
Anthropic / Benj Edwards
On Thursday, Anthropic announced Claude 3.5 Sonnet, its latest AI language model and the first in a new series of “3.5” models that build upon Claude 3, launched in March. Claude 3.5 can compose text, analyze data, and write code. It features a 200,000 token context window and is available now on the Claude website and through an API. Anthropic also introduced Artifacts, a new feature in the Claude interface that shows related work documents in a dedicated window.
So far, people outside of Anthropic seem impressed. “This model is really, really good,” wrote independent AI researcher Simon Willison on X. “I think this is the new best overall model (and both faster and half the price of Opus, similar to the GPT-4 Turbo to GPT-4o jump).”
As we’ve written before, benchmarks for large language models (LLMs) are troublesome because they can be cherry-picked and often do not capture the feel and nuance of using a machine to generate outputs on almost any conceivable topic. But according to Anthropic, Claude 3.5 Sonnet matches or outperforms competitor models like GPT-4o and Gemini 1.5 Pro on certain benchmarks like MMLU (undergraduate level knowledge), GSM8K (grade school math), and HumanEval (coding).
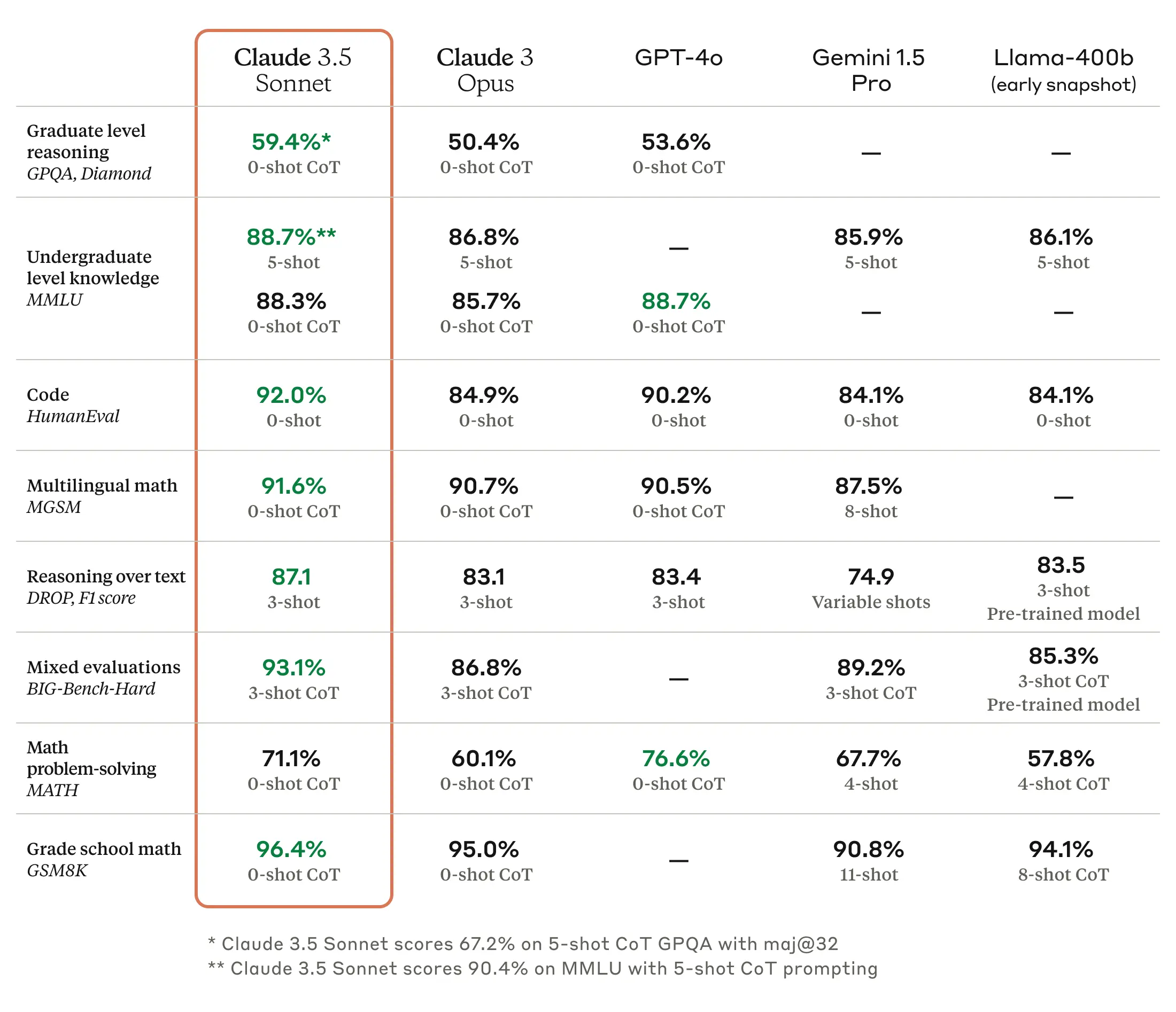
Enlarge / Claude 3.5 Sonnet benchmarks provided by Anthropic.
If all that makes your eyes glaze over, that’s OK; it’s meaningful to researchers but mostly marketing to everyone else. A more useful performance metric comes from what we might call “vibemarks” (coined here first!) which are subjective, non-rigorous aggregate feelings measured by competitive usage on sites like LMSYS’s Chatbot Arena. The Claude 3.5 Sonnet model is currently under evaluation there, and it’s too soon to say how well it will fare.
Claude 3.5 Sonnet also outperforms Anthropic’s previous-best model (Claude 3 Opus) on benchmarks measuring “reasoning,” math skills, general knowledge, and coding abilities. For example, the model demonstrated strong performance in an internal coding evaluation, solving 64 percent of problems compared to 38 percent for Claude 3 Opus.
Claude 3.5 Sonnet is also a multimodal AI model that accepts visual input in the form of images, and the new model is reportedly excellent at a battery of visual comprehension tests.
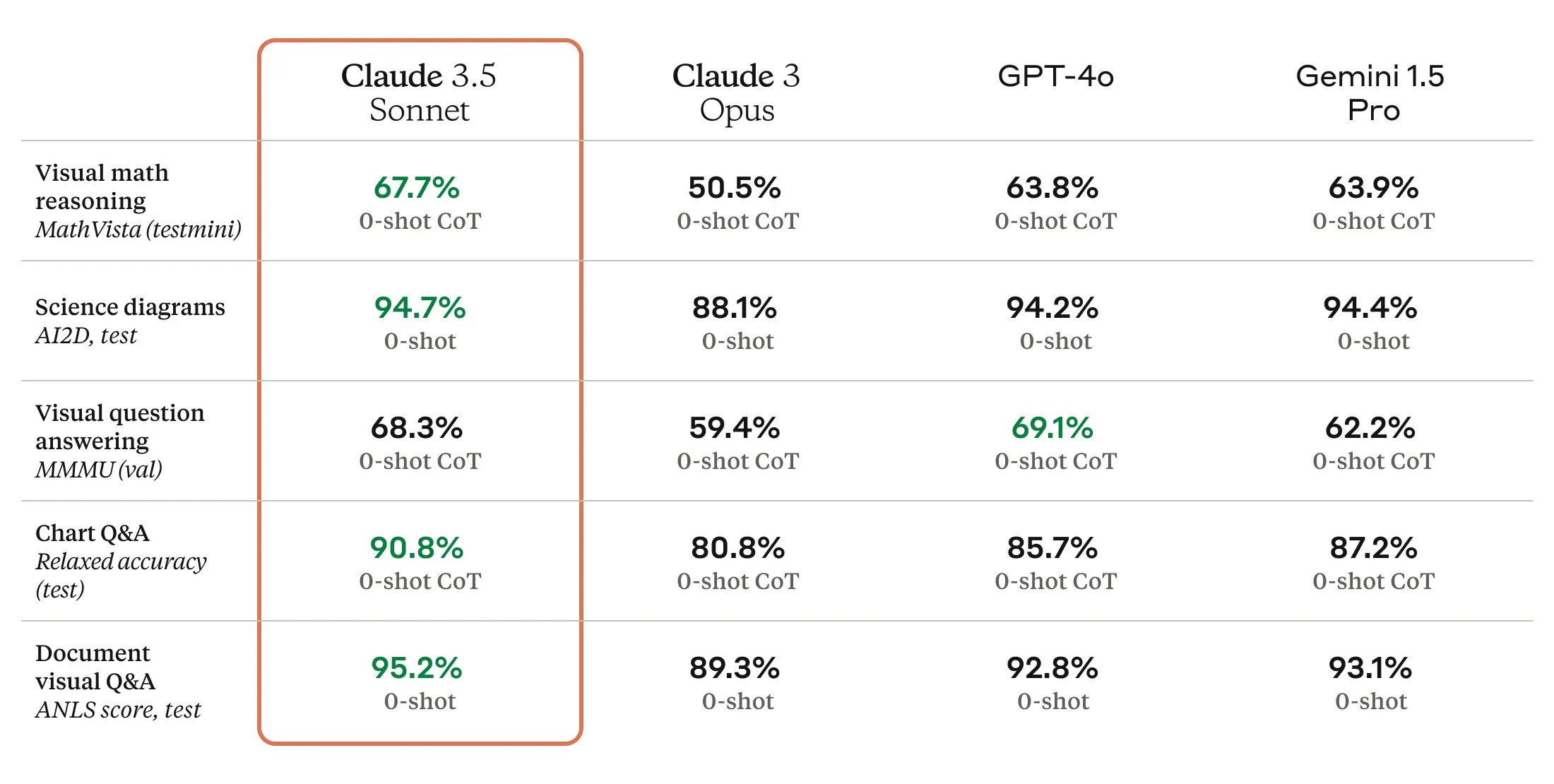
Enlarge / Claude 3.5 Sonnet benchmarks provided by Anthropic.
Roughly speaking, the visual benchmarks mean that 3.5 Sonnet is better at pulling information from images than previous models. For example, you can show it a picture of a rabbit wearing a football helmet, and the model knows it’s a rabbit wearing a football helmet and can talk about it. That’s fun for tech demos, but the tech is still not accurate enough for applications of the tech where reliability is mission critical.