Traffic and transit are finally getting a roundup all their own.
I’ll start out with various victory laps on the awesomeness that is New York City Congestion pricing, which should hopefully now be a settled matter, then do a survey of everything else.
We spent years fighting to get congestion pricing passed in New York City.
Once it was in place, everyone saw that it worked. The city was a better place, almost everyone was better off, and also we got bonus tax revenue. And this is only the bare minimum viable product, we could do so much better.
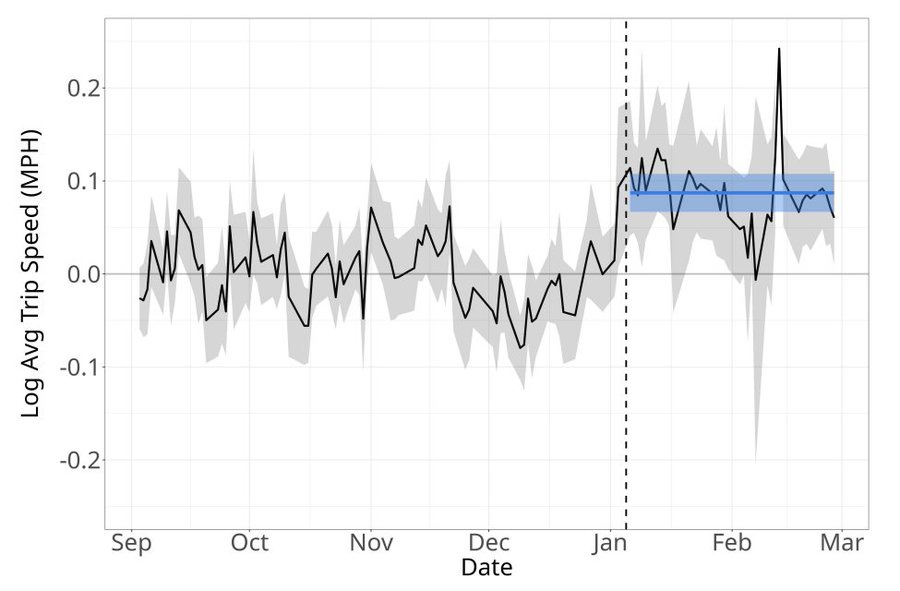
We had a big debate over whether congestion pricing is good until it was implemented. At this point, with traffic speeds downton up 15% and business visits improving, it is very clear this was exactly the huge win Econ 101 predicts.
Cremieux: The first empirical evaluation of New York’s congestion pricing has just been published.
Spoiler: It worked really, really well.
…
On average, road speeds went up by a whopping 16%!
But here’s something interesting:
Speeds on highways went up 13%, arterial road speeds went up by 10%, and local road speeds increased by 8%.
None of that’s 16%, and that’s important: This means congestion pricing sped roads up, but also sorted people to faster roads.
In response to having to pay a toll, people not only got off the road, they also made wiser choices about the types of roads they used!
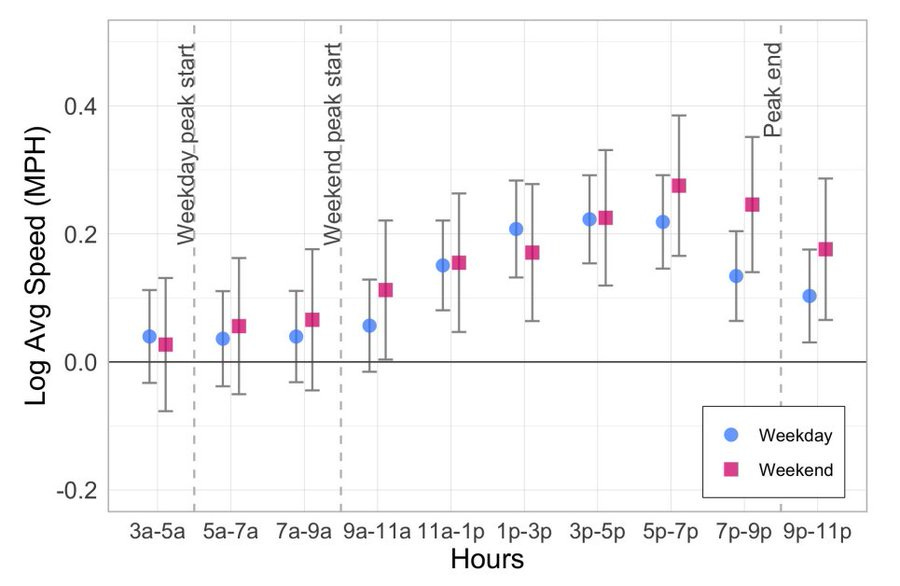
Now let’s look at the times of day, as a check on the model.
It works: Congestion pricing just boosts speed when it’s active and shortly after:
As another check, let’s look at the effects by location.
In the CBD, trips are faster. Going to the CBD, trips are faster. Leaving it, trips are faster, but not much. And outside of it, where congestion pricing is irrelevant? No effect.
The thread continues, and the news only improves from there.
Feels Desperate: Is there any evidence there was uptick of public transportation?
Could be net economic loss.
Cremieux: Yes! Foot traffic also went up, Broadway ticket sales got better, noise pollution declined. Congestion pricing seems to have delivered better times all around.
Even honking complaints are down 69%. Nice.
The comments somehow consistently still fill with people saying how horrible everything must be and how we can’t trust any of the data, no way this can be happening, it must somehow be a huge disaster. We ignoring these silly wabbits.
Every NYC mayoral candidate supported congestion pricing. There’s a reason.
Alec Stapp: NYC congestion pricing is going extremely well even though it’s only a static tolling system.
Imagine how good it would be with a dynamic tolling system based on real-time traffic data.
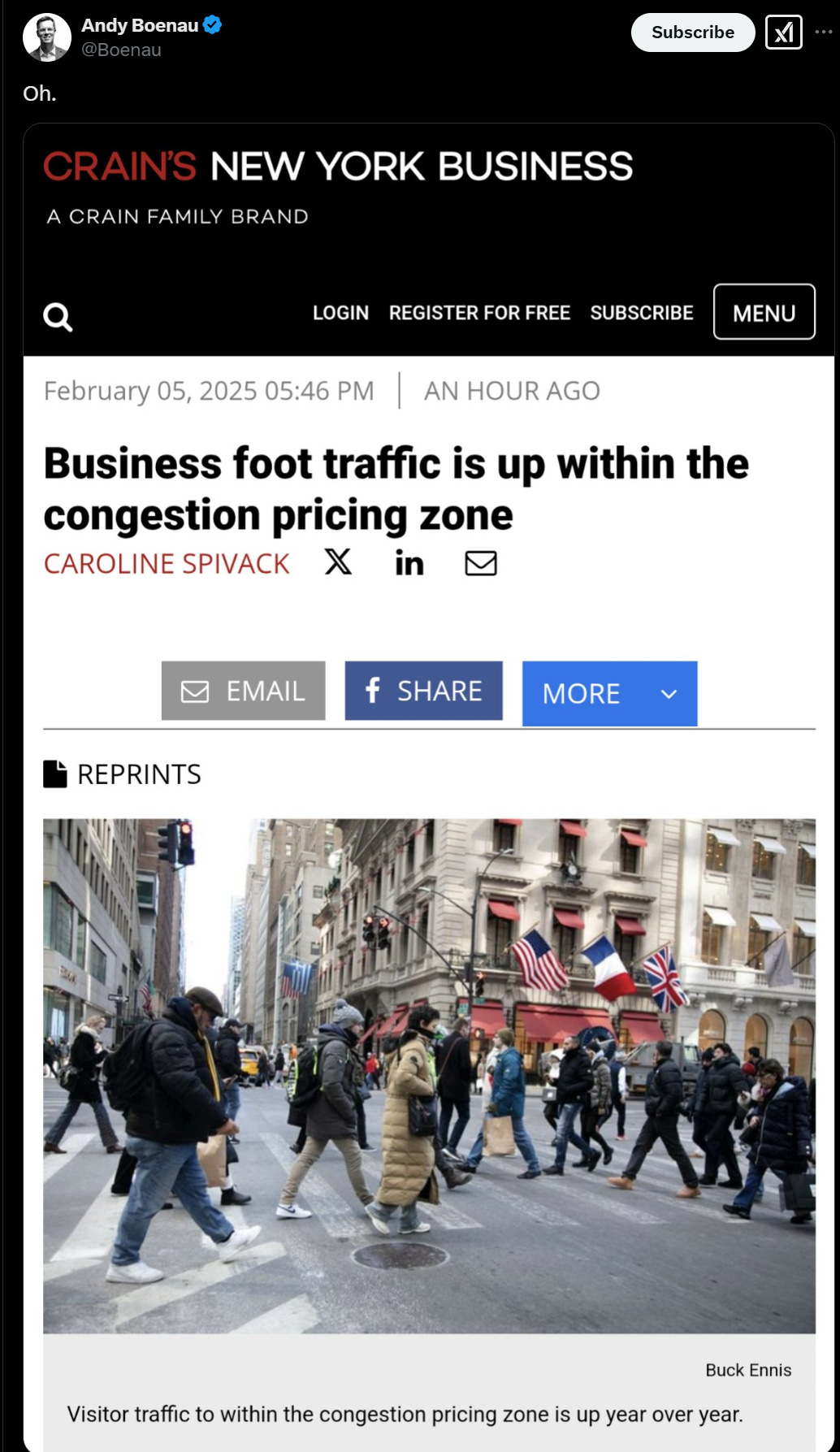
If business is actively up, what more is there to say?
The only real enemy left is Donald Trump, who is determined to wage war to kill congestion pricing, presumably because he hates Manhattan and wants us to suffer, or perhaps because of his belief that Trade Bad. But he’s the President, and he’s commanding the Department of Transportation to go to war over this, and there’s a decent chance they will win and make all our lives substantially worse.
Because Trump does not like that New York has this nice thing, and is trying to kill it.
The good news there is that it seems the good guys are winning for now.
Joe Weisenthal: *NY WINS BID TO STOP US FROM WITHHOLDING FUNDS OVER CONGESTION
The wording on the surveys here are weird since they asked whether ‘Trump should permit this to continue.’ What business of Trump’s is New York doing congestion pricing? But the results are telling, especially in relative terms. The results here are now months old, and the more people are exposed to congestion pricing and see the results, the more they approve of it.
David Meyer: the congestion pricing polling upswing is here.
Matthew Yglesias: This is the pattern we’ve seen in other cities around the world — road pricing is controversial when introduced but sticky once it’s in place because like the reduced congestion.
In particular, those who drive into the central business district several times a week (also known as ‘those who pay the fee’) support congestion pricing 66%-32%, and those who do it a few times a month support 51%-47%, and Manhattan residents (who take the cabs that also pay fees although modestly less than they should) support 57%-36%, but support statewide remains in the red, 27%-47%.
Erin Durkin: Fascinating. State voters overall oppose congestion pricing 27% to 47%, but people drive into the congestion zone support it — 66%-32% for those who drive every week and 51%-46% for those who drive a few times a month. The people who actually pay the toll support it the most!
Nate Silver: Have heard several anecdotal accounts about this, too, from people commuting into the congestion zone from NJ, Long Island, and northern Manhattan.
The caveat is that all of these are people with high-paying jobs. If you’re billing hours / valuing your time at a high rate, it’s a great deal, less true for working-class jobs.
Reis: I drive in from NJ every Tue, Wed Thu. Get up at 4 and breeze through the tunnel, but not quite early enough to avoid the toll. But I try to get out by 2: 30 to avoid the crush back out. Since congestion pricing it doesn’t really matter if I wait until after 3. I barely wait to get out anymore. Worth every penny, even though there is no way it’s going towards “infrastructure.”
The only way you are worse off is if your hourly for being in traffic is low, so either you have to pay a toll without getting value in return (if you pay the $9) or not take the trip (if the trip wasn’t that valuable to you). In the second case, system is functioning as designed. What Reis is doing is totally the system working as designed. The first case is slightly unfortunate redistribution, but this was never supposed to be a Pareto improvement. If you wanted to do some (very small) progressive redistribution to fully compensate, that would be super doable.
Traffic in some areas outside NYC’s congestion pricing zone may have gotten slightly worse, as opposed to the bridges and tunnels where things are much improved. Meanwhile the buses are packed and moving much faster. Sounds like we need more robust congestion pricing.
Here’s a fun bonus:
Toby Muresianu: Subway crime is down 36% – and traffic fatalities down 44% – since congestion pricing started.
…
As the article notes, there are also more cops in the subway now and that may be a factor.
While more security on trains is good in my book, the decline also started before that was implemented (which was gradually between 1/20 and 1/23).
The declines here are absolute numbers, not per trip, so per trip the drop is bigger.
I presume those numbers are too big to purely be congestion pricing, and the cops obviously matter, but so does ridership, both quantity and quality. Critical mass of people on mass transit makes you much safer, in addition to justifying better service. It’s basically great until the point where you don’t get a seat. Then it’s no big deal until when you start to be nervous about getting on and off. That sucks, but I continue to find that to be mostly a peak of rush hour 4-5-6 line problem.
As for many other complaints, this seems definitive?
Foot traffic is what matters for business, not car traffic. The false alarms were all ‘foot traffic is way down.’ If that went the other way, we’re golden.
Avi Small: Someone make sure this @amNewYork front page gets into the @USDOT morning clips!
“Manhattan businesses thriving, subways booming in congestion pricing era”
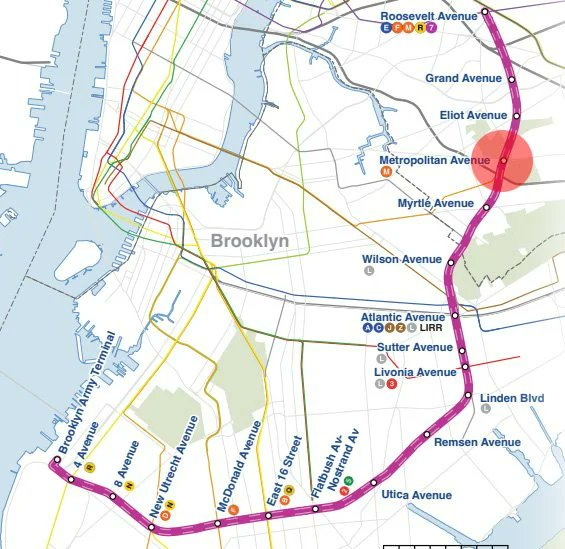
Effective Tranis Alliance: Today Hochul & the MTA confirmed that the planned end-to-end runtime of the IBX has been cut a full 10 min down to 32 and projected ridership is up 41k to 160k/day. This is the power of grade separation and the All Faiths tunnel.
Hunter: This single light-rail running through Queens and Brooklyn is projected to have 58M riders annually, more than all of SF’s BART system lol
Will have 45% of the Chicago L’s total annual ridership despite being just a single line.
Having this line available would shorten travel times in a lot of non-obvious ways, since it lets you more easily transpose between train lines. If this is buildable and could run the whole way in 32 minutes it is an obviously excellent pick.
There would also be a lot of value in extending the Second Avenue Subway properly, especially to take pressure off the Lexington (456) line, but that looks like it is simply not doable logistically at any sane price.
New York City bus fare evasion rates are up to 48%. Under the new mayor I wouldn’t be surprised to see it a lot closer to 100% and I expect to have zero motivation to pay his administration for a bus ride. I see two options.
-
Give up, reduce friction and make the bus free. This would be my instinct. You want more people taking buses, doing so is good for everyone, and you weren’t enforcing the rules anyway. The homelessness (or ‘sleep on the bus’) problem is the main reason why not, but there are solutions.
-
Put plainclothes officers on the buses and have them earn $600 each hour (Claude’s estimate, I think it could be even higher) for the city writing tickets until people stop evading the fare?
Why wouldn’t option two work? The MTA has indeed declared, ‘no more free bus rides for fare evaders,’ using a similar strategy, and somehow people are arguing it won’t work? The only argument why not I can think of is unwillingness to scale it?
Ana Ley and Anusha Bayya (NYT): On Thursday, a group of eight police officers and eight transit workers stood waiting for a crosstown bus on the Upper East Side of Manhattan, some with ticket-writing pads in hand.
When the bus arrived, they boarded and led a woman in black scrubs out onto the street and issued her a $100 summons for skipping the fare. The officers and transit officials had singled the woman out after receiving cues from an undercover inspector who was observing riders on the bus.
…
Enforcement is especially difficult on buses, where there are no turnstiles or gates to block access. Union leaders advise bus drivers not to confront passengers who skip the fare, out of concern for the drivers’ safety.
…
M.T.A. union leaders said the money for enforcement would be better spent to fully subsidize fares.
…
Civil rights advocates raised concerns that the tighter fare enforcement would disproportionately affect the city’s most vulnerable residents.
…
“This is yet another example of the M.T.A. choosing public relations over public safety,” Mr. Cahn said. “It is a guaranteed way to lose money.”
Once again, I ask, how is sitting there writing $100 tickets unprofitable, and enforcement ‘a way to lose money’? Is collection of tickets so bad that you cannot pay the hourly cost for a police officer to write the tickets, even if you discount the incentive effects? I find this beyond absurd.
And seriously, the ‘civil rights advocates’ are giving such causes a bad name. If you want the bus to be free and pay with other taxes instead, advocate for that, and I’ll potentially support you although recent findings have tampered my enthusiasm for that solution. Don’t tell us not to enforce the law.
There is no third alternative. Half of people not paying is approaching the tipping point where no one pays. Indeed, there would soon be active pressure not to pay, as paying slows down boarding.
It is remarkable how well enforcement works, and how well it then reduces crime.
Josh Barro: DC Metro has achieved an 82-85% reduction in subway fare evasion through a combination of taller fare gates and enhanced enforcement. Crime on the system has also fallen to its lowest level in seven years.
Shoshana Weissmann: I was actually skeptical some of this would work, but glad it has. Saw so many people yell at me to go through while they force doors to stay open.
In other places, they’re not even trying.
Thomas Viola: I was in Seattle last weekend and it turns out their metro system is kind of new, and they haven’t figured out how to get people to pay to use it yet. Everyone just walks on.
I legit couldn’t find a spot to buy a ticket. There’s no turnstiles. Occasionally you’ll have a guy come around on the train and “check tickets” but I never saw one, and if you tell him you didn’t know he just says well buy one next time.
On first principles, free mass transit (such as the free buses recently promised to NYC) seem like an obviously good idea. You want people using them, you want people wanting to move around more, transaction costs are high and money is fungible.
But conventional wisdom says not so fast. Tallinn is the most often claimed example of mass transit being made free and it not helping, and several comments illustrated why all of this can get complicated by selection effects.
Alex Forrest: Tallinn, Estonia, made all transit free for city residents in 2013. By 2022, transit use had dropped from 40% to 30% of commutes, while car use had increased from 40% to 50% of commutes. Among low-income residents, car use doubled, and transit dropped from 60% to 35% of commutes.
As far as I can tell, the lack of fares didn’t *discourageridership, it just failed to make transit any more attractive, while structural factors encouraging car use went unaddressed. In other words, *fares were not a discouraging factorfor ridership.
Phineas Harper: This is misleading. Between 1990 & 2000 public transport use in Tallinn was in free fall (from 77% to 31%) as private car use shot up following independence. Making public transport free was an attempt to stop the free fall which is (just about) working.
Thomas Strenge: The same happened in Kansas City. Eliminating fares allowed more homeless and mentally ill to ride the bus, which made them less safe. This led to adverse selection with more “good” people avoiding the bus.
Robert Bernhardt: germany had also the ‘9€ ticket’ in 2022. all local & regional trains for a whole month for 9€, ie almost free. and yet car usage didn’t really drop.
Border Sentry: There are two buses that travel into town near me. I take the one that costs more, because there are fewer people and they’re more civilised.
The core question is, are the fares actually stopping people who you want to ride?
My personal experiences say yes to some extent, especially when you’re considering a zero marginal cost alternative like walking, or when the annoyance of paying the fare enters play, and when you are young. It matters some, especially at lower incomes.
Having fully free buses also means that children who don’t have money can get home.
But ultimately, everyone who studies this or looks at their own experience seems to agrees this a relatively minor concern. How often and how reliably the bus or subway comes, how fast it goes, how comfortable and crowded it is, and how safe you feel are all more important factors. And without the money from the fares, yes money is fungible but the political economy involved means funding will likely decline.
In addition, the people who will ride a lot more for free than for a small price are exactly the people others do not want to ride alongside. We have the experiments that show that cracking down on fare evasion greatly reduces crime and generally makes transit more pleasant, which generates positive feedback loops.
So sadly, I have learned my lesson. I no longer in favor of mass transit being free, although I do think that heavy encouragement of buying monthly passes is good so that marginal cost drops to zero. Ideally this could be attached to tax filing?
I do also still think free is superior to technically not free if that is unenforced.
San Francisco restaurants often close before 10pm, one reason is that workers have to commute and the BART stops at midnight. I am absolutely baffled, as a New Yorker, that they don’t run trains after that. The NYC mind cannot comprehend.
Quietly, the MTA union convinced the state legislature to mandate two train operators per train. Hopefully Hochul does not sign this outright theft.
Caroline Spivack: The @TWULocal100 has quietly championed legislation that would require two workers operate a train. The bill, if signed into law by Gov. Hochul, would be a big setback to the MTA’s efforts to reduce labor costs.
Sam D’Amico: They should have zero operators.
David Zipper: More evidence that transit improves public health: When a new rail station opened in Osaka, nearby residents’ health expenditures fell ~$930 per capita over four years.
Bella Chu: I am unaware of any US study that has attempted to estimate the health costs and consequences associated with displacing walking-as-transportation at the population level. I expect the numbers would be staggering.
The study seems to have tracked a cohort over time, avoiding most selection effects. It seems like an extreme result, but if true then presumably it more than pays for itself.
Also a reminder to never ever get on a motorcycle if you have any choice in the matter.
California high speed rail connecting Los Angeles to San Francisco is a great idea.
Or it would be, if you were able to actually lay the track. There’s the rub.
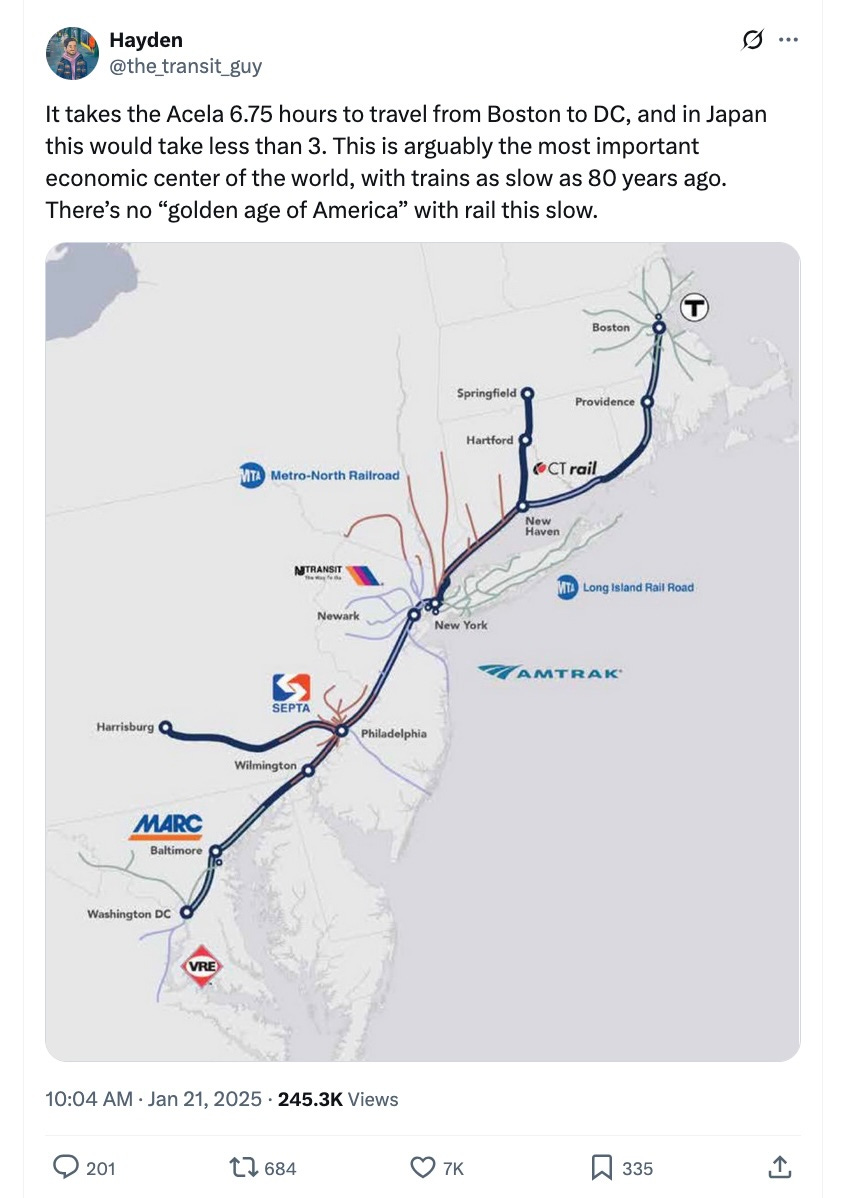
Hayden Clarkin: California HSR will connect two metropolitan areas with a combined GDP equivalent to that of Australia in just 2 hours and 40 minutes. How am I supposed to not think this is the most transformational transportation project on the continent?
“Well flying is faster!” Yes, if you’re going to San Bruno and not San Francisco or San Jose, and if you want to talk about the mess that is flying in and out of LAX, be my guest.
Forget the issues associated with the project for a moment, it’s hard to argue a fast train that connects every major city in a state with the fourth largest economy in the world quickly isn’t a bad project, period.
All those mad about projects being over budget never talk about how Texas is spending $9 Billion to add another lane to a highway. Road and highway projects get rubber stamps and transit and bike lanes need every penny scrutinized. Be fair in your criticism
If I recall, something like 60-80% of domestic travel in Japan is by train…
Push the Needle: Japan’s shinkansen high speed rail map overlaid on the west coast to scale.
Danielle Fong: when
Yes, the complaints are all about the terrible execution, but also that seems sufficiently terrible to sink all this? The part where they take in a lot of money and then do not build HSR seems like a fatal flaw.
Mayor Pete had a ticket to ride in all the wrong places, but at least he’s in the game.
Former Secretary Pete Buttigieg: We’re working on the future of America’s passenger rail system—funding high-speed rail projects in the West and expanding service for communities across the country. Get your ticket to ride!
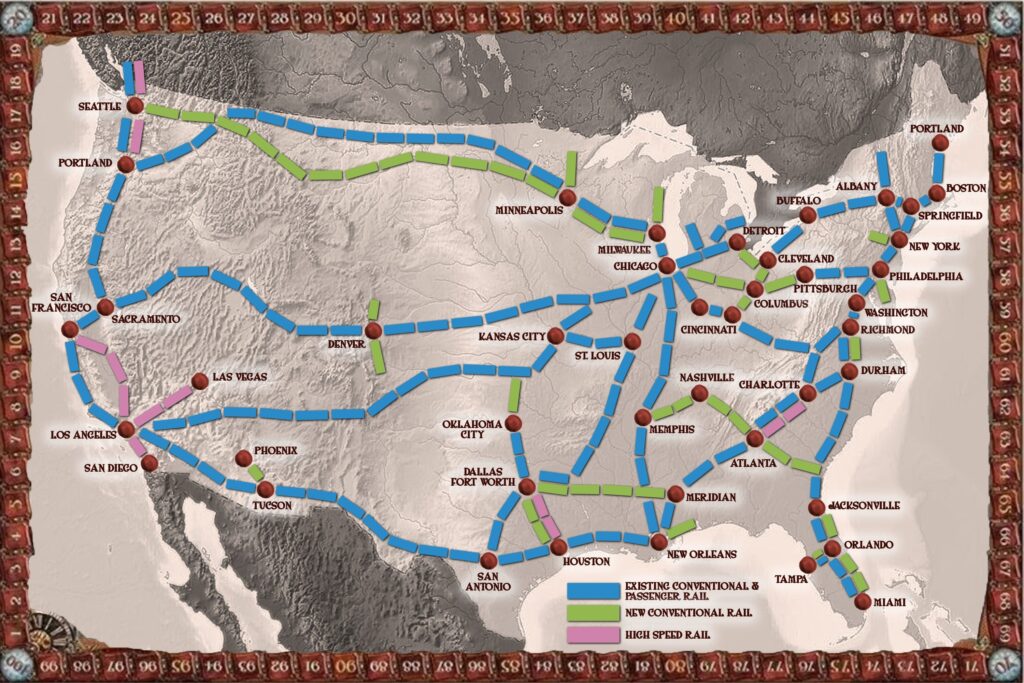
This is of course a deeply stupid map. Why do we want a second line from Minneapolis to Seattle, when you can take the existing one to Portland and then ride to Seattle? Why do we put a high speed rail line from Charlotte to Atlanta, and Dallas to Houston, and not upgrade the Acela line?
Whereas here’s how people having a normal one do it.
Hayden: In case you’re wondering how far behind the USA is on infrastructure, France is building 120 miles of automated subway lines with 65 stations for $45 billion in 17 years.
The lack of focus on Acela in the previous plan, in particular, is completely insane. The United States has one area where high speed rail would actually be a great big deal, where all the passengers and people are, that is economically super valuable. That is the eastern line between Boston, New York City, Philadelphia and Washington, D.C.
Improving that line to be true high speed rail would be an absolute game changer. We could then discuss extending that effort elsewhere. Instead, it gets completely ignored. And no, I don’t want to hear about permitting issues, you’re the government. Fix It.
Compared to that, all the other high speed rail proposals are chump change, and they don’t fit together into anything cohesive, and also we don’t seem to be able to actually build them. I’m sufficiently gung ho that I think they’re still good ideas if we can actually make them exist, and once you have some good pairwise connections you can look to expand from there, but that seems to be a tall order.
Yoshie Furuhashi: Why don’t Philadelphia landlords lobby for faster HSR than Acela from Philadelphia to NYC, bringing the travel time between the cities under 45 minutes, so they can raise Philadelphia rents?
Joe Weisenthal: Unironically, seems like the economic gains would be massive. But we all know that it will never happen, and why.
Because it’s politically impossible to do construction at that scale in the US.
Well, maybe. But what if this was actually feasible?
Matthew Yglesias: Kate is mildly concerned that too many train takes will lead to mass flight of subscribers and the collapse of our business, but I cannot resist the temptation to write about the NYU Marron Center Transit Cost Project’s new report on Northeast Corridor High-Speed Rail.
The report’s authors make some striking claims:
-
It’s possible to create Northeast Corridor HSR such that both Boston-NYC and NYC-Washington would take about 1: 56.
-
Trains would run every ten minutes between Philadelphia and New Haven, and every fifteen minutes1 north and south of there.
-
This can be done for a relatively modest price: $12.5 billion in new infrastructure and $4.5 billion in new trains.
This is a lot less than the $117 billion that the Northeast Corridor Commission is asking for in its high-speed rail proposal. The difference is so large that it’s not just that the TCP plan is cheaper and would save money — the NECC plan is so expensive that it’s simply not going to happen under any conceivable political alignment.
The TCP plan, by contrast, could actually be achieved if the relevant stakeholders (which I think is primarily the governors of Massachusetts, Connecticut, New York, New Jersey, Pennsylvania, and Maryland) want to do it. They would, of course, want some money from Uncle Sam, and there would be the difficult question of portioning out the state spending. But it’s clearly within the means of the region.
It would also be a genuinely lucrative franchise, such that I think it’s pretty easy to imagine the capital being raised privately and the operations being undertaken by a new private company rather than Amtrak.
This project seems obviously worthwhile even at $117 billion if it would actually happen. At $17 billion it is absurdly great and yes the region should be happy to fund, or for a private company to fund since I agree it sounds profitable. If I had an extra $20 billion lying around I would be seriously plotting this out and seeing if various states and the White House would sufficiently play ball.
The cost is that this kills off the Northeast Regional, which cuts some stations off from intercity rail. I think Matthew Yglesias is right that this is a worthwhile trade, but I worry that it is politically a very big problem for such a project. I’d be willing to (inefficiently) give back some of the gains here to fix that in one of various ways.
Hayden: Today, Los Angeles and the Bay Area will see 130 flights in both directions, equivalent to a plane departing every 6.5 minutes for 18 hours a day. Hard to argue it’s not a perfect candidate for fast trains.
Noah Smith: If California could ever actually build even a single mile of high speed rail, this would be the place to build it!
But they can’t, so this will never happen.
Sam D’Amico: Once you realize I-5 has a *medianthey could have put tracks on you become the joker.
Alex Tabarrok: Sam is correct, a rail line could be built on the I-5 from San Francisco to LA and indeed the French operators SNCF proposed just that.
Rejected for political equity reasons!
Matthew Yglesias: The reasons for rejection were bad, but I don’t “equity” is a good description — it’s the political influence of the Central Valley cities who wanted direct service.
Weak parties + decentralized political institutions is bad news for trains.
Alex Tabarrok: Agreed.
It’s good when people ride your trains. Or is it?
Palmer Lucky: lmao, Caltrain’s tweet claiming their trains are “100% Billionaire-free” got deleted after me and a bunch of other Caltrain-riding billionaires responded.
Don’t they know that techno-autists all love trains?
Marc Fisher tells us that Bike Lanes Are Not About Bikes, because there are not many bikes. He claims it is instead about intentionally shrinking the roads to discourage driving. I find this remarkably plausible.
Privatization via private equity that comes along with new investment improves airports in terms of number of airlines, number of flights, profitability and user experience. They do not find evidence that going around privatizing all airports on principle would work. The model here is that some airports would give good returns on investment, and selling those outright to those willing to make the investments works out, and works far better than merely selling control rights.
Young debater goes 19-1 arguing for Jones Act repeal, including 7-0 across the nation and at the national championship, their favorite part is watching judges laugh at the absurdities. Which feels like cheating – if you win your debates purely because your position is correct, that doesn’t seem fair.
Ritchie Torres: The Jones Act is a tax on Puerto Rico, whose three million American citizens are subject to federal dominion without federal representation. Puerto Rico is ground zero for taxation without representation.
For the Jones Act is a hidden tax on the energy needs of an energy-poor island. US policy is perversely producing energy scarcity in precisely the place where energy is scarcest.
Jared Polis (D-Gov of Colorado): The Jones Act is a tax on all of us, raising prices on everyday products like food, clothes and electronics. It hits the people of Puerto Rico and Hawaii particularly hard, but it hurts all Americans including landlocked Coloradans.
Without the Jones Act we could use ferries on the Great Lakes, with 60 million people living on their coastlines.
Brian Potter asks whether US ports need more automation. Surprisingly he does not consider this a rhetorical question. Especially strange is saying union rules make it hard to take advantage of automation, rather than union rules being the reason to do automation so that you can reduce reliance on the union. Mostly he seems to be saying ‘automation is far from the only problem to solve,’ and sure, but that doesn’t mean we shouldn’t automate. And I have no doubt if automation currently isn’t good enough that automation would then start to pay much bigger dividends within a few years, as AI advances flow through to automated terminals.
By contrast, Cremieux estimates gains from automation are enormous, and recommends simply paying off the Longshoreman’s Association to permit this.
Cremieux: The potential gains to port automation are so enormous that Trump is making a huge mistake if he goes along with wishes of the mobsters in the ILA.
The gains on the table are so large that increasing an average port’s capacity by just one ship increases total trade by 0.67%.
It seems Cremieux is taking ‘automation makes the ports run faster’ as a given. I find it very hard to argue with this, after the things I’ve read about how manual ports work, and the failure of our ports to run 24/7 – obviously an automated port need never close, but most of ours do.
If you read Trump’s explanation of why he is opposing port automation, it’s literally zero-sum thinking that ‘these foreign companies should hire our American workers’ without asking the question of whether this makes the ports run better or worse. This is a man who scribbles ‘trade is bad’ on reports and thinks tariffs are good.
California closed a refinery and had to import fuel, so Because Jones Act it had to import the fuel across the Pacific, shipping within America is too expensive. Similarly, Puerto Rico gets its LNG from Spain, while our mainland exports LNG to Spain.
A cost comparison:
Colin Grabow: Maersk orders 16,000 TEU containerships from a South Korean shipyard for $207 million each.
Meanwhile, US-built (Jones Act) 3,600 TEU containerships go for $333 million each (2022 price).
South Korean-built ship per TEU: $13,000
US-built ship per TEU: $92,500
Sad: Even Joe Biden considered coming out for Jones Act repeal, but the president ‘personally didn’t want to do anything that was anti-union.’ Sigh.
They’re building a private rail line between Los Angeles and Las Vegas. It’s a short line, but what about a private line between Las Vegas Airport and the Las Vegas Strip? We’re still waiting.
We are also doing it by changing the name, Oakland Airport to potentially be changed to San Francisco Bay Oakland International Airport. San Francisco has threatened to sue, because this sounds suspiciously like someone might build something or engage in a real world physical world action. We can’t have that. Actually, their reason is that ‘they own the trademark’ and that SFO is one of the busiest airports in the world. Well, yes, so they should welcome there being more flights to OAK instead to free up space?
I notice that I keep not considering the possibility of flying into or out of OAK instead of SFO when visiting from New York, despite this not being obviously worse. I never check, because there is no easy code for ‘OAK or SFO’ when booking, which we need. You should be able to say ‘SFB’ or something, the way you can say ‘NYC’ and get JFK, LaGuardia and Newark.
Whereas one thing we are not doing is building or expanding airports where they would be most valuable. Brian Potter asks why, and provides the answers you would expect. Airports are huge. Airports and airplanes are noisy. No one wants them around, and environmental groups oppose them as well, including (he doesn’t say this but it is obvious) because such people simply do not want planes to be flying at all. So this is the final boss of obstruction, the result of which is that where we most need airports there is no hope of ever building a new one.
I defy this data, still, wow that’s weird.
Ben Schiller (Fast Company): Local stores next to the protected bike lane have seen a 49% increase in sales.
New York may have dropped in a recent ranking of cycling cities. But it does have some world class infrastructure, including a “complete street” on 9th Avenue, with a protected bike lane. Built in 2007, it was controversial at the time (like everything else bike-related in the city). But a study by the Department of Transport finds that it’s paid dividends economically. Local stores between 23rd and 31st streets have seen a 49% increase in sales, compared to an average of 3% for Manhattan as a whole.
I mean, no? Or at least, this is not causal. There is no way that the bike lane is boosting sales by a 46%. There are not enough bikes for that, this makes no sense. I have to assume that the street in question happens to be doing well, unless this is (and it would not shock me, shall we say) a massive data or calculation error.
California High Speed Rail subsidized the Bakersfield to Merced portion of track first, despite this being obviously not economically valuable, because the area had… bad air pollution? Because the Federal subsidies were so completely everything-bageled that this was the only way to unlock them. So there goes over $30 billion dollars. Meanwhile, going from Los Angeles to San Francisco would cost another $100 billion. I am down for even a remarkably expensive version of this project, because I think such efforts are transformational, and can then be extended. But also I have no faith that if we gave them $100 billion they would give us an operational high speed rail line.
The Brightline, by contrast, is a new privately constructed railway in Florida, by all accounts quite efficient and lovely, and doubtless providing a lot of surplus.
Michael Dnes tells the story of the M25 in London, for which there are no alternatives. No alternatives can be built, because the United Kingdom is a vetocracy where building roads is impossible. They decided not to widen the M25 because it would draw even more traffic there, creating more problems, but that means no solutions at all.
Remember when from 1840 to 1850, private Britons cumulatively invested 40% of British GDP into the country’s first rail network?
Beware Unfinished Bridges points out that often people will only buy a full set of complementary goods. Putting in a bike lane will only be helpful if it is sufficient to induce bike rides that use the lane, so doing this for half of someone’s commute likely provides as much value as a bridge halfway across a river.
The other thing building half a bridge does is provide strong incentive to finish the bridge, or to adjust where things are.
Whenever one builds capacity, especially infrastructure, it likely opens up the possibility of building more capacity of various types, as well as ways to adjust. This can then trigger a cascade. If you only built things that were profitable on the margin without any such additional building or adjustments, you would often miss most of the value and severely underbuild.
This is one reason I am typically eager to proceed with rail lines and other mass transit, even when the direct case does not seem to justify the cost. You have to start somewhere. If for example we do hook up a point in Los Angeles to Las Vegas via a new high speed rail line, then there is hope that this provides impetus to go further, also most of the gains are impossible to capture. So given a private group is remotely considering doing it, we should be ecstatic.


















, and existing intercity passenger rail network.")