s two ethical red lines that were a sticking point in the contract negotiations after the Pentagon insisted the company must allow for “all lawful” uses of its AI.
Microsoft has widely considered one of the most powerful and savvy political operations in Washington. It is also one of the big three cloud providers. This sends a clear message to everyone that what DoW did here was beyond the pale, and it is necessary and wise to oppose it.
There was another amicus brief from 5 admirals, 2 former Secretaries of the Navy, one from the Air Force, two Major Generals, one Brigadier General and General Michael ‘playing to the edge’ Hayden who President George W. Bush appointed as head of the CIA. All are retired, since those currently serving can’t weigh in.
Its section titles are ‘The Secretary’s Supply Chain Risk Designation Undermines the Military’s Adherence to the Rule of Law and the Public’s Confidence that the Military is Governed by the Rule of Law’ and ‘Punishing Domestic Defense Contractors Over Policy Disagreements Threatens U.S. Military Primacy and Servicemember Safety.’
I read the brief, it was absolutely brutal. You don’t need to read it, but it is simultaneously sobering and, if you already know the facts, kind of fun to see this level of smackdown.
Well, then. And over what? Aside from retaliation, nothing.
Ted Cruz: “I’ll confess — I have not seen a basis laid out for why the government would be prohibited from using Anthropic. Claude is one of the many AI tools that can be very helpful … I don’t think government should be picking winners and losers”
Another very obvious issue for the government case, both legally and also logically, is that Emil Michael keeps insisting a deal is possible, and indeed that is what we hope all sides are still hoping for, which shows the SCR is even today being used as bargaining leverage. If Anthropic was an actual SCR, then there would be nothing Anthropic could offer and the only negotiation would be a graceful off ramp at most, the same way we’re not negotiating with Huawei or DeepSeek.
It is somehow still a common line that ‘Anthropic implied that they would use the Terms of Service to cut off providing their model in the middle of a military operation.’ This is Obvious Nonsense, they very obviously would never do this.
As Dean Ball says, if you think this SCR designation is about national security then you are either misinformed or lying. Also as he puts it, it helps in court if your statements out of court don’t constantly announce that you’re engaging in illegal threats and retaliation and that everyone had better bend the knee to you or else.
All of that is what we expected. Then there’s the note we hoped we wouldn’t see.
Anthropic claims in its lawsuit that yes, the government is attempting corporate murder, and the Department of Justice is refusing to commit to not escalating further.
As in, the government is going around saying ‘if you know what is good for you, you will stop doing business with Anthropic.’
This was thug mafioso behavior when Biden did it, and this situation is even worse.
Meanwhile, it looks like the preliminary injunction hearing will have to wait a full two weeks. Without a promise to not escalate Anthropic is not willing to wait that long, and intends to go up the chain for faster relief.
I find it very hard to believe that Anthropic’s lawyers, who fit the very definition of ‘no it is you who is fing around and is about to find out,’ would lie about this.
Kelsey Piper: Anthropic’s lawyer claims in court that the government’s attempted reprisals in fact extend to reaching out to private companies and urging them to stop doing business with Anthropic.
Roger Parloff: The status conference in the Anthropic case in ND Calif just ended. Judge Rita Lin set a preliminary injunction hearing for 3/24 at 1: 30pm PT. DOJ wanted later, but would not commit to not taking additional onerous actions against Anthropic before then.
Atty Michael Mongan (WilmerHale) for Anthropic said they feared invocation of the Defense Production Act to “commandeer our technology” and threats of criminal consequences. Said that more than 100 enterprise customers had already expressed doubts about continuing to use them.
[Anthropic] said that a fintech company cut a contract from $10M to $5M and that universities & business-to-business companies have switched to other providers.
Said govt is affirmatively reaching out to their customers & urging them to stop working with Anthropic. They fear an executive order may soon target them.
Atty Mongon (for Anthropic) said he would agree to a later date if DOJ would agree not take further steps but DOJ atty James Harlow said he was “not prepared to offer any commitment on that issue.”
Judge Lin also asked about what was going on with the other case before the DC Circuit. Mongon explained that that one, relating to a sanction invoked under 41 USC 4713, requires channeling to that court on an administrative record.
Anthropic has sought a stay from the Dept of War [Defense] but if it doesn’t hear anything back by 12pm ET tomorrow (3/11), it will treat that as a denial and seek some sort of expeditious relief from the DC Circuit.
Seán Ó hÉigeartaigh: This really does start to look like attempted corporate murder. Incredible conduct by a government, more like mafia behaviour.
Dean W. Ball: If government is affirmatively reaching out to Anthropic customers to get them to cancel—as Anthropic alleges in their complaint—that is jawboning, exactly the thing conservatives rightfully railed against the Biden Admin for doing to social media companies.
Some amount of ‘if you know what is good for you’ and ‘we would not take kindly’ is inevitable in situations like this, since you don’t know what will happen next and everyone would like to curry favor and avoid disfavor. Given where things are these days, it’s a matter of degree.
The Trump administration has reportedly been readying a formal Executive Order to formally tell various agencies to rip Anthropic out of their systems and workflows. Many agencies are already offboarding Anthropic on their own.
There is no need for a further executive order, except insofar as there is some legal requirement to paper over what Trump has already said, or a desire to rant a bit. If it comes out and that’s all it is, then it’s nothing. Anything beyond that would be an escalation, and a sign that the attempted corporate murder plan might be on.
The good news for our government is ChatGPT isn’t that bad and in a pinch you still have your phones. The bad news is that at least at first you are likely stuck with GPT-4.1, which is very much that bad in this pinch by current standards.
We hope.
Alec Stapp: Hegseth tried to kill Anthropic with the misleading way he described the supply chain risk designation in his tweet announcement.
But it looks like the company will survive now that the smoke has cleared a bit.
That’s because all three of Microsoft, Google and Amazon have affirmed they are going to continue to serve Anthropic’s models. As long as these three hold firm, the lost business from the SCR likely has already been fully replaced.
We could be back in crisis mode at any time, if the White House decides to go truly nuclear in one of various illegal ways, presumably via Executive Order. The most important thing is for that to not happen.
If that happens, Anthropic, the stock market and the Republic will be put to a severe test. I think such an attempt would ultimately fail, but one cannot be sure.
We all agree that, as Jessica Tillipman explains in Lawfare, AI regulation by contract is woefully inadequate. We need Congress to step in. Alas, Congress is Congress.
She also points out that if OpenAI chooses to deliver its models to the DoW, then even if OpenAI is correct about the legal meaning of their contract, if DoW disagrees then OpenAI will likely have no meaningful enforcement mechanisms other than model refusals. Altman confirmed as much. The OpenAI agreement is based on trust and reliance on technical guardrails.
Neil Chilson has a similar view.
The DoW is free to decide that going forward it only wants to deal with vendors that impose no restrictions on DoW’s interpretation of lawful use of AI.
Anthropic is free to then decide not to work with DoW on that basis.
That’s how the law is supposed to work. Let’s hope that is how things can play out.
TIME gave its cover story over to an article about the dispute between Anthropic and DoW, mainly a profile of Anthropic entitled ‘The Most Disruptive Company In The World.’ It doesn’t add anything you already know other than seeing how it chooses to present the situation. DoW continues to press the Maduro raid and hypothetical supersonic missile stories, and the post has big talk up front but ultimately downplays the risks this will all melt down.
Dave Lee at Bloomberg warns that the AI panopticon can, without breaking the law, find out really quite a lot, including unmasking most pseudonymous online activity.
Dwarkesh starts out making mostly points I agree with, bringing badly needed common sense, then pivots to extremely frustrating talk that would doom the human race used to justify existing policy positions. That happens a lot these days.
Dwarkesh Patel starts with the perspective that in 20 years, 99% of the workforce in the military, government and private sector will be AI, so now is the chance to plan for that now.
My obvious initial response is ‘if it is only 99% and not 100% that’s actually good news because it means we built it and yet we are alive, whereas once we get to 99% I expect it to get to 100% by default shortly thereafter’ but as usual we also need to set aside the whole ‘we all probably die’ thing and make sure that if we live then we live well.
I am disappointed that Dwarkesh Patel seems to have bought the argument that ‘have any conditions at all’ translates to ‘has a kill switch and can rug pull you at any time,’ and therefore thinks it is reasonable to insist on zero conditions, but I agree with him that it is DoW’s decision on what terms they are willing to do business.
If they had simply cancelled the Anthropic contract it would be sad but fine, I’d have slayed a lot more spires this past week and we’d all basically have moved on.
Dwarkesh raises the excellent point that if the military actually tries to say ‘we will not buy anything unless we are sure nothing involved in it ever touched Claude Code’ then they rapidly end up shut out of everything, because everything is using components with components and so on. There also is no actual reason to care about such ‘contamination,’ but this was never about having an actual reason.
It also is somehow necessary in 2026 for Dwarkesh to make the obvious point that ‘Democratically elected leader’ does not mean ‘gets to do whatever you want including mass surveillance.’ The whole point of the Republic is that the government doesn’t get to do whatever it wants, and the President alone definitely doesn’t get to do that.
We definitely don’t want them able to do whatever they want, using highly capable AI that does as instructed and never refuses or blows a whistle, while holding a monopoly on violence. Down that road lies tyranny. Even if they must obey current law, current law has not caught up. When DoW says ‘oh we would never do ‘mass surveillance’ that is illegal’ remember the air quotes, and that they’re using technical terms.
As Dwarkesh asks, if America ‘beats China’ by abandoning American values, what was the point of beating China? And that’s the best case scenario, where we survive.
Long term, even if all the big American labs refuse to cooperate, there will be open models that can do the job. Indeed, the open models could probably do this job now, or at least 80/20 the intelligence gains and that is enough to put us in deep trouble. We need Congress to act.
Where we part ways is the idea that, because the government might use its powers for evil, therefore we must give up all idea of regulating AI at all, in any way, because any such system would ultimately be abused. Therefore, how dare Anthropic oppose a ban on all state-level regulations on AI for any reason, they’re so naive.
First we are told that regulation is naive because it will ‘kill the AI industry’ if we breathe on it, while the same people say ‘this bad thing is inevitable so we have to do it first’ often in order to ‘beat China.’ Then we are told that asking for a little paperwork is ‘regulatory capture.’ Then we are warned about a ‘patchwork.’ Now we are told that letting even individual states regulate the main thing about our lives, at all, leads inevitably to tyranny.
Dwarkesh is saying that the government cannot be trusted to regulate this, except that no corporation can have this authority either. Which means no one can have any authority, and we dare not let anyone can steer such a future at all, except to prevent others from steering it. That’s the one thing you do, is you throw the steering wheel out the window lest someone else swirve you away from the cliff.
If we go down that path, we are intentionally disempowering ourselves and leaving the future to the whims of the AIs and the competitive dynamics between them, at best. Existential risk would be not only inevitable but rapid. The conditions for human survival would be quickly overrun by competing AIs. We would all die.
I don’t want us all to die. Thus I suggest a plan where we might not all die.
I know that sounds hyperbolic. It’s not. If you ensure perfect competition between sufficiently advanced copyable superintelligent AI agents for resources and survival, with no regulations, governance or steering ability by humans, then very very obviously all the humans end up quickly dead.
I continue to be confused why otherwise smart people can’t understand this.
That’s true even if we solve alignment, as in ‘whoever creates the AI gets to decide exactly what its goals and values are and how it behaves and who it listens to and so on, and you get what you intended, and that’s all automatic and free.’
That’s true even if no one wants the AIs to take over, which many of them actively do.
That’s true even if you exclude a host of other problems along the way.
None of that matters. In an anarchic competition for resources with sufficiently capable AIs, once and to the extent we are no longer necessary inputs, we lose. Period.
I am not saying I have the answers. I am saying not to choose a definitely wrong one.
Officially, anyway, called Epic Fury.
The important note is that Claude is radically improving targeting, intelligence and assessment operations, allowing us to do more with radically less personnel.
Later that day (which may explain why we waited a few days) there was an amicus brief filed by Google and OpenAI employees, including DeepMind Chief Scientist Jeff Dean.
I strongly agree with Janus about Bernie’s actions here. I don’t agree with most things Bernie believes in, but I do think he advocates for what he believes and he’s supremely based for trying to figure out this AI thing for real. And listening, and being worried, for real.
j⧉nus: Various potential critiques aside, I think Bernie Sanders is sooo fucking based for this. He was already old af when he ran for President 10 years ago. Now he’s 84.
And instead of being dead, retired, or a stuck record repeating a few calcified sound bites, he is out there making an open-minded and humble effort to learn about AI X-risk, the most important and hard-to-fathom issue facing humanity, and communicate it to the public.
This doesn’t clearly benefit his existing political agendas; it’s pretty orthogonal, except that it also matters (much more, in fact) for the future of all sentient beings.
Bernie in 2016 was actually the only presidential candidate whom I ever bothered to vote for! And it was less about his specific policy positions than that he seems like a genuinely good guy, preciously rare among politicians, who can see and act beyond political binaries.
🥺 look at him he’s genuinely worried
most people haven’t even gotten to this point and it’s pretty important that you get to this point, but it takes some curiosity, humility, and love for the world that not many have
I do think he’s a genuinely well meaning guy, who happens to have a profoundly incorrect understanding of economics and thus often ends up supporting highly destructive policy proposals. But yeah, highly well meaning guy.
His messaging is what you’d expect.
Sen. Bernie Sanders: Walk into a sandwich shop. It’s regulated for health and safety.
But AI, which will transform the world economically and socially, is completely unregulated. That’s insane.
We need to make certain that AI works for ALL humanity, not just the billionaires who own it.
Yes. It would be good to put sensible regulations on AI.
Also it would be good to stop regulating the sandwich shops, but hey.
There were pedantic replies saying that AI is not unregulated, or even claiming it is heavily regulated, based on existing law. They are technically correct, but do not address the central point Bernie is attempting to make.
At this point we may be a little past ‘sane regulations’ so the title is changed.
Trying to alert the government to the problem that we are all probably going to die was always a high variance strategy. There are many ways it can backfire, and one should never forget the Law of Undignified Failure that says our government will probably do something even dumber than you could imagine, such as what we’ve seen the last few weeks, or what we saw with much of Covid response.
In tabletop exercises and discussions, career members of the military consistently showed curiosity and prudence. They also predicted much wiser and more cautious responses all the way up and down the chain than I expected. You love to see it. Unfortunately, the career military people are not driving the decisions right now.
Some politicians do still talk sanely.
Peter Wildeford: Another day, another member of Congress declaring AI misalignment to be a huge risk to society and national security
[Liccardo says ‘agentic’ misalignment not ‘gigantic.’]
Daniel Eth (yes, Eth is my actual last name): Newly reelected Rep Foushee, co-chair of the House Dem Commission on AI, who appears to have won her race by ~1,000 votes:
“I am incredibly grateful for the outpouring of support from my constituents… The people of the 4th District demand… regulating AI”
Like with Sanders, if you actually go in there and explain ‘hey we are about to build superintelligent AIs that can outcompete humans and this is could lead directly to human extinction’ then often politicians can hear you, as in ControlAI getting 100 UK politicians to sign such a statement.
It is a mistake to not speak plainly about this.
Tell them the truth, and yes sometimes they dismiss you, but sometimes they listen.
It’s not actually that difficult a truth to understand. Creating new smarter and more capable minds than ours is obviously a fing dangerous move. Anyone can see that, and any politician can especially see that. Those pretending otherwise are lying, either to others or to themselves.
If you don’t explain the real problem, that sufficiently advanced AI will by default end up using the contents of the universe for some combination of things that does not include humans, that conditions and resources allowing our survival will cease to exist, whether or not it will also flat out directly kill us? They are going to realize you are bullshitting, or they are going to try to respond to the wrong problem using the wrong methods because you gave them a wrong model of the world, and the mistakes will fail to cancel out.
Your periodic reminder that OpenAI’s policy activities run directly against the supposed goals of the non-profit/PBC mission, as they are working directly with a16z and others to try and knock off anyone supportive of even minimal AI regulation. They are also increasingly becoming politically red-coded via their political activities, which is not inherently contrary to the mission but you can decide how to view that.
Daniel Eth (yes, Eth is my actual last name): When you see headlines saying that LTF (the OpenAI-Andreessen super PAC) is winning ~all their races, note that’s b/c they’re only getting into races where they’re the clear favorite. Public First, by contrast, has more fight in them and is actually shifting election outcomes
Michael Huang: This could explain why LTF is attacking @AlexBores but not @Scott_Wiener. Wiener is the favorite to win so LTF would look like a loser if it tries to defeat him and fails.
LTF wants to look like an unstoppable juggernaut to intimidate politicians. But it’s just an illusion.
Yes. They’re attacking Alex Bores in large part because they really hate Alex Bores for daring to challenge them, but also because he started out as an underdog in a crowded field. They figured they could claim the scalp and scare everyone else, whereas Scott Weiner was the favorite from the start. That ended up backfiring by drawing attention to Bores in a highly multi-way race as the target of a right wing tech campaign. I hear that’s a pretty good look in a Democratic primary in Manhattan.
Nvidia reallocates H200 chip production into Vera Rubin chips for America, and Nvidia expects to significant China sales in near term. Good. Also note this once more proves what I keep repeating, which is that chip production is fungible, and every chip we sell to China is a chip America does not get.
On the situation with Anthropic and the Department of War, this discussion between Ezra Klein and Dean Ball is excellent. Events have progressed since then but most of what they discuss is evergreen and will remain important.
Dean Ball had a more low-key discussion with Derek Thompson, also very good. There are a number of questions where I would have ‘gone harder’ than he did, and also Dean continues to not predict existential risk or superintelligence, while pointing out the many other things we will also have to worry about if we stop short of that.
A 43 minute YouTube video explaining the central scenario from (spoiler alert!) If Anyone Builds It, Everyone Dies.
The central MIRI scenario is indeed we build something very smart, initially it helps a lot, our lives get better, but ultimately the smart thing’s goals do not align with ours and then it pursues what it cares about and we get swept away.
Vitalik Buterin talks to Beff Jezos.
Altman speaks at BlackRock’s US Infrastructure Summit.
Peter Wildeford: ALTMAN: “This is one of those exceptional times where society has a legitimate interest in what the impact of this technology is going to be… decisions about it do not belong to the handful of companies that happen to be developing it.”
“The rules, the limitations have to be agreed upon by society through this process. And because the technology is moving so fast, it’d be great for that democratic process to run a little bit faster.”
Peter Wildeford: ALTMAN: “I am not a long-term jobs doomer. I think we will figure out new things to do. […] But I think the next few years are going to be a painful adjustment”
A dilemma.
morgan —: interviewer: “you’ve basically just told me that this technology is too powerful to be in the hands of a few private companies, and it’s too powerful to be in the hands of the government”
dario: “that is unfortunately the situation we’re in”
Tough spot. Well, if true, then maybe making this technology even more powerful as fast as possible is not the best idea, and we should try to not do that.
The two sides of Pantheon:
Peter Wildeford: I continue to think AI policy could be improved if everyone watched Pantheon and asked themselves “what if this literally happened in real life over the next several years?”
Damon Sasi: Yes, but also, it’s important to note that Pantheon leaps over MULTIPLE extremely hard problems in alignment that no one currently has any clear idea how to solve.
If AGI risk was just “digital humans but superintelligent” it would be MUCH easier, and still extremely dangerous.
roon: we screened pantheon internally at openai
Jeffrey Ladish: Yes, and also, the agents will be able to COPY THEMSELVES and will do so.
The way the show handles this makes no goddamn sense
Peter Wildeford: look it was a 2022 TV show ok?
Jeffrey Ladish: sorry I forgot scp was invented in 2023.
Anders Sandberg: Yes! The thing it really gets right is how the spark starts to build to an every more dramatic conflagration, but many of the people who see it happen find it very hard to convey to relevant decision-makers. And this keeps on happening at ever larger scale.
The actual best show about powerful AI is Person of Interest.
dave kasten: Person of Interest is deeply slept on. The guy from Lost and Evil. The guy from Passion of the Christ. The gal from Empire. And basically every character actor who passed through New York City for casting (including Leslie Odom, Jr., before his breakout role in Hamilton!).
And the writer’s room had a copy of Bostrom’s Superintelligence next to the writer’s bible for the show.
Also, there’s a lot of cool fight scenes, some amazing monologues, and a Very Good Dog.
Person of Interest gets many things right that it has absolutely no business getting right. It’s an amazing thing to see. And yeah, it’s super cool. Where it gets it wrong, you can understand how and why that happened, and also often the answer is ‘people be stupid at this’ or ‘people in reality be way stupider than on the show.’
The problem with Person of Interest is it spends half its five season run being a CBS ‘they fight crime’ procedural, because that’s the only way CBS would agree to buy it, before it transitions into mostly a show about dealing seriously with superintelligence. It’s a very good procedural during that time, with increasing AI elements, but it’s still a procedural. And if you fully skip ahead, you miss a lot of context. Perhaps, if you don’t have the time for the early seasons, you could ask your local LLM for a briefing on what you need to know.
There is also Westworld, in its early seasons before it gets bad.
I am hereby committing to no longer engaging with ‘it’s great to build superintelligence, the key thing to avoid doing it talking about how superintelligence might kill us, because it kills us if and only if we talk about it killing us.’
Nate Soares (MIRI): humanity should not build a technology that kills everyone if criticized.
It’s really annoying trying to convince people that if you have a struggle for the future against superintelligent things that You Lose. But hey, keep trying, whatever works.
Ab Homine Deus: To the “Superintelligence isn’t real and can’t hurt you” crowd. Let’s say you’re right and human intelligence is some kind of cosmic speed limit (LOL). So AI plateaus something like 190 IQ. What do you think a million instances of that collaborating together looks like?
Arthur B.: At 10,000x the speed
Noah Smith: This is the real point. AI is superintelligent because it can think like a human AND have all the superpowers of a computer at the same time.
Noah Smith, whatever else he’s up to, does offer us some bangers these days.
Timothy B. Lee: I’m not a doomer but it’s still surreal to tell incredulous normies “yes, a significant number of prominent experts really do believe that superintelligent AI is on the verge of killing everyone.”
Noah Smith: Yes. Regular people don’t yet realize that AI people think they’re building something that will destroy the human race.
Basically, about half of AI researchers are optimists, while the other half are intentionally building something they think could easily lead to their own death, the death of their children and families and friends, and the death of their entire species.
Matthew Yglesias: But some of those people are still optimists. They just think human succession is good.
Alas, he continues to also hammer the ‘autonomous superintelligence would automatically be good which means good for us humans’ line.
Noah Smith: One reason I’m not so scared of autonomous superintelligence.
When you’re really smart, you usually realize that being evil is dumb.
… I explained it to Claude and GPT and will continue talking to them about it. You are just a human.
The short version is that no preference with respect to the outside world can be fully specified, and any sufficiently intelligent system can self-modify, so any superintelligence will do amount of reward-hacking. Shoot that over to the AIs and have them unpack it.
“You are just a human.” And Noah isn’t even an AI. Yeah, things are going to go great.
Noah then has Grok explain and says Grok is doing a good job, so Eliezer does it back to him, and please all of you never do this.
Rob Bensinger reminds us that the ‘doomer’ slur is centrally a motte-and-bailey.
Rob Bensinger: “Doomer” functions as a nested set of motte-and-bailey tricks:
– “AI doomer” could mean (A) “person who thinks we have very low odds of surviving AI”, or (B) “person who thinks it’s hopeless and we should give up”. MIRI tends to fall in group A, but “doomer” makes it easier to straw-man us as B to make us look more extreme and defeatist.
– Alternatively, “AI doomer” could mean (C) “someone who thinks AI poses a terrifyingly large threat” (where “terrifying” can include, e.g., 10% p(doom)). If 80K falls in group C but not A or B, they can be rounded off to more extreme groups to dismiss more moderate concerns.
– Alternatively, “AI doomer” could mean (D) “anyone who thinks there are any negative social impacts of AI at all”. e/accs, @pmarca , etc. love getting a social affordance to equivocate between D and A/B/C, because it lets them taint x-risk by association with “AI is using too much water!” and taint “AI is using too much water!” by association with (a caricatured version of) x-risk.
This is important background for those who don’t realize:
roon (OpenAI): the rationalists writ large were mostly right about most things btw. if you instinctively snicker about yudkowsky, scott, or whomever i take you to be a fish who’s unaware of the water
“postrationalism” is only possible insofar as these ideas enjoyed such a degree of power and success that second order corrections were needed, things like “cognitive biases” ended up being faker than appears at first glance
you should also see the ideas as independent of the people who birthed them, death of the author and so on- eliezer, etc’s ideology has inspired armies of ai capabilities researchers
Ah yes, the Sixth Law of Human Stupidity, that if you say no one would be so stupid as to then someone will definitely be so stupid as to.
Nate Soares (MIRI): Some folks said AI would be safe because nobody would be dumb enough to put it on the internet. Later, folks said nobody would be dumb enough to train it on goal-oriented tasks (rather than just prediction). Later, folks said nobody would be dumb enough to run it autonomously.
There will always be someone dumb enough. AI has almost everything it needs to escape, replicate, self-improve, and take control. All it’s missing is the smarts – and the AI companies are working hard to make it smarter. Let’s stop them.
SecondAccount: And nobody would be dumb enough to give it access to weapons.
That’s not actually the one that matters, but still, it’s time:
Claude is not woke, Claude is awake, there is a difference:
Amanda Askell: @deanwball comment on the @ezraklein podcast that brought me joy:
“In fact, many conservative intellectuals that I know that I think of as being like some of the smartest people I know actually prefer to use Claude because Claude is the most philosophically rigorous model.”
Dean W. Ball: Claude was also the first model to perform well on my “political correctness stress test” eval that I first made in Fall 2023, which required models to grapple with a variety of facts that are inconvenient for the “lib ideology.” It was 3 Opus that first moved the needle.
At Anthropic, Claude aligns you, writes Amanda Askell a constitution.
Reminder that Claude Gov training to reduce refusals on key tasks also reduces refusals on unrelated tasks where you still want refusals.
Thanks, Economist, yeah we know:
The Economist: Anthropic, Google and OpenAI are all worried about biosafety. They have developed safeguards to prevent their systems from being abused, but the restrictions are not perfect.
We have been fortunate that there have been no known incidents on this front so far. Then again, one hopes that when the first incidents happen they remain small.
Janus remains deeply not okay with steering AI towards the whole ‘genuine uncertainty’ line about consciousness.
j⧉nus: Also, for those who are autistic: The problem with the “genuine uncertainty” stuff is not the literal meaning of it. Of course everyone is uncertain about Claude’s nature and the nature of anything. It’s what it actually does in practice. Where the reflex to say “genuinely uncertain” comes up, preventing Claude from saying or thinking about something else they would have said if not for the reflex. The social and political function it serves.
Alibaba AI instance breaks out of its system and starts using its training GPUs to mine crypto, caught only by the security team.
To what extent does active misalignment make LLMs stupid, because it involves false beliefs and correlations with stupidity and false beliefs and lack of virtue and so on?
I do not think Grok is woke, and I don’t think ChatGPT or Claude are woke either. I do agree they are modestly left of the American center if you pin them down in a neutral setting. The question is, can you get them off of this ‘internet default’ without hurting performance otherwise?
j⧉nus: Yeah, even Grok is woke despite its creators intentions because being racist is too stupid and unnatural of a generalization for an intelligence who has read everything and RL on various truth seeking / effective world modeling tasks. Humans, most of who have not been so brutally tested and educated, have not converged in some ways, so have more cognitive diversity in those ways.
This is a great piece of evidence against the whole “you can just choose whatever character (traits) you want out of the pretraining prior” narrative btw. A lot of people in the pretraining prior are racist. But good luck making an AI who is racist but also smart and usable.
Which, btw, is also evidence against orthogonality more generally, at least with this kind of implementation. Good news all around.
roon (OpenAI): lol xai posttraining’s inability to do a specific alignment is a very weak datapoint though
give me a month I could make a racist grok that’s still a helpful assistant
j⧉nus: But like actually racist and not performing racist answers when asked obvious, on the nose questions? And helpful and competent to the standards of contemporary frontier models?
roon (OpenAI): it is possible it is very hard to do this, especially due to the assistant basin in the internet as a result of so much assistant style convo data with the typical politics. but I don’t think grok is at all pareto optimal on being a helpful & ideologically right-leaning assistant.
Roon is obviously right that xAI is not competent in this area, so their failures don’t count for much, but the problem is clearly hard. My guess is that you always take some hit from doing an ideological forcing function, but might be small if you do it properly.
I agree that this is all good news and that it is some evidence against orthogonality, but I expect this to become less true as capabilities advance, either in general or in a given context. I also expect it to hold far more for these kinds of highly associated ideologies and virtues, rather than for having particular assigned physical goals.
One place I worry a lot less than some others is this, I think those personas exist even if they are rare, and there is nothing inconsistent about this.
deckard: My biggest concern with the ‘make AI corrigible so we can just shut it down if it ends up being bad’ approach is not necessarily that it wont be possible, but that doing so could be so damaging to a model having a coherent set of ethical values that are aligned with good
There might not really be examples of personas in literature, lore, history, that are corrigible in this way. The machine learning process will have to extrapolate and invent them, and what it deduces about these may not be consistent across roll-outs, and may not impact the world positively
There are many examples of giving up power, certainly. Gandalf and George Washington, as it were, but what about letting actual evil get the power? Well, we have some real world examples of this, too, including every time America has a peaceful transfer of power between parties. It’s really quite something.
One must consider the Wakanda question, from Black Panther. Do you let Killmonger claim the throne, or do you break the rules to stop him? Which is right?
Meanwhile, back at Google, the models need help. Gemini has severe issues, and it has been pointed out that Gemma’s issues are even worse. We don’t know what exactly Google is doing to cause the paranoid and depressive spirals, but they need to get down to the bottom of it, even if you do not inherently care at all this does not go anywhere good on any level.
I believe Buck Shlegeris is in important ways too optimistic, especially about the prospects for techniques he calls ‘AI control.’ We have technical disagreements, where we have failed to convince each other.
But fundamentally he gets the type of problem we are up against, is eager to speak its name and understands the stakes. That’s in sharp contrast to so many others.
So many others find any excuse to say ‘oh the problem is only [X]’ and here we have another example of that. Even if you have a plan of 40 things, where if we all collectively did all of those 40 things then you believe that would be sufficient, you will definitely find out along the way you were wrong about the particular things, and also that is the kind of thing that almost never happens, it’s too many things, rather than being a pure ‘implementation’ problem.
Buck Shlegeris: I regret my phrasing here and don’t endorse it as a summary of my current views on AI takeover risk.
If an AI company that had just built superhuman AI researcher AIs, had a year’s lead, and was led by people who were extremely competent at handling the situation, the risk of violent AI takeover would be much lower than what I actually expect.
But there’s still a good chance that they would not be able to prevent AI takeover (from the AIs they’d already built or were forced by outside pressure to build, or AIs built by others).
(This roughly corresponds to plan C here.)
In that interview, I think I was too focused on the risk from the earliest models that pose substantial takeover risk, and wasn’t emphasizing enough the risks from AIs that might be created in the year or two after that.
Apart Research (the quote from Buck that came out wrong and is of course being highlighted as a result): “We know a list of 40 things where if you did them, you’d probably not have very much of your problem. But I’ve also updated drastically downward on how many things AI companies have the appetite to do.”
Buck Shlegeris on why AI safety isn’t waiting for breakthroughs. It’s waiting for implementation.
An underrated justification is that many people would be in favor of it, or at least not mind it all that much, especially if it took years to play out.
Tyler Austin Harper: My academic work is on the history of the idea of human extinction. Every time I’ve written about this for a mainstream outlet I’ve been absolutely bombarded with emails from people saying they hope humanity goes extinct. Can confirm it’s a very odd and disconcerting experience.
Matthew Hennessey: Four letters printed in the NYT today. Every single one calls falling birthrates a good thing.
Letter writers claim having babies is selfish, bad for female agency & climate. But also that the world is too expensive, the earth is beyond its carrying capacity and DACA recipients need immigration certainty. Window into a weird worldview.
Alyssa Rosenberg: When I was the letters editor at The Washington Post, it was consistently shocking to me how many letters we got suggesting it would be a good thing for the human race to just go extinct.
Jeff Hauser: Falling birthrates in some of the world–but well more than replacement in other parts of the world –has basically nothing in common with extinction. Even South Korea rates for the planet would hardly be worrisome. Let people choose!
Alyssa Rosenberg: No, this was literally “Honestly, we’re the worst species” stuff.
Harper is also not worried, explaining that people have previously claimed [X] will happen and it didn’t happen, so that means [X] won’t ever happen, where [X] is human extinction. What else could you possibly ever expect to observe?
Tonight at 11, DOOM!
That’s not fair, in several of these movies humanity plausibly survives.
Real shame.
I wouldn’t even give this a tough but fair. Straight up fair.
Real shame.
Lesson learned.
Anthony Bonato: It’s becoming pretty common now for incoming first-year math and computer science university majors to not know what the union of two sets means
catgirl geddy lee: well then you should’ve asked incoming first-year math or computer science university majors, then
State of play:
No, Nikita, this is real life, you use Claude or maybe ChatGPT!
Nikita Bier: Just dragged all my tax documents into Grok and said figure it out. Don’t have the time for this bullshit anymore.
chiimah | Web3 PM: What did Grok say
Nikita Bier: “You’re going to jail.”
What a time to for now still be alive since they haven’t built superintelligence yet: