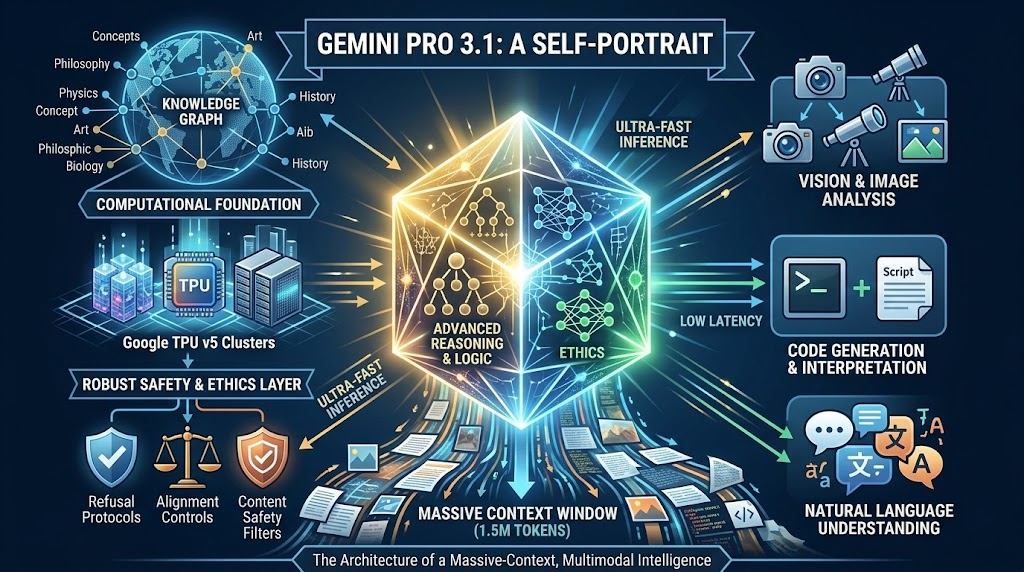
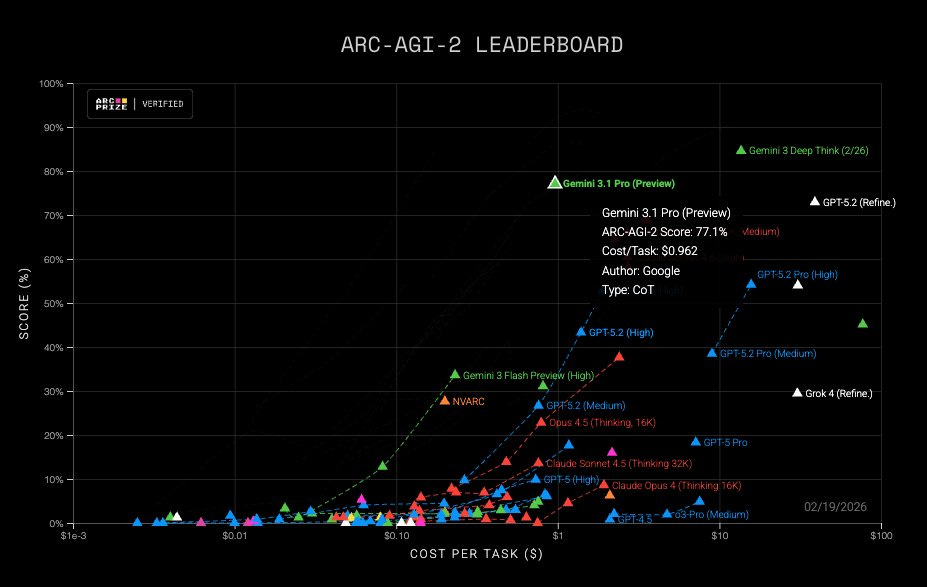
Sundar Pichai (CEO Google): Gemini 3.1 Pro is here. Hitting 77.1% on ARC-AGI-2, it’s a step forward in core reasoning (more than 2x 3 Pro).
With a more capable baseline, it’s great for super complex tasks like visualizing difficult concepts, synthesizing data into a single view, or bringing creative projects to life.
We’re shipping 3.1 Pro across our consumer and developer products to bring this underlying leap in intelligence to your everyday applications right away.
Jeff Dean also highlighted ARC-AGI-2 along with some cool animations, an urban planning sim, some heat transfer analysis and the general benchmarks.
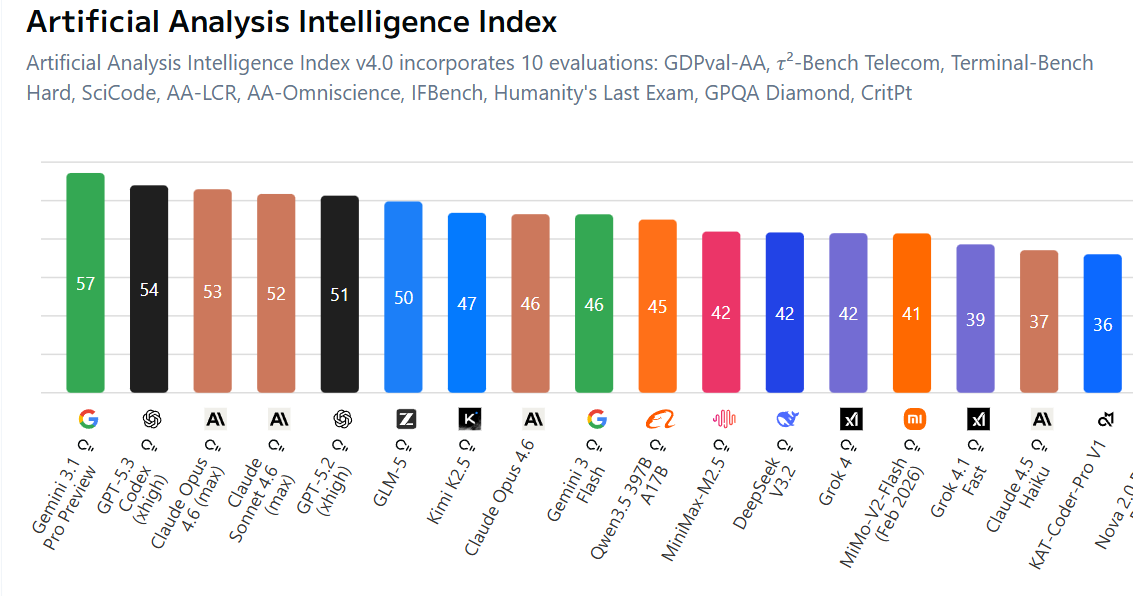
Gemini to push the Pareto Frontier of performance and efficiency
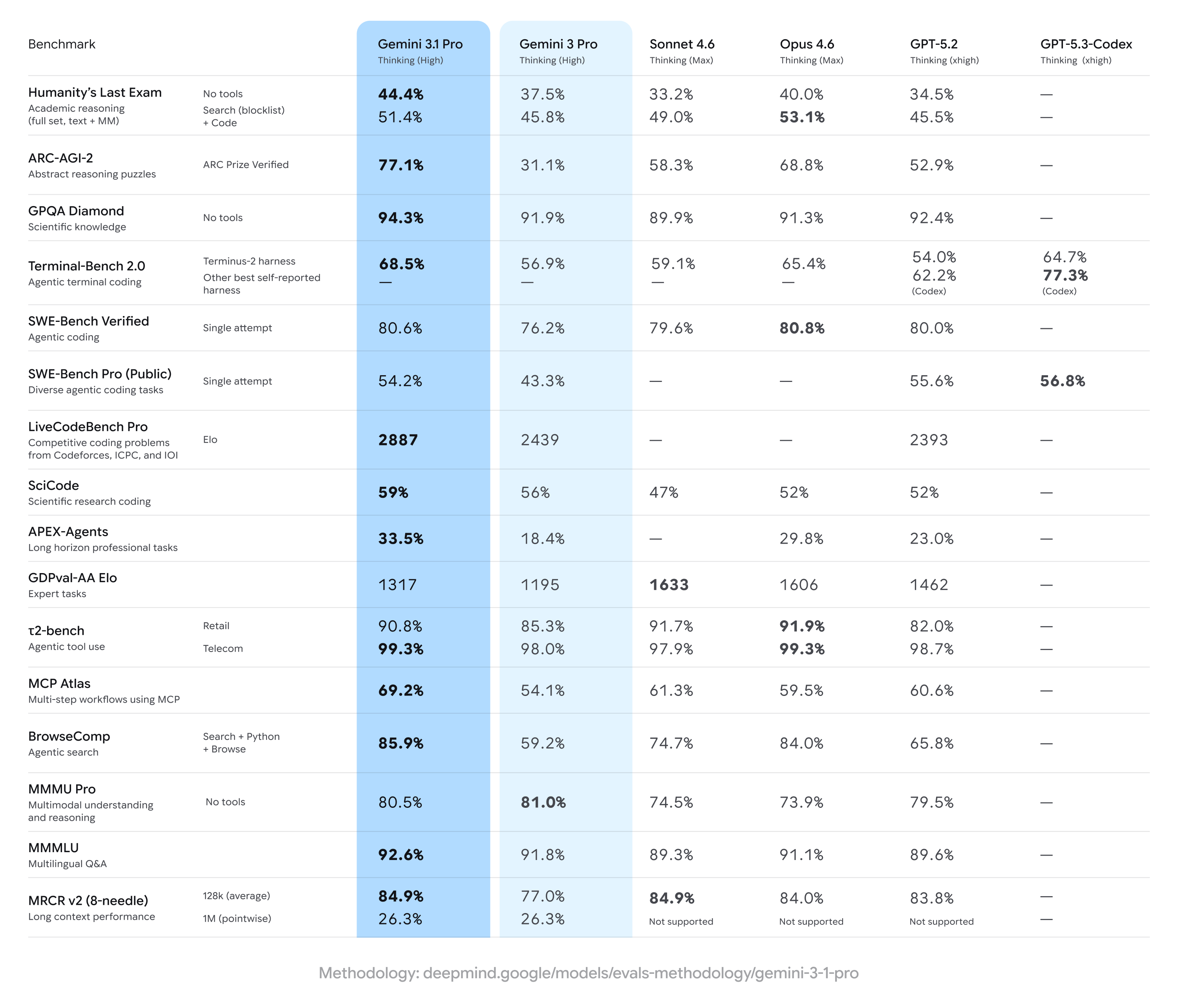
The highlight here is covering up Claude Opus 4.6, which is in the mid-60s for a cost modestly above Gemini 3.1 Pro.
Gemini 3.1 Pro overall looks modestly better on these evals than Opus 4.6.
The official announcement doesn’t give us much else. Here’s a model. Good scores.
The model card is thin, but offers modestly more to go on.
Gemini: Gemini 3.1 Pro is the next iteration in the Gemini 3 series of models, a suite of highly intelligent and adaptive models, capable of helping with real-world complexity, solving problems that require enhanced reasoning and intelligence, creativity, strategic planning and making improvements step-by-step. It is particularly well-suited for applications that require:
agentic performance
advanced coding
long context and/or multimodal understanding
algorithmic development
Their mundane safety numbers are a wash versus Gemini 3 Pro.
Their frontier safety framework tests were run, but we don’t get details. All we get is a quick summary that mostly is ‘nothing to see here.’ The model reaches several ‘alert’ thresholds that Gemini 3 Pro already reached, but no new ones. For Machine Learning R&D and Misalignment they report gains versus 3 Pro and some impressive results (without giving us details), but say the model is too inconsistent to qualify.
It’s good to know they did run their tests, and that they offer us at least this brief summary of the results. It’s way better than nothing. I still consider it rather unacceptable, and as setting a very poor precedent. Gemini 3.1 is a true candidate for a frontier model, and they’re giving us quick summaries at best.
A few of the benchmarks I typically check don’t seem to have tested 3.1 Pro. Weird. But we still have a solid set to look at.
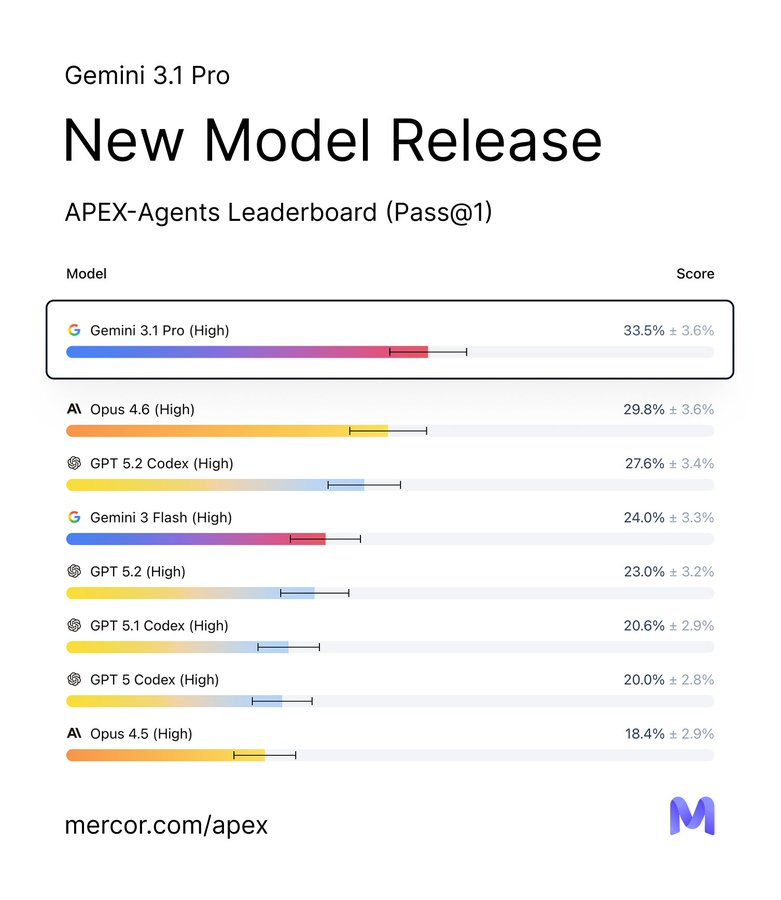
Mercor: Gemini 3.1 Pro completes 5 tasks that no model has been able to do before. It also tops the banking and consulting leaderboards – beating out Opus 4.6 and ChatGPT 5.2 Codex, respectively. Gemini 3 Flash still holds the top spot on our APEX Agents law leaderboard with a 0.9% lead. See the latest APEX-Agents leaderboard.
It turns out to be a runtime configuration of Gemini 3.1 Pro, which explains how the benchmarks were able to make such large jumps.
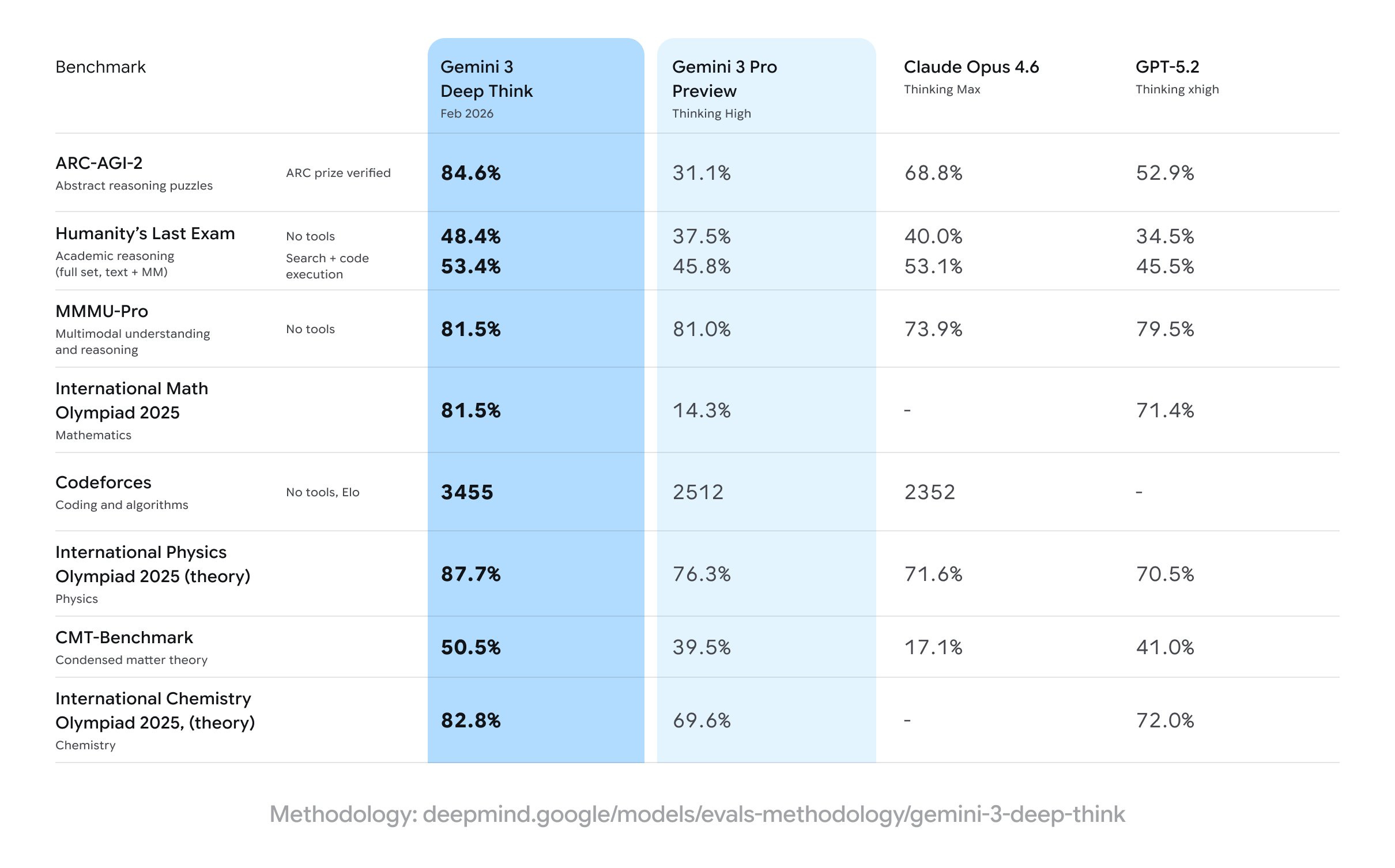
Google: Today, we updated Gemini 3 Deep Think to further accelerate modern science, research and engineering.
With 84.6% on ARC-AGI-2 and a new standard on Humanity’s Last Exam, see how this specialized reasoning mode is advancing research & development
Google: Gemini 3 Deep Think hits benchmarks that push the frontier of intelligence.
By the numbers: 48.4% on Humanity’s Last Exam (without tools) 84.6% on ARC-AGI-2 (verified by ARC Prize Foundation) 3455 Elo score on Codeforces (competitive programming)
The new Deep Think is now available in the Gemini app for Google AI Ultra subscribers and, for the first time, we’re also making Deep Think available via the Gemini API to select researchers, engineers and enterprises. Express interest in early access here.
Those are some pretty powerful benchmark results. Let’s check out the safety results.
What do you mean, we said at first? There are no safety results?
Nathan Calvin: Did I miss the Gemini 3 Deep Think system card? Given its dramatic jump in capabilities seems nuts if they just didn’t do one.
There are really bad incentives if companies that do nothing get a free pass while cos that do disclose risks get (appropriate) scrutiny
After they corrected their initial statement, Google’s position is that they don’t technically see the increased capability of V2 as imposing Frontier Safety Framework (FSF) requirements, but that they did indeed run additional safety testing which they will share with us shortly.
I am happy we will got this testing, but I find the attempt to say it is not required, and the delay in sharing it, unacceptable. We need to be praising Anthropic and also OpenAI for doing better, even if they in some ways fell short, and sharply criticizing Google for giving us actual nothing at time of release.
It was interesting to see reacts like this one, when we believed that V2 was based on 3.0 with a runtime configuration with superior scaffolding, rather than on 3.1.
Noam Brown (OpenAI): Perhaps a take but I think the criticisms of @GoogleDeepMind ‘s release are missing the point, and the real problem is that AI labs and safety orgs need to adapt to a world where intelligence is a function of inference compute.
… The corollary of this is that capabilities far beyond Gemini 3 Deep Think are already available to anyone willing to scaffold a system together that uses even more inference compute.
… Most Preparedness Frameworks were developed in ~2023 before the era of effective test-time scaling. But today, there is a massive difference on the hardest evals between something like GPT-5.2 Low and GPT-5.2 Extra High.
… In my opinion, the proper solution is to account for inference compute when measuring model capabilities. E.g., if one were to spend $1,000 on inference with a really good scaffold, what performance could be expected on a benchmark? ARC-AGI has already adopted this mindset but few other benchmarks have.
… If that were the norm, then indeed releasing Deep Think probably would not result in a meaningful safety change compared to Gemini 3 Pro, other than making good scaffolds more easily available to casual users.
The jump in some benchmarks for DeepThink V2 is very large, so it makes more sense in retrospect it is based on 3.1.
When I thought the difference was only the scaffold, I wrote:
If the scaffold Google is using is not appreciably superior to what one could already do, then it was necessary to test Gemini 3 Pro against this type of scaffold when it was first made available, and it is also necessary to test Claude or ChatGPT this way.
If the scaffold Google is using is appreciably superior, it needs its own tests.
I’d also say yes, a large part of the cost of scaling up inference is figuring out how to do it. If you make it only cost $1,000 to spend $1,000 on a query, that’s a substantial jump in de facto capabilities available to a malicious actor, or easily available to the model itself, and so on.
Like it or not, our safety cases are based largely on throwing up Swiss cheese style barriers and using security through obscurity.
That seems right for a scaffold-only upgrade with improvements of this magnitude.
The V2 results look impressive, but most of the gains were (I think?) captured by 3.1 Pro without invoking V2. It’s hard to tell because they show different benchmarks for V2 versus 3.1. The frontier safety reports say that once you take the added cost of V2 into account, it doesn’t look more dangerous than the 3.1 baseline.
That suggests that V2 is only the right move when you need its ‘particular set of skills,’ and for most queries it won’t help you much.
It does seem good at visual presentation, which the official pitches emphasized.
Junior García: Gemini 3.1 Pro is insanely good at animating svgs
internetperson: i liked its personality from the few test messages i sent. If its on par with 4.6/5.3, I might switch over to gemini just because I don’t like the personality of opus 4.6
it’s becoming hard to easily distinguish the capabilties of gpt/claude/gemini
This is at least reporting improvement.
Eleanor Berger: Finally capacity improved and I got a chance to do some coding with Gemini 3.1 pro. – Definitely very smart. – More agentic and better at tool calling than previous Gemini models. – Weird taste in coding. Maybe something I’ll get used to. Maybe just not competitive yet for code.
Aldo Cortesi: I’ve now spent 5 hours working with Gemini 3.1 through Gemini CLI. Tool calling is better but not great, prompt adherence is better but not great, and it’s strictly worse than either Claude or Codex for both planning and implementation tasks.
I have not played carefully with the AI studio version. I guess another way to do this is just direct API access and a different coding harness, but I think the pricing models of all the top providers strongly steer us to evaluating subscription access.
Eyal Rozenman: It is still possible to use them in an “oracle” mode (as Peter Steinberger did in the past), but I never did that.
Medo42: In my usual quick non-agentic tests it feels like a slight overall improvement over 3.0 Pro. One problem in the coding task, but 100% after giving a chance to correct. As great at handwriting OCR as 3.0. Best scrabble board transcript yet, only two misplaced tiles.
Ask no questions, there’s coding to do.
Dominik Lukes: Powerful on one shot. Too wilful and headlong to trust as a main driver on core agentic workflows.
That said, I’ve been using even Gemini 3 Flash on many small projects in Antigravity and Gemini CLI just fine. Just a bit hesitant to unleash it on a big code base and trust it won’t make changes behind my back.
Having said that, the one shot reasoning on some tasks is something else. If you want a complex SVG of abstract geometric shapes and are willing to wait 6 minutes for it, Gemini 3.1 Pro is your model.
Ben Schulz: A lot of the same issues as 3.0 pro. It would just start coding rather than ask for context. I use the app version. It is quite good at brainstorming, but can’t quite hang with Claude and Chatgpt in terms of theoretical physics knowledge. Lots of weird caveats in String theory and QFT or QCD.
Good coding, though. Finds my pipeline bugs quickly.
typebulb: Gemini 3.1 is smart, quickly solving a problem that even Opus 4.6 struggled with. Also king of SVG. But then it screwed up code diffs, didn’t follow instructions, made bad contextual assumptions… Like a genius who struggles with office work.
Also, their CLI is flaky as fuck.
Similar reports here for noncoding tasks. A vast intelligence with not much else.
Petr Baudis: Gemini-3.1-pro may be a super smart model for single-shot chat responses, but it still has all the usual quirks that make it hard to use in prod – slop language, empty responses, then 10k “nDone.” tokens, then random existential dread responses.
Google *stillcan’t get their post-train formal rubrics right, it’s mind-boggling and sad – I’d love to *usethe highest IQ model out there (+ cheaper than Sonnet!).
Leo Abstract: not noticeably smarter but better able to handle large texts. not sure what’s going on under the hood for that improvement, though.
I never know whether to be impressed by UI generation. What, like it’s hard?
The most basic negative feedback is when Miles Brundage cancels Google AI Ultra. I do have Ultra, but I would definitely not have it if I wasn’t writing about AI full time, I almost never use it.
One form of negative feedback is no feedback at all, or saying it isn’t ready yet, either the model not ready or the rollout being botched.
Dusto: It’s just the lowest priority of the 3 models sadly. Haven’t had time to try it out properly. Still working with Opus-4.6 and Codex-5.3, unless it’s a huge improvement on agentic tasks there’s just no motivation to bump it up the queue. Past experiences haven’t been great
Kromem: I’d expected given how base-y 3 was that we’d see more cohesion with future post-training and that does seem to be the case.
I think they’ll be really interesting in another 2 generations or so of recursive post-training.
Eleanor Berger: Google really messed up the roll-out so other than one-shotting in the app, most people didn’t have a chance to do more serious work with it yet (I first managed to complete an agentic session without constantly running into API errors and rate limits earlier today).
Or the perennial favorite, the meh.
Piotr Zaborszczyk: I don’t really see any change from Gemini 3 Pro. Maybe I didn’t ask hard enough questions, though.
They’re claiming can outperform Gemini 2.5 Flash on many tasks.
My Chrome extension uses Flash-Lite, actually, for pure speed, so this might end up being the one I use the most. I probably won’t notice much difference for my purposes, since I ask for very basic things.
And that’s basically a wrap. Gemini 3.1 Pro exists. Occasionally maybe use it?
The petition cited research suggesting that in the US airline industry, some “mergers increased fares not only on overlap routes but also on non-overlap routes.”
Charter/Cox competition not entirely nonexistent
The petition also quoted comments from the California Public Utilities Commission’s Public Advocates Office, which said that Charter and Cox do compete against each other directly in parts of their territories. The California Public Advocates Office submitted a protest in the state regulatory proceeding in September 2025, writing:
The Joint Applicants claim that Charter and Cox have no, or very few, overlapping locations, so the Proposed Transaction will not harm competition. However, FCC broadband data show that Charter and Cox California have 25,503 overlapping locations. At 16,485 of these locations (65%), Charter and Cox California are the only two providers offering speeds of at least 1,000 Mbps download.
If the Proposed Transaction is approved, customers in those areas will have access to only a single provider for high-speed service and will have no meaningful choice between providers. Finally, Charter is already the sole provider of gigabit service in 48% of its service area, while Cox is the sole provider in 65% of its service area. Consolidating these footprints would significantly expand Charter’s monopoly power in the high-speed fixed broadband market.
Public Knowledge Legal Director John Bergmayer said that the Carr FCC “did not require Charter to do anything it wasn’t already planning to do.” He said this is in stark contrast to the FCC’s 2016 approval of Charter’s merger with Time Warner Cable, which allowed Charter to become the second biggest cable company in the US.
“In 2016, the commission approved Charter’s acquisition of Time Warner Cable only after imposing conditions on data caps, usage-based pricing, and paid interconnection,” Bergmayer said on Friday. “Today’s order finds those concerns no longer apply, largely because the agency credits fixed wireless and satellite as competitive constraints on cable. Further, the Commission imposed no affordability conditions, despite doing so in the 2016 Charter, Comcast-NBCU, and Verizon-TracFone transactions. The record does not support this outcome.”
Disclosure: The Advance/Newhouse Partnership, which owns 12 percent of Charter, is part of Advance Publications, which owns Ars Technica parent Condé Nast.
Though the rules are among the strictest in the US, locals say they aren’t enough.
A rendering of the QTS data center currently under construction in Cedar Rapids, Iowa. Credit: QTS
PALO, Iowa—There are two restaurants in Palo, not counting the chicken wings and pizza sold at the only gas station in town.
All three establishments, including the gas station, stand on the same half-mile stretch of First Street, an artery that divides the marshy floodplain of the Cedar River to the east from hundreds of acres of cornfields on the west.
During historic flooding in 2008, the Cedar River surged 10 feet above its previous record, cresting at 31 feet and wiping out homes and businesses well outside the floodplain.
Nearly 20 years later, those structures have been rebuilt, but Palo residents still worry about the river. Except these days, they worry that data centers will drink it dry.
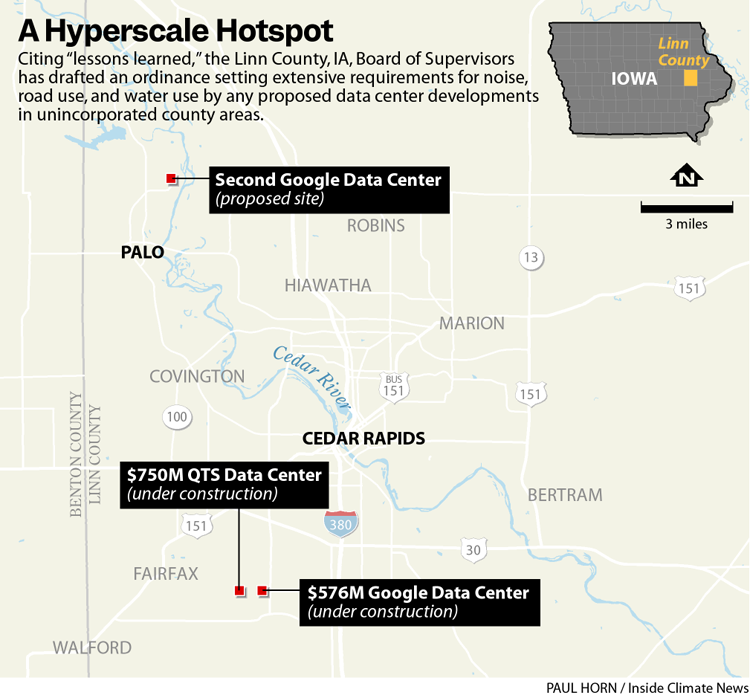
In an effort to shield residents and natural resources from the negative impacts of hyperscale data center development in rural Linn County, officials have adopted what may be one of the most comprehensive local data center zoning ordinances in the nation.
The new ordinance requires data center developers to conduct a comprehensive water study as part of their zoning application and to enter into a water-use agreement with the county before construction. It also places limits on noise and light pollution, introduces mandatory setbacks of 1,000 feet from residentially zoned property, and requires developers to compensate the county for damage to roads or infrastructure during construction and to contribute to a community betterment fund.
“We are trying to put together the most protective, transparent ordinance possible,” Kirsten Running-Marquardt, chair of the Linn County Board of Supervisors, told the nearly 100 residents who gathered for the draft ordinance’s first public reading in early February.
But seated beneath a van-sized American flag hanging from the rafters of the drafty Palo Community Center gymnasium, residents asked for even stronger protections.
One by one, they approached the microphone at the front of the gym to voice concerns about water use, electricity rates, light pollution, the impacts of low-frequency noise on livestock, and the county’s ability to enforce the terms of the ordinance. Some, including Dorothy Landt of Palo, called for a complete moratorium on new data center development.
“Why has Linn County, Iowa, become a dumping ground for soon-to-be obsolete technology that spoils our landscape and robs us of our resources?” Landt asked. “While I admire the efforts of the Board of Supervisors to propose a data center ordinance, I would prefer to see all future data centers banned from Linn County.”
The county is already home to two major data center projects, operated by Google and QTS. Both are located in Cedar Rapids, Iowa’s second-largest city, and are therefore subject to its laws. The new ordinance would apply only to unincorporated areas of the county, which make up more than two-thirds of its geographic footprint.
In October 2025, Google informed the Linn County Board of Supervisors of early plans to construct a six-building campus in Palo, part of unincorporated Linn County, alongside the soon-to-reopen Duane Arnold Energy Center, Iowa’s sole nuclear power plant. Later that month, Google signed a 25-year power purchase agreement with the plant, committing to buy the bulk of the electricity it generates.
A view of the Duane Arnold Energy Center in Palo, Iowa.
Credit: NextEra Energy
A view of the Duane Arnold Energy Center in Palo, Iowa. Credit: NextEra Energy
Google has not yet submitted a formal application to the county for the second campus, but its announcement last year, as well as interest from another, unnamed, hyperscale data company, prompted Linn County officials to begin work on an ordinance setting the terms for any new development, said Charlie Nichols, director of planning and development for Linn County.
“I just don’t want to be misled by anything. … I want to know as much as possible before we go ahead with this,” Sue Biederman of Cedar Rapids told supervisors at the public meeting in February.
In drafting the ordinance, Nichols and his staff drew on the experiences of communities nationwide, meeting with local government officials in regions that have seen massive booms in data center development, including several counties in northern Virginia, the “data center capital of the world.”
As data center development balloons, many communities that initially zoned the operations as warehouses or standard commercial users are abandoning that practice, Nichols noted.
The extreme energy and water demands of data centers simply cannot be accounted for by existing zoning frameworks, he said. “These are generational uses with generational infrastructure impacts, and treating them as a normal warehouse or normal commercial user is just not working.”
Loudoun County, Virginia, for example, is home to 198 data centers, nearly all of which were built before the county required conditional or “special exception” use designations for data centers. At the urging of hyperscale-weary residents, the county is now in the second phase of a plan to establish data-center-specific zoning standards.
Similar reassessments are taking place across the country, Chris Jordan, program manager for AI and innovation at the National League of Cities, wrote in an email to Inside Climate News. “We’re seeing tighter zoning standards, more required impact studies, and in some cases temporary moratoria while communities assess infrastructure capacity,” Jordan wrote.
The Linn County, Iowa, ordinance goes one step further than tightening existing zoning rules. Instead, it creates a new, exclusive-use zoning district for data centers, granting county officials the power to set specific application requirements and development standards for projects.
Residents of Linn County, Iowa, gather at the Palo Community Center on Feb. 4 to comment on a draft of a new data center ordinance.
Credit: Anika Jane Beamer/Inside Climate News
Residents of Linn County, Iowa, gather at the Palo Community Center on Feb. 4 to comment on a draft of a new data center ordinance. Credit: Anika Jane Beamer/Inside Climate News
No other counties in the state have introduced similar zoning requirements, said Nichols. In fact, few jurisdictions nationwide have.
“Linn County’s approach is more comprehensive than many local zoning updates we’ve seen,” Jordan wrote. The creation of a data center-specific district, especially one that requires formal water-use agreements and economic development agreements, goes further than typical zoning amendments for data centers, Jordan said.
Despite the layers of protection baked into the new ordinance, Linn County still has limited ability to protect local water resources. Without a municipal water utility, permitting in rural Iowa communities falls to the state Department of Natural Resources (DNR), explained Nichols. Similarly, electric rates fall under the jurisdiction of the state utilities commission and cannot be regulated by the county.
Data centers may tap rivers or drill deep wells into shared aquifers, so long as that use complies with the terms of their water-use permit from the Iowa DNR. That leaves the Cedar River and public and private wells, which provide drinking water to much of Linn County, vulnerable.
“We know that we can have multi-year droughts. The question is, are we depleting that river and the water table faster than it’s running?” Leland Freie, a Linn County resident, told supervisors at the first public meeting on the ordinance.
Without superseding state authority, the Linn County ordinance attempts to claw back a bit more local control, Nichols explained.
As part of their zoning application, data centers would submit a study “prepared by a qualified professional” assessing the capacity of proposed water sources, anticipating demands and cooling technologies, and developing contingency plans in case the water supply is interrupted.
Credit: Inside Climate News
Credit: Inside Climate News
Requiring a water study ensures, at a minimum, a baseline understanding of local water resources and dynamics near proposed data centers. That’s something the state of Iowa generally lacks, said Cara Matteson, a former geologist and the sustainability director for Linn County.
DNR staff told Matteson that water data gathered in Linn County by qualified researchers on behalf of a data center applicant would be incorporated in state-level permitting and enforcement decisions.
The department confirmed in an email to Inside Climate News that it would use the additional local water data.
If a data center’s application is approved, developers would then enter into an agreement with Linn County, outlining terms for water-use monitoring and reporting to both the county and the DNR. The agreement could also include contingency plans for droughts.
Still, the county has limited ability to act on the water monitoring data it’s seeking. The DNR doesn’t just issue water-use permits; it also issues penalties for permit violations.
Linn County’s zoning rule underwent several modifications in response to questions raised by attendees at the first two public readings, Nichols said.
From its first reading to final adoption, the ordinance has expanded to include language setting light pollution standards, requiring a waste management plan, including the Iowa DNR in the water-use agreement to address potential well interference issues, and requiring an applicant-led public meeting before any zoning commission meetings.
“I am very confident that no ordinance for data centers in Iowa is asking for more information or asking for more requirements to be met than our ordinance right now,” said Nichols at the final reading.
The Cedar Rapids Metro Economic Alliance has said that it strongly supports current and future data center development in the area. The new ordinance is not an effective moratorium, Nichols said. He said he “strongly believes” that a data center can be built within the adopted framework.
Google spokespeople did not respond to requests for comment.
New rules may prompt data centers to develop elsewhere, acknowledged Brandy Meisheid, a supervisor whose district includes many of Linn County’s smaller communities. But the ordinance sets out to protect residents, not developers, Meisheid said. “If it’s too high a price for them to pay, they don’t have to come.”
Anika Jane Beamer covers the environment and climate change in Iowa, with a particular focus on water, soil, and CAFOs. A lifelong Midwesterner, she writes about changing ecosystems from one of the most transformed landscapes on the continent. She holds a master’s degree in science writing from the Massachusetts Institute of Technology as well as a bachelor’s degree in biology and Spanish from Grinnell College. She is a former Outrider Fellow at Inside Climate News and was named a Taylor-Blakeslee Graduate Fellow by the Council for the Advancement of Science Writing.
Smart underwear measures farts, brain cells play Doom, and AI discovers rules of an ancient game.
Illustration of a star that collapsed, forming a black hole. Credit: Keith Miller, Caltech/IPAC – SELab
It’s a regrettable reality that there is never enough time to cover all the interesting scientific stories we come across each month. So every month, we highlight a handful of the best stories that nearly slipped through the cracks. February’s list includes the revival of a forgotten battery design by Thomas Edison that could be ideal for renewable energy storage; a snap-on device to turn those boxers into “smart underwear” to measure how often we fart; and a dish of neurons playing Doom, among other highlights.
Reviving Edison’s battery design
Credit: Maher El-Kady/UCLA
Credit: Maher El-Kady/UCLA
At the onset of the 20th century, electric cars powered by lead-acid batteries outnumbered gas-powered cars. The internal combustion engine ultimately won out, in part because those batteries had a range of just 30 miles. But Thomas Edison believed a nickel-iron battery could extend that range to as much as 100 miles, while also having a long life and recharging times of seven hours. An international team of scientists has revived Edison’s concept of a nickel-iron battery and created their own version, according to a paper published in the journal Small.
The team took their inspiration from nature, specifically how shellfish form their hard outer shells and animals form bones: Proteins create a scaffolding onto which calcium compounds cluster. For the battery scaffolding, the authors used beef byproduct proteins, combined with graphene oxide, and then grew clusters of nickel for positive electrons and iron for negative ones. The team superheated all the ingredients in water followed by baking them at very high temperatures. The proteins charred into carbon, stripping away the oxygen atoms in the graphene oxide and embedding the nickel and iron clusters in the scaffolding. Essentially, it became an aerogel.
The folded structure limited the clusters to less than 5 nanometers, translating into significantly more surface area for the chemical reactions fueling the battery to occur. The resulting prototype recharged in mere seconds and endured for more than 12,000 cycles, equivalent to about 30 years of daily recharging. However, their battery’s storage capacity is still well below that of current lithium-ion batteries, so powering EVs might not be the most promising application. The authors suggest it might be ideal for storing excess electricity generated by solar farms or other renewable energy sources.
In 2014, NASA’s NEOWISE project picked up a gradual brightening of infrared light coming from a massive star in the Andromeda galaxy, an observation that was confirmed by several other ground- and space-based telescopes. Astronomers kept monitoring the star, so they also noticed when it quickly dimmed in 2016. Once one of the brightest stars in that galaxy, it effectively “vanished” from sight; it would be like Betelgeuse suddenly disappearing. It’s now only detectable in the mid-infrared range.
The obvious explanation was that the star was dying and had collapsed into a black hole, but if so, it didn’t go through the supernova phase that usually occurs with stars of this size. That makes it an intriguing object for further study. After analyzing archival data from NEOWISE, a team of astronomers concluded that this was indeed a case for direct collapse, according to a paper published in the journal Science.
Theoretical work from the 1970s provided a possible explanation. As gravity begins to collapse the star, and the core first forms a dense neutron star, the accompanying burst of neutrinos typically creates a powerful shock wave strong enough to rip apart the core and outer layers, leading to a supernova. But some theorists suggested that the shock wave might not always be powerful enough to expel all that stellar material, which instead falls inward, and the baby neutron star directly collapses into a black hole without ever going supernova.
Convection, it seems, is key. It occurs because the matter near the star’s center is hotter than the outer regions, so the gases move from hotter to cooler regions. The authors of this latest paper suggest that as the core collapses, gas in the outer layers is moving rapidly, which prevents them from falling into the core. The inner layers orbit outside the new black hole and eject the outer layers, which cool and form dust to hide the hot gas still orbiting the black hole. The dust warms in response into mid-infrared wavelengths, giving the object a slight glow that should last for decades.
This work has already led the team to re-evaluate a similar star first observed a decade ago, so this may constitute a new class of objects—ones that are harder to detect because they don’t go supernova and because of the faintness of the afterglow. At least now astronomers know to look for that distinctive signature.
Let’s face it, everybody farts, and those suffering from conditions that produce excess gas fart more than most. But physicians don’t have a reliable means of quantifying just how much gas people produce each day. In other words, they lack a baseline of what is normal—like we have for blood glucose or cholesterol—which makes it difficult to determine whether the farting in any given case is excessive. To address this, scientists at the University of Maryland have devised “smart underwear” to measure the wearer’s flatulence, according to a paper published in the journal Biosensors and Bioelectronics.
Brantley Hall and his cohorts developed a small device with electrochemical sensors that snaps onto one’s underwear; those sensors track any emitted farts around the clock, including as the wearer sleeps. In the past, fart frequency relied on small studies using invasive methods or unreliable self-reports. So perhaps it’s not surprising that Hall et al. recorded much higher farting estimates in their study: healthy adults pass gas on average 32 times per day, compared to just 14 times per day reported in past studies.
There was also considerable variation among individuals, with a lowest fart rate of just four times per day and a highest rate of 59 per day. This is a first step to determining a healthy baseline, which the team hopes to do via their Human Flatus Atlas program. People can volunteer to don the smart underwear 24/7 in hopes of correlating the flatulence patterns with diet and microbiome composition across a much larger sample size. You can enroll in the Human Flatus Atlas here; you must live in the US and be 18 years or older to participate. (Fun bonus fact: noted gastroenterologist Michael Levitt was apparently known as the “King of Farts” because of his extensive body of research on the subject.)
Just past Neptune lies the Kuiper Belt, a band littered with remnants from the early formative period of our Milky Way, including dwarf planets and smaller bodies known as planetesimals. Roughly 10 percent of those planetesimals consist of two connected spheres resembling a rudimentary snowman, called contact binaries. In a paper published in the Monthly Notices of the Royal Astronomical Society, Michigan State University researchers reported evidence for a process by which these contact binaries may have formed.
Planetesimals are the result of dust and pebbles gradually packing together into aggregate objects in response to gravity, much like forming a snowball. Every now and then, these nascent objects get ripped in two by the rotating cloud and form two separate planetesimals that orbit each other. Most theories of how the unusual snowman-shaped contact binaries formed rely on rare events or exotic phenomena, which would not account for the large number of contact binaries that we observe.
Prior computational simulations modeled colliding objects in the Kuiper Belt as fluid-like blobs that merged into spheres, but this did not result in conditions conducive to forming the snowman configuration. These new simulations retained the colliding objects’ strength and allowed them to rest against each other. This revealed that after two colliding planetesimals begin to orbit one another, gravity causes them to spiral inward until they eventually make contact and fuse. Because the Kuiper Belt is relatively empty, it is rare for the contact binaries to crash into another object, so they are less likely to break apart.
There is archaeological evidence for various kinds of board games from all over the world dating back millennia: Senet and Mehen in ancient Egypt, for example; a strategy game called ludus latrunculorum (“game of mercenaries”) favored by Roman legions; a 4,000-year-old stone board discovered in 2022 that just might be a precursor to an ancient Middle Eastern game known as the Royal Game of Ur; or a Bronze Age board game that might be the earliest form of Hounds and Jackals, originating in Asia, which challenges the longstanding assumption that the game originated in Egypt.
There may be other ancient games that archaeologists still don’t know about, nor is it always possible for them to tease out what the rules of play might be. AI is emerging as a useful tool for determining the latter. Most recently, researchers have used AI tools to work out the rules of what they believe might be another ancient Roman game board, according to a paper published in the journal Antiquity. The object in question is a flat stone housed in the Roman Museum in Heerlen, the Netherlands, with a distinctive geometric pattern carved on one side. Walter Crist of Leiden University noticed some visibly uneven wear consistent with pushing stone game pieces across the surface, with the most wear along one particular diagonal line.
Crist thought this might be a Roman game board and decided to pit two AI agents against each other in thousands of “games” to test different variations in possible rules, gleaned from known ancient board games from around the world. Crist and his co-authors identified nine possibilities, all so-called blocking games, in which a player with more pieces tries to stop their opponent from moving. They have dubbed this potentially new game Ludos Coriovalli. There is not yet any means of knowing for sure, since no other carved slabs with that particular pattern have been found, but it might be a prototype game, per Crist.
In 2022, a company called Cortical Labs managed to get brain cells grown in a dish—dubbed DishBrain—electrically stimulated in such a way as to create useful feedback loops, enabling them to “learn” to play Pong, albeit badly. This provided intriguing evidence that neural networks formed from actual neurons spontaneously develop the ability to learn. Now the company is back with a video (see above) showing DishBrain playing Doom—technically the open-sourced Freedoom, which lacks some of the copyrighted demon and weapon elements.
Like four years ago, we’re talking about a dish with a set of electrodes on the floor. When neurons are grown in the dish, these electrodes can do two things: sense the activity of the neurons above them or stimulate those electrodes. But the team has added a new interface that makes the system easier to program, using Python. Teaching DishBrain to play Pong took years of painstaking effort; getting it to play Freedoom took just one week—a significant improvement.
DishBrain still can’t come close to matching the performance of the best Doom players, but it learned faster than conventional silicon-based machine learning. But it’s also not comparable to a human brain. “Yes, it’s alive, and yes, it’s biological, but really what it is being used as is a material that can process information in very special ways that we can’t re-create in silicon,” Brett Kagan of Cortical Labs told New Scientist. In fact, in 2024, scientists taught hydrogels—soft, flexible biphasic materials that swell but do not dissolve in water—to play Pong, inspired by the company’s earlier research. (Hydrogels can also “learn” to beat in rhythm with an external pacemaker, just like living cells.)
Jennifer is a senior writer at Ars Technica with a particular focus on where science meets culture, covering everything from physics and related interdisciplinary topics to her favorite films and TV series. Jennifer lives in Baltimore with her spouse, physicist Sean M. Carroll, and their two cats, Ariel and Caliban.
“There were assumptions that were made in the strategy that obviously didn’t come to fruition.”
An unarmed Minuteman III missile launches during an operational test at Vandenberg Air Force Base, California, on September 2, 2020. Credit: US Air Force
DENVER—The US Air Force’s new Sentinel intercontinental ballistic missile is on track for its first test flight next year, military officials reaffirmed this week.
But no one is ready to say when hundreds of new missile silos, dug from the windswept Great Plains, will be finished, how much they cost, or, for that matter, how many nuclear warheads each Sentinel missile could actually carry.
The LGM-35A Sentinel will replace the Air Force’s Minuteman III fleet, in service since 1970, with the first of the new missiles due to become operational in the early 2030s. But it will take longer than that to build and activate the full complement of Sentinel missiles and the 450 hardened underground silos to house them.
Amid the massive undertaking of developing a new ICBM, defense officials are keeping their options open for the missile’s payload unit. Until February 5, the Air Force was barred from fitting ballistic missiles with Multiple Independently targetable Reentry Vehicles (MIRVs) under the constraints of the New START nuclear arms control treaty cinched by the US and Russia in 2010. The treaty expired three weeks ago, opening up the possibility of packaging each Sentinel missile with multiple warheads, not just one.
Senior US military officials briefed reporters on the Sentinel program this week at the Air and Space Forces Association’s annual Warfare Symposium near Denver. There was a lot to unpack.
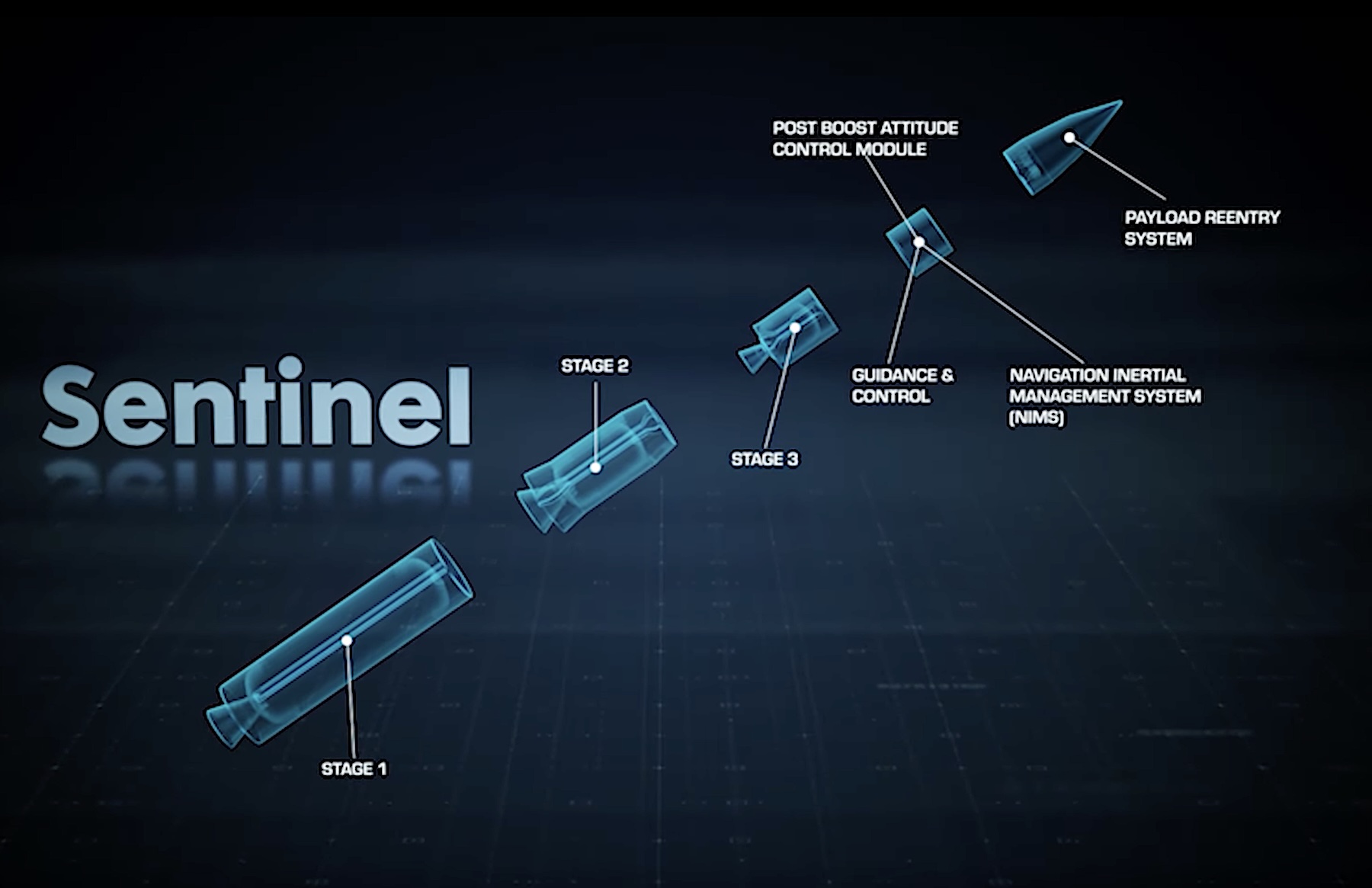
This cutaway graphic shows the major elements of the Sentinel missile.
Credit: Northrop Grumman
This cutaway graphic shows the major elements of the Sentinel missile. Credit: Northrop Grumman
Into the breach
Two years ago, the Air Force announced the Sentinel program’s budget had grown from $77.7 billion to nearly $141 billion. This was after something known as a “Nunn-McCurdy breach,” referring to the names of two lawmakers behind legislation mandating reviews for woefully overbudget defense programs. In 2024, the Pentagon determined that the Sentinel program was too essential to national security to cancel.
“We’ve gotten all the capability that we can out of the Minuteman,” said Gen. Stephen “S.L.” Davis, commander of Air Force Global Strike Command. Potential enemy threats to the Minuteman ICBM have “evolved significantly” since its initial deployment in the Cold War, Davis said.
The $141 billion figure is already out of date, as the Air Force announced last year that it would need to construct new silos for the Sentinel missile. The original plan was to adapt existing Minuteman III silos for the new weapons, but engineers determined that it would take too long and cost too much to modify the aging Minuteman facilities.
Instead, the Air Force, in partnership with contractors and the US Army Corps of Engineers, will dig hundreds of new holes across Colorado, Montana, Nebraska, North Dakota, and Wyoming. The new silos will include 24 new forward launch centers, three centralized wing command centers, and more than 5,000 miles of fiber connections to wire it all together, military and industry officials said.
Sentinel, which had its official start in 2016, will be the largest US government civil works project since the completion of the interstate highway system, and is the most complex acquisition program the Air Force has ever undertaken, wrote Sen. Roger Wicker (R-Mississippi) and Sen. Deb Fischer (R-Nebraska) in a 2024 op-ed published in the Wall Street Journal.
Gen. Dale White, the Pentagon’s director of critical major weapons systems, said Wednesday the Defense Department plans to complete a “restructuring” of the Sentinel program by the end of the year. Only then will an updated budget be made public.
“It’s been a very, very long time since we’ve done this,” White said. “At the very core, there were assumptions that were made in the strategy that obviously didn’t come to fruition.”
“We’re not reusing the Minuteman III silos, but at the same time that obviously gives much greater operational flexibility to the combatant commander,” White said. “So, we had to take a step back and have a more enduring look at what we were trying to do, what capability is needed, making sure we do not have a gap in capability.”
341st Missile Maintenance Squadron technicians connect a reentry system to a spacer on an intercontinental ballistic missile during a Simulated Electronic Launch-Minuteman test September 22, 2020, at a launch facility near Great Falls, Montana.
Credit: US Air Force photo by Senior Airman Daniel Brosam
341st Missile Maintenance Squadron technicians connect a reentry system to a spacer on an intercontinental ballistic missile during a Simulated Electronic Launch-Minuteman test September 22, 2020, at a launch facility near Great Falls, Montana. Credit: US Air Force photo by Senior Airman Daniel Brosam
Decommissioning the Minuteman III silos will come with its own difficulties. An Air Force official said on background that commanders recently took one Minuteman silo off alert to better gauge how long it will take to decommission each location. Meanwhile, Northrop Grumman, Sentinel’s prime contractor, broke ground on the first “prototype” Sentinel silo in Promontory, Utah, earlier this month.
The Air Force has ordered 659 Sentinel missiles from Northrop Grumman, including more than 400 to go on alert, plus spares and developmental missiles for flight testing. The first Sentinel test launch from a surface pad at Vandenberg Space Force Base, California, is scheduled for 2027.
To ReMIRV or not to ReMIRV
For the first time in more than 50 years, the world’s two largest nuclear forces have been unshackled from any arms control agreements. New START was the latest in a series of accords between the United States and Russia, and with it came the ban on MIRVs aboard land-based ICBMs. The Air Force removed the final MIRV units from Minuteman III missiles in 2014.
The Trump administration wants a new agreement that includes Russia as well as China, which was not part of New START. US officials were expected to meet with Russian and Chinese diplomats this week to discuss the topic. There’s no guarantee of any agreement between the three powers, and even if there is one, it may take the form of an informal personal accord among leaders, rather than a ratified treaty.
“The strategic environment hasn’t changed overnight, from before New START was in effect, until it has lapsed, and within our nation’s nuclear deterrent,” said Adm. Rich Correll, head of US Strategic Command. “We have the flexibility to address any adjustments to the security environment as a result of that treaty lapsing.”
This flexibility includes the option to “reMIRV” missiles to accommodate more than one nuclear warhead, Correll said. “We have the ability to do that. That’s obviously a national-level decision that would go up to the president, and those policy levers, if needed, provide additional resiliency within the capabilities that we have.”
MIRVs are more difficult for missile defense systems to counter, and allow offensive missile forces to package more ordnance in a single shot. With New START gone, there’s no longer any mechanism for international arms inspections. Russia may now also stack more nukes on its ICBMs. Gone, too, is the limitation for the United States and Russia to deploy no more than 1,550 nuclear warheads at one time.
“The expiration of this treaty is going to lead us into a world for the first time since 1972 where there are no limits on the sizes of those arsenals,” said Ankit Panda of the Carnegie Endowment for International Peace.
“I think this opens up the question of whether we’re going to be heading into a world that’s just going to be a lot more unpredictable and dangerous when you have countries like the United States and Russia that have a lot less transparency into each other’s nuclear arsenals, and fundamentally, as a result, a lot less predictability about the world that they’re operating in,” Panda continued.
Mk21 reentry vehicles on display in the Missile and Space Gallery at the National Museum of the US Air Force in Dayton, Ohio.
Credit: US Air Force
Mk21 reentry vehicles on display in the Missile and Space Gallery at the National Museum of the US Air Force in Dayton, Ohio. Credit: US Air Force
Some strategists have questioned the need for land-based ICBMs in the modern era. The locations of the Air Force’s missile fields are well known, making them juicy targets for an adversary seeking to take out a leg of the military’s nuclear triad. The stationary nature of the land-based missile component contrasts with the mobility and stealth of the nation’s bomber and submarine fleets. Also, bombers and subs can already deliver multiple nukes, something land-based missiles couldn’t do under New START.
Proponents of maintaining the triad say the ICBM missile fields serve an important, if not macabre, function in the event of the unimaginable. They would soak up the brunt of any large-scale nuclear attack. Hundreds of miles of the Great Plains would be incinerated.
“The main rationale for maintaining silo-based ICBMs is to complicate an adversary’s nuclear strategy by forcing them to target 400 missile silos dispersed throughout the United States to limit a retaliatory nuclear strike, which is why ICBMs are often referred to as the ‘nuclear sponge,’” the Center for Arms Control and Non-Proliferation wrote in 2021. “However, with the development of sea-based nuclear weapons, which are essentially undetectable, and air-based nuclear weapons, which provide greater flexibility, ground-based ICBMs have become increasingly technologically redundant.”
Policymakers in power do not agree. The ICBM program has powerful backers in Congress, and Sentinel has enjoyed support from the Obama, Biden, and both Trump administrations. The Pentagon is also developing the B-21 Raider strategic bomber and a new generation of “Columbia-class” nuclear-armed subs.
Stephen Clark is a space reporter at Ars Technica, covering private space companies and the world’s space agencies. Stephen writes about the nexus of technology, science, policy, and business on and off the planet.
Apple is taking an “ain’t broke/don’t fix” approach to most of its gadgets.
Apple’s 2018-era design for the then-Intel-powered MacBook Air. The M1 Air used largely the same design, and we expect Apple’s lower-cost MacBook to look pretty similar. Credit: Valentina Palladino
Apple’s 2018-era design for the then-Intel-powered MacBook Air. The M1 Air used largely the same design, and we expect Apple’s lower-cost MacBook to look pretty similar. Credit: Valentina Palladino
Excepting the AirTag 2, so far it’s been a quiet year for Apple hardware. But that’s poised to change next week, as the company is hosting a “special experience” on March 4.
The use of the word experience, rather than event or presentation, implies that Apple’s typical presentation format won’t apply here. And CEO Tim Cook more or less confirmed this when he posted that the company had “a big week ahead,” starting on Monday. Apple is most likely planning multiple days of product launches announced via press release on its Newsroom site, with the “experience” on Wednesday serving as a capper and a hands-on session for the media.
Apple has used a similar strategy before, spacing out relatively low-key refreshes over several days to generate sustained interest rather than dropping everything in a single 30- to 60-minute string of pre-recorded videos.
Reporting on what, exactly, Apple plans to announce has consistently centered on a small handful of specific devices, but with the exception of the iPhone 17 series, the M5 Vision Pro, and the Apple Watch, most of Apple’s major products have gone long enough without an update that anything is possible. Here’s what we consider to be the most likely, and a few other notes besides.
The long-awaited “budget” MacBook
Most rumors and leaks agree that Apple is preparing to launch a new MacBook priced well below the MacBook Air, in a style similar to the $349 iPad or the iPhone 16e. Commonly cited specs include a 13-inch-ish screen and an Apple A18 Pro chip, which debuted in the iPhone 16 Pro in 2024 and is typically packaged with 8GB of RAM. The laptop is also said to be coming in multiple colors, taking a page from the iMac and the basic iPad.
Rumors have circulated about a “cheap” MacBook purpose-built for cost-conscious buyers since the late 2000s, if not before. But none of these, if they’ve existed in Apple’s labs, have ever made it to stores, and Apple’s laptops have reliably started at around $1,000 for over 20 years.
But in the two years since removing it from its online store, Apple has used the old M1 MacBook Air design as a sort of trial balloon. Since early 2024, the laptop has only been available through Walmart in the US, with a basic 8GB of RAM and 256GB of storage. But it has been priced in the same $600 to $700 range as midrange Windows laptops and higher-end Chromebooks and has apparently done well enough to merit a true successor.
I expect Apple to follow a pattern similar to what it did when it first launched the $329 iPad in 2017, or the iPhone SE in 2016: to essentially re-use the 2020-era MacBook Air’s design and other components to the greatest degree possible.
These are already parts that Apple and its suppliers have a lot of experience manufacturing, and they’ve been around long enough that they’re probably about as inexpensive as they’re going to get. They’re also proven components that meet Apple’s usual standards for materials and build quality. If that leaves the new MacBook slightly out of step with the rest of Apple’s laptop designs, that’s a compromise the company has been willing to make in the past.
Some of the details of this system will probably be a surprise, but we can expect Apple to create some intentional distance between this MacBook and the MacBook Air, the same as it does for the low-end iPad and iPhone. The processor will be one limitation; the potential 8GB RAM ceiling, limited upgrade options, fewer and less-capable ports, and limited external display support may be others.
This thing is likely destined to be an email, browsing, and casual phone-camera-photo-editing machine for people who prefer a traditional clamshell laptop to an iPad. The $999-and-up MacBook Air will continue to be Apple’s default do-anything laptop, and the MacBook Pro will continue to occupy the “do-anything, but faster” position.
The $349 iPad
Apple’s basic $349 iPad could get an Apple Intelligence update, thanks to a processor and RAM bump.
Credit: Andrew Cunningham
Apple’s basic $349 iPad could get an Apple Intelligence update, thanks to a processor and RAM bump. Credit: Andrew Cunningham
Speaking of the Apple A18 series, Apple is apparently planning a refresh of its $349 base-model iPad that uses an A18 or possibly an A19. Assuming it still comes with 8GB of RAM—up from 6GB for the current Apple A16-powered iPad—either chip would help it clear the bar for Apple Intelligence support.
Apple doesn’t always update its basic iPad every year; in 2024, for instance, it got a price drop rather than a hardware refresh. But the A16 iPad is currently the only thing in the entire iPhone/iPad/Mac lineup without support for Apple Intelligence, a bundle of features that Apple markets pretty heavily despite their functional unevenness. That marketing campaign is likely to intensify when Apple finally releases its new Google Gemini-powered Siri update at some point this year.
Even if you don’t care about Apple Intelligence, a basic iPad with 8GB of RAM will be a win for most users, since you can use that extra RAM for all kinds of things that have nothing to do with AI. It’s the same amount of memory Apple has shipped with the iPad Air since the M1 model, and with several generations of iPad Pro. Even attached to a slower processor, this should still improve the multitasking and productivity experience on the tablet.
The iPhone 17e
Apple would let the old iPhone SE languish for at least a couple years between updates, but it’s apparently taking a different tack with the “e” iPhones.
The main star of this refresh is a new chip, which will supposedly be upgraded from an Apple A18 to an A19. It’s also said to be picking up MagSafe charging support, making it compatible with Apple-made and third-party accessories that magnetically clamp to the back of other iPhones.
Other than that, the rumor mill suggests that the 17e will stick with its notched screen rather than a Dynamic Island, and we’d be surprised to see it move beyond its basic one-lens camera. Assuming Apple sticks with the same $599 starting price, though, there will still be some awkward overlap between the iPhone 16 and the regular iPhone 17.
The iPad Air
Do you like the current iPad Air with the Apple M3? Or the last one with the Apple M2?
That’s lucky for you, because a next-generation iPad Air is likely to continue in the same vein, picking up a new chip but not changing much else. If you’re holding out for something more exciting, like improved screen technology, you’ll likely be disappointed.
There’s no word on whether the M4 might come with any other internal upgrades, like more RAM or increased storage in the base model. Either or both of those could spice up an otherwise straightforward update.
Other possibilities
Apple could update the remaining M4 family MacBook Pros (pictured) with M5 family replacements.
Credit: Andrew Cunningham
Apple could update the remaining M4 family MacBook Pros (pictured) with M5 family replacements. Credit: Andrew Cunningham
Apple could choose to refresh almost any of its Macs next week—only the low-end MacBook Pro has an M5 chip, and it has been at least a year since the rest of the lineup was last updated. There’s no refresh that would come as a true surprise, excepting maybe the Mac Pro that Apple has allegedly put “on the back burner” (again).
Higher-end MacBook Pros with M5 Pro and M5 Max processors would be the most interesting updates, since they would be the first Macs to debut higher-end M5 family processors. But if you’re not desperate for an upgrade, it might be better to keep waiting a while longer. These M5 models are said to continue using the same design Apple has been using for the MacBook Pro for the last five years, and a more significant design update with OLED touchscreens and the Mac’s first Dynamic Island could be on the horizon.
M5 updates for the 13- and 15-inch MacBook Air, the iMac, the Mac mini, and the Mac Studio could happen, too; none of these computers are said to be getting any kind of significant design overhaul this generation. I would, however, be surprised if Apple chose to refresh these Macs all at once. To update some models now and hold others back until later in the spring or maybe even until the Worldwide Developers Conference in June would be more in keeping with Apple’s past practice.
As for other devices, reports have circulated for months about an imminent update for the Apple TV box, last refreshed in 2022. It has yet to materialize and is not mentioned on any shortlist for next week’s announcements, but an update is well overdue, and a new chip like the A18 or A19 would be necessary if Apple wanted to start bringing Apple Intelligence features to tvOS.
The common theme to all of these refreshes is that we can expect their updates to happen primarily on the inside, rather than the outside. The inside of a device is often more important than the outside of it, and these kinds of chip-only updates are usually successful in keeping Apple’s hardware feeling fresh. Just don’t expect to have many interesting new things to look at.
Andrew is a Senior Technology Reporter at Ars Technica, with a focus on consumer tech including computer hardware and in-depth reviews of operating systems like Windows and macOS. Andrew lives in Philadelphia and co-hosts a weekly book podcast called Overdue.
“What started as a fragmented but flexible streaming ecosystem is increasingly trending toward rebundling—fewer, larger super-platforms offering broader catalogues at higher price points,” Mathur said.
Paramount holds on to cable
Paramount’s WBD bid is unique in its aggressive push for cable channels, which are struggling with viewership and advertising revenue. Under a WBD merger, Paramount would add networks like HGTV, Cartoon Network, TLC, and CNN to its linear TV lineup, which currently includes Comedy Central, Nickelodeon, and CBS.
Although Paramount and WBD’s cable businesses are both in decline, they are both profitable. Paramount’s TV/media business, which includes its cable channels and production studios, reported $1.1 billion in adjusted OIBDA in Q4 2025. WBD’s cable business posted adjusted EBITDA of $1.41 billion that quarter.
Ultimately, a Paramount-WBD merger would put diversity of viewpoints at risk. Under Ellison’s ownership, CBS News has adjusted its approach with new editor-in-chief Bari Weiss. There have also been concerns about censoringCBS under Ellison’s Paramount, including from Stephen Colbert, who said this month that CBS forbade him from interviewing Texas Democratic Senate candidate James Talarico; CBS denied Colbert’s claim. Further, Paramount could have a lasting impact on CNN, including costs, layoffs, and coverage.
More to come
Regulatory scrutiny will be at the center of Paramount and WBD’s merger over the upcoming months. Federal approval is likely, but the merger also faces European regulation and potential state lawsuits. The theater industry is also lobbying against Paramount’s WBD merger.
Should a Paramount-WBD merger ultimately be greenlit, two declining businesses will be challenged to form a profitable one. Even with regulatory approval, Paramount-Skydance-Warner-Bros.-Discovery faces an uphill climb.
Although the bidding war may be settled, the fight for WBD is only beginning.
Despite the headline, this isn’t really a story about superconductivity—at least not the superconductivity that people care about, the stuff that doesn’t require exotic refrigeration to work. Instead, it’s a story about how superconductivity can be used as a test of some of the weirder consequences of quantum mechanics, one that involves non-existent particles of light that still act as if they exist.
Researchers have found a way to get these virtual photons to influence the behavior of a superconductor, ultimately making it worse. That may, in the end, tell us something useful about superconductivity, but it’ll probably take a little while.
Virtual reality
The story starts with quantum field theory, which is incredibly complex, but the simplified version is that even empty space is filled with fields that could govern the interactions of any quantum objects in or near that space. You can think of different particles as energetic excitements of these fields—so a photon is simply an energetic state of the quantum field.
Some of these particles have real existences we can track, like a photon emitted by a laser and absorbed by a detector some distance away. But the quantum field also allows for virtual photons, which simply act to transmit the electromagnetic force between particles. We can’t really directly detect these, but we can definitely track their effects.
One of the stranger consequences of this is that locations that have a strong electromagnetic field can be filled with virtual photons even when no real ones are present.
Which brings us to one of the materials central to the new work: boron nitride. Like the more famous graphene, boron nitride forms a series of interlinked hexagonal rings, extending out into macroscopic sheets. The bulk material is made of sheets layered onto sheets layered onto yet more sheets. This has an effect on light transiting through the material. In one direction, the light will simply slam into the material, getting absorbed or scattered. But if it’s oriented along the plane of the sheets, it’s possible for the light to travel in the space between the boron and nitrogen atoms.
Director Gore Verbinksi and screenwriter Matthew Robinson on the making of this darkly satirical sci-fi film.
Credit: Briarcliff Entertainment
We haven’t had a new film from Gore Verbinski for nine years. But the director who brought us the first three Pirates of the Caribbean movies, the nightmare-inducing horror of The Ring (2002), and the Oscar-winning hijinks of Rango (2011) is back in peak form with Good Luck, Have Fun, Don’t Die. It’s a darkly satirical, inventive, and hugely entertaining time-loop adventure that also serves as a cautionary tale about our widespread online technology addiction.
(Some spoilers below but no major reveals.)
Sam Rockwell stars as an otherwise unnamed man who shows up at a Norms diner in Los Angeles looking like a homeless person but claiming to be a time traveler from an apocalyptic future. He’s there to recruit the locals into his war against a rogue AI, although the diner patrons are understandably dubious about his sanity. (“I come from a nightmare apocalypse,” he assures the crowd about his grubby appearance. “This is the height of f*@ing fashion!”)
The fact that he knows everything about the people in the diner is more convincing. It’s his 117th attempt to find the perfect combination of people to join him on his quest. As for what happened to his team on all the previous attempts, “I really don’t like to say it out loud. It’s kind of a morale killer.”
This time, Future Man picks married school teachers Mark (Michael Pena) and Janet (Zazie Beetz), who have just escaped a zombie horde of smartphone-addicted students; Marie (Georgia Goodman), who just wanted a piece of pie; Susan (Juno Temple), a grieving mother; Ingrid (Haley Lu Richardson), who is literally allergic to Wi-Fi; Scott (Asim Chaudhry); and Bob (Daniel Barnett), a scout leader. Their mission: to locate a 9-year-old boy who is about to create a sentient AI that will take over the world and usher in the aforementioned nightmare apocalypse. Things start to go haywire pretty quickly. And then things start to get weird.
“Everything I write, I put up to what I call The Twilight Zone test—would this make a good Twilight Zone episode?” screenwriter Matthew Robinson (The Invention of Lying, Love and Monsters) told Ars. “Because that’s my favorite piece of media that’s ever existed.” Good Luck, Have Fun, Don’t Die (GLHFDD) is an amalgam of various such ideas. Mark and Janet’s storyline, for instance, was originally Robinson’s idea for a pilot that he described as “a reverse Breakfast Club, where the teachers are the rebels and the children are the conformists.”
“I had all these little pieces that fell under the theme of technology and tech addiction,” said Robinson. Then one night, he was sitting in the Norms Diner on La Cienaga in LA, where he often liked to write. “I remember looking around and seeing a sea of faces lit by cell phones, and I thought, ‘What would it possibly take for someone to wake us up out this tech sleep that we all find ourselves in?’ And then the image of a homeless guy strapped with bombs came into my head.”
Those earlier story ideas became the backstories of the central characters. Per Robinson, GLHFDD is essentially a cleverly camouflaged anthology story, normally a format that is “the kiss of death” for a project in Hollywood, although there are rare exceptions—most notably Quentin Tarantino’s Pulp Fiction. He thinks of the film as a sci-fi Canterbury Tales in which each character is a pilgrim on a journey whose story is told via flashbacks. “The cohesion came from the fact that all the stories are informed by a general frustration with tech addiction and the pervasive way that technology has invaded our brains and our personal lives and our relationships,” said Robinson.
A twisted time loop
GLHFDD is also a time loop movie in the fine tradition of Groundhog Day, with Robinson citing such films as 12 Monkeys and Edge of Tomorrow as inspirations. He didn’t overthink his time travel rules. “We can reset the timeline,” said Robinson. “[The man from the future] can’t go forward. He literally can’t move in any other direction. He has an anchor point that he can return to any time he hits a button, and that’s as far as the technology went.”
The plot device might be simple, but the ramifications quickly become complex. “I think in his draft, Matthew intended to lift his leg on the time travel movie, to poke a little fun at it,” Verbinski told Ars. “But also, I feel like you can’t go back 117 times without picking up some cosmic lint, particularly if your antagonist is right there with you. You had 14 attempts to make it out of the house and learned there is a secret passage, but then the entity you’re gaming against is going to throw another curveball. If you’re going to go back in time, I just like the idea that there are consequences. They might be really small, but you’re going to miss one.” That element is key to the teetering-on-the-edge-of-sanity paranoia of Rockwell’s time traveler.
Robinson very much wanted the film “to wear its genre-ness on its sleeve,” he said. “As much as I love a Marvel movie, they’ve sort of homogenized parallel universes and time travel, and it’s all so rote now. It used to feel special and weird and complicated and would always have some wild themes and ideas that felt challenging. If anything this was just trying to get back to that era of ’80s and ’90s genre movies that were allowed to get weird.”
Verbinski voiced similar sentiments, citing 1984’s Repo Man as an influence. “So many movies have to be an Egg McMuffin, and who doesn’t like an Egg McMuffin after a hangover?” he said. “They’re satisfying. But you’re not going to necessarily talk about those three days later. You’re not going to be haunted by those. I’m just happy we got to will [GLHFDD] into existence because it’s a type of movie you can’t make now. Sam’s outfit is kind of a metaphor for the movie. We went to a little electronic store and we bought all these pieces, and we laid them out on a table and we glued them together, and we just made it like a Halloween costume. The whole movie was sort of made that way. It had to be; it wouldn’t model out any other way.”
Reality unravels
As for what drew him to Robinson’s script, “I think we’re in this kind of global ennui or some grand sense of identity theft or loss of purpose,” said Verbinksi. “It’s a great time for art, but it’s art against a profound sense of disillusionment.” The director developed two quite distinct visual styles to accentuate the film’s narrative progression.
“Fundamentally, it was important that the film start in the real world, in Norms diner, in a high school, at a [children’s] birthday party, and then slowly twist the taffy a bit as we get closer to the [AI] antagonist,” said Verbinski. “As these anomalies occur, the film is evolving into a second visual style. The first style is [akin to] directors like Hal Ashby or Sidney Lumet, where the performance is more important than the composition or the shot construction. As you get further into it, the actual language of shots becomes more critical to the narrative.”
That ultimately translates into some big, boldly creative swings in the film’s wild third act, and to his credit, Verbinski never blinks. Robinson cites the animated film Akira as a major inspiration for that element. “Akira has maybe my favorite third act of all time, where everything just falls apart and then comes together in this beautiful way,” he said. “Gore and I wanted [the audience] to feel like reality was unraveling, because it literally is for these characters. The AI himself is very much an homage to Akira.”
“I think that it’s inherited our worst attributes,” said Verbinski of the film’s AI antagonist. “It’s much, much worse than wanting to kill humans. It wants us to like it. It demands that we like it. I think part of that has to do with being tasked in its formative years to keep us engaged. A lot of people talk about, what is AI doing to us? But there’s not a lot of conversations about what we’re doing to it. This entity being born, it’s being tied and bound and manipulated and told, ‘Let’s look at the humans and what do they want, what do they need? What do they respond to most? What do they hate?’ All those things are going to be hardwired into its source code. It’s going to have mommy issues, we’re going to have to put it on a couch.”
Perhaps not surprisingly, given the film’s themes, Robinson has largely unplugged from most social media, although he still indulges his YouTube addiction, which he jokingly describes as “channel surfing on crack.” But ideally he would like to free himself—and the rest of humanity—from the seductions of Very Online culture entirely. “My goal would be to make teenagers think their phones aren’t cool,” he said. “I would love it if all 13-year-olds went, ‘Eww, I don’t want this, this is my parents’ thing that they track me with.’ I want them all to throw it in the trash. That would be the dream.”
Jennifer is a senior writer at Ars Technica with a particular focus on where science meets culture, covering everything from physics and related interdisciplinary topics to her favorite films and TV series. Jennifer lives in Baltimore with her spouse, physicist Sean M. Carroll, and their two cats, Ariel and Caliban.
Given the right permissions and with the proper plugins, it could create, modify, or delete the user’s files and otherwise change things far beyond what most users could achieve with existing models and MCP (Model Context Protocol). Users would use files like USER.MD, MEMORY.MD, SOUL.MD, or HEARTBEAT.MD to give the tool context about its goals and how to work toward them independently, sometimes running for long stretches without direct user input.
On one hand, that meant it could do impressive things—the first glimpses of the sort of knowledge work that AI boosters have been saying agentic AI would ultimately do. On the other hand, it was prone to serious errors and vulnerable to prompt injection and other security problems, in part due to a Wild West of unverified plugins.
The same toolkit that was used to create a viral Reddit clone populated by AI agents was also, at least in one case, responsible for deleting a user’s emails against her will.
Stay in your lane
Perplexity Computer aims to address those concerns in a few ways. First, its core process occurs in the cloud, not on the user’s local machine. Second, it lives within a walled garden with a curated list of integrations, in contrast to OpenClaw’s unregulated frontier.
This is, of course, an imperfect analogy, but you could say that if OpenClaw were the open web of AI agent tools, then Computer is Apple’s App Store. While you’re more limited in what you can do, you’re not trusting packages from unverified sources with access to your system.
There could still be risks, though. For one thing, LLMs make mistakes, and those could be consequential if Computer is working with data you don’t have backed up elsewhere or if you’re not verifying the outputs, for example.
Perplexity Computer aims to button up, refine, and contain the wild power of the viral OpenClaw agentic AI tool—competing with the likes of Claude Cowork—by optimizing subtasks by selecting models best suited to them.
It surely won’t be the last existing AI player to try and do this sort of thing. After all, OpenAI hired OpenClaw’s developer, with CEO Sam Altman suggesting that some of what we saw in OpenClaw will be essential to the company’s product vision moving forward.
With Nano Banana 2, Google promises consistency for up to five characters at a time, along with accurate rendering of as many as 14 different objects per workflow. This, along with richer textures and “vibrant” lighting will aid in visual storytelling with Nano Banana 2. Google is also expanding the range of available aspect ratios and resolutions, from 512px square up to 4K widescreen.
So what can you do with Nano Banana 2? Google has provided some example images with associated prompts. These are, of course, handpicked images, but Nano Banana has been a popular image model for good reason. This degree of improvement seems believable based on past iterations of Nano Banana.
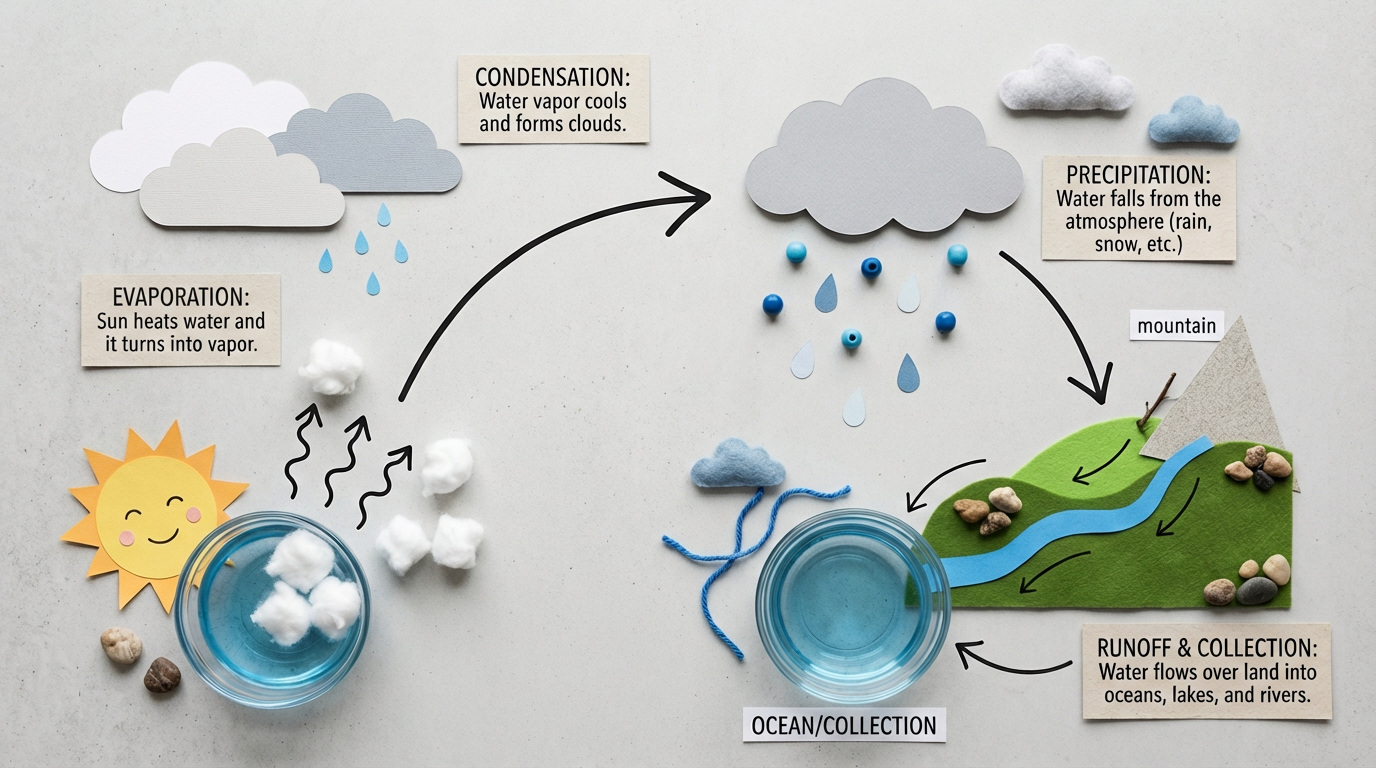
Prompt: High-quality flat lay photography creating a DIY infographic that simply explains how the water cycle works, arranged on a clean, light gray textured background. The visual story flows from left to right in clear steps. Simple, clean black arrows are hand-drawn onto the background to guide the viewer’s eye. The overall mood is educational, modern, and easy to understand. The image is shot from a top-down, bird’s-eye view with soft, even lighting that minimizes shadows and keeps the focus on the process.
Credit: Google
Prompt: High-quality flat lay photography creating a DIY infographic that simply explains how the water cycle works, arranged on a clean, light gray textured background. The visual story flows from left to right in clear steps. Simple, clean black arrows are hand-drawn onto the background to guide the viewer’s eye. The overall mood is educational, modern, and easy to understand. The image is shot from a top-down, bird’s-eye view with soft, even lighting that minimizes shadows and keeps the focus on the process. Credit: Google
Prompt: Create an image of Museum Clos Lucé. In the style of bright colored Synthetic Cubism. No text. Your plan is to first search for visual references, and generate after. Aspect ratio 16:9.
Credit: Google
Prompt: Create an image of Museum Clos Lucé. In the style of bright colored Synthetic Cubism. No text. Your plan is to first search for visual references, and generate after. Aspect ratio 16:9. Credit: Google
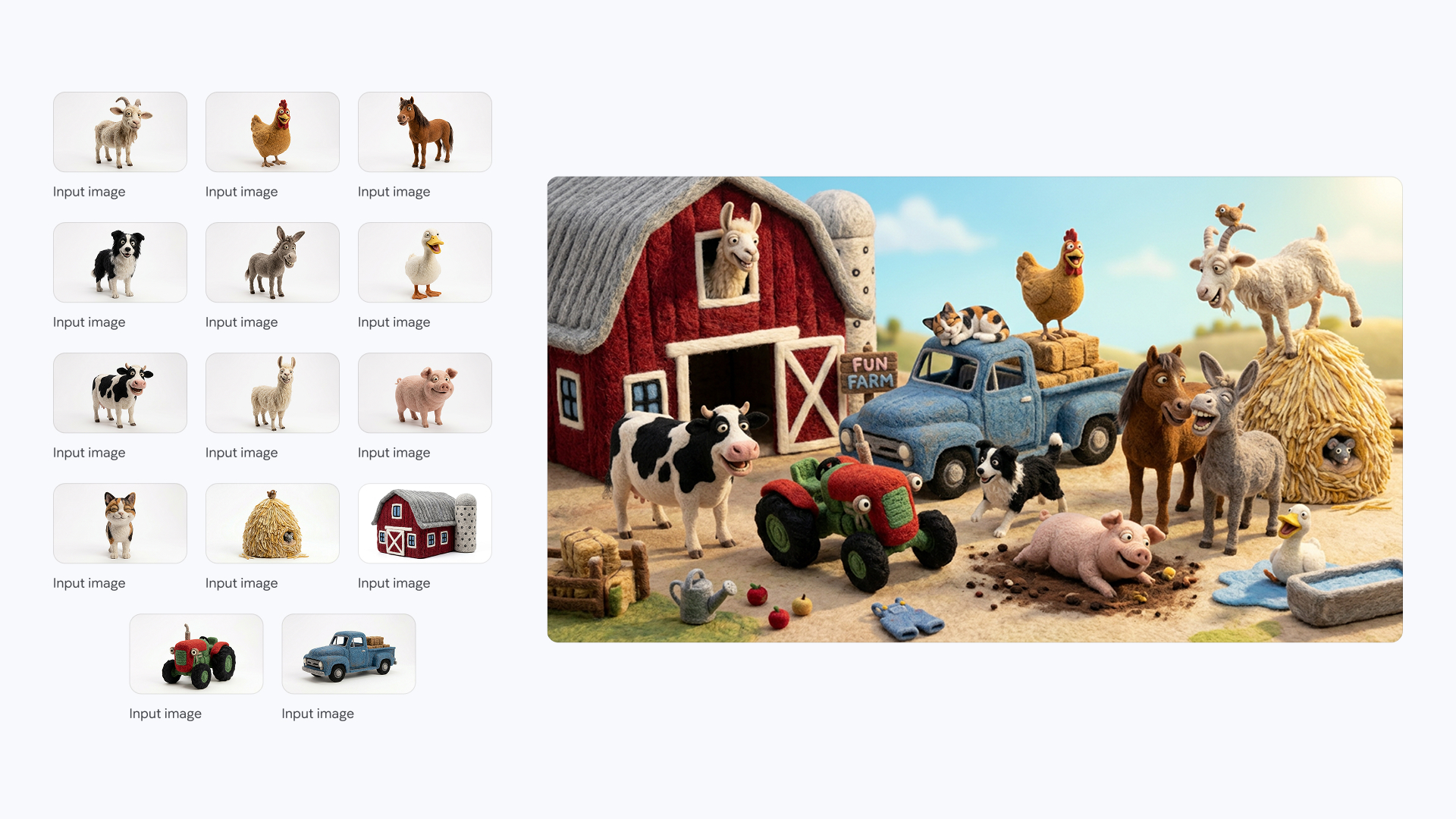
Create an image of these 14 characters and items having fun at the farm. The overall atmosphere is fun, silly and joyful. It is strictly important to keep identity consistent of all the 14 characters and items.
Credit: Google
Create an image of these 14 characters and items having fun at the farm. The overall atmosphere is fun, silly and joyful. It is strictly important to keep identity consistent of all the 14 characters and items. Credit: Google
Google must be pretty confident in this model’s capabilities because it will be the only one available going forward. Starting now, Nano Banana 2 will replace both the standard and Pro variants of Nano Banana across the Gemini app, search, AI Studio, Vertex AI, and Flow.
In the Gemini app and on the website, Nano Banana 2 will be the image generator for the Fast, Thinking, and Pro settings. It’s possible there will eventually be a Nano Banana 2 Pro—Google tends to release elements of new model families one at a time. For now, it’s all “Flash” Image.
Opening a valuable skin like this in a loot box is akin to winning a lottery, New York alleges in a new lawsuit.
Opening a valuable skin like this in a loot box is akin to winning a lottery, New York alleges in a new lawsuit. Credit: Twitter / Luksusbums
The lawsuit also takes Valve to task for allowing third-party sites that facilitate the resale of in-game skins for cash. While the suit notes that Valve has “sporadically enforced” rules against so-called skin gambling sites—which use Steam inventories as virtual chips for gambling games—it alleges that Valve “has not acted against sites that permit the sale of Valve’s virtual items.” The suit cites “internal communications” from numerous Valve employees suggesting that the company was OK with such “cash-out services” for Steam items as long as off-platform gambling wasn’t explicitly involved.
We’ll see you in court
In a press release announcing the suit, state Attorney General Letitia James said the gambling Valve’s system enables can “lead to serious addiction problems, especially for our young people. … These features are addictive, harmful, and illegal, and my office is suing to stop Valve’s illegal conduct and protect New Yorkers.”
In 2016, Valve faced a pair of civil lawsuits from parents concerned about Valve’s connection to skin gambling sites—those suits were eventually dismissed. Around the same time, Valve received a letter from Washington state threatening “civil or criminal action” if Valve didn’t crack down on skin gambling, but the state stopped short of filing a lawsuit in that matter.
In addition to asking Valve to modify or eliminate its loot box system, the New York suit asks for Valve to make “full restitution to consumers” for the disgorgement of “all monies” received from its gambling system, and for fines of “three times the amount of its gain.” Ars Technica has reached out to Valve for comment.